
Redis 高可用之哨兵集群原创
前言
我们在前面的文章中分析了Redis 高可用之主从复制。
主从复制奠定了Redis 分布式的基础,但是普通的主从复制并不能满足高可用性。
在普通的主从复制模式下,如果主服务器发生宕机,就只能通过人工,手动将从节点切换为主节点后服务才恢复,很显然这种方案并不可取。
Redis 官方为了解决这一问题推出了「可抵抗节点故障」的高可用方案——Redis Sentinel(哨兵)。
哨兵机制是 Redis 高可用性的解决方案,是实现主从库自动切换的关键机制。
哨兵模式能在主节点故障后能自动将从节点提升成主节点,不需要人工干预操作就能恢复服务可用。
我们之前那也分析了哨兵机制的工作流程,这里简单回顾下哨兵负责的三个任务:
-
监控:通过
PING -
选主:主库挂了,在从库中按照一定机制选择一个新主库;
-
通知:通知其他从库和客户端新主库的相关信息。
由于「单机哨兵」很容易产生「误判」,误判后主从切换会产生一系列的额外开销,为了减少误判,避免这些不必要的开销,采用「哨兵集群」,通过引入多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主库下线的情况。
本文我们就来分析哨兵集群的工作原理。
启动并初始化 Sentinel
通过部署多个哨兵实例,就可以形成一个哨兵集群。
一旦多个实例组成了哨兵集群,即使有哨兵实例出现故障挂掉了,其他哨兵还能继续协作完成主从库切换的工作,包括判定主库是不是处于下线状态,选择新主库,以及通知从库和客户端。
哨兵本质就是一台 Redis 服务器,但是和普通 Redis 服务不同的是,它是一个拥有较少的命令以及部分特殊功能的 Redis 服务。比如,Sentinel 模式下,Redis 服务器不需要读取RDB、AOF文件来还原数据状态。
启动一个 Sentinel 需要的步骤:
-
初始化 Sentinel 服务器
-
使用 Sentinel 专用代码
-
初始化 Sentinel 状态
-
初始化 Sentinel 监视的主服务器列表
-
创建连向主服务器的网络连接
-
获取主服务器信息
-
根据主服务获取从服务器信息,创建同从服务器的网络连接
-
根据发布/订阅获取 Sentinel 信息,创建 Sentinel 之间的网络连接
初始化 Sentinel 状态
使用了 Sentinel 专用代码之后,Sentinel 会初始化一个 sentinelState
初始化 Sentinel 监视的主服务器列表
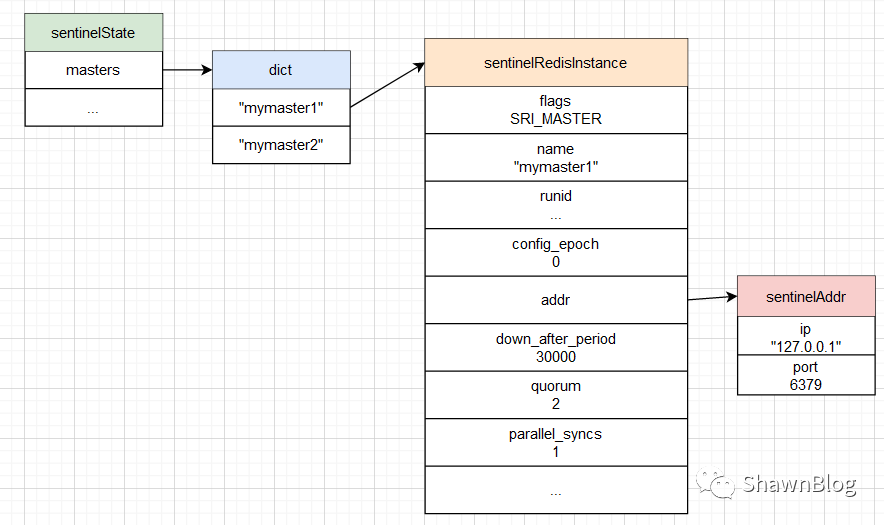
Sentinel 监视的主服务器信息保存在「masters 字典」中:
-
字典的键是主服务器的名字;
-
字典的值是一个指向
sentinelRedisInstance
每个 sentinelRedisInstance
sentinel.c/sentinelRedisInstance:
typedef struct sentinelRedisInstance{
// 标识值,标识当前实例的类型和状态。如SRI_MASTER、SRI_SLVAE、SRI_SENTINEL
int flags;
// 实例名称
// 主服务器为用户配置实例名称
// 从服务器和Sentinel的名字由 Sentinel 自动设置 格式 为ip:port
char *name;
// 实例运行ID
char *runid;
//配置纪元,故障转移使用
uint64_t config_epoch;
// 实例地址
sentinelAddr *addr;
// 实例判断为主观下线的时长
// sentinel down-after-milliseconds redis-master 30000
mstime_t down_after_period;
// 实例判断为客观下线所需支持的投票数
// sentinel monitor redis-master 127.0.0.1 6379 2
int quorum;
// 执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量
// sentinel parallel-syncs redis-master 1
int parallel-syncs;
// 刷新故障迁移状态的最大时限
// sentinel failover-timeout redis-master 180000
mstime_t failover_timeout;
// ...
}sentinelRedisInstance;
我们需要在 sentinel.conf
sentinel monitor <master-name> <ip> <redis-port> <quorum>
比如:
sentinel monitor mymaster1 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000sentinel monitor mymaster2 127.0.0.1 12345 2
sentinel down-after-milliseconds mymaster2 30000
sentinel parallel-syncs mymaster2 1
sentinel failover-timeout mymaster2 180000
实例结构,如下图所示:
创建连向主服务器的网络连接
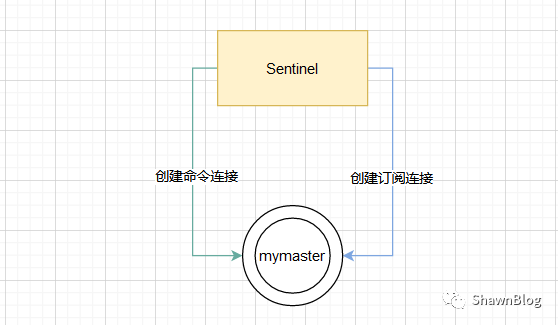
当实例结构初始化完成之后,Sentinel 会开始创建连向主服务器的网络连接,这一步 Sentinel 将成为主服务器的客户端。
对于每个被 Sentinel 监视的主服务器来说,Sentinel 会创建两个连向主服务器的异步连接:
-
命令连接:获取主从信息;以及发布 Sentinel 本身信息和监控的主服务器信息;
-
订阅连接:通过订阅
__sentinel__:hello
获取主服务器信息
在创建完网络连接之后,Sentinel 默认会以 10 秒一次的频率通过「命令连接」向主服务器发送INFO
-
主服务器的信息;
-
主服务器属下的所有从服务器信息。
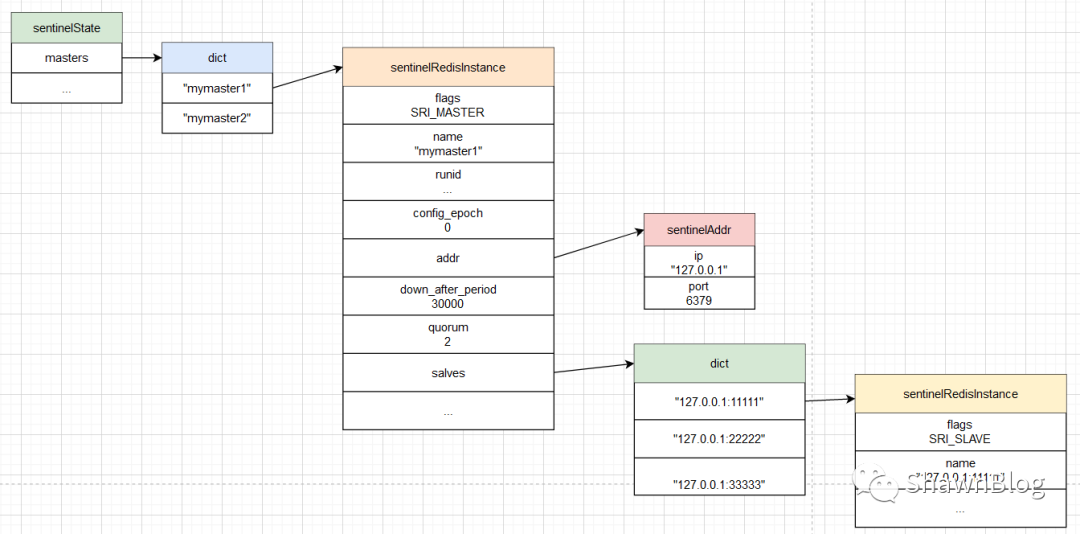
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:3
slave0:ip=127.0.0.1,port=11111,state=online,offset=666,lag=0
slave1:ip=127.0.0.1,port=22222,state=online,offset=666,lag=0
slave2:ip=127.0.0.1,port=33333,state=online,offset=666,lag=0
...
主服务器实例结构包含一个 slaves 字典,这个字典记录了主服务器属下的从服务器的名单。实例结构如下所示:
获取从服务器信息
根据主服务器获取了从服务器信息,Sentinel 可以创建到 Slave 的网络连接,Sentinel 和 Slave 之间也会创建「命令连接」和「订阅连接」。
当 Sentinel 和 Slave 之间创建网络连接之后,Sentinel 成为了 Slave 的客户端,Sentinel 也会每隔10 秒钟通过INFO
到这一步 Sentinel 获取到了 Master 和 Slave 的相关服务器数据。这其中比较重要的信息如下:
-
从服务器的运行 ID run_id
-
从服务器的角色 role
-
主服务器的IP地址 以及端口号
-
主从服务器的连接状态
-
从服务器的优先级
-
从服务器的复制偏移量
通过上面分析,我们知道 Sentinel 和主从服务器之间的信息交互,但是哨兵实例之间是不知道彼此地址的,那又是如何组成集群的呢?
要弄明白这个问题,我们就需要学习一下哨兵之间是如何建立通信的。
创建 Sentinel 之间的网络连接
向主从服务器发送信息
Sentinel 会与自己监视的所有 Master 和 Slave 之间订阅 __sentinel__:hello__sentinel__:hello
PUBLISH __sentinel__:hello "<s_ip>,<s_port>,<s_runid>,<s_epoch>,<m_name>,<m_ip>,<m_port>,<m_epoch>"信息格式:
-
s_ip :Sentinel的 IP 地址
-
s_port:Sentinel 的端口号
-
s_runid:Sentinel 的运行ID
-
s_epoch:sentinel当前的配置纪元
-
m_name:主服务的名字
-
m_ip:主服务器ip
-
m_port:主服务器的端口号
-
m_epoch:主服务器当前的纪元
接收主从服务器的频道信息
当 Sentinel 跟一个主库或者从库建立起「订阅连接」之后,就会发送:
SUBSCRIBE __sentinel__:hello
命令。通过频道接收到的信息就可获取到其他 Sentinel 的 ip 和 port。
“对于每个与 Sentinel 连接的服务器,Sentinel 既通过「命令连接」向服务器的
频道发送信息,又通过「订阅连接」服务器的__sentinel__:hello频道接收信息。__sentinel__:hello
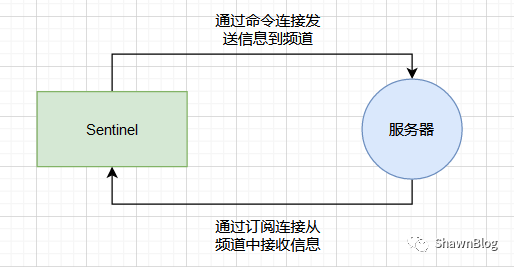
因为我们的 Sentinel 是集群部署,所以多个 Sentinel 在配置文件中会配置相同的主服务器 ip 和端口信息,也就是说,多个 Sentinel 均会订阅__sentinel__:hello
-
如果接收到的 runID 和自己的 runID 相同,那么说明消息是自己发布的,Sentinel 会直接丢弃,不处理。
-
相反,如果接收到的 runID 和自己的不相同,则说明接收到的消息是其他 Sentinel 发布的,然后根据获取的信息判断是更新或新增实例结构,这就需要更新 sentinels 字典了。
sentinels 字典保存在 sentinelRedisInstance
“Sentinel 之间不会创建订阅连接,它们只会创建命令连接。因为 Sentinel 通过订阅主从库的频道信息来获取新的 Sentinel 。相互已知的Sentinel 只需要命令连接进行通信就可以了。
介绍完 Sentinel 的初始化工作,下面我们开始分析 Sentinel 的工作原理。
Sentinel 的工作原理
Sentinel 最主要的工作就是监视 Redis 服务器,当实例超出预设的时限后,切换新的 Master 实例。这其中有很多细节工作,大致分为四个步骤:
-
检测Master是否主观下线
-
检测Master是否客观下线
-
选举领头Sentinel
-
故障转移
我们逐个分析。
检测主观下线状态
Sentinel 每隔1秒钟,向 sentinelRedisInstancePING
在 Sentinel 的配置文件中,当 Sentinel PINGdown-after-millisecondsSentinel 认为其主观下线。
Sentinel 的配置文件中配置的 down-after-millisecondssentinelRedisInstance
“无效指令指的是+PONG、-LOADING、-MASTERDOWN之外的其他指令,包括无响应。
如果当前 Sentinel 检测到 Master 处于主观下线状态,那么它将会修改其 sentinelRedisInstanceflags 属性 为 SRI_S_DOWN
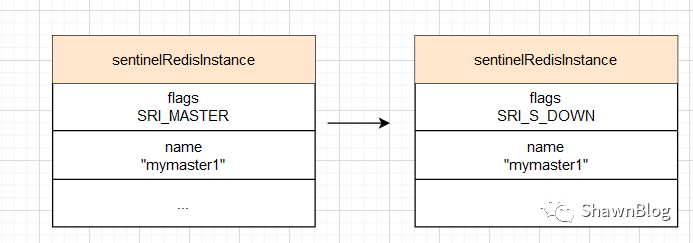
检测客观下线
当前 Sentinel 认为其下线只能处于主观下线状态,要想判断当前 Master 是否客观下线,还需要询问其他 Sentinel,并且所有认为 Master 主观下线或者客观下线的总和需要达到 quorum 配置的值,当前 Sentinel 才会将 Master 标记为「客观下线」。
当前 Sentinel 向 sentinelRedisInstance
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid>-
ip:被判断为主观下线的 Master 的IP地址
-
port:被判断为主观下线的 Master 的端口
-
current_epoch:当前 sentinel 的配置纪元
-
runid:可以是
*runid*runid
当一个 Sentinel 接收到发来的 SENTINEL is-master-down-by-addr
-
down_state:检查结果 1 代表主服务器已下线、0 代表主服务器未下线
-
leader_runid:返回
*runid -
leader_epoch:当 leader_runid 返回
runid
根据其他 Sentinel 返回的回复,Sentinel 统计其他 Sentinel 同意主服务器已下线的数量,当这个值达到配置下线所需数量时,Sentinel 会将主服务器实例结构 flags 属性的 SRI_O_DOWN
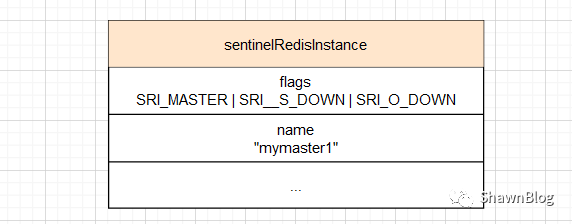
选举领头Sentinel
当主库被判断为「客观下线」之后,监视这个主库的所有 Sentinel 会进行商议,选举出一个领头的 Sentinel ,由领头 Sentinel 对下线主库进行故障转移。
由哪个哨兵执行主从切换?
确定由哪个哨兵执行主从切换的过程,和主库「客观下线」的判断过程类似,也是一个「投票仲裁」的过程。
选举领头Sentinel的规则:
-
所有在线的 Sentinel 都有被选举为领头 Sentinel 的资格;
-
每次选举之后,不管是否选举成功,所有的 Sentinel 配置纪元的值都会自增一次;配置纪元实际上就是一个计数器;
-
在一个配置纪元里,所有 Sentinel 都有一次将某个 Sentinel 设置为局部领头 Sentinel 的机会,局部领头一旦设置,在这个配置纪元里就不能再更改;
-
每个发现主库进入客观下线的 Sentinel 都会要求其他 Sentinel 将自己设置为局部领头 Sentinel ;
-
当一个 Sentinel (源 Sentinel )向另一个 Sentinel (目标 Sentinel )发送
SENTINEL is-master-down-by-addr*而是源 Sentinel 的 runid 时,表示源 Sentinel 要求目标 Sentinel 将前者设置为后者的局部领头 Sentinel; -
Sentinel 设置局部领头 Sentinel 的规则是先到先得:如果目标 Sentinel 被设置了局部领头 Sentinel,之后接收到的请求都会拒绝;
-
目标 Sentinel 接收到
SENTINEL is-master-down-by-addrleader_runidleader_epoch -
源 Sentinel 接收到目标 Sentinel 的回复之后,会检查回复中
leader_epochleader_runidleader_runid -
如果某个 Sentinel 被半数以上的 Sentinel 设置为 局部领头 Sentinel,那么该 Sentinel 成为领头 Sentinel 。
-
如果在给定的时限内,没有一个 Sentinel 被选举为领头 Sentinel ,那么各个 Sentinel 将在一段时间之后再次选举,直到选出领头 Sentinel 为止。
这一大段看起来很难理解,我们通过一个例子来说明一下。
假设有三个 Sentinel 在监视同一个主服务器。并且,这三个 Sentinel 已经通过 SENTINEL is-master-down-by-addr
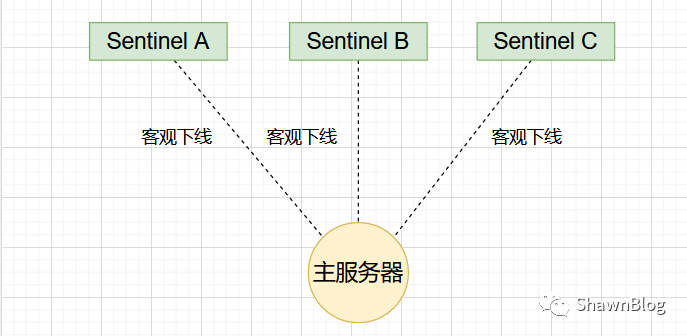
为了选举领头 Sentinel ,三个 Sentinel 会再次向其他 Sentinel 发送 SENTINEL is-master-down-by-addr
和检测客观下线不同的是,这次会带上自己的 runid,例如:
SENTINEL is-master-down-by-addr 127.0.0.1 6379 0 cd46b4591e3d8984bc984223ed4321f8c6f9981b
如果说,接收到这个命令的 Sentinel 还没有设置局部领头 Sentinel ,它就会将 runid 为 cd46b4591e3d8984bc984223ed4321f8c6f9981b
需要注意的是,如果哨兵集群只有 2 个实例,此时,一个哨兵要想成为 Leader,必须获得 2 票,而不是 1 票。
所以,如果有个哨兵挂掉了,那么,此时的集群是无法进行主从库切换的。
因此,通常我们至少会配置 3 个哨兵实例。这一点很重要,在实际应用时可不能忽略了。
故障转移
选举出领头 Sentinel 之后,领头 Sentinel 就会对已下线的 Sentinel 进行故障转移。
故障转移有两个重要的点:
-
选主
-
通知
这两个我在Redis 高可用之哨兵机制已经介绍了,这里就不在赘述。
好了,关于哨兵集群我们就分析到这里了。


