
给32位系统装8g内存条能用吗?为什么?原创

关于32位和64位,这个概念一直让人比较懵。
在买电脑的时候,我们看到过32位和64位CPU。
下软件的时候,我们也看到过32位或64位的软件。
就连装虚拟机的时候,我们也看过32位和64位的系统。
在写代码的时候,我们的数值,也可以定义为int32或者int64。
我们当然很清楚,装软件的时候,一般64位的系统就选64位的软件,肯定不出错,但是这又是为什么呢?既然CPU,软件,操作系统,数值大小都有32位和64位,他们之间就可以随意组合成各种问题,比如32位的系统能装64位的软件吗?32位的系统能计算int64的数值吗?他们之间到底有什么关系?这篇文章会尝试解释清楚。
<br>
从代码到到可执行文件
我们从熟悉的场景开始说起,比方说,我们写代码的时候,会在代码编辑器里写入。
// test.c
#include <stdio.h>
int main()
{
int i,j;
i = 3;
j = 2;
return i + j;
}
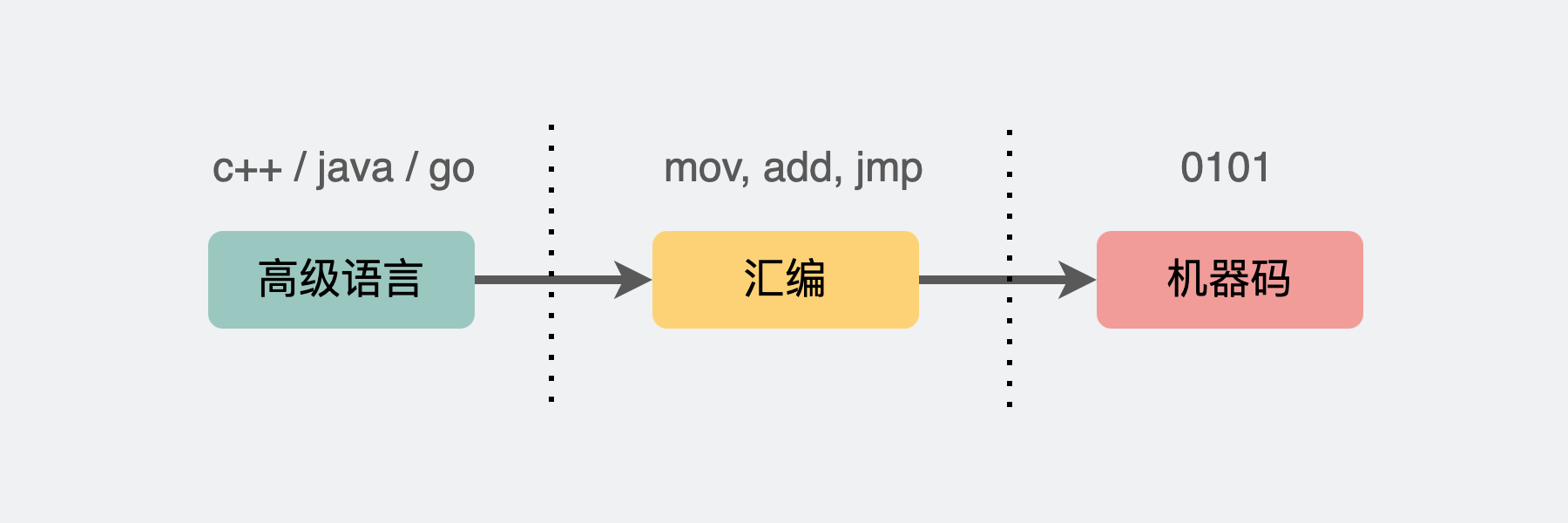
但这个代码是给人看的,机器可看不懂,于是这段代码,还会经过被编译器转成汇编码。
汇编码就是我们大学的时候学的头秃的这种
// gcc -S test.c
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movl $0, -4(%rbp)
movl $3, -8(%rbp)
movl $2, -12(%rbp)
movl -8(%rbp), %eax
addl -12(%rbp), %eax
popq %rbp
retq
大家也别去看上面的内容,没必要。
而汇编,总归还是有各种movl,pushq这些符号,虽然确实不好看,但说到底还是给人看的,而机器cpu要的,说到底还是要0101这样的二进制编码,所以还需要使用汇编器将汇编转成二进制的机器码。我们可以看到下面内容分为3列,左边是指令地址, 右边是汇编码内容,中间的就是指令机器码,是16进制,可以转成二进制01串,这就是机器cpu能认识的内容了。
// objdump -d test
0000000000001125 <main>:
1125: 55 push %rbp
1126: 48 89 e5 mov %rsp,%rbp
1129: c7 45 fc 03 00 00 00 movl $0x3,-0x4(%rbp)
1130: c7 45 f8 02 00 00 00 movl $0x2,-0x8(%rbp)
1137: 8b 55 fc mov -0x4(%rbp),%edx
113a: 8b 45 f8 mov -0x8(%rbp),%eax
113d: 01 d0 add %edx,%eax
113f: 5d pop %rbp
1140: c3 retq
1141: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
1148: 00 00 00
114b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
而机器码,最后会放在我们编译生成的可执行文件里。
也就是说我们平时写的代码,最后会变成一堆01机器码,放在可执行文件里,躺在磁盘上。
<br>
从可执行文件到进程
一旦我们执行以下命令
./可执行文件名
这个可执行文件就会加载进内存中,成为一个进程,运行起来。
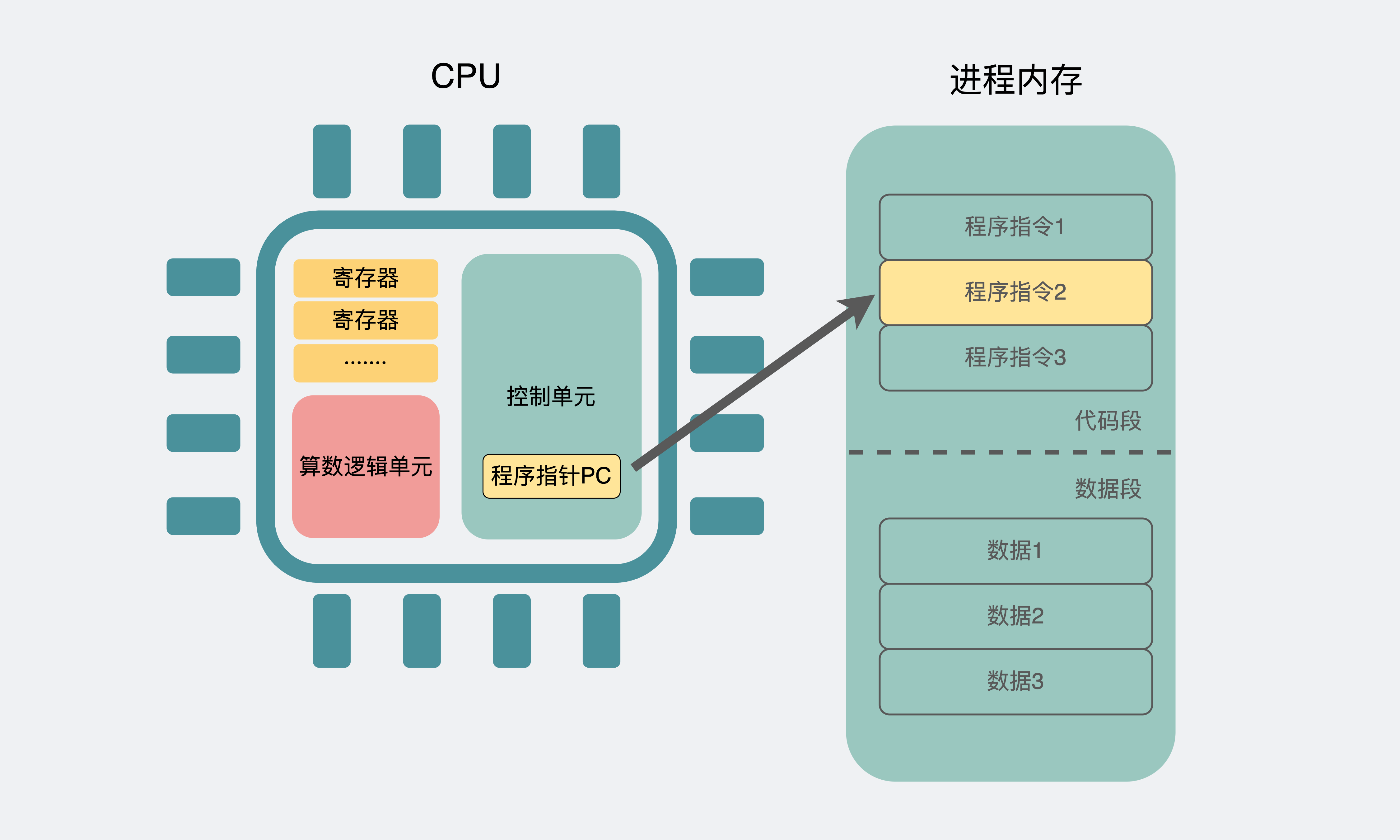
可执行文件里的机器码也会被加载到内存中,它就像是一张列满todo list的清单,而CPU就对照着这张清单,一行行的执行上面的机器码。从效果上来看,进程就动起来了。
对CPU来说,它执行到某个特定的编码数值,就会执行特定的操作。比如计算2+3,其实就是通过总线把数据2和3从内存里读入,然后放到寄存器上,再用加法器相加这两个数值并将结果放入到寄存器里,最后将这个数值回写到内存中,以此循环往复,一行行执行机器码直到退出。
<br>
CPU位数的含义
上面这个流程里,最重要的几个关键词,分别是CPU寄存器,总线,内存。
CPU的寄存器,说白了就是个存放数值的小盒子,盒子的大小,叫位宽。32位CPU能放入最大2^32的数值。64位就是最大2^64的值。这里的32位位宽的CPU就是我们常说的32位CPU,同理64位CPU也是一样。
而CPU跟内存之间,是用总线来进行信号传输的,总线可以分为数据总线,控制总线,地址总线。功能如其名,举个例子说明下他们的作用吧。在一个进程的运行过程中,CPU会根据进程的机器码一行行执行操作。
比如现在有一行是将A地址的数据与B地址的数据相加,那么CPU就会通过控制总线,发送信号给内存这个设备,告诉它,现在CPU要通过地址总线在内存中找到A数据的地址,然后取得A数据的值,假设是100,那么这个100,就会通过数据总线回传到CPU的某个寄存器中。B也一样,假设B=200,放到另一个寄存器中,此时A和B相加后,结果是300,然后控制CPU通过地址总线找到返回的参数地址,再把数据结果通过数据总线传回内存中。这一存一取,CPU都是通过控制总线对内存发出指令的。
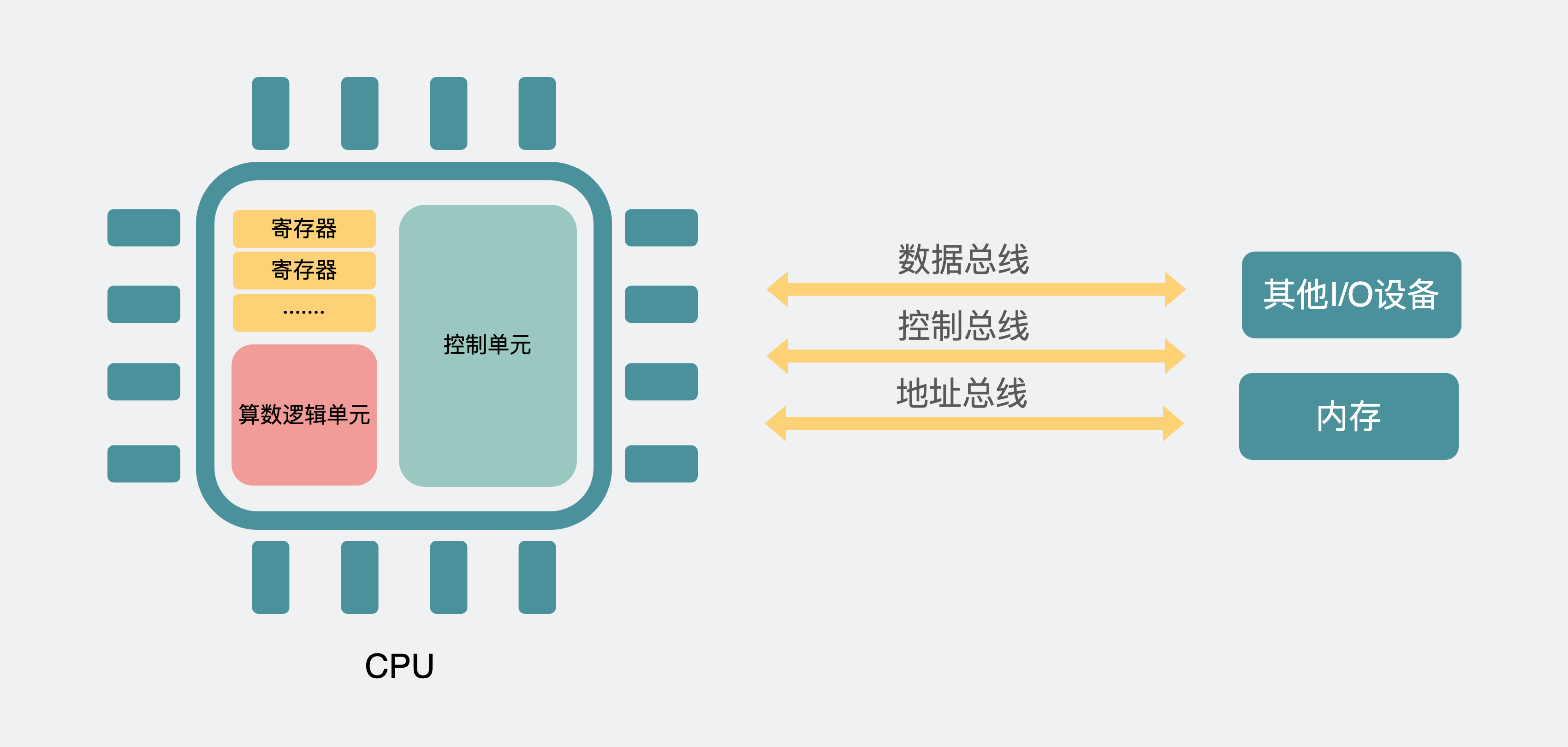
而总线,也可以理解为有个宽度,比如宽度是32位,那么一次可以传32个0或1的信号,那么这个宽度能表达的数值范围就是0到2^32这么多。
32位CPU的总线宽度一般是32位,因为刚刚上面提到了,CPU可以利用地址总线在内存中进行寻址操作,那么现在这根地址总线,最大能寻址的范围,也就到2^32,其实就是4G。
64位CPU,按理说总线宽度是64位,但实际上是48位(也有看到说是40位或46位的,没关系,你知道它很大就行了),所以寻址范围能到2^48次方,也就是256T。
<br>
系统和软件的位数的含义
上面提到了32位CPU和64位CPU的内存寻址范围,那么相应的操作系统,和软件(其实操作系统也能说是软件),也应该按CPU所能支持的范围去构建自己的寻址范围。
比方说下面这个图,在操作系统上运行一个用户态进程,会分为用户态和内核态,并设定一定的内存布局。操作系统和软件都需要以这个内存布局为基础运行程序。比如32位,内核态分配了1个G,用户态分配了3G,这种时候,你总不能将程序的运行内存边界设定在大于10G的地方。所以,系统和软件的位数,可以理解为,这个系统或软件内存寻址的范围位数。

一般情况下,由于现在我们的CPU架构在设计上都是完全向前兼容的,别说32位了,16位的都还兼容着,因此64位的CPU是能装上32位操作系统的。
同理,64位的操作系统是兼容32位的软件的,所以32位软件能装在64位系统上。
但反过来,因为32位操作系统只支持4g的内存,而64位的软件在编译的时候就设定自己的内存边界不止4个G,并且64位的CPU指令集内容比32位的要多,所以32位操作系统是肯定不能运行64位软件的。
同理,32位CPU也不能装64位的操作系统的。
<br>
程序数值int32和int64的含义
这个我们平时写代码接触的最多,比较好理解了。int32也就是用4个字节,32位的内存去存储数据,int64也就是用8个字节,64位去存数据。这个数值就是刚刚CPU运行流程中放在内存里的数据。
<br>
那么问题又来了。
<br>
32位的CPU能进行int64位的数值计算吗?
先说结论,能。但比起64位的CPU,性能会慢一些。
如果说我用的是64位的CPU,那么我在计算两个int64的数值相加时,我就能将数据通过64位的总线,一次性存入到64位的寄存器,并在进行计算后返回到内存中。整个过程一步到位,一气呵成。
但如果我现在用的是32位的CPU,那就憋屈一点了,我虽然在代码里放了个int64的数值,但实际上CPU的寄存器根本放不下这么大的数据,因此最简单的方法是,将int64的数值,拆成前后两半,现在两个int64相加,就变成了4个int32的数值相加,并且后半部分加好了之后,拿到进位,才能去计算前面的部分,这里光是执行的指令数就比64位的CPU要多。所以理论上,会更慢些。
<br>
系统位数会限制内存吗?
上面提到了CPU位数,系统位数,软件位数,以及数值位数之间的区别与联系。
现在,我们回到标题里提到的问题。
<br>
32位CPU和系统插8g内存条,能用吗?
系统能正常工作,但一般用不到8G,因为32位系统的总线寻址能力为2的32次方,也就是4G,哪怕装了8G的内存,真正能被用到的其实只有4g,多少有点浪费。
注意上面提到的是一般,为什么这么说,因为这里有例外,32位系统里,有些是可以支持超过4G内存的,比如Windows Server 2003就能最大支持64G的内存,它通过使用 PAE (Intel Physical Address Extension)技术向程序提供更多的物理内存,PAE本质上是通过分页管理的方式将32位的总线寻址能力增加到36位。因此理论上寻址能力达到2的36次方,也就是64G。
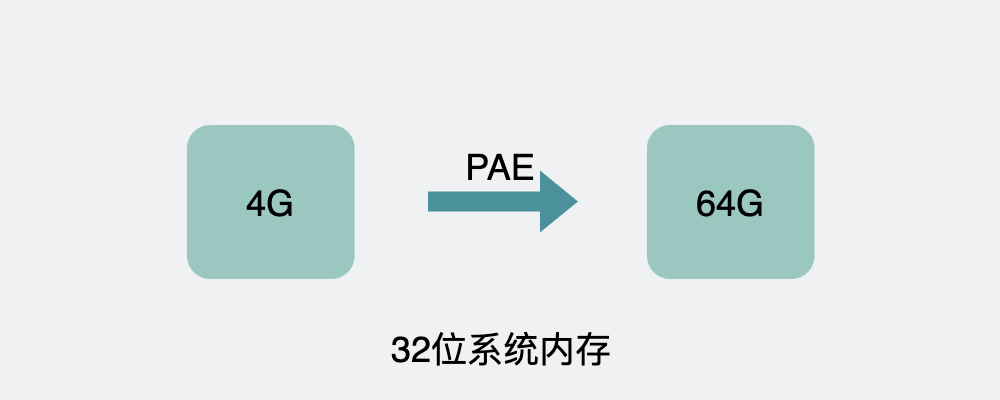
至于实现细节大家也不用关心,现在用到这玩意的机器也该淘汰的差不多了,而且都是windows server,注意Windows Server 2003 名字里带个server,是用来做服务器的,我们一般也用不到,知道这件事,除了能帮助我们更好的装x外,就没什么作用了。
所以,你当32位系统最大只能用到4G内存,那也没毛病。
<br>
64位CPU装32位操作系统,再插上8g的内存条,寻址能力还是4G吗
上面提到32位CPU就算插上8G内存条,寻址能力也还是4G,那如果说我现在换用64位的CPU,但装了个32位的操作系统,这时候插入8G内存条,寻址能力能超过4G吗?
寻址能力,除了受到cpu的限制外,还受到操作系统的限制,如果操作系统就是按着32位的指令和寻址范围(4G)来编译的话,那么它就会缺少64位系统该有的指令,它在运行软件的时候就不能做到超过这个限制,因此寻址能力还会是4G。
<br>
最后留下一个问题吧。
上面提到,我们平时写的代码(也就是C,go,java这些),先转成汇编,再转成机器码。最后CPU执行的是机器码,那么问题来了。
为什么我们平时写的代码不直接转成机器码,而要先转成汇编,这是不是多此一举?
<br>
总结
- CPU位数主要指的是寄存器的位宽,
- 32位CPU只能装32位的系统和软件,且能计算int64,int32的数值。内存寻址范围是4G。
- 64位CPU,同时兼容32位和64位的系统和软件,并且进行int64数值计算的时候,性能比32位CPU更好,内存寻址范围可以达到256T。
- 32位CPU和操作系统,插入8G的内存,会有点浪费,因为总线寻址范围比较有限,它只能用上4G不到的内存。
- 64位CPU,如果装上32位的操作系统,就算插上8G的内存,效果也还是只能用上4G不到的内存。
<br>
最后
刚工作的时候一直觉得int32,有21个亿,这么大的数值肯定够用了吧,结果现实好几次打脸。
以前做游戏的时候,血量一开始是定义为int32,游戏设定是可以通过充钱,提升角色的属性,还能提升血量上限,谁也没想到,老板们通过氪金,硬是把血量给打到了int32最大值。于是策划提了个一句话需求:“血量要支持到int64大小”,这是我见过最简单的策划案,但也让人加班加的最凶。
那是我第一次感受到了钞能力。

<br>
这篇文章老早就想写了,但涉及的知识点有点多,一直很头疼,怎么样才能用最简单的方式把他们表述清楚,于是想着从大家最熟悉的场景开始说起。希望能给大家带来价值。
如果文章对你有帮助,欢迎…
算了。
<br>
别说了,一起在知识的海洋里呛水吧
点击下方名片,关注公众号:【小白debug】




