
线上Bug! Sharing-JDBC第一次查询为什么这么慢?原创
-
@Test -
publicvoid testInserts() { -
Random random = new Random();ArrayList<User> users = new ArrayList<>(); -
for(int i = 0; i < 400; i++) { -
User user = newUser(); -
user.setId(random.nextInt()); -
user.setAge(20); -
user.setName("bin"); -
users.add(user); -
} -
//Spring提供的计时器,非常简单好用,推荐使用 -
StopWatch stopWatch = new StopWatch(); -
//开始计时 -
stopWatch.start(); -
userMapper3.inserts(users); -
//结束计时 -
stopWatch.stop(); -
//输出:总的用时 -
System.out.println("testInsert 共计:"+ (stopWatch.getTotalTimeMillis()) + " ms"); -
}


https://github.com/apache/incubator-shardingsphere/issues/3351
-
@Test -
publicvoid testInserts() { -
Random random = new Random(); -
ArrayList<User> users = new ArrayList<>(); -
for(int i = 0; i < 400; i++) { -
User user = newUser(); -
user.setId(random.nextInt()); -
user.setAge(20); -
user.setName("bin"); -
users.add(user); -
} -
//Spring提供的计时器,非常简单好用,推荐使用 -
StopWatch stopWatch = new StopWatch(); -
//开始计时 -
stopWatch.start(); -
userMapper3.inserts(users); -
//结束计时 -
stopWatch.stop(); -
//输出:总的用时 -
System.out.println("testInsert 共计:"+ (stopWatch.getTotalTimeMillis()) + " ms"); -
StopWatch stopWatch2 = new StopWatch(); -
stopWatch2.start(); -
userMapper3.inserts(users) -
stopWatch2.stop(); -
System.out.println("testInsert 共计:"+ (stopWatch2.getTotalTimeMillis()) + " ms"); -
}
执行结果:
[11-16 14:39:20.020] [WARN] [cat] Cat is lazy initialized! testInsert 共计:4342 ms testInsert 共计:50 ms

Mybatis核心 MapperProxy#invoke
-
@Override -
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { -
if (Object.class.equals(method.getDeclaringClass())) { -
try { -
return method.invoke(this, args); -
} catch (Throwable t) { -
throw ExceptionUtil.unwrapThrowable(t); -
} -
} -
//调用 mapperMethod() -
final MapperMethod mapperMethod = cachedMapperMethod(method); -
//执行sql -
return mapperMethod.execute(sqlSession, args); -
} -
//缓存mapperMethod方法 -
private MapperMethod cachedMapperMethod(Method method) { -
MapperMethod mapperMethod = methodCache.get(method); -
//第一次执行时缓存 -
if (mapperMethod == null) { -
mapperMethod = new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()); -
methodCache.put(method, mapperMethod); -
} -
//直接返回缓存中的mapperMethod,无需重复解析,提升了性能。(ps:此时不需要sql解析) -
return mapperMethod; -
}
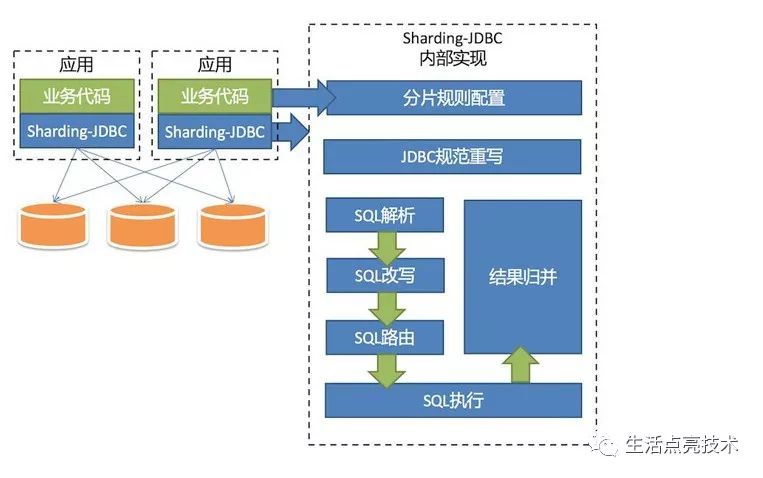
附SharingJDBC简介:
-
Applicable in any ORM framework based on JDBC, such as JPA, Hibernate, Mybatis, Spring JDBC Template or direct use of JDBC.
-
Support any third-party database connection pool, such as DBCP, C3P0, BoneCP, Druid, HikariCP. -
Support any kind of JDBC standard database: MySQL, Oracle, SQLServer, PostgreSQL and any SQL92 followed databases.
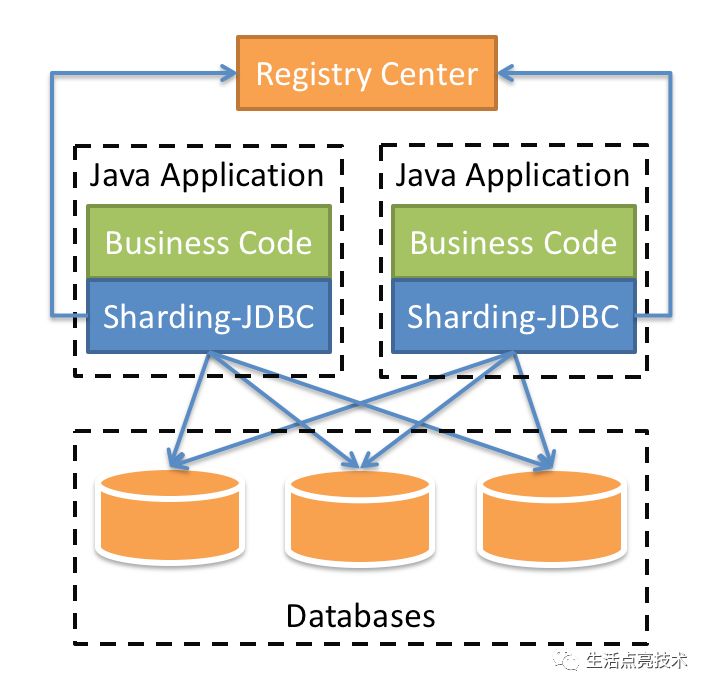
https://github.com/apache/incubator-shardingsphere
Internal Structure
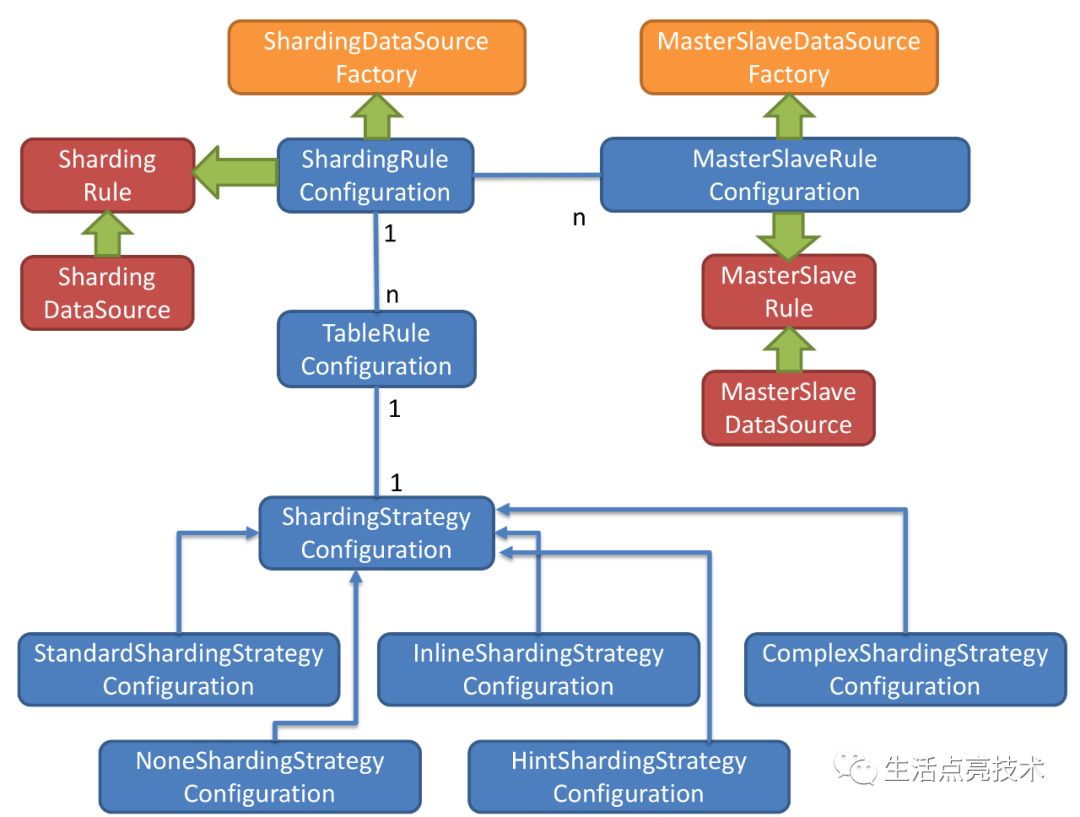
https://shardingsphere.apache.org/document/current/en/manual/sharding-jdbc/


