
磁盘IO异常排查案例原创
问题现象
服务使用的是golang语言,跟mysql数据库打交道用的是go-mysql-driver,当时系统的测试环境频繁的爆出一个invalid connection的错误,但实际上拿这个sql执行的时候却是正常执行的,也是在正常时间返回的。
问题分析
首先由于报的是无效连接的错误,首先考虑到是不是客户端使用了一个过期的连接,由于mysql的服务器端还有客户端都能够去配置各自连接的一个最大生命周期,那如果客户端配置的一个连接最大生命周期大于服务端,并且客户端自身又没有这种无效连接重试的机制,服务端在连接过期之后,客户端有可能是使用到了过期的连接,从而引发了这种无效连接这种错误。
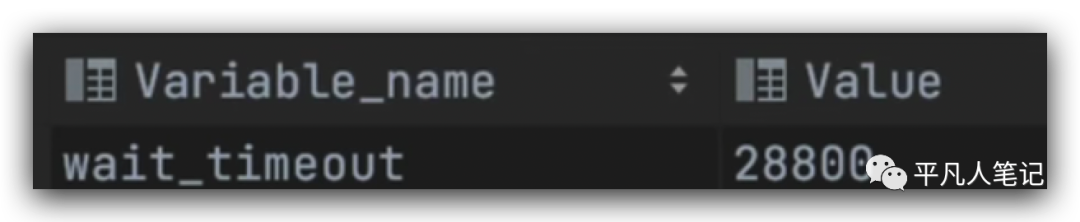
mysql服务器端的最大生命周期,
show global variables like 'wait_timeout';
这是以秒为单位的。
客户端最大生命周期配置,

这里配置了1个小时,所以mysql服务器的一个最大生命周期是大于golang客户端的最大生命周期,所以客户端始终使用的是一个有效连接,所以排除了客户端使用无效连接导致的invalid conn错误。
这种异常当时排查到这里的时候一时间没有思路,但是由于想到这个是和连接有关的一个问题,所以我直接进行了抓包,去看这个连接到底是断在了哪个地方。
在服务器上面,用tcpdump去dump下来这个pcap文件,用wireshark打开这个pcap文件,通过wireshark能够对抓到的包做一个整体的分析,
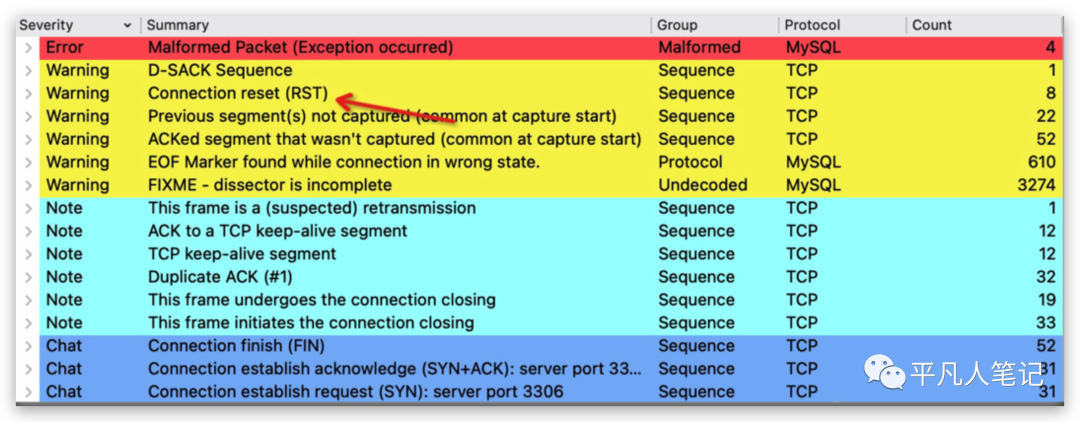
这里着重看一下抓到的包当中有八个rst的这种信号包,产生rst的话一定是属于异常情况产生的,在正常的三次握手还有四次挥手的过程当中,如果连接正常的打开或者是关闭,是不可能会产生rst的。
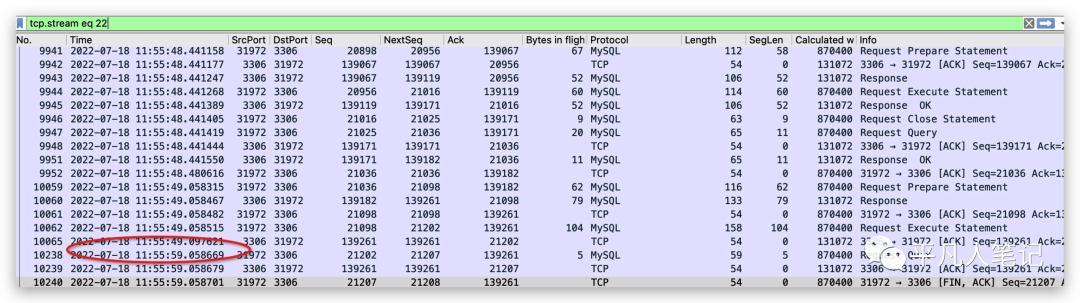
所以这里看了一下rst包产生的上下文,通过抓取到的一个连接,然后看到最底部产生了一个rst,并且发现到了一个比较令人困惑的一个点,可以看到这里我圈出来的地方,在mysql服务端回应了客户端一个ack之后,客户端隔了十秒钟才回送了一个request quit信号给mysql服务器,这个request quit是一个mysql协议里面规定的一条命令,它能够把当前连接关闭掉,所以这里是客户端经过十秒钟之后主动断开的连接,
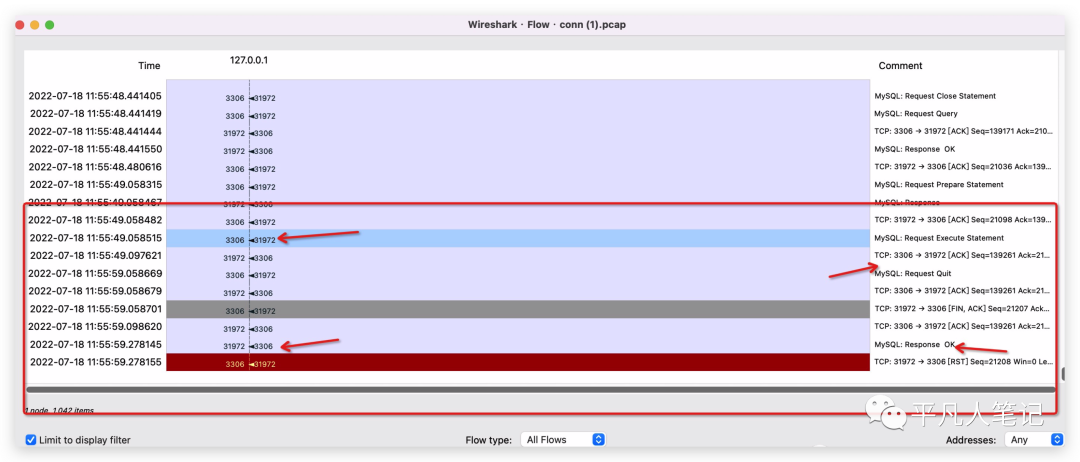
用wireshark的flow graph详细的看了一下,相比于之前那个图,能够更加清晰的看一下这个包的数据传递过程,
首先是客户端在11:55:49秒的时候,向mysql发起了一个request execute statement的命令,这个命令是执行一条sql语句,mysql回复了一个ack,但是mysql并没有把执行的结果返回给客户端,所以客户端在等待了十秒钟之后,它主动关闭掉连接,然后mysql是在11:55:59的时候,才会回复给了客户端,但这个时候客户端的连接已经关闭了,所以对已经关闭的连接里发送数据就会触发rst的信号,客户端回应给服务器一个rst的信号,所以看到这一步的话,已经是可以很明确的确定是mysql服务器sql超时了或者说是mysql服务器执行sql很快,但是mysql服务器返回给客户端的时候这一段网络传输的距离导致了网络超时,但是由于我们这个是测试环境,mysql和应用服务是部署在同一台机器上面的,所以排除了这种情况,只能是mysql服务器执行超时了,那再来进一步看是不是由于mysql执行sql的超时而导致的invalid conn这种报警,所以要回到golang的客户端代码去看,
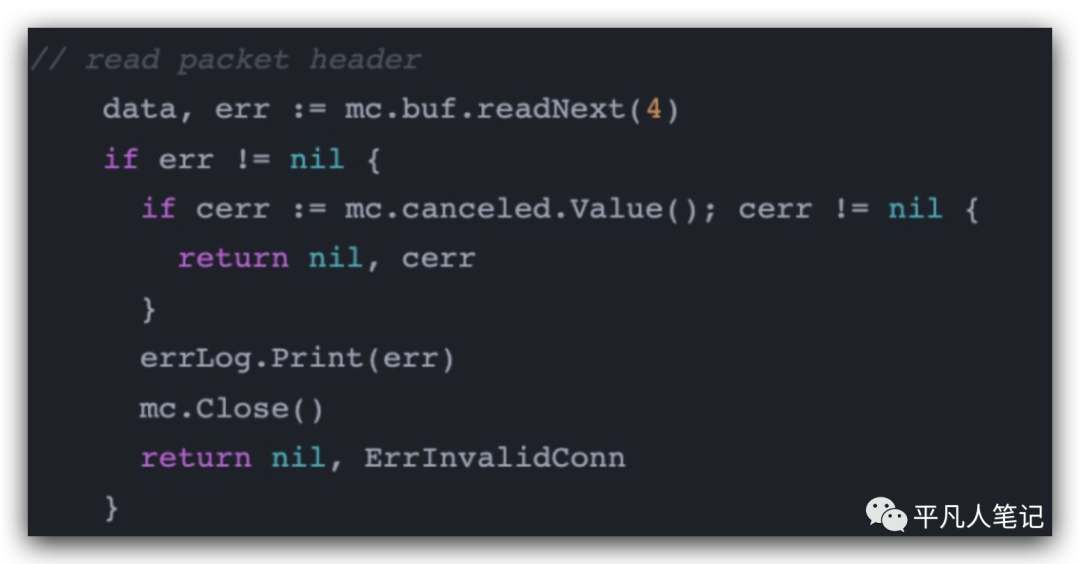
找到了golang在read packet的一段代码通过mc.buf.readNext能够去读连接的下一个四个字节,紧跟着readNext里面的代码,有一段超时逻辑,设置了timeout超时时间,

而这个时间是我们在配置客户端的时候设定的十秒钟,所以看到这一步,已经可以很明确的看到的确是由于超时导致了客户端报警错误。
其实golang的client在这个时候报超时错误可能会更好,而不仅仅是报invalid conn这种错误,因为这个错误看起来好像是这个连接无效而并不是由于服务端执行sql超时导致,这里也是一个比较迷惑的点。
找到了是由于mysql在执行sql超时了,我们得找到根本原因是什么因素导致mysql执行sql时间过长了,因为mysql是数据库,所以首先想到了磁盘,当磁盘io的使用率比较高的时候,肯定会对数据库在读取数据的时候有影响,
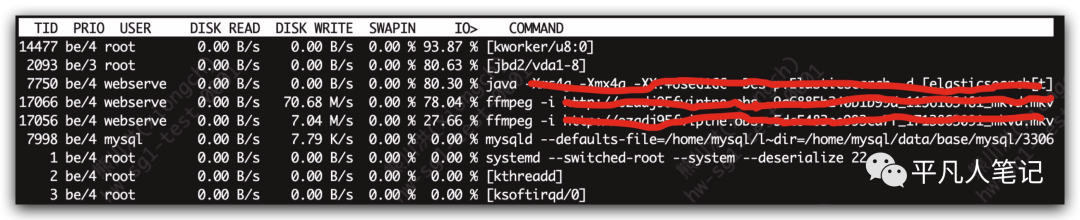
所以用top或iostat、iotop命令去分析系统的指标,用iotop看io使用率最高的进程的时候,发现了几个比较异常的点,可以看到ffmpeg有两个进程io使用率都飙到很高了,还有一个java进程使用率也是飙到很高,所以看到这一步之后,已经能够完全的确定是由于磁盘io使用率过高导致了mysql的执行数据受到了影响,在正常服务器上面的io使用率在大多数时候都会在百分之几这样一个状态,不可能像持续的两三个进程跑在了百分之七八十或者接近100%这种状态,所以在发现了这种问题进程之后,经过确认发现这两个进程其实是一个视屏转码的一个功能,然后测试环境是可以暂时关闭这种转码功能的,所以对这个转码功能进行了关闭,关闭之后,mysql就再也没有报警了。
其实在之前看抓包的时候,看到mysql返回超时的时候,其实就应该立即去看系统io这种硬件指标了,这里由于是测试环境,我还特意看了一下go-mysql-driver的代码做进一步的确认是否是超时导致的invalid conn异常,在整个排查问题的过程之后,有了如下反思:
1、测试环境的监控体系还不够完善,没有监控界面不然能够一眼就看出磁盘io的异常
2、回归到应用层看代码的时机在整个排查问题过程当中是处于一个比较靠后的状态,最主要的原因是因为我被invalid conn这个错误码所迷惑了,如果这个时候报timeout超时的错误,可能我会立马去看mysql执行时长这么一个问题,而不会去定位到可能是由于mysql客户端的一个连接无效或者是网络情况这种导致无效连接的情况
3、然后最重要的一点是我在排查问题当中忽略了一个点,当时这个报警,它是一个频繁报警的状态,但不是每时每刻都在报,最开始在碰到这个问题的时候,其实也是先有用top还有iostat这种工具去分析磁盘的一个占用情况,但是由于那段时间内指标是没有异常的,加上这个报错又是一个无效连接的报错,所以想当然的认为,这个问题应该是在网络连接上出了问题或者是mysql客户端这个连接的确是一个无效的连接,后来进行了抓包分析,所以在看这种偶发性的异常,这种报警的时候,应该持续性的去观察这个系统指标,我当时只看了十几秒钟觉得没有问题就去分析其他因素了,其实应该是一直持续不断的去看这个系统的硬件指标,直到报警再次出现,然后看报警出现后这些硬件指标会不会有异常情况,这也是我在整个排查问题的过程当中犯的一个最严重错误。
测试环境开启慢日志
set global slow_query_log=1
查看开启状态
show variables like 'show_query%'
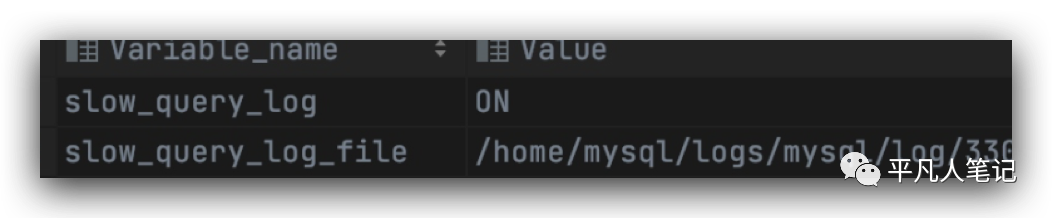
开启了测试环境的慢日志,便于之后再碰到这种超时的情况,能够直接通过慢日志去看mysql执行sql的时长,而不用再去抓包进行分析。
开启慢日志的命令set global可以给mysql的一些变量属性赋值,但是这个值是会在mysql重启之后失效的,要想不失效,要去改mysql的cnf的配置文件,改完之后,可以通过show variables like命令去看一下慢日志是否开启并且慢日志的记录文件也会输出来。


