
寻找已经发生高上下文切换问题的原因原创
作者介绍:
张子恒,西安邮电大学研一在读,导师陈莉君老师,刚刚踏入Linux内核学习的小白一枚。
段落引用背景介绍:
问题:vmstat只能实时统计进程上下文切换的次数,具有一定的局限性,如果已经发生了高上下文切换的情况,那么该如何找到高上下文切换问题的原因在哪?
想法:进程切换最核心的地方就是堆栈,那么可以通过打印进程的堆栈信息,找到已经发生高上下文切换问题的原因。
NO.01进程堆栈
linux 栈空间查看和修改
1、通过命令 ulimit -s 查看linux的默认栈空间大小

2、通过命令 ulimit -s 设置大小值 临时改变栈空间大小:ulimit -s 102400, 即修改为100M
3、可以在/etc/rc.local 内加入 ulimit -s 102400 则可以开机就设置栈空间大小
4、在/etc/security/limits.conf 中也可以改变栈空间大小
进程与程序
进程是程序的一次执行过程。用剧本和演出来类比,程序相当于剧本,而进程则相当于剧本的一次演出,舞台、灯光则相当于进程的运行环境。
进程的堆栈
每个进程都有自己的堆栈,内核在创建一个新的进程时,在创建进程控制块task_struct的同时,也为进程创建自己堆栈。**一个进程有2个堆栈,用户堆栈和系统堆栈;**用户堆栈的空间指向用户地址空间,内核堆栈的空间指向内核地址空间。当进程在用户态运行时,CPU堆栈指针寄存器指向用户堆栈地址,使用用户堆栈,当进程运行在内核态时,CPU堆栈指针寄存器指向的是内核栈空间地址,使用的是内核栈。
NO.02寻找切入点
工具介绍:
sysbench是一个模块化的、跨平台、多线程基准测试工具,主要用于评估测试各种不同系统参数下的数据库负载情况。这里用它来模拟高上下文切换的环境,下文会经常用到sysbench --threads=10 --time=300 threads run指令,参数–threads设置进程的线程数,参数–time设置最长运行时间。
高上下文切换环境的模拟:
在Linux虚拟机终端,执行指令sysbench --threads=10 --time=300 threads run进行多线程模拟,利用top指令进行观察如图所示:
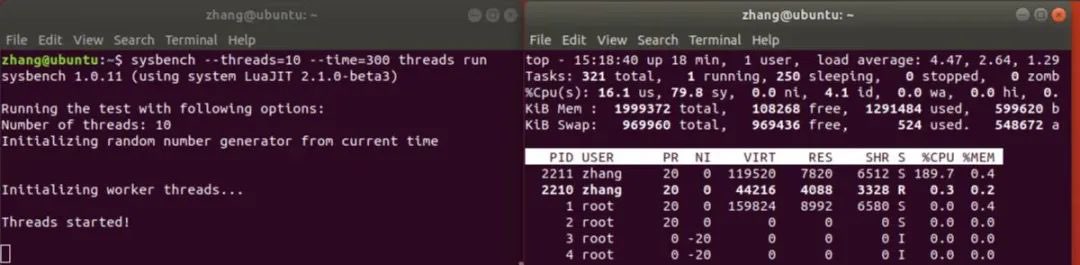
可以看出:
1.平均负载已经到达了我虚拟机cpu核数(总cpu核数为2)的两倍多,而且仍然在增加,造成了高负载的情况;
2.在这个环境下CPU主要运行在内核态,这是因为上下文切换过高会导致CPU像个搬运工,频繁在寄存器和运行队列之间奔波 ,更多的时间花在了线程切换,而不是真正工作的线程上,直接的消耗包括CPU寄存器需要保存和加载,系统调度器的代码需要执行,间接消耗在于多核cache之间的共享数据;
补充:cache是存在于主存和cpu中间的存储介质,是一种存储量较小但是速度很快的能和cpu以及主存交换数据。
切入点:高上下文切换会导致高负载,高负载可以通过进程的堆栈去找到原因,那么进程的堆栈中一定有关于高上下文切换的线索。
NO.03堆栈信息的打印
Load指标表示特定时间间隔内,系统有多少个正在运行的任务。包含:
1、正在CPU上面运行的任务数量(运行状态)
2、等待CPU调度运行的任务数量(不可中断状态)
3、等待IO执行结果的任务数量(不可中断状态)
TASK_RUNNING:正在运行或处于就绪状态:就绪状态是指进程申请到了CPU以外的其他所有资源,正所谓:万事俱备,只欠东风。提醒:一般的操作系统教科书将正在CPU上执行的进程定义为RUNNING状态、而将可执行但是尚未被调度执行的进程定义为READY状态,这两种状态在Linux下统一为 TASK_RUNNING状态。
TASK_UNINTERRUPTIBLE:处于等待队伍中,等待资源有效时唤醒(比如等待键盘输入、socket连接、信号等等),但不可以被中断唤醒。
此处代码借鉴于同门刘冰的博客文章http://t.csdn.cn/rKR8s:
程序介绍:在谢宝友老师的Load高故障分析代码的基础上做的修改,本程序是一个内核模块,用于监控系统负载,在平均负载超过4时,打印所有进程的调用栈。
load.h代码:
#include <linux/kprobes.h> /* for *kprobe* */
/* 调用kprobe找到kallsyms_lookup_name的地址位置 */
void *find_kallsyms_lookup_name(char *sym) { /* 通过kprobe找到函数入口地址 */
int ret;
void *p; /* 用于保存要返回的函数入口地址,void *可以指向任何类型的数据 */
struct kprobe kp = { /* 初始化探针,前面不加点也可以赋值,加 “.”的话可以不考虑赋值顺序 */
.symbol_name = sym, /* 设置要跟踪的内核函数名 */
};
if ((ret = register_kprobe(&kp)) < 0) { /* 探针注册失败就报告错误信息并返回空指针 */
printk(KERN_INFO "register_kprobe failed, error\n", ret);
return NULL;
}
/* 保存探针跟踪地址,即函数入口;输出注册成功信息,注销探针,返回地址 */
p = kp.addr;
printk(KERN_INFO "%s addr: %lx\n", sym, (unsigned long)p);
unregister_kprobe(&kp); /*卸载kprobe探测点*/
return p;
}
kallsyms_lookup_name函数可以通过函数名字获取对应的地址。
struct kprobe在内核中的定义:
struct kprobe {
struct hlist_node hlist; /*被用于kprobe全局hash,索引值为被探测点的地址*/
struct list_head list; /*用于链接同一被探测点的不同探测kprobe*/
unsigned long nmissed; /*如果 kprobe 嵌套,增加nmissed字段的数值*/
kprobe_opcode_t *addr; /*被探测点的地址*/
const char *symbol_name; /*被探测函数的名称*/
unsigned int offset; /*被探测点在函数内部的偏移,用于探测函数内核的指令,如果该值为0表示函数的入口*/
kprobe_pre_handler_t pre_handler; /*在被探测指令被执行前回调*/
kprobe_post_handler_t post_handler; /*在被探测指令执行完毕后回调(注意不是被探测函数)*/
kprobe_fault_handler_t fault_handler; /*在内存访问出错时被调用*/
kprobe_opcode_t opcode; /*保存的被探测点原始指令*/
struct arch_specific_insn ainsn; /*被复制的被探测点的原始指令,用于单步执行,架构强相关*/
u32 flags; /*状态标记*/
};
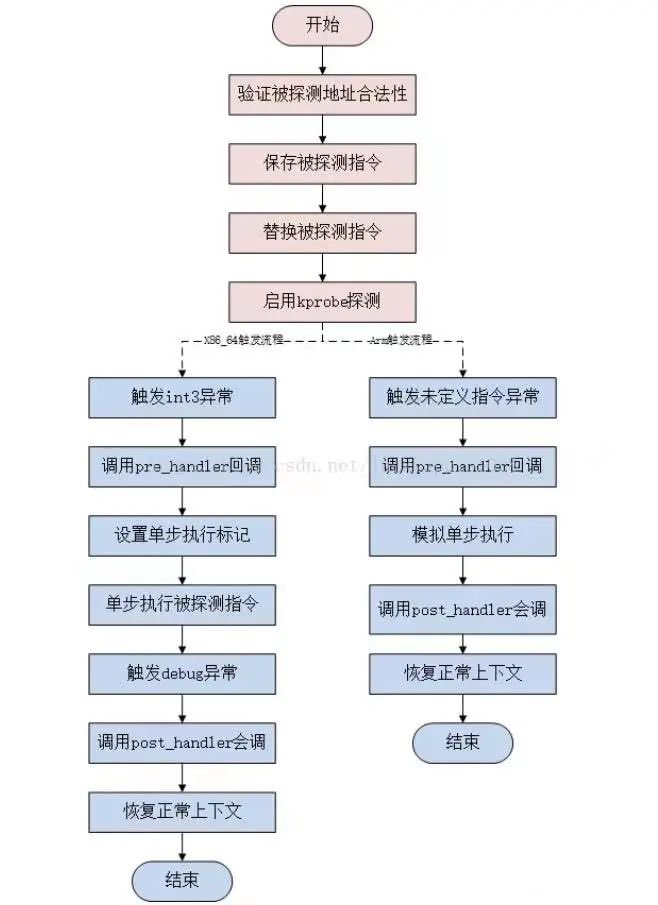
kprobe原理图:
main.c代码:
#include <linux/stacktrace.h> /* for stack_trace_print */
#include <linux/module.h> /* for module_*, MODULE_*, printk */
#include <linux/hrtimer.h> /* for hrtimer_*, ktime_* */
#include <linux/sched/loadavg.h> /* for avenrun, LOAD_* */
#include <linux/sched.h> /* for struct task_struct */
#include <linux/sched/signal.h> /* for do_each_thread, while_each_thread */
#include "load.h" /* for find_kallsyms_lookup_name */
#define BACKTRACE_DEPTH 20 /* 最大栈深度 */
unsigned int (*StackTraceSaveTask)(struct task_struct *tsk, unsigned long *store, unsigned int size, unsigned int skipnr); /* 将要指向stack_trace_save_tsk ,这个函数没有被导出,也就是源代码里没有export_symbol它的语句,所以不能用*/
static void print_all_task_stack(void) { /* 打印全部进程调用栈 */
struct task_struct *g, *p; /* 用于遍历进程 */
unsigned long backtrace[BACKTRACE_DEPTH]; /* 用于存储调用栈的函数地址 */
unsigned int nr_bt; /* 用于存储调用栈的层数 */
printk("!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!\n");
printk("Load: %lu.%02lu, %lu.%02lu, %lu.%02lu\n", /* 输出近期平均负载 */
LOAD_INT(avenrun[0]), LOAD_FRAC(avenrun[0]),
LOAD_INT(avenrun[1]), LOAD_FRAC(avenrun[1]),
LOAD_INT(avenrun[2]), LOAD_FRAC(avenrun[2]));
rcu_read_lock(); /* 为运行队列上锁 */
printk("dump running task.\n");
do_each_thread(g, p) { /* 遍历运行队列 */
if(p->state == TASK_RUNNING) {
printk("running task, comm: %s, pid %d\n", p->comm, p->pid);
nr_bt = StackTraceSaveTask(p, backtrace, BACKTRACE_DEPTH, 0); /* 保存栈 */
stack_trace_print(backtrace, nr_bt, 0); /* 打印栈 */
}
} while_each_thread(g, p);
printk("dump uninterrupted task.\n");
do_each_thread(g, p) { /* 和上面的遍历类似 */
if(p->state & TASK_UNINTERRUPTIBLE) {
printk("uninterrupted task, comm: %s, pid %d\n", p->comm, p->pid);
nr_bt = StackTraceSaveTask(p, backtrace, BACKTRACE_DEPTH, 0); /* 保存栈 */
stack_trace_print(backtrace, nr_bt, 0); /* 打印栈 */
}
} while_each_thread(g, p);
rcu_read_unlock(); /* 为运行队列解锁 */
}
struct hrtimer timer; /* 创建一个计时器 */
static void check_load(void) { /* 主要的计时器触发后的程序 */
static ktime_t last; /* 默认值是0 */
u64 ms;
int load = LOAD_INT(avenrun[0]); /* 最近1分钟的Load值 */
if(load < 4) /* 近1分钟内平均负载不超过4,没问题 */
return;
ms = ktime_to_ms(ktime_sub(ktime_get(), last)); /* 计算打印栈时间间隔 */
if(ms < 20*1000) /* 打印栈的时间间隔小于20s,不打印 */
return;
last = ktime_get(); /* 获取当前时间 */
print_all_task_stack(); /* 打印全部进程调用栈 */
}
static enum hrtimer_restart monitor_handler(struct hrtimer *hrtimer) { /* 计时器到期后调用的程序 */
enum hrtimer_restart ret = HRTIMER_RESTART;
check_load();
hrtimer_forward_now(hrtimer, ms_to_ktime(10)); /* 延期10ms后到期 */
return ret;
}
static void start_timer(void) {
hrtimer_init(&timer, CLOCK_MONOTONIC, HRTIMER_MODE_PINNED); /* 初始化计时器为绑定cpu自开机以来的恒定时钟 */
timer.function = monitor_handler; /* 设定计时器到期回调函数 */
hrtimer_start_range_ns(&timer, ms_to_ktime(10), 0, HRTIMER_MODE_REL_PINNED); /* 启动计时器并设定计时模式为绑定cpu的相对时间,计时10ms,松弛范围为0 */
}
static int load_monitor_init(void) { /* 模块初始化 */
StackTraceSaveTask = find_kallsyms_lookup_name("stack_trace_save_tsk");
if(!StackTraceSaveTask)
return -EINVAL;
start_timer(); /* 启动计时器 */
printk("load-monitor loaded.\n");
return 0;
}
static void load_monitor_exit(void) { /* 模块退出 */
hrtimer_cancel(&timer); /* 取消计时器 */
printk("load-monitor unloaded.\n");
}
module_init(load_monitor_init);
module_exit(load_monitor_exit);
MODULE_DESCRIPTION("load monitor module");
MODULE_AUTHOR("Baoyou Xie <baoyou.xie@gmail.com>");
MODULE_LICENSE("GPL");
- CLOCK_MONOTONIC:从系统启动这一刻起开始计时,不受系统时间被用户改变的影响。
- HRTIMER_MODE_PINNED:与初始化相关的模式,计时器绑定到CPU,仅在启动定时器时考虑。
- EINVAL 是定义在 errno.h 中的一个宏定义,它定义了一个整形变量(此处值为22),是错误代码的一个取值。EINVAL表示 无效的参数,即为 invalid argument ,包括参数值、类型或数目无效等。错误返回通常返回赋值,所以在EINVAL前面加一个负号,即return -EINVAL,便于进一步检测返回值的错误类型。
- stack_trace_save_tsk()函数:将任务堆栈跟踪保存到存储阵列中
enum hrtimer_restart在内核中的定义:
/* 回调函数的返回值 */
enum hrtimer_restart {
HRTIMER_NORESTART, /* 计时器未重新启动 */
HRTIMER_RESTART, /* 计时器必须重新启动 */
};
Makefile代码:
OS_VER := UNKOWN
UNAME := $(shell uname -r)
ifneq ($(findstring 4.15.0-39-generic,$(UNAME)),)
OS_VER := UBUNTU_1604
endif
ifneq ($(KERNELRELEASE),)
obj-m += $(MODNAME).o
$(MODNAME)-y := main.o
ccflags-y := -I$(PWD)/
else
export PWD=`pwd`
endif
ifeq ($(KERNEL_BUILD_PATH),)
KERNEL_BUILD_PATH := /lib/modules/`uname -r`/build
endif
ifeq ($(MODNAME),)
export MODNAME=load_monitor
endif
all:
make CFLAGS_MODULE=-D$(OS_VER) -C /lib/modules/`uname -r`/build M=`pwd` modules
clean:
make -C $(KERNEL_BUILD_PATH) M=$(PWD) clean
比较参数“arg1”和“arg2”的值是否相同,如果不同,则为真。
插入模块,然后执行指令sysbench --threads=10 --time=300 threads run,待平均负载达到4以上时,打印结果
补充知识:sysbench设计非常简单。SysBench运行指定数量的线程,它们都并行执行请求。请求产生的实际工作负载取决于指定的测试模式。您可以限制请求总数或基准测试的总时间,也可以同时限制两者。
运行结果:
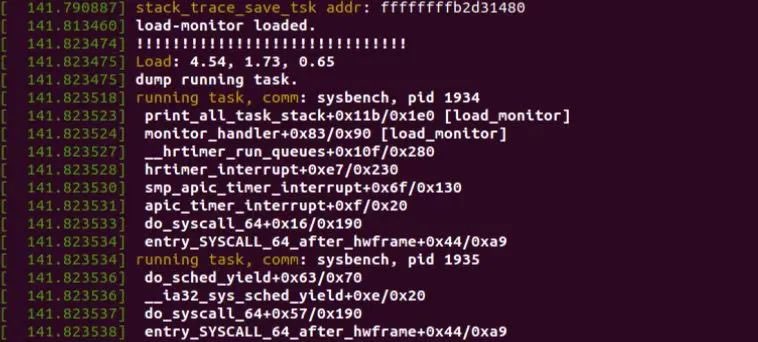
疑问:模拟的十个线程都同属于一个进程,为什么pid不同?
解答:每个线程都有一个pid(不知道叫什么),获取函数:syscall(SYS_gettid),除了主线程pid和自己进程pid一样,其他子线程pid都是唯一的。
NO.04打印结果分析
目的:寻找导致高上下文切换的堆栈信息
运行结果的栈信息:
[ 141.790887] stack_trace_save_tsk addr: ffffffffb2d31480
[ 141.813460] load-monitor loaded.
[ 141.823474] !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
[ 141.823475] Load: 4.54, 1.73, 0.65
[ 141.823475] dump running task.
[ 141.823518] running task, comm: sysbench, pid 1934
/*[ 141.823523] print_all_task_stack+0x11b/0x1e0 [load_monitor]
[ 141.823524] monitor_handler+0x83/0x90 [load_monitor]
[ 141.823527] __hrtimer_run_queues+0x10f/0x280
[ 141.823528] hrtimer_interrupt+0xe7/0x230
[ 141.823530] smp_apic_timer_interrupt+0x6f/0x130
[ 141.823531] apic_timer_interrupt+0xf/0x20 */这一部分都是和刚才加载的模块(load_monitor)相关
[ 141.823533] do_syscall_64+0x16/0x190
[ 141.823534] entry_SYSCALL_64_after_hwframe+0x44/0xa9
[ 141.823534] running task, comm: sysbench, pid 1935
[ 141.823536] do_sched_yield+0x63/0x70
[ 141.823536] __ia32_sys_sched_yield+0xe/0x20
[ 141.823537] do_syscall_64+0x57/0x190
[ 141.823538] entry_SYSCALL_64_after_hwframe+0x44/0xa9
[ 141.823538] running task, comm: sysbench, pid 1936
[ 141.823539] do_sched_yield+0x63/0x70
[ 141.823540] __ia32_sys_sched_yield+0xe/0x20
[ 141.823540] do_syscall_64+0x57/0x190
[ 141.823541] entry_SYSCALL_64_after_hwframe+0x44/0xa9
[ 141.823541] running task, comm: sysbench, pid 1937
[ 141.823543] futex_wait_queue_me+0xb9/0x120
[ 141.823544] futex_wait+0x100/0x270
[ 141.823545] do_futex+0x370/0x4e0
[ 141.823545] __x64_sys_futex+0x13f/0x190
[ 141.823546] do_syscall_64+0x57/0x190
[ 141.823547] entry_SYSCALL_64_after_hwframe+0x44/0xa9
[ 141.823547] running task, comm: sysbench, pid 1938
[ 141.823548] futex_wait_queue_me+0xb9/0x120
[ 141.823549] futex_wait+0x100/0x270
[ 141.823550] do_futex+0x370/0x4e0
[ 141.823551] __x64_sys_futex+0x13f/0x190
[ 141.823552] do_syscall_64+0x57/0x190
[ 141.823552] entry_SYSCALL_64_after_hwframe+0x44/0xa9
[ 141.823553] running task, comm: sysbench, pid 1939
[ 141.823553] do_sched_yield+0x63/0x70
[ 141.823554] __ia32_sys_sched_yield+0xe/0x20
[ 141.823555] do_syscall_64+0x57/0x190
[ 141.823555] entry_SYSCALL_64_after_hwframe+0x44/0xa9
......
据观察,这几个sysbench线程都有类似的堆栈信息:
- entry_SYSCALL_64_after_hwframe+0x44/0xa9
- do_syscall_64+0x57/0x190
- do_sched_yield+0x63/0x70
- do_futex+0x370/0x4e0
- futex_wait+0x100/0x270
- futex_wait_queue_me+0xb9/0x120
这些堆栈信息几乎囊括了sysbench线程的全部堆栈信息。
entry_SYSCALL_64: 负责判定system_call的类型,以及呼叫特定的系统调用处理程序函数。
do_syscall_64:在 do_syscall_64 里面,从 rax 里面拿出系统调用号,然后根据系统调用号,在系统调用表 sys_call_table 中找到相应的函数进行调用,并将寄存器中保存的参数取出来,作为函数参数。
do_sched_yield:将当前CPU分配给其他任务。如果此CPU上没有其他线程运行,则此函数将返回。
do_futex:函数do_futex通过op位运算生成cmd来确定具体的调用的futex的形式。
futex_wait:为了避免忙等待的情况而设置的挂起等待机制。
futex_wait_queue_me:将futex_q排在futex_hash_bucket,并等待唤醒、超时或信号。
futex:
在futex诞生之前,linux下的同步机制可以归为两类:用户态的同步机制 和 内核同步机制。用户态的同步机制基本上就是利用原子指令实现的spinlock。自旋锁(spinlock):是指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,即忙等待,不断尝试获取锁,直到获取到锁才会退出循环。内核提供的同步机制,诸如semaphore、等,其实骨子里也是利用原子指令实现的spinlock,内核在此基础上实现了进程的睡眠与唤醒。使用这样的锁,能很好地支持进程挂起等待。但是最大的缺点是每次lock与unlock都是一次系统调用,即使没有锁冲突,也必须要通过系统调用进入内核之后才能识别。
futex作为linux下的一种快速用户空间同步机制,已经存在了很长一段时间了(since linux 2.5.7)。它的基本设计有三点:
1.同步对象可以在进程间使用,并且保证同步对象的内部状态访问有序;
2.当同步对象没有竞争的情况下,可以在用户空间快速完成(fastpath);
3.当同步对象发生竞争时,必须进入内核使用futex系统提供的排队机制进行仲裁(slowpath),仲裁胜出的任务(进程或线程)必须返回到用户空间完成同步对象的其它状态的修改 。
综上所述:
根据打印出的堆栈信息,可以看出每个sysbench线程不是在请求被调用,就是在执行系统调用,进行上下文切换,几乎没有关于其他的堆栈信息,因此可以得出初步结论:当发生高上下文切换时,根据堆栈信息,可以高度关注像sysbench这类的线程,找到已经发生高上下文切换的原因。
由于作者还在学习阶段,本文错漏缺点在所难免,希望读者批评指正。



