
接口响应延迟案例分析原创
本文以实际案例介绍下:关于接口响应慢时所要排查的一些角度以及在对程序进行分析系统延迟的时候所用到的一些工具。
系统延迟的本质是由于cpu在这段时间里没有去及时的运算你的应用程序代码,导致你的应用程序代码在阻塞之后,再被调度回来的整个时间间隔会过长,从用户的角度看,就会表现为整个接口延迟会过高,响应时间过长。
造成延迟的原因,第一个是从进程内部看,有可能是你的机器的网络io或磁盘io这种阻塞操作或者是cpu的使用率 达到瓶颈之后会造成调度你的程序代码会比较慢。
第二个是调第三方系统,像mysql、redis,如果在执行查询的时候,像慢查询,整个应用程序的吞吐量肯定会有所下降的。
最近线上有个golang的应用程序会隔三差五的、晚上10点左右,总会有慢sql的报警出现,并且在平时略有高峰期,比如晚上6-9:30,偶尔也会出现sql的报警,这个报警是对sql执行时长的一个报警,sql报警是在应用程序内部通过对sql操作增加钩子函数,然后对sql前后执行的位置进行计时,对两个计时相减得到sql在我们应用程序内部执行的时间,如果时间大于1s就报警。
晚上10点正好是业务高峰期,所以很多接口偶尔出现一些sql报警并且响应时长会超过两秒。一个接口超过2秒才响应,对用户的体验是极其不好的,所以对此进行了优化。由于这个是慢sql的一个报警,所以首先看的是这个sql的写法有没有问题,有没有索引,看了下后台慢sql的查询日志,发现并没有慢sql日志打印出来,然后重新执行了这条sql,又发现它的执行时间,仍然在毫秒以内是能够完成的。
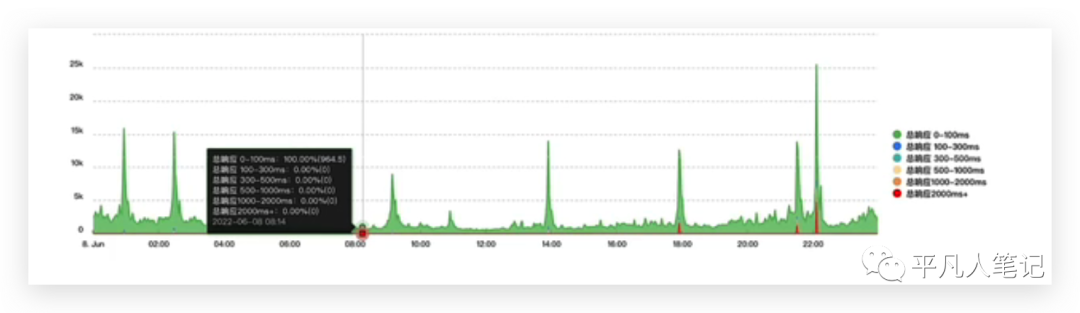
所以我的一个想法是排除掉了sql写法本身所带来的性能问题。为什么这条sql不是慢查询,但是应用程序的方法调度回来之后变慢了?所以有没有可能是系统资源达到了瓶颈之后,导致cpu来不及调度到应用程序代码,所以又去看了系统的硬件资源。
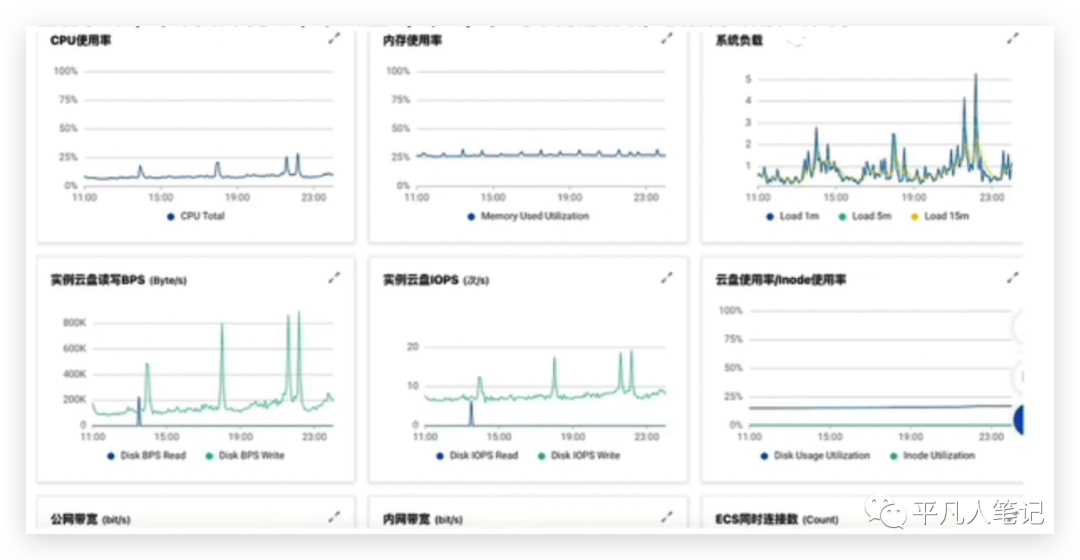
cpu使用率 、内存使用率,可以看到是在一个很低的值,线上cpu是4核,高峰期才达到25%的一个使用率,内存使用率也是基本上25%左右,没有出现过多的波动。
唯一在高峰期有一点点偏高的是系统负载,在高峰期的时候可能会超过4这个值,达到5也不足以说硬件资源达到了瓶颈。既然硬件资源没有达到瓶颈,应用程序为什么在此刻没有被cpu调度到,所以很有可能应用程序处于一种阻塞等待的状态,而这个阻塞等待是不会耗费cpu的或者说在这个阻塞等待状态的时候所执行的动作对cpu的使用并不高。
所以考虑程序是在执行一个cpu使用率不高的动作但是这个动作又不是在执行用户代码,应用程序可能会在阻塞之后,整个程序可能会再执行一个调度的动作:寻找那些可以执行的协程去执行,而这个调度的动作并不是很耗cpu的一个动作,关键要看应用程序究竟阻塞在了哪一部分,它等待在了哪一部分。
这里用到了off cpu的一个工具 fg prof,off cpu指的是能够展示出来应用程序等待cpu所消耗的时间占比,通常用go tool pprof去看cpu的时候,看的是cpu真正执行的时间。
而对于我们这个场景,它是没有意义的,因为我们的cpu使用率不高。
可能等待cpu的时间才是我们应该考虑的一个关注点,通过fg prof可以看到,占用off cpu过高的一个方法,这个方法里面其实是在进行一个sql的操作,
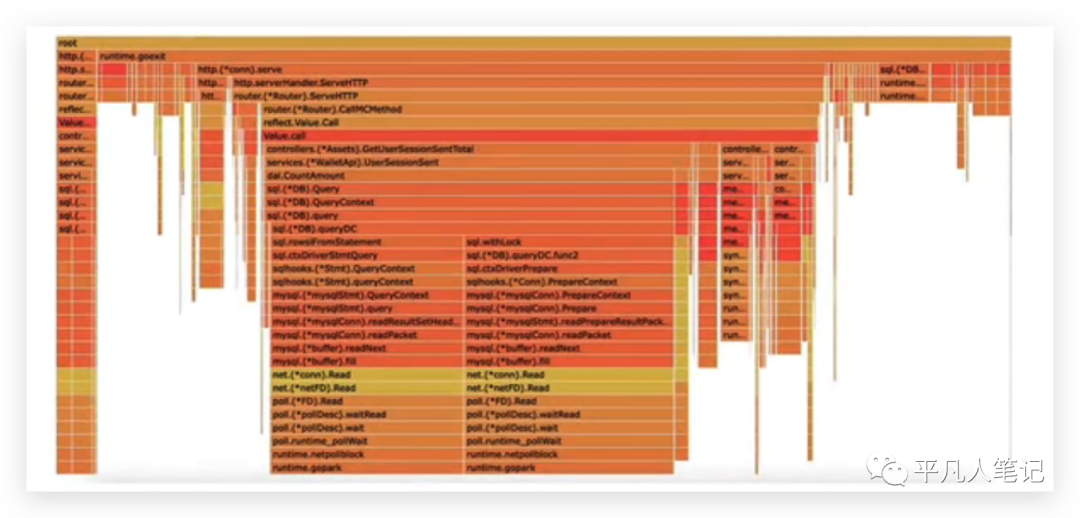
但是这个sql的操作并不是由于慢查询到的,它可能是由于withLock,一般我们加锁应用程序,很可能就会陷入阻塞,并且通过跟mysql的一个读写操作,涉及到了网络io的部分,那这个网络io和withLock所占用的等待cpu的时间会占一个很大的比例,所以这里就初步判定了很有可能是由于这个接口在高频的进行这种阻塞操作的代码,导致了这个接口在对外暴露的时候,有一部分接口响应时间会超过两秒。
然后用更精细的工具去看系统延迟的时间,因为仅仅通过fg prof去看系统延迟的时候,可以知道这部分代码在off cpu占了大部分时间,但是具体占用多少时间,通过fg prof还是无法分析出来的,这里是为了百分之百的确定的确是这部分代码导致的问题。用了golang官方提供的go trace这个工具,go trace能够将应用程序此时一个状态并且执行的情况完整的给你展示出来并且记录程序在执行动作的时候所消耗的时长。通过go trace我们得到了这样的图,
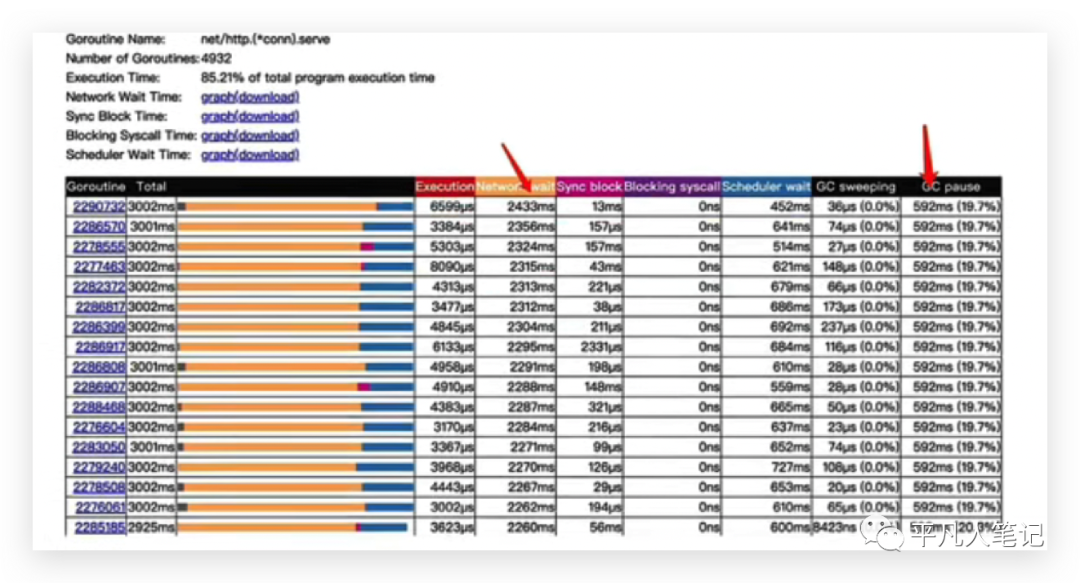
进行了3秒的采样,最左边是协程编号, 这个协程网络等待时间在三秒以内的话,都达到了两秒多,所以可以看到网络等待时长其实是很长的。
这里不能仅仅因为网络的io就判定这个协程是由于网络等待io所造成的阻塞,首先要明白网络等待io算法的原理:网络等待io它是在进行调度网络io代码的时候,会记录下此时协程的时间,并把协程从p队列拿下来,然后异步的等待epoll回调通知,等到文件描述符可读之后,它会把这个协程再加入到p队列,这个时候重新执行调度函数。
所以网络等待时间就是从p队列拿下来到加入到p队列的时间间隔,协程真正会再次被调度的时候是要等待这个图里面的scheduler wait时间,才会真正的被执行、被cpu调度到。
为什么说一个协程仅仅看网络等待时间不能判定是由于网络等待时间所造成的阻塞?是由于一个协程可能会执行多次请求,因为开了keepalive之后,一条连接是能够执行多次请求的,而在golang http服务里面的一个连接是对应一个协程,一个协程很有可能是在for循环里面,频繁的去等待着连接可读,所以造成了等待时长增加,而等待下一次请求这个时间间隔的网络io时间,是不会影响你的整个接口变慢的,所以除了要看网络等待时间,也可以去看看其他指标。
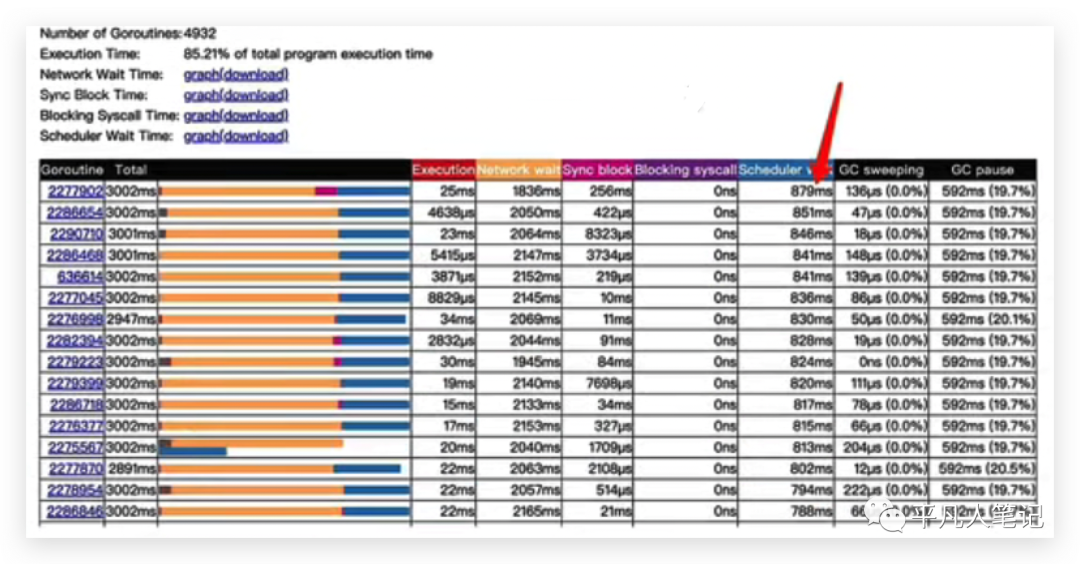
在这里将scheduler wait进行了从大到小的排序之后,可以看到三秒钟以内还是有一些协程,它们的一个等待调度时间都达到了800多毫秒,阻塞的时长也是能够达到700多毫秒,这样的占比,肯定会导致我们的请求会带来更大的延迟,因为保不准这个协程在执行请求的时候,它可能等到被调度的时候,会再去等待一个800毫秒才会真正的去执行你的代码,而整个响应延迟超过2秒也很常见了。
由于我们是在进行频繁的一个网络请求和一个阻塞操作 wthLock,可以将这部分操作完全的放到内存里面来,这样就能够减少对数据库的网络请求,减少因数据库产生的withLock操作带来的阻塞问题,
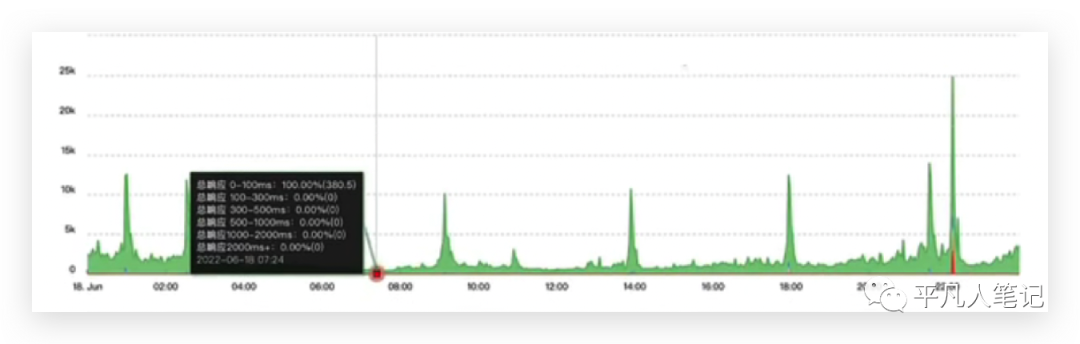
优化了这部分代码之后,晚上6点到9点半这部分响应时间超过两秒的接口已经不存在了,但是在10点的时候还是有部分接口时超过2秒的,后来经过排查发现,由于我们的线上机器同时了部署了多个其他服务,由于其他服务影响导致的,所以后续可能还会做继续的优化,让其他服务的接口处理能力提升上去或者将进程资源进行隔离。


