
Fork & 写时复制COW原理原创
本篇文章的内核的代码是 Linux 0.11
上一篇文章我们看了计算机系统中的异常和中断是怎么做的,这篇文章我们来看看 fork 是如何利用异常实现进程的创建,以及 COW 实现原理
使用
fork 函数是一个系统调用函数,它是用来创建一个新的进程,如下:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
printf("hello world (pid:%d)\n", (int) getpid());
int rc = fork();
if (rc < 0) {
// fork failed
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
// child (new process)
printf("hello, I am child (pid:%d)\n", (int) getpid());
} else {
// parent goes down this path (main)
printf("hello, I am parent of %d (pid:%d)\n", rc, (int) getpid());
wait(NULL);
}
return 0;
}
我们执行一下:
hello world (pid:5093)
hello, I am parent of 5094 (pid:5093)
hello, I am child (pid:5094)
上面这个例子中分别输出了三次进程号,在调用 fork 函数之后,如果是父进程会返回子进程号,如果是子进程,那么会返回 0 。所以上面可以通过 fork 返回的进程号来判断父子进程。并且被 fork 出来的子进程不会从 main 函数开始执行,而是接着 fork 函数往下执行,彷佛像自己调用了 fork 函数一样。
父进程之所以要调用 wait 函数是为了等一下子进程,同步一下子进程的状态,否则可能会产生孤儿进程或僵尸进程,这个我们后面再说。
还有一点需要注意的是,父子进程的调度是随机的,并没有规定父进程调度一定会先于子进程被调度。
fork 函数实现过程
进程都是由其他进程创建出来的,每个进程都有自己的PID(进程标识号),在 Linux 系统的进程之间存在一个继承关系,所有的进程都是 init 进程(1号进程)的后代。可以通过 pstree 命令查看到进程的族谱。在 Linux 中所有的进程都通过 task_struct 描述,里面通过 parent 和 children 字段维护一个父子进程树的链表结构。
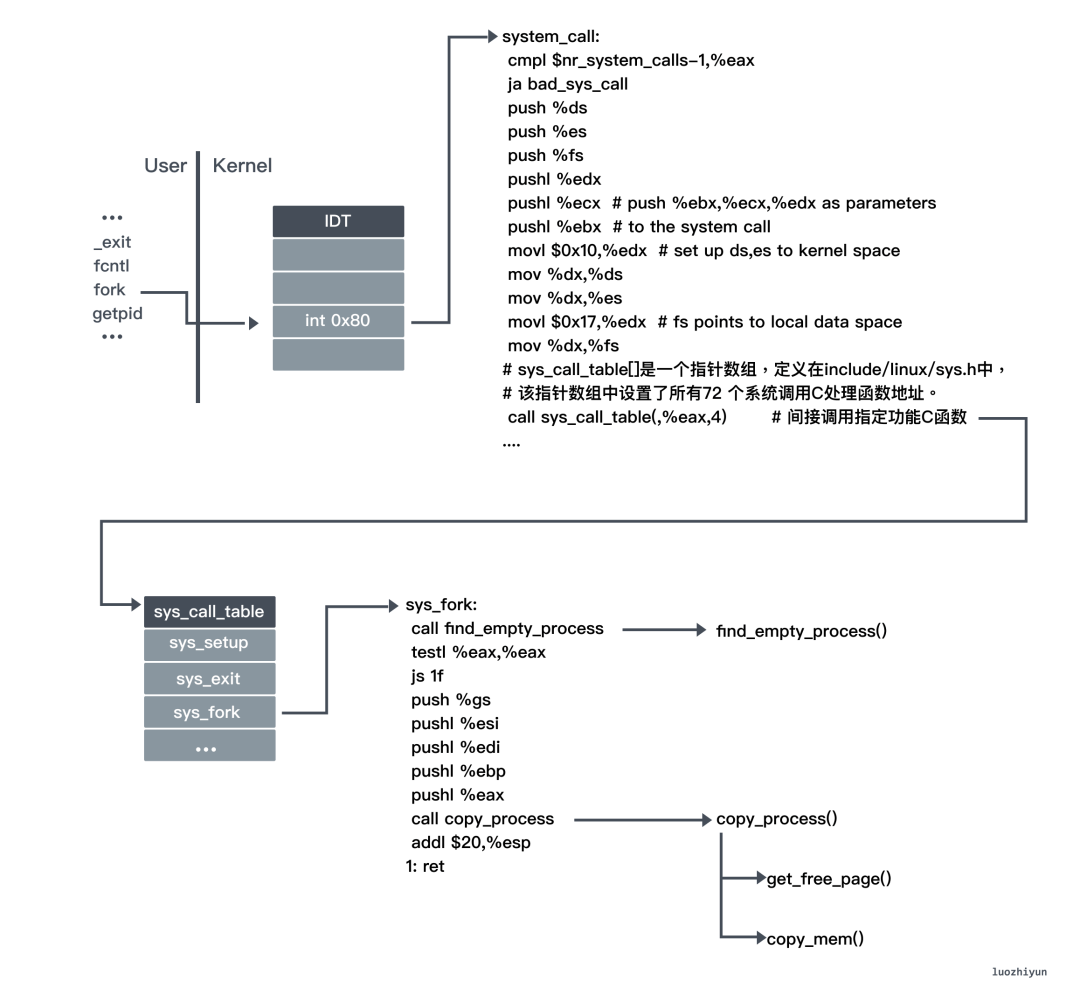
而 fork 函数是创建子进程的一种方法,它是一个系统调用函数,所以在看 fork 系统调用之前我们先来看看 system_call。
系统调用处理函数 system_call 与 int 0x80 中断描述符表挂接。 system_call 是整个操作系统中系统调用软中断的总入口。所有用户程序使用系统调用,产生 int 0x80 软中断后,操作系统都是通过这个总入口找到具体的系统调用函数。
系统调用函数是操作系统对用户程序的基本支持。在操作系统中,像类似读盘、创建子进程之类的事物需要通过系统调用实现。系统调用被调用后会触发 int 0x80 软中断,然后由用户态切换到内核态(从用户进程的3特权级翻转到内核的0特权级),通过 IDT 找到系统调用端口,调用具体的系统调用函数来处理事物,处理完毕之后再由 iret 指令回到用户态继续执行原来的逻辑。
fork 函数由于也是系统调用的函数之一,所以也是通过 int 0x80 软中断来进行触发的。在触发 int 0x80 软中断后会切换到内核态,找到 sys_call_table 中根据 fork 的 index(也就是2) 找到对应的函数:
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,
sys_write, sys_open, sys_close... };
然后拿到对应的 C 函数 sys_fork。因为会变中对应 C 的函数名在前面多加一个下划线,所以会跳转到 _sys_fork 处执行。
在 _sys_fork 中首先会调用 find_empty_process 申请一个空闲位置并获取一个新的进程号 pid。空闲位置由 task[64] 这个数组决定,也就是说最多只能同时 64 个进程同时在跑,并用全局变量 last_pid 来存放系统自开机以来累计的进程数,如果有空闲位置,那么 ++last_pid 作为新进程的进程号,在 task[64] 中找到的空闲位置的 index 作为任务号。
_sys_fork 接下来调用 copy_process 进行进程复制:
- 将 task_struct 复制给子进程,task_struct 是用来定义进程结构体,里面有关于进程所有信息;
- 随后对复制来的进程结构内容进行一些修改和初始化赋0。比方说状态、进程号、父进程号、运行时间等,还有一些统计信息的初始化,其余大部分保持不变;
- 然后会调用 copy_mem 复制进程的页表,但是由于Linux系统采用了写时复制(copy on write)技术,因此这里仅为新进程设置自己的页目录表项和页表项,而没有实际为新进程分配物理内存页面,此时新进程与其父进程共享所有物理内存页面。
- 最后 GDT 表中设置子进程的 TSS(Task State Segment) 段和 LDT(Local Descriptor Table) 段描述符项,将子进程号返回。其中 TSS 段是用来存储描述进程相关的信息,比方一些寄存器、当前的特权级别等;
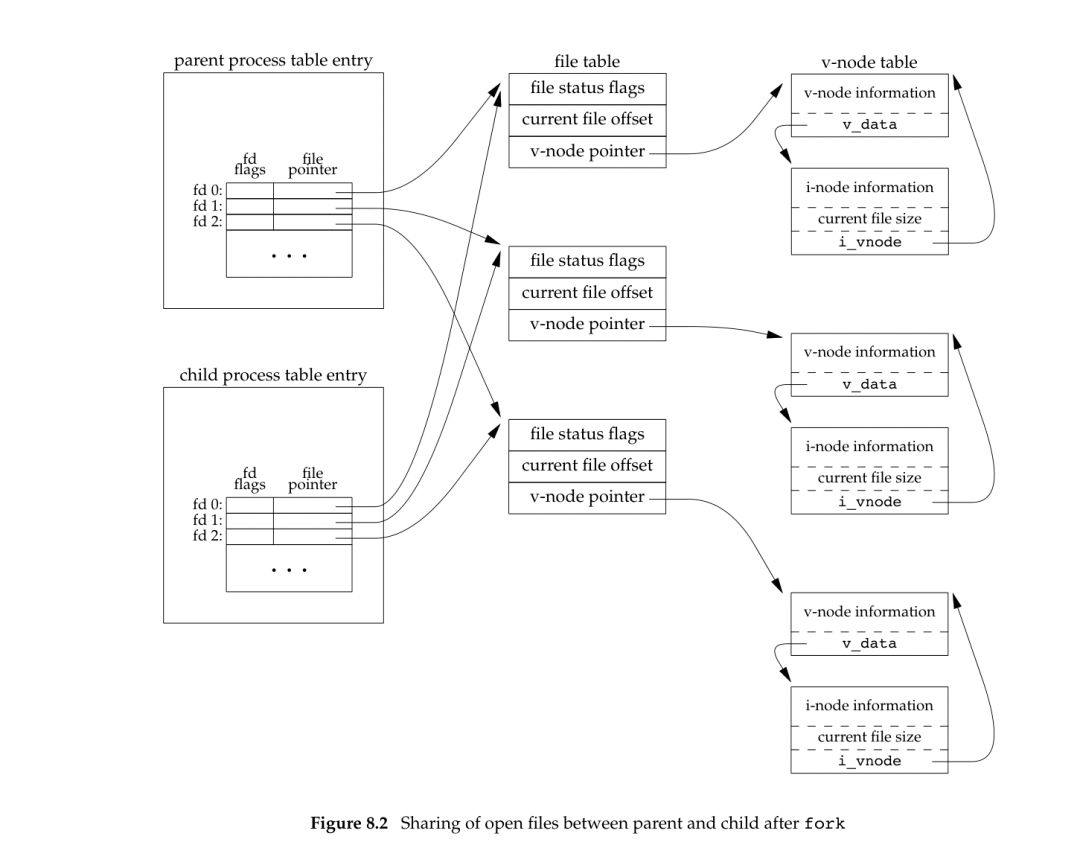
需要注意的是子进程也会继承父进程的文件描述符,也就是子进程会将父进程的文件描述符表项都复制一份,也就是说如果父进程和子进程同时写一个文件的话可能产生并发写的问题,导致写入的数据错乱。
写时复制 Copy-On-Write
Copy-on-write (COW), sometimes referred to as implicit sharing[1] or shadowing,[2] is a resource-management technique used in computer programming to efficiently implement a “duplicate” or “copy” operation on modifiable resources.[3] If a resource is duplicated but not modified, it is not necessary to create a new resource; the resource can be shared between the copy and the original. Modifications must still create a copy, hence the technique: the copy operation is deferred until the first write.
按照上面 COW 的定义,它是一种延迟拷贝的资源优化策略,通常用在拷贝复制操作中,如果一个资源只是被拷贝但是没有被修改,那么这个资源并不会真正被创建,而是和原数据共享。因此这个技术可以推迟拷贝操作到首次写入之后进行。
fork 函数调用之后,这个时候因为Copy-On-Write(COW) 的存在父子进程实际上是共享物理内存的,并没有直接去拷贝一份,kernel 把会共享的所有的内存页的权限都设为 read-only。当父子进程都只读内存,然后执行 exec 函数时就可以省去大量的数据复制开销。
当其中某个进程写内存时,内存管理单元 MMU 检测到内存页是 read-only 的,于是触发缺页异常(page-fault),处理器会从中断描述符表(IDT)中获取到对应的处理程序。在中断程序中,kernel就会把触发的异常的页复制一份,于是父子进程各自持有独立的一份,之后进程再修改对应的数据。
COW的好处是显而易见的,同时也有相应的缺点,如果父子进程都需要进行大量的写操作,会产生大量的缺页异常(page-fault)。缺页异常不是没有代价的,它会处理器会停止执行当前程序或任务转而去执行专门用于处理中断或异常的程序。处理器会从中断描述符表(IDT)中获取到对应的处理程序,当异常或中断执行完毕之后,会继续回到被中断的程序或任务继续执行。
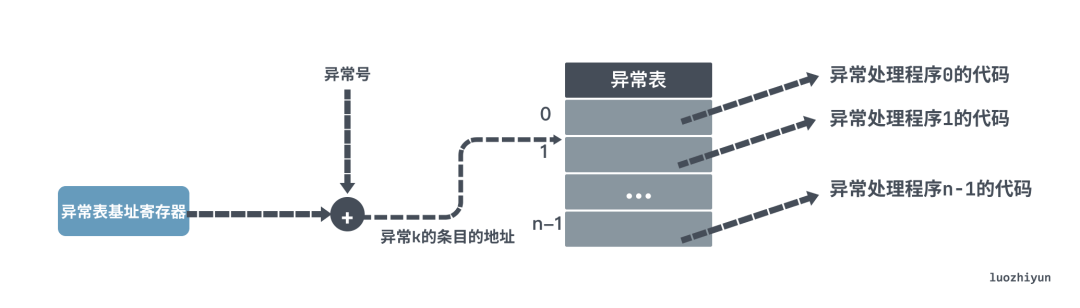
也就是说缺页异常会导致上下文切换,然后查询 copy 数据到新的物理页这么个过程,如果在分配新的物理页的时候发现内存不够,那么还需要进行 swap ,执行相应的淘汰策略,然后进行新页的替换。所以在 fork 之后要避免大量的写操作。
孤儿进程 & 僵尸进程
因为 Linux 提供了一种机制可以保证只要父进程想知道子进程结束时的状态信息, 就可以得到。所以即使子进程运行完了,还依然会挂在那里,方面父进程可以获取一些状态信息,直到父进程通过wait / waitpid来取时才释放。
如果进程不调用 wait / waitpid 的话,那么保留的那段信息就不会释放,其进程号就会一直被占用,僵尸进程就是这么诞生的。如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程,所以是有一定危害的。
而孤儿进程就是一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被挂到 init 进程(1号进程)下面,而 init 进程会循环地 wait 它的已经退出的子进程,所以孤儿进程反倒没什么问题。
总结
这篇文章还是比较清晰的,没有什么比较大的概念。首先要理解 fork 之前需要理解一下操作系统的异常 & 中断机制,fork 会触发软中断,陷入到系统调用函数里面,最后根据系统函数调用表找到对应的处理函数创建子进程同事拷贝父进程一些数据,但是这个时候虽然拷贝了虚拟页表,由于 COW 的存在并不会立马去复制物理内存,而是会延迟到写入的时候,通过 page fault 中断来拷贝物理内存数据,最后还补充了一下孤儿进程 & 僵尸进程的知识点作为收尾。
Reference
《深入理解计算机系统》
《Linux内核设计的艺术图解》
《Advanced.Programming.in.the.UNIX.Environment.3rd.Edition》

