
一次有趣的 DNS 导致 Node 服务故障问题分析实录原创
问题描述
有一个部署 k3s 的边缘节点的机器,切到离线模式以后,有一个前端页面的部分请求接口异常了。node 部分的请求分为两类,一种是纯 node 的处理,一种是需要先 http 请求后端微服务的处理接口。现象是涉及 Node 请求后端 Java 服务的都 block 住了,纯 node 处理的请求都飞快返回了。
首页请求如下:
| 请求 url | 是否请求 java 后端 | 功能 |
|---|---|---|
| http://172.20.111.30:3300/ | 否 | 首页 |
| http://172.20.111.30:3300/xxx.js(.css/.jpg) | 否 | 首页资源 |
| http://172.20.111.30:3300/captcha/generate | 是 | 图形验证码 |
对应的页面如下
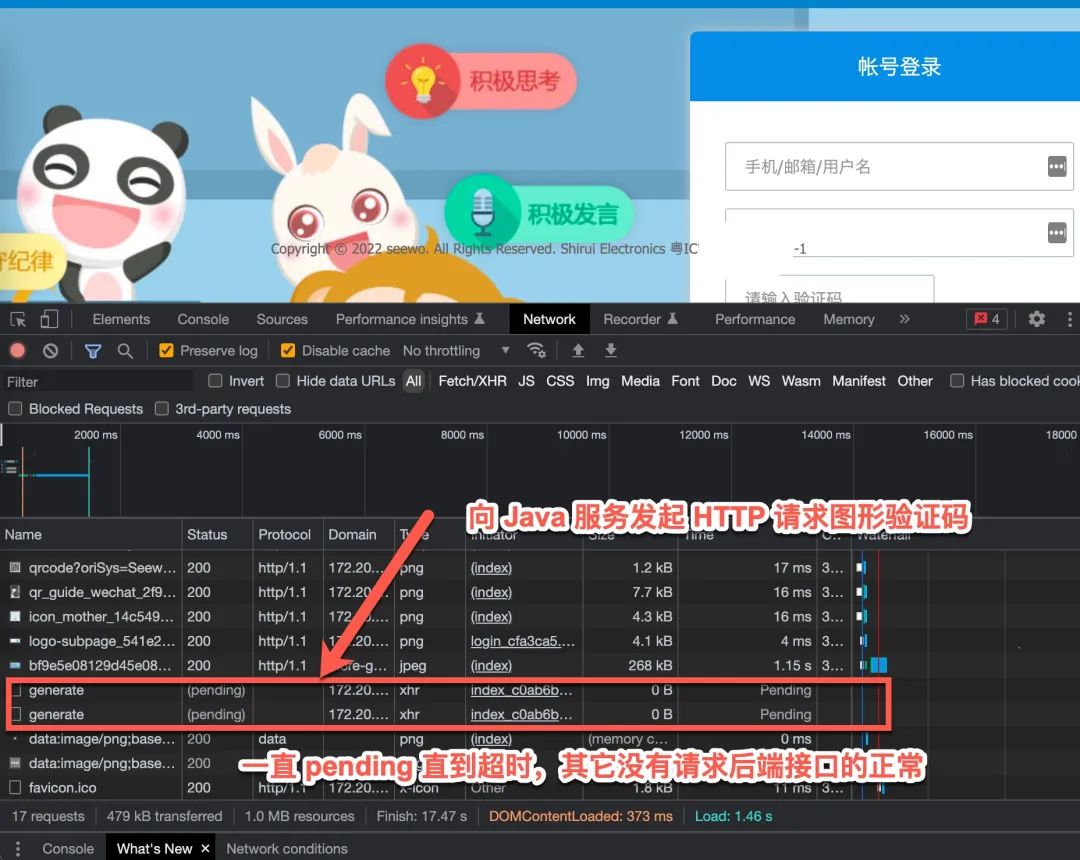
简单的调用拓扑如下。
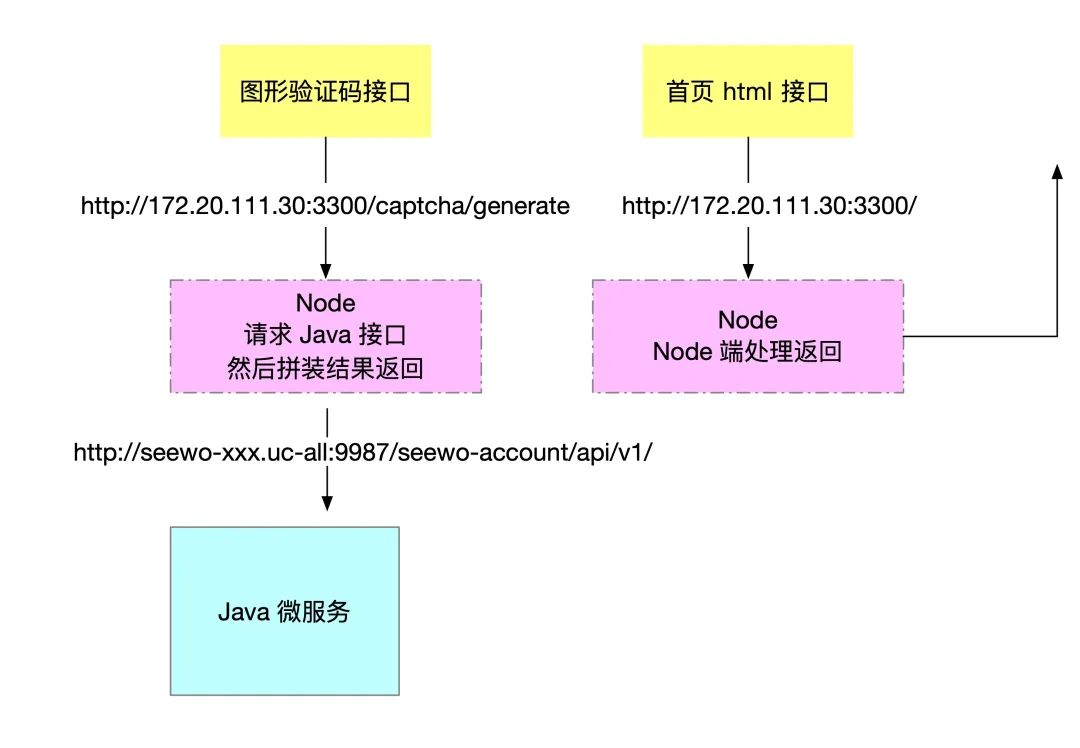
于是帮忙一起分析了一下,处理的过程如下。
遇事不决先抓包
对于一个非自己开发维护的项目,遇到这种调用关系的问题,第一反应是抓包,看看有没有请求,以及请求是否有返回。
使用 tcpdump 抓包以后,发现 node 对 Java 的 http 调用没有发生,甚至没有握手建连的包,但是经之前业务的同学为了排查已经打了日志,代码逻辑确实已经走到了 http request 发起的地方,有日志为证,也就是 http 库的函数的调用是有实际发生的,但是为什么没有请求,甚至没有建连。
有几种可能,一种可能是连接池满了,这种情况下,http 调用 block 在连接池的获取处,但是经过 netstat 查看一个连接都没有,排除了连接池满导致的问题。
到这里我大概已经猜到是什么原因了,连接没有发起,那就有可能是在连接之前出了问题,发起连接的前提是知道对端 ip 才能 tcp 三次握手,也就是 DNS 如果没有拿到结果,那么握手是一定不可能发生的。
GDB 进一步清晰问题方向
为了分析这个问题,特意修改了基础镜像,在镜像中安装了一个 gdb,用来调试 Node,在复现问题以后,我 attach 上去看了一下线程的 stack。
gdb attach 7
set pagination off
thread apply all bt
果然发现有两个线程长时间处于 getaddrinfo DNS 处理阶段。
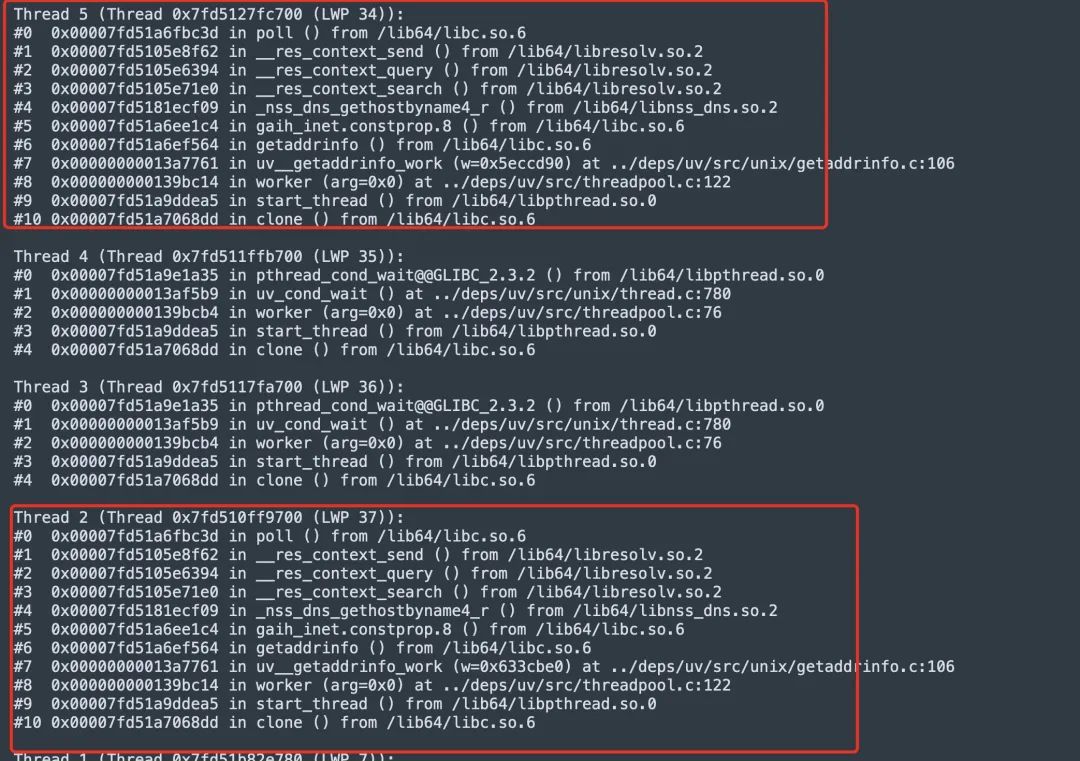
这里的堆栈内容我们后面来详细讲述,现在先不展开。
DNS 问题分析
于是转向抓取 DNS 的包,很快得到失望的结果,seewo-xxx.uc-all 域名的 DNS 的请求也没有发起。
如果这个域名的 DNS 请求有发起,但是结果不对或者没有返回,那可以去找 coredns 的问题。但是这里情况是 DNS 请求都没有发起,那还不能甩锅到 coredns 那里。

到这里没办法,老老实实去下一份对应 Node 版本的源代码,去看 DNS 部分是如何处理的。
libuv 源码分析部分(不感兴趣的桶子们跳过)
这部分源码挺有意思,可读性也很好,待我细细道来。libuv 是一个跨平台、高性能、事件驱动的 IO,起初是转为 Node.js 设计的,提供了跨平台的文件 I/O 和线程功能。
它的主要模块如下。
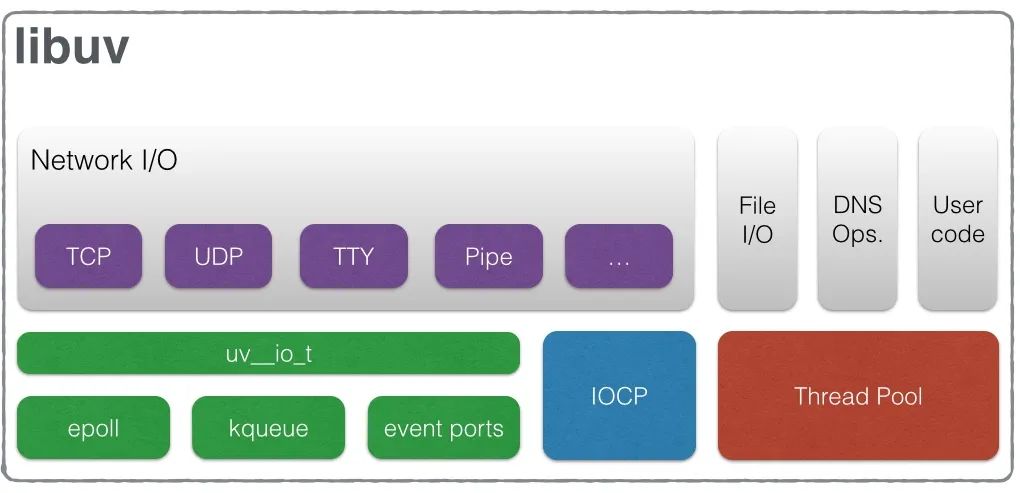
通过这个图可以看到 libuv 对于网络事件的处理和文件 IO、DNS 的处理是不一样。DNS 的处理使用的是线程池,具体的逻辑后面会介绍。
Node 的 DNS 解析不是自己实现的,而是省事直接用了系统方法 getaddrinfo,这个函数的签名如下
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>
int getaddrinfo(const char *restrict node,
const char *restrict service,
const struct addrinfo *restrict hints,
struct addrinfo **restrict res);
不幸的是,getaddrinfo 的实现是同步阻塞的,这与 Node 的异步显然是不搭的,于是 Node 使用线程池来调用 getaddrinfo,模拟异步。
这部分逻辑是 Node 的核心依赖 libuv 实现的,libuv 是一个基于事件驱动的异步 io 库,本身的事件循环部分是单线程的,如果出现阻塞或耗时的操作,不可以阻塞主循环。于是 libuv 实现了一个线程池来处理阻塞、耗时的操作,比如 DNS 等。
线程池初始化
初始化线程池的逻辑在 deps/uv/src/threadpool.c 的 init_threads 方法中。libuv 默认会开启 4 个线程,可以通过 UV_THREADPOOL_SIZE 环境变量修改,最大不能超过 1024,然后初始化了 3 个队列,然后创建并启动线程。
static uv_thread_t default_threads[4];
#define MAX_THREADPOOL_SIZE 1024
static void init_threads(void) {
nthreads = ARRAY_SIZE(default_threads); // 默认 4 个线程
val = getenv("UV_THREADPOOL_SIZE");
if (val != NULL)
nthreads = atoi(val);
if (nthreads > MAX_THREADPOOL_SIZE)
nthreads = MAX_THREADPOOL_SIZE; // 最大不超过 1024
// 这里很关键,初始化了三个队列
QUEUE_INIT(&wq); // 主队列
QUEUE_INIT(&slow_io_pending_wq); // SlowIO队列
QUEUE_INIT(&run_slow_work_message); // 特殊标识节点
// 这里真正创建线程
for (i = 0; i < nthreads; i++)
if (uv_thread_create(threads + i, worker, &sem))
abort();
// 等所有线程启动完然后继续执行
for (i = 0; i < nthreads; i++)
uv_sem_wait(&sem);
}
libuv 将任务分为三大类型,CPU 型、FastIO 和 SlowIO,我们这的 DNS 请求就属于 SlowIO 这一类,文件操作属于 FastIO。
enum uv__work_kind {
UV__WORK_CPU,
UV__WORK_FAST_IO,
UV__WORK_SLOW_IO
};
这里对几个核心的变量做一些说明
-
wq:任务主队列,用于处理 UV__WORK_CPU和UV__WORK_FAST_IO,收到此类任务,就将其出入到此队列的尾部,然后唤醒 worker 线程去处理 -
slow_io_pending_wq:用于处理 UV__WORK_SLOW_IO,收到 SlowIO 类型的任务插入到此队列 -
run_slow_work_message:特殊标识节点,用于表示存在 SlowIO 时,会将这个作为一个标识节点放入主队列 wq 中,当 SlowIO 类型请求所有都处理完毕时,将这个标记节点从 wq 中移除
线程池中任务的生产和消费
任务产生具体的逻辑在 deps/uv/src/threadpool.c 的 post 方法中。post 方法的主要功能是下面这些:
-
如果任务是 SlowIO,则任务插入到 slow_io_pending_wq 队尾,同时在主队列 wq 中插入特殊标识节点 run_slow_work_message,告诉主队列这里有一个 SlowIO 要处理。 -
如果不是 SlowIO 就简单的将任务插入到主队列 wq 尾部
随后就是唤醒空闲线程起来干活,处理任务。
static void post(QUEUE* q, enum uv__work_kind kind) {
if (kind == UV__WORK_SLOW_IO) {
// 如果是 SlowIO 任务,就插入到 slow_io_pending_wq 中
QUEUE_INSERT_TAIL(&slow_io_pending_wq, q);
if (!QUEUE_EMPTY(&run_slow_work_message)) {
uv_mutex_unlock(&mutex);
return;
}
q = &run_slow_work_message; // 特殊消息节点 run_slow_work_message,给主队列 wq 插入一个特殊的标识节点 run_slow_work_message,告诉主队列这里有一个慢 IO 任务队列需要处理
}
QUEUE_INSERT_TAIL(&wq, q); // 不管什么任务,都入队尾
if (idle_threads > 0)
uv_cond_signal(&cond); // 唤醒空闲线程起来干活
}
任务的消费在 deps/uv/src/threadpool.c 的 worker 方法中。worker 方法的主要作用就是从队列中窃取任务执行。如果是 SlowIO,需要做的一个处理是控制 SlowIO 的线程数不超过线程池大小的一半。
static void worker(void* arg) {
// ...
for (;;) {
/* `mutex` should always be locked at this point. */
/* Keep waiting while either no work is present or only slow I/O
and we're at the threshold for that. */
// 当队列为空或 SlowIO 任务个数达到阈值(2)时,进入阻塞等待唤醒
while (QUEUE_EMPTY(&wq) ||
(QUEUE_HEAD(&wq) == &run_slow_work_message &&
QUEUE_NEXT(&run_slow_work_message) == &wq &&
slow_io_work_running >= slow_work_thread_threshold())) {
idle_threads += 1;
uv_cond_wait(&cond, &mutex);
idle_threads -= 1;
}
// ...
w = QUEUE_DATA(q, struct uv__work, wq);
// 调用 SlowIO 真正的逻辑,DNS 解析线程会阻塞在这里
w->work(w);
// 执行完 SlowIO 任务,slow_io_work_running 计数减一
if (is_slow_work) {
/* `slow_io_work_running` is protected by `mutex`. */
slow_io_work_running--;
}
}
}
在我们这里 SlowIO 线程数阈值等于 2,计算方式如下。
static unsigned int slow_work_thread_threshold(void) {
return (nthreads + 1) / 2; // (4+1)/2=2
}
当 SlowIO 任务的个数达到两个时,当前处理 SlowIO 的线程会阻塞等待 SlowIO 有任务完成。
这样就可以避免出现 SlowIO 任务把所有的线程池占满,导致其它类型的任务没有机会执行。
问题分析
回到我们最初用 GDB 捞到的线程栈
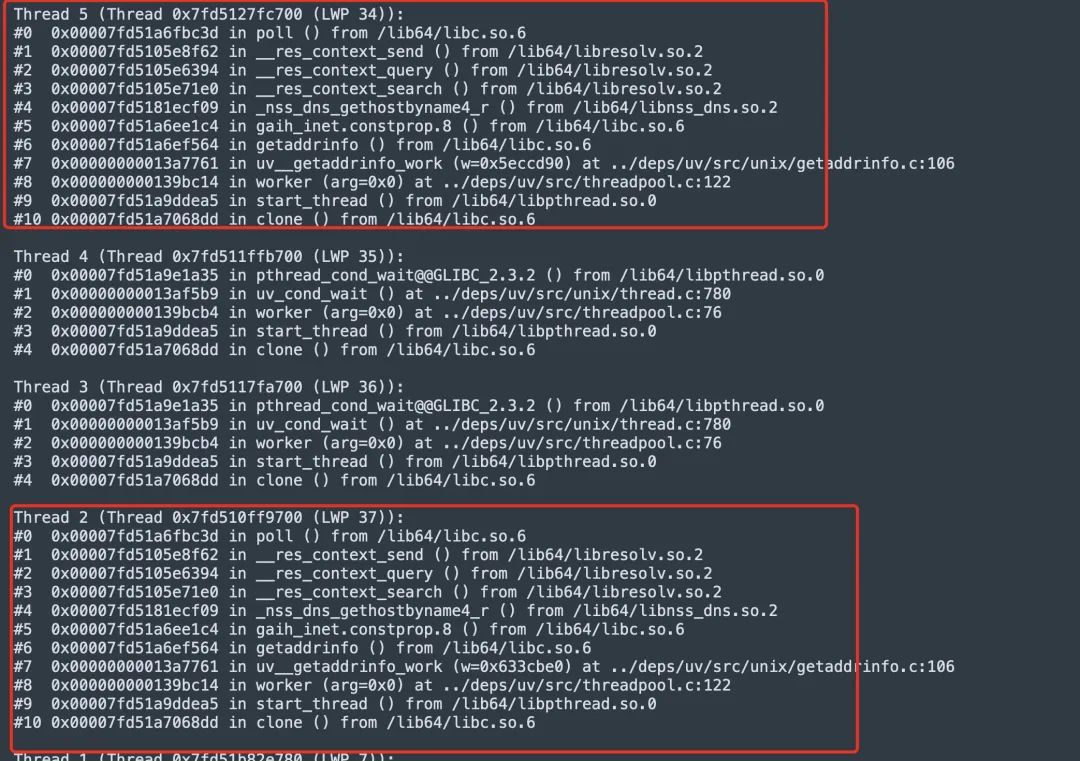
确实如源码中所指向的一样,threadpool 阻塞在 worker 方法调用,worker 内部同步调用了 getaddrinfo 这个同步阻塞接口。而且确实有两个 SlowIO 的任务阻塞了,这样后面 DNS 请求就没有机会执行了。
但是还是没能解释,为什么我们请求后端的域名 seewo-xxx.uc-all 没能进入 SlowIO 队列中进行 DNS 解析呢?这个域名的解析是 OK 的。那只有一个可能了,就是这两个 SlowIO 的线程在解析别的域名,长时间拿不到结果。
空口无凭,还是要靠证据。
GDB 确认问题
在 GDB 中,我们可以通过 thread + 线程号 切换到 SlowIO 处理的线程,也就是阻塞在 getaddrinfo 的线程。
Thread 2 (Thread 0x7fd510ff9700 (LWP 37)):
#0 0x00007fd51a6fbc3d in poll () from /lib64/libc.so.6
#1 0x00007fd5105e8f62 in __res_context_send () from /lib64/libresolv.so.2
#2 0x00007fd5105e6394 in __res_context_query () from /lib64/libresolv.so.2
#3 0x00007fd5105e71e0 in __res_context_search () from /lib64/libresolv.so.2
#4 0x00007fd5181ecf09 in _nss_dns_gethostbyname4_r () from /lib64/libnss_dns.so.2
#5 0x00007fd51a6ee1c4 in gaih_inet.constprop.8 () from /lib64/libc.so.6
#6 0x00007fd51a6ef564 in getaddrinfo () from /lib64/libc.so.6
#7 0x00000000013a7761 in uv__getaddrinfo_work (w=0x633cbe0) at ../deps/uv/src/unix/getaddrinfo.c:106
#8 0x000000000139bc14 in worker (arg=0x0) at ../deps/uv/src/threadpool.c:122
#9 0x00007fd51a9ddea5 in start_thread () from /lib64/libpthread.so.0
#10 0x00007fd51a7068dd in clone () from /lib64/libc.so.6
我们通过 frame 7 切换到第 7 个栈帧,也就是切换到 deps/uv/src/unix/getaddrinfo.c:106:uv__getaddrinfo_work 这个函数:
static void uv__getaddrinfo_work(struct uv__work* w) {
uv_getaddrinfo_t* req;
int err;
req = container_of(w, uv_getaddrinfo_t, work_req);
err = getaddrinfo(req->hostname, req->service, req->hints, &req->addrinfo);
req->retcode = uv__getaddrinfo_translate_error(err);
}
这里有一个 req 变量,我们就可以通过 p *req 查看这个 req 变量,它的类型为 uv_getaddrinfo_t,里面就有字段表示当前 DNS 请求的域名是什么,可以看到这里的域名不是我们的目标域名 seewo-xxx.uc-all,而是 myou.cvte.com,这个域名请求的哪里来的,我们后面来分析。
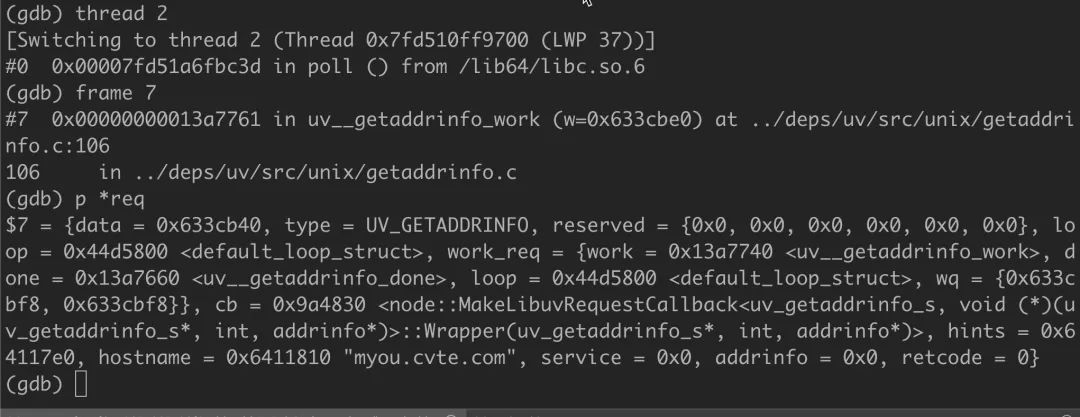
我们切换到另外一个 SlowIO 的 5 号线程,使用同样的方式,可以看到也是 myou.cvte.com 的域名。
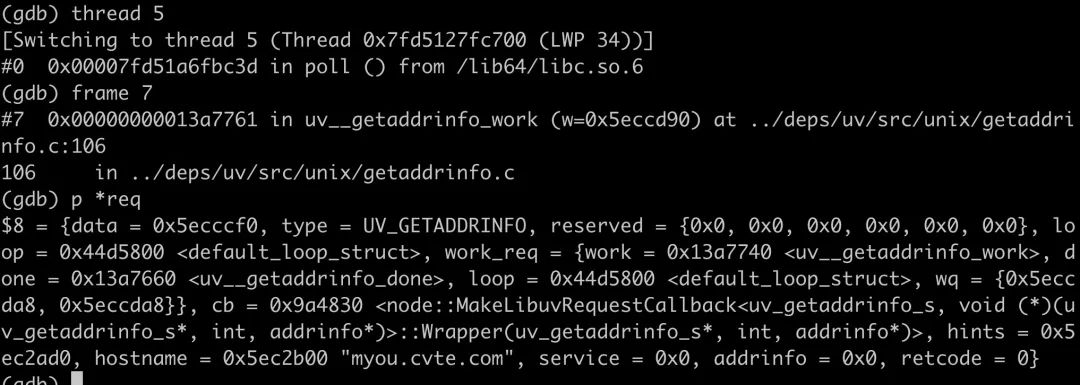
那是不是这个域名的请求,一直没有正确结果的返回,导致占满了 SlowIO 的 2 个线程呢?
通过 DNS 抓包,可以确认这个域名的 DNS 请求耗时非常久,而且一直没有返回正确的结果(要么 Nosuch name,要么 Server failure)。
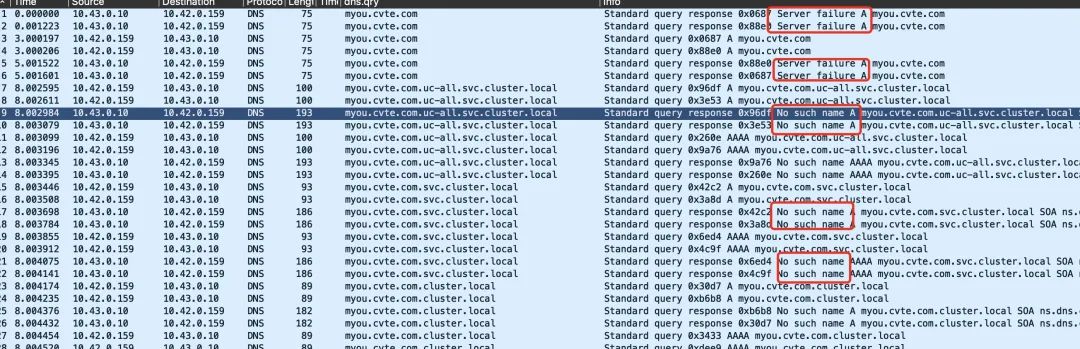
到这里,我们只需要去看代码,哪里触发了 myou.cvte.com 相关域名的这个请求即可。通过简单的看代码,发现首页接口 http://172.20.111.30:3300/ 里面调用了 redis 相关的接口
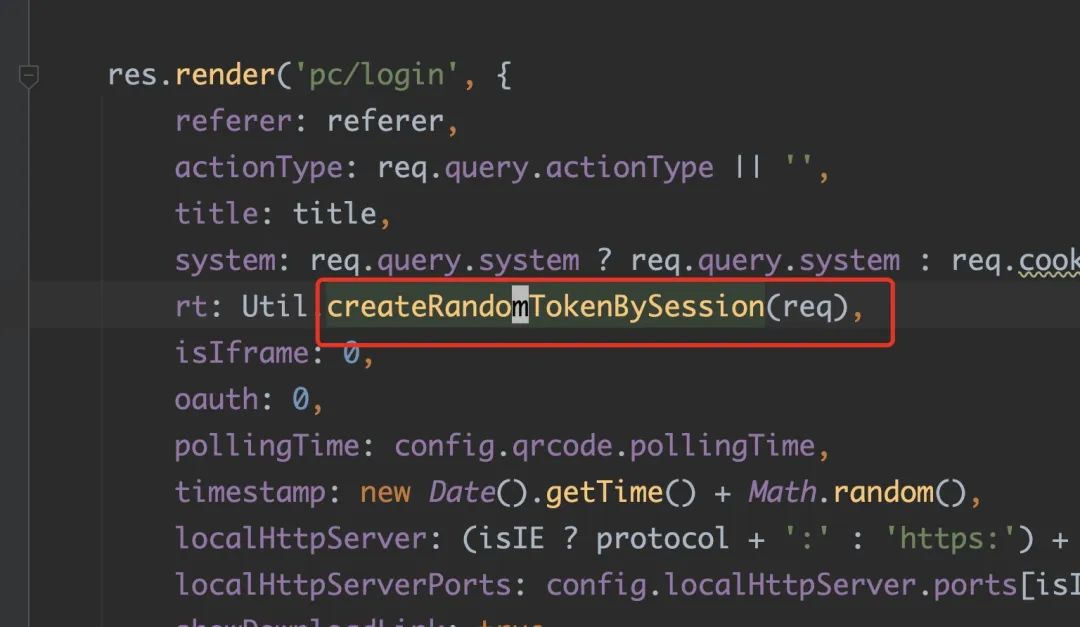
createRandomTokenBySession 这个函数内部调用了两次 Redis
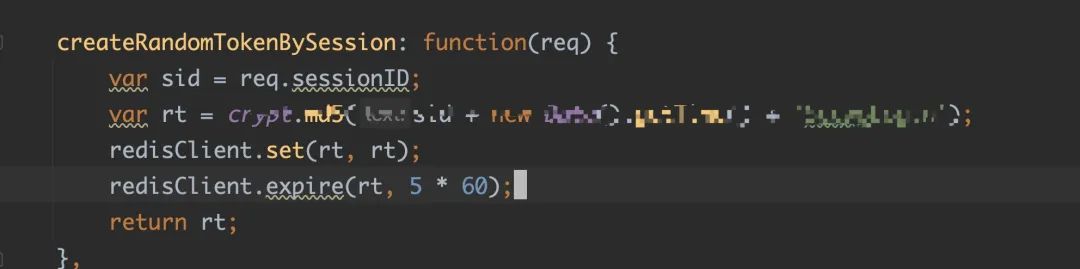
很不幸,这两次 Redis 操作因为配置的问题都失败了,通过日志可以确认。

我们自己封装的 redis 库在失败时会把错误信息尝试上报给 myou.cvte.com 相关的接口。
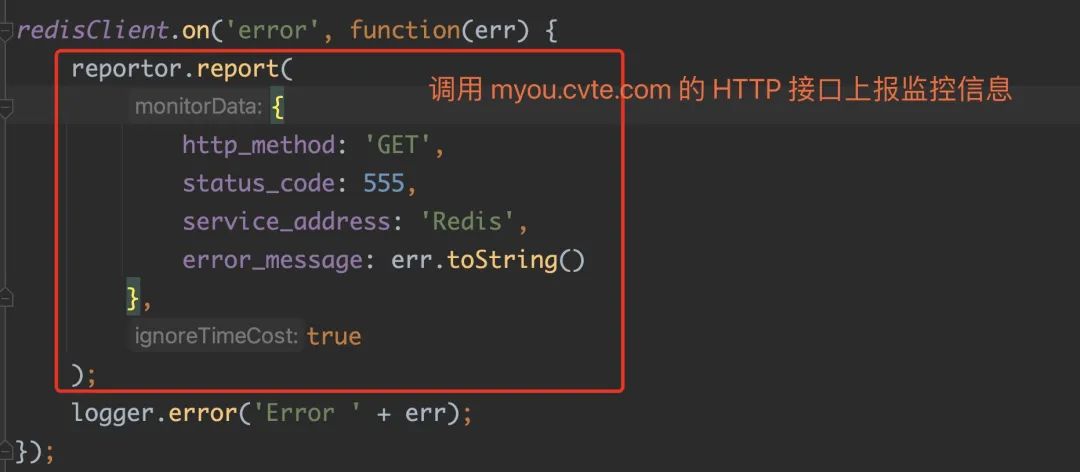
到这里,原因就非常清楚了。
首页请求,会访问两次 Redis,这两次 Redis 都失败了,然后会造成两次 myou.cvte.com 接口的请求,这里会触发两次 myou.cvte.com 域名的解析,又因为 myou.cvte.com 域名解析迟迟没有返回,把 Node 内部的 libuv 的两个 SlowIO 线程占满,导致后续所有的 DNS 请求都无法继续进行下去。
知道了原因就很好修改了,因为是离线部署,这里的上报很多余,直接去掉是最快的方式。还有一种可能的改法是调大线程池大小 UV_THREADPOOL_SIZE,都可以尝试。
当然下一步就是要去查看 redis 设置失败、myou.cvte.com 域名解析失败的原因了。
后记
同步阻塞的 DNS 系统函数是挺坑的,有 N 多第三方库自己实现基于 epoll 的异步 DNS 库,感兴趣的同学可以写一个玩一玩。
Node 的 C/C++ 部分的代码可读性还挺好的,觉得可以继续研究研究。


