
从29.6s优化到33ms,我是如何做到的原创
案发现场
收到用户反馈,功能不好用了:

“这个列表是坏了嘛
我今天给一下午都点不开”
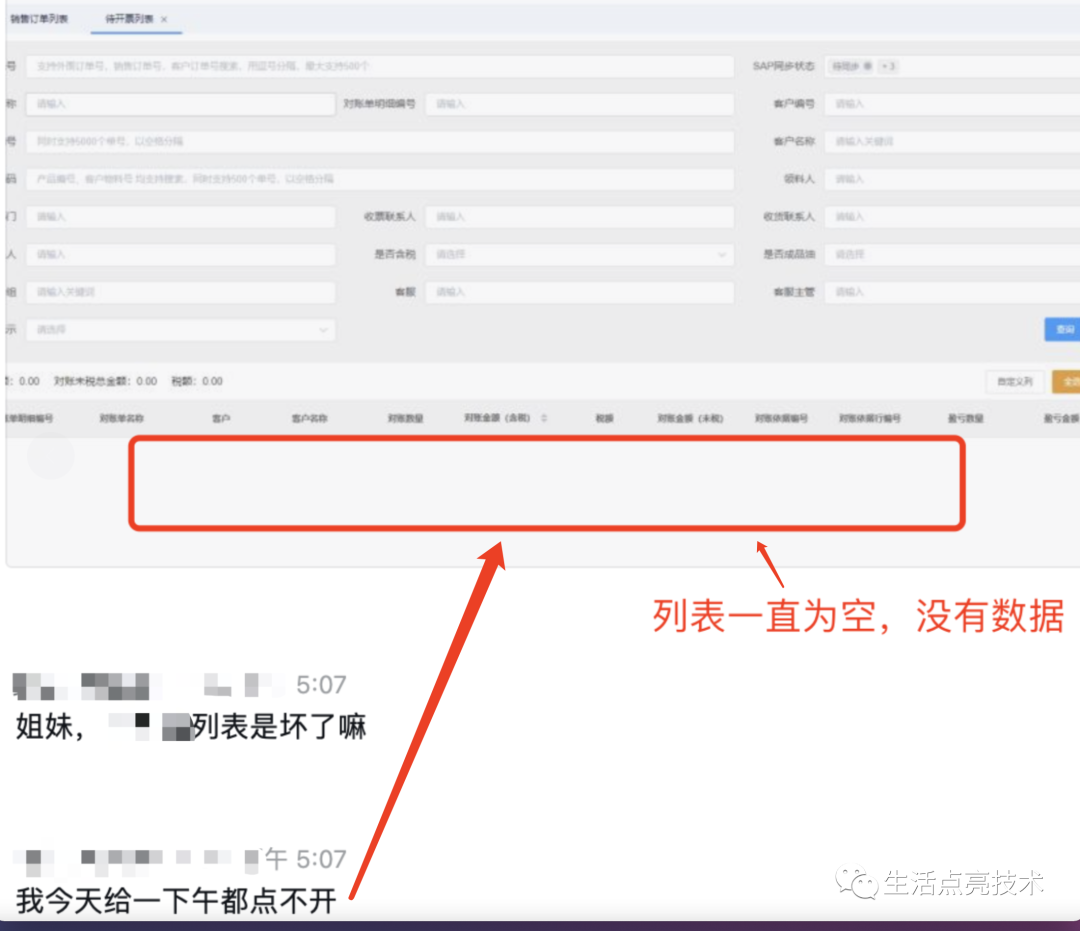
抓紧在本地复现了下:
测试环境是没有问题的。
线上的页面打开慢、还会报错:"request timeout"
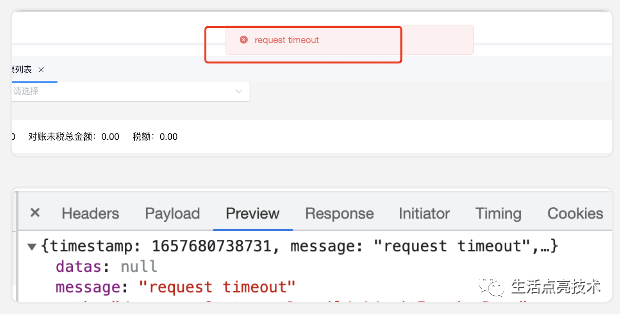
现状
去日志中查了下,是查询TableStore时报错了:
content:2022-07-28 20:06:44[7e165900997904910398fe22 ][http-nio-8080-exec-11] ERROR c.z.common.dto.ApiResponse - failure :{"datas":null,"message":"request timeout","path":"/v1/waitInvoicePage","status":500,"timestamp":1659011104445}Caused by: com.alicloud.openservices.tablestore.TableStoreException: request timeoutcom.alicloud.openservices.tablestore.TableStoreException:request timeout
表格存储(Tablestore)面向海量结构化数据提供 Serverless 表存储服务,同时针对物联网场景深度优化提供一站式的 IoTstore 解决方案。适用于海量账单、IM 消息、物联网、车联网、风控、推荐等场景中的结构化数据存储,提供海量数据低成本存储、毫秒级的在线数据查询和检索以及灵活的数据分析能力。
根据日志中的traceId,去全链路跟踪平台上查看下整体情况:
异常:com.alicloud.openservices.tablestore.TableStoreException:request timeoutat com.alicloud.openservices.tablestore.core.CallbackImpledFuture.getResultWithoutLock(CallbackImpledFuture.java:107)at com.alicloud.openservices.tablestore.core.CallbackImpledFuture.get(CallbackImpledFuture.java:89)at com.alicloud.openservices.tablestore.SyncClient.waitForFuture(SyncClient.java:502)at com.alicloud.openservices.tablestore.SyncClient.search(SyncClient.java:467)
就是查tableStore失败了,在日志平台查下看到,因为查询参数太长,日志平台直接进行了截断!!!
估计此处有坑
{ "dataSize": 26, "type": "STRING", "value": "2103241740451151094605"},
{"dataSize": 26, "type": "STRING", "value": "3241741331950505477"},
{"dataSize": 26, "type": "STRING", "valu收起继续看日志。前端传来的查询参数并不多,
但在对TableStore进行查询时,却传了这么多参数,应该有情况!
继续跟。梳理下这个服务的业务逻辑。这个业务域的数据主要由一个Header表和一个Item表来承载。
一条完整的业务数据包含一条Header数据和至少一条Item数据。
这个服务返回的数据需要满足以下特征:
-
Header表中的状态是 已完成
-
Item表中的记录要满足指定的筛选条件
上面的需求翻译成sql是这样的:
select header.filed_name1,item.filed_name2,item.filed_name3 from header ,item
where header.id=item.headerId and header.status='Finished'
and item.filed_name_x='指定的筛选条件'
and item.filed_name_y='指定的筛选条件'
。。。其它筛选条件 。。。查到此处,是不是有小朋友有疑问了:不就是一个sql搞定的事,为什么报错的是TableStore,而不是MySql?
这是个好问题!
如果header表和item表中数据量在10万以下,直接用上面的SQL就可以把这个需求摆平了。
如果数据量是百万级时,估计就会慢得像蜗牛。
对数据库有了解的同学,肯定会讲sql查询慢,可以通过加索引来解决!
是的,sql查询慢时,要考虑加索引。
如果查询条件有19个,并且都是可选的,
这种情况下,索引该怎么加?
要想解决速度问题,至少要加15+索引。一些区分度低的字段,就不适合加索引

这也是没有查MySql,而是查询存在TableStore上的数据的原因之一。
索引:在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
为什么uat环境正常,但线上环境坏了?
ua环境和线上,这两个环境上的数据量级是不同的。
uat的数据不到2万,线上的数据是百万级,接近千万。
这也是为什么测试环境是ok的,到了线上,功能就坏了的原因。
根因分析&解决办法
经过上面的排查,来简单梳理一下:
从数据角度拆解这个需求,就是所需数据存在两个张表,这两张表中是1:n的关系。
这个需求中的筛选条件,Header表中有,Item表中也有。
数据流
-
把Header表中满足条件的Id查出来。得到 headder_id_list,线上有50万+个
-
筛选Item表中的数据。需要一个条件:where item.header_id in ($headder_id_list)
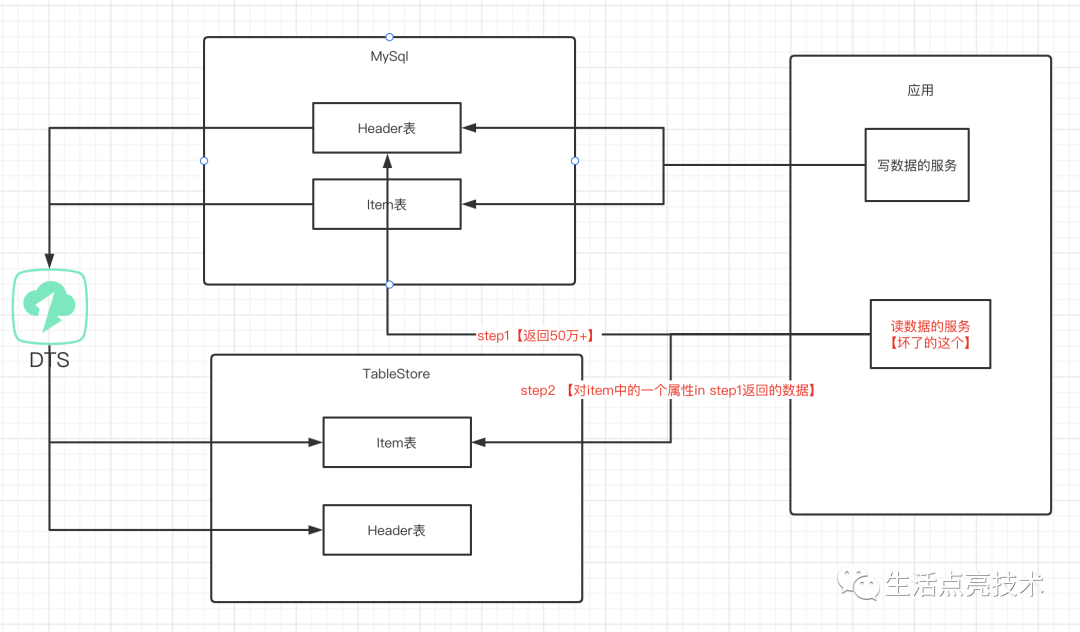
问题:
headder_id_list 在线上的数量是50万+,并且随着业务开展还会持续增加,
直接in这么多数据,TableStore也抗不住,直接尥蹶子了
com.alicloud.openservices.tablestore.TableStoreException:request timeout优化方案
根据上面的分析,可以得到以下判断:
-
不能直接查mysql。
数据量目前是百万级,随着业务开展,数据量还会持续增加。 -
两表关联查询查库,有性能问题
-
筛选条件多,19个。需要的索引多。
索引会占用额外的空间,索引过多也会增加MySql性能优化器的负担,对查询速度有影响。
-
不能通过MySql+TableStore的方式来进行数据筛选。
Header表中的数据量在50万+,TableStore直接in这么数据,也搞不定
问题来了:是哪个环节做错了,导致这个功能坏了?
-
数据模型错了?
为什么使用Header表和Item表两张表来承载这些业务数据?从业务上看有一个总的描述,
譬如整体上这项事务有没有完成,就像金字塔原理中讲的结论先行、以上统下、归类分组。
如果是使用这种由多张能互相联接的二维行列表格组成的关系型数据库来承载这个1:n的业务概念,必然是一张Header表来承载总体描述,一张Item表来承诺1+条明细信息。 -
技术方案错了?
因为查询条件多且可以随意组合,使用MySql是不合适的,使用TableStore的这处技术中间件是对的。TableStore不支持两表关联查询,按目前的数据模型,只能把Header表上的状态先查出来,再进行in
这样看来,数据模型没错,技术方案在方向上也没有明显的问题,
只是没考虑到TableStore不能很好支持in超过5万+的数据
那么,问题的根子在哪?
消费数据的维度与持久化数据的维度不一致。
存数据,是结论先行、以上统下。拆成Header表、Item表。
消费数据,是以局部看整体。Item上的数据体现了一个具体业务的整体情况。
这个不一致,引发了线上功能的各种坑。
解决方案:
数据异构。建立一个Item维度的一个异构数据,或者理解为CQRS模型中的查询Model也可以。
这个异构数据包含了业务需求中涉及到的所有数据,数据查询都来查这个Model。即SRP:将写、读操作拆到独立的上下文。
最终的技术方案如下:
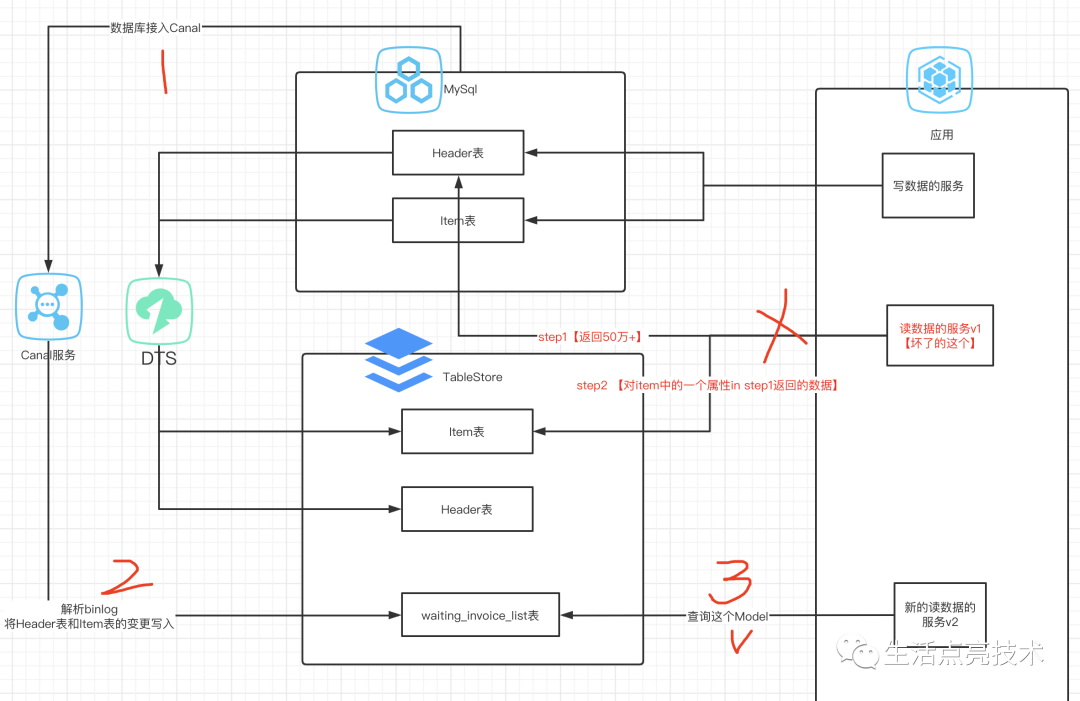
什么是异构?简单的说就是指一个整体中包含有不同的成分的特性,即这个整体由多个不同的成分构成。
什么是数据异构?按照不同查询维度建立表结构,这样就可以按照这种不同维度进行查询。数据异构有查询维度异构、聚合数据异构等。
如何完成异构数据的落地?
通过MQ机制接收数据变更,然后原子化存储到合适的存储引擎,如TableStore、Redis、ES或持久化KV存储。数据闭环和数据异构其实是一个概念,目的都是实现数据的自我控制,当其它系统出问题时不影响自己的系统,或者自己出问题时不影响其它系统。一般通过消息队列来实现数据分发。
CQRS模式【命令查询的责任分离,Command Query Responsibility Segregation】:通过将数据存储和数据查询这两个关注点分离。通过分离读写操作,可以实现数据异构,进而提升查询性能。
C(Command)端负责数据存储,Q(Query)端负责数据查询,Q端的数据通过C端产生的Event来同步。
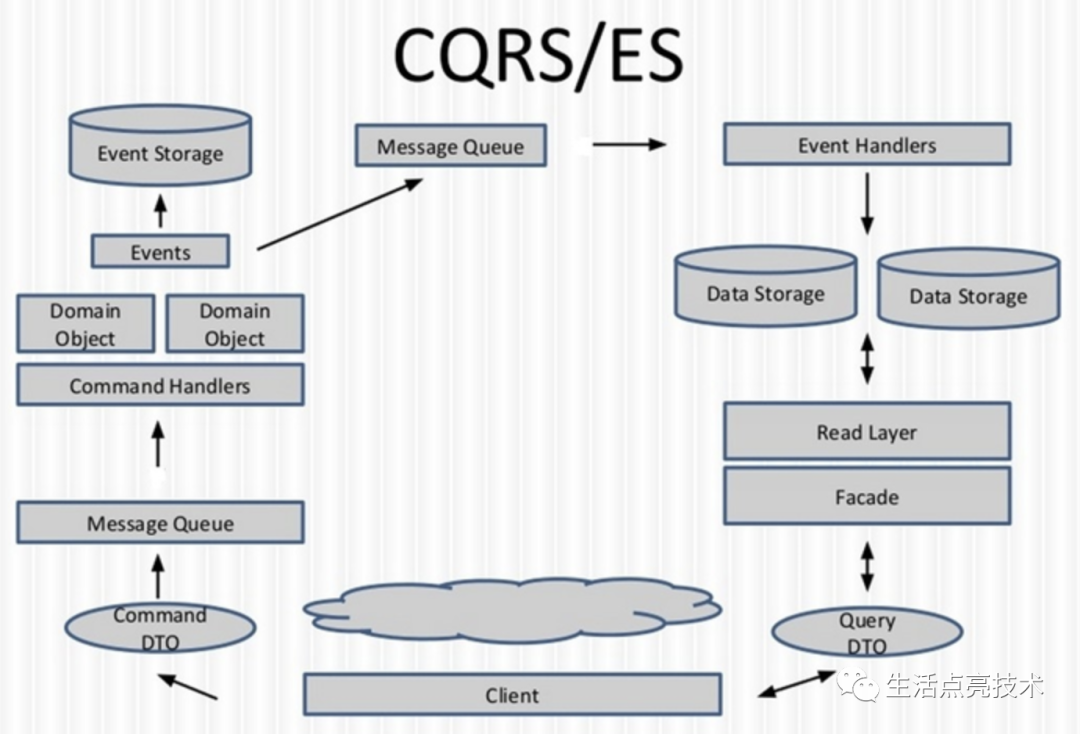
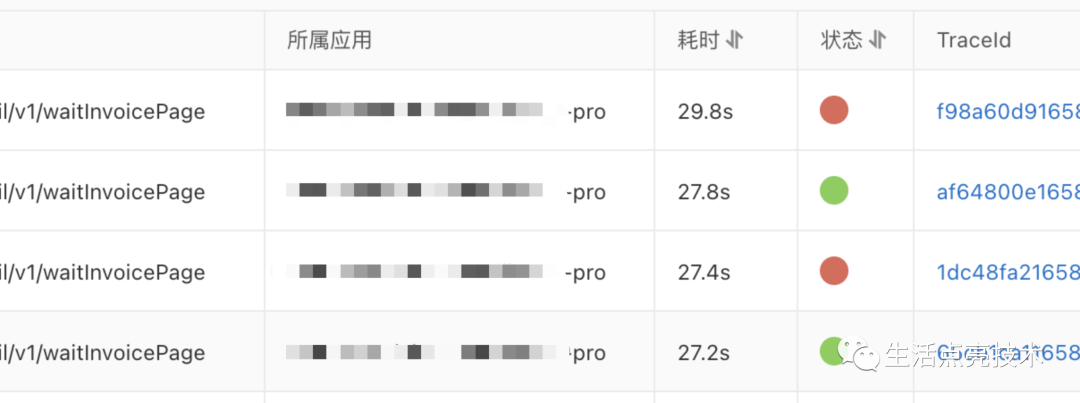
优化后的效果
优化前:报错或者耗时24s+
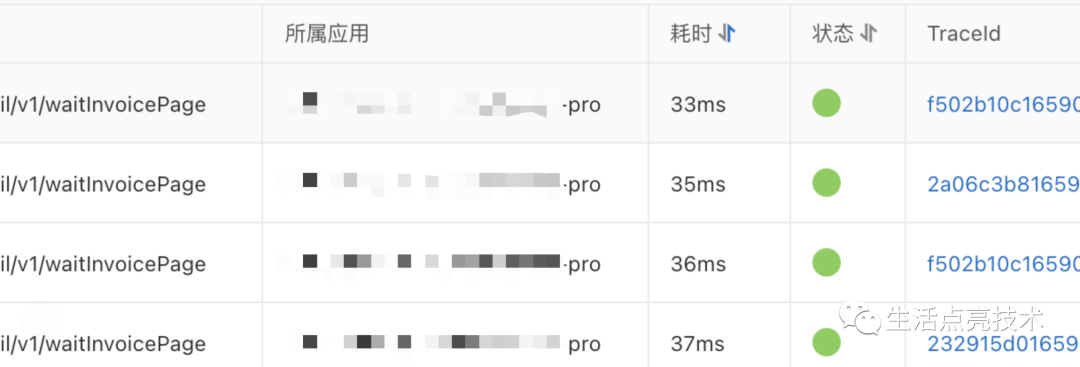
优化后:
没有报错了。最少耗时33ms
小结
在大数据量、多筛选条件、高访问量时,使用数据异构是非常有效的。
不过数据异构也增加了架构的复杂度,需要团队根据各自的技术积累,慎重权衡。
异构可以通过订阅MQ或者解析Binlog来实现业务数据存储和构建异构数据这两件事的解耦。
参考:
https://www.cnblogs.com/softidea/p/6877767.html
https://www.cnblogs.com/softidea/p/13827446.html
https://www.cnblogs.com/softidea/p/7306007.html
https://www.aliyun.com/product/ots
https://martinfowler.com/bliki/CommandQuerySeparation.html
https://blog.csdn.net/yb223731/article/details/120835012
https://www.jdon.com/cqrs.html


