
Redis 高可用之哨兵机制原创
前言
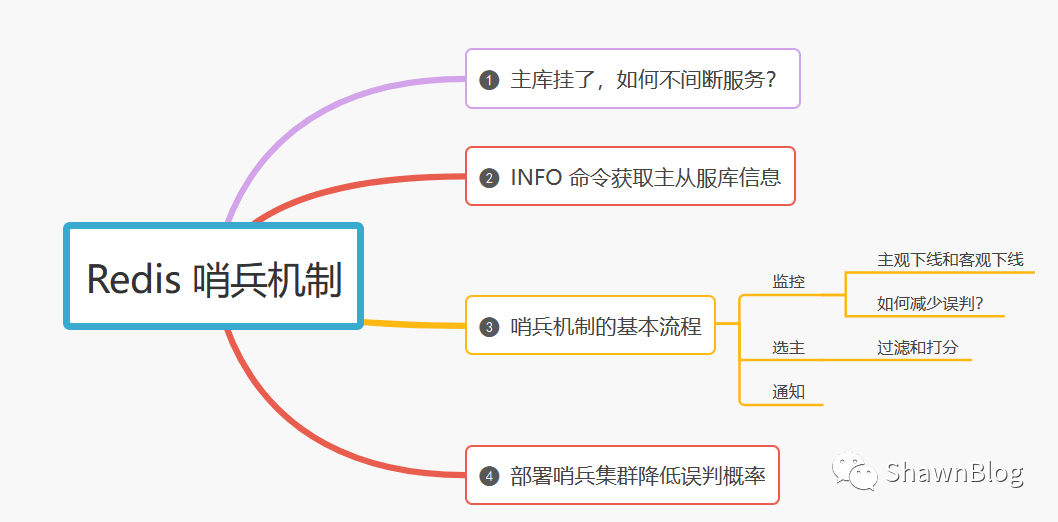
在前面的文章中,我们分析了Redis 高可用之主从复制。在这个模式下,如果从库发生故障,客户端可以继续向主库或其他从库发送请求,进行相关的操作。但是如果主库发生故障了,那直接就影响到从库的同步,因为从库没有相应的主库可以进行数据复制操作了。
如果说,客户端发送的都是读操作请求,那还可以由从库继续提供服务,这在纯读的业务场景下还能被接受。一旦有写操作请求了,按照主从库模式下的读写分离要求,需要由主库来完成写操作。此时,没有实例可以服务客户端的写操作请求,如下图所示:
所以,如果主库挂了,我们就需要运行一个新主库,比如说把一个从库切换为主库,把它当成主库。这就涉及到三个问题:
-
主库真的挂了吗?
-
该选择哪个从库作为主库?
-
如何把新主库的相关信息通知给从库和客户端?
这就要提到 哨兵机制了。
在 Redis 主从集群中,哨兵机制是实现主从库自动切换的关键机制,它有效地解决了主从复制模式下故障转移的这三个问题。
哨兵机制
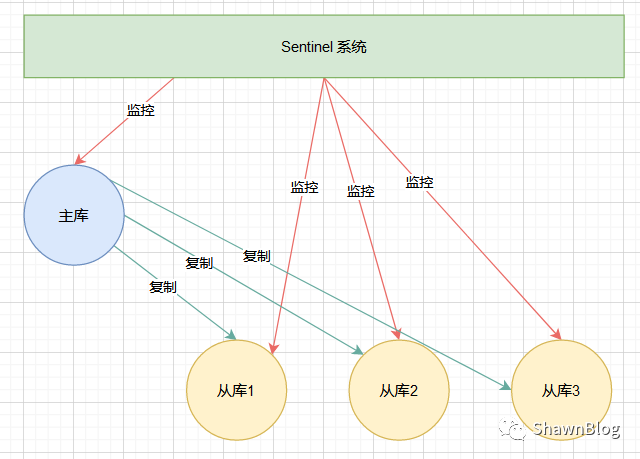
哨兵(Sentinel)是 Redis 高可用性的解决方案,它其实就是一个运行在特殊模式下的 Redis 进程,主从库实例运行的同时,它也在运行。
由一个或多个 Sentinel 实例组成的 Sentinel 系统可以监视多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求。
<<Redis 设计与实现>>
获取主服务器信息
Sentinel 通过发送 INFO
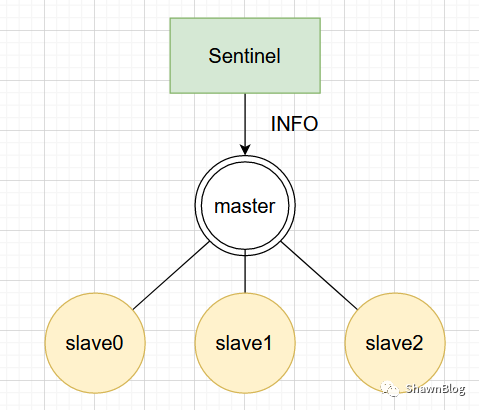
当 Sentinel 发现从库之后,Sentinel 将对 slave0 、slave1 和 slave2 分别创建命令连接和订阅连接。
创建完命令连接之后,Sentinel 会向从库发送
INFO-
从库的运行id;
-
从库的角色
-
主库的ip和端口号;
-
主库的连接状态;
-
从库的优先级
-
从库复制偏移量
根据这些信息,Sentinel 会对从库的实例结构进行更新。
了解了 Sentinel 如何获取主从库的信息之后,下面我们分析下哨兵机制的基本流程。
哨兵机制的基本流程
哨兵主要负责的就是三个任务:监控、选主(选择主库)和通知。
-
监控:通过
PING -
选主:主库挂了,在从库中按照一定机制选择一个新主库;
-
通知:通知其他从库和客户端新主库的相关信息;
我们先看监控。
监控
默认情况下,Sentinel 会以每秒一次的频率向所有主从库发送PING
Sentinel 配置文件中的down-after-millisenconds
如果一个实例在 down-after-millisenconds
细心地同学注意到了,这里说的是主观下线。其实,Sentinel对主库的下线判断有「主观下线」和 「客观下线」两种。
那么,为什么会存在两种判断呢?它们的区别和联系是什么呢?
主观下线和客观下线
主观下线:哨兵进程会使用PING
如果哨兵发现主库或从库对PING
如果检测的是从库,那么,哨兵简单地把它标记为「主观下线」就行了,因为从库的下线影响一般不太大,集群的对外服务不会间断。
但是,如果检测的是主库,那么,哨兵还不能简单地把它标记为「主观下线」,开启主从切换。因为很有可能存在这么一个情况:那就是哨兵误判了,其实主库并没有故障。
而且,一旦启动了主从切换,后续的选主和通知操作都会带来额外的计算和通信开销。为了避免这些不必要的开销,我们要特别注意误判的情况。
误判
误判就是主库实际并没有下线,但是哨兵误以为它下线了。一般会发生在集群网络压力较大、网络拥塞、或者是主库本身压力较大的情况下。
一旦哨兵判断主库下线了,就会开始选择新主库,并让从库和新主库进行数据同步,这个过程本身就会有开销。例如,哨兵要花时间选出新主库,从库也需要花时间和新主库同步。
而真实的情况是,主库本身根本就不需要进行切换的,所以这个过程的开销是没有价值的。
正因为这样,我们需要判断是否有误判,以及减少误判。
如何减少误判?
在日常生活中,当我们要对一些重要的事情做判断的时候,经常会和家人或朋友一起商量一下,然后再做决定。
哨兵机制也是类似的,我们通常会采用多实例组成的集群模式进行部署,也被称为哨兵集群。
引入多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主库下线的情况。
同时,多个哨兵的网络同时不稳定的概率较小,由它们一起做决策,误判率也能降低。
当 Sentinel 将一个主库判断为主观下线之后,为了确认是否误判,它会向同样监视这一主库的其他 Sentinel 进行询问。只有大多数的哨兵实例,都判断主库已经「主观下线」了,主库才会被判定为「客观下线」,这个叫法也是表明主库下线成为一个客观事实了。
这个判断条件在于 Sentinel 配置中设置的quorum
sentinel mointor master 127.0.0.1 6379 2那么只要有 2 个 Sentinel 认为主库已经进入下线状态,那么该主库就被判断为「客观下线」。
一般来说,当有 N 个哨兵实例时,最好要有 N/2 + 1
这样一来,就可以减少误判的概率,也能避免误判带来的无谓的主从库切换。
借助于多个哨兵实例的共同判断机制,我们就可以更准确地判断出主库是否处于下线状态。如果主库的确下线了,Sentinel就要开始下一个决策过程了,即从许多从库中,选出一个从库来做新主库。
然后是执行哨兵的第二个任务,选主。
如何选定新主库?
主库挂了以后,Sentinel 就需要从已下线的主库属下的所有从库里,挑选出一个状态良好、数据完整的从库,把它作为新的主库。
这一步完成后,现在的集群里就有了新主库。
一般来说,我们把 Sentinel 选择新主库的过程称为「筛选 + 打分」。
简单来说,我们在多个从库中,先按照一定的筛选条件,把不符合条件的从库过滤掉。
然后,我们再按照一定的规则,对剩下的从库逐个打分,将得分最高的从库选为新主库。
我们先来看看筛选条件。
筛选条件
Sentinel会把已下线主库属下的所有从库保存到一个列表中。然后按照以下规则,进行筛选:
1)、一般情况下,我们肯定要保证所选的从库仍然在线运行,所以首先就需要删除列表中处于下线或者断线状态的从库。
不过,在选主时从库正常在线,这只能表示从库的现状良好,并不代表它就是最适合做主库的。
设想一下,如果在选主时,一个从库正常运行,我们把它选为新主库开始使用了。可是,很快它的网络出了故障,此时,我们就得重新选主了。这显然不是我们期望的结果。
所以,在选主时,除了要检查从库的当前在线状态,还要判断它之前的网络连接状态。
2)、删除列表中所有最近 5 秒没有回复过INFO
3)、如果从库总是和主库断连,而且断连次数超出了一定的阈值,我们就有理由相信,这个从库的网络状况并不是太好,就可以把这个从库筛掉了。
具体怎么判断呢?
使用配置项 down-after-millisenconds * 10
其中,down-after-millisenconds
如果在down-after-millisenconds
好了,这样我们就过滤掉了不适合做主库的从库,完成了筛选工作。
打分
接下来就要给剩余的从库打分了。我们可以分别按照三个规则依次进行三轮打分,这三个规则分别是从库优先级、从库复制进度以及从库 ID 号。
只要在某一轮中,有从库得分最高,那么它就是主库了,选主过程到此结束。如果没有出现得分最高的从库,那么就继续进行下一轮。
第一轮:优先级最高的从库得分高。
我们可以通过 slave-priority
slave-priority 100比如,你有两个从库,它们的内存大小不一样,你可以手动给内存大的实例设置一个高优先级。
在选主时,哨兵会给优先级高的从库打高分,如果有一个从库优先级最高,那么它就是新主库了。
如果从库的优先级都一样,那么哨兵开始第二轮打分。
第二轮:复制偏移量最大的从库得分高。
这个规则的依据是,对具有相同最高优先级所有从库进行排序,选出其中偏移量最大也就是和旧主库数据同步最接近的那个从库作为主库。
如何判断从库和旧主库间的同步进度呢?
前面文章我们提到过,主从库同步时有个命令传播的过程。
在这个过程中,主库会用master_repl_offsetrepl_backlog_bufferslave_repl_offset
此时,我们想要找的从库,它的slave_repl_offsetmaster_repl_offsetslave_repl_offsetmaster_repl_offset
就像下图所示,旧主库的 master_repl_offsetslave_repl_offset
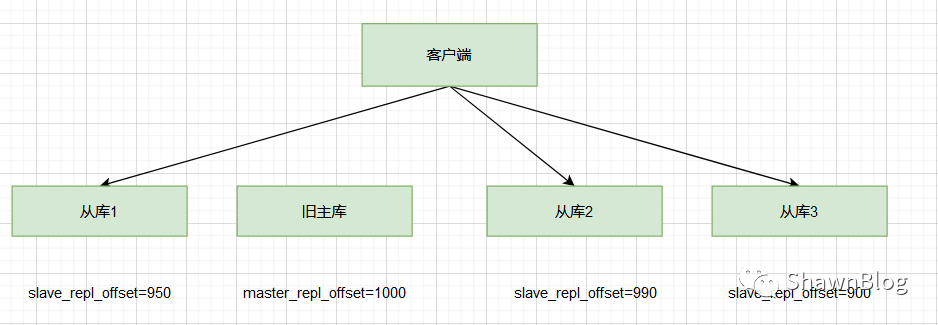
如果有两个从库的slave_repl_offset
第三轮:运行 ID 最小的从库得分高。
每个实例都会有一个 ID,这个 ID 就类似于这里的从库的编号。目前,Redis 在选主库时,有一个默认的规定:在优先级和复制进度都相同的情况下,运行 ID 号最小的从库得分最高,会被选为新主库。
到这里,新主库就被选出来了,「选主」这个过程就完成了。
我们再回顾下这个流程:
-
首先,哨兵会按照在线状态、网络状态,筛选过滤掉一部分不符合要求的从库;
-
然后,依次按照优先级、复制进度、ID 号大小再对剩余的从库进行打分,只要有得分最高的从库出现,就把它选为新主库。
通知
当新的主库出现之后,下一步,哨兵会执行最后一个任务:通知。即让已下线的所有从库去复制新的主库。
通过让从库执行slaveof
同时,哨兵会把新主库的连接信息通知给客户端,让它们把请求操作发到新主库上。并且会把已下线的主库设置为新主库的从库。


