
关于对前端稳定性建设的一些总结原创
稳定性是数学或工程上的用语,判别一系统在有界的输入是否也产生有界的输出。若是,称系统为稳定;若否,则称系统为不稳定。
前端的稳定性大致也可以如此概括,简单地说就是在外界影响下表现出的某种稳定状态,例如无报错、响应快、内容呈现正确等。
要想达到稳定状态,需要做些有效的防范措施和机制,而这些也正是我们组现在和未来会持续推进的工作之一。
一、监控
线上业务是必须要监控的,否则在排查用户问题时将无从下手。
1)业务监控
业务监控就是与业务相关的监控,常见的就是Node.js的代码日志。
包括数据库查询语句、内部通信的请求和响应、自定义的打印、代码报错等。
这部分在接入阿里云的服务后,就可以通过阿里云提供的日志网站查询到,如下所示。
content:
{
"name": "koa",
"pid": 26,
"req_id": "4df3f997e7dc6c03eeaac3e1e01ee0f5",
"level": 30,
"msg": " <-- POST /services/getKey",
"time": "2022-08-23T10:25:21.927Z",
"v": 0
}
content:
{
"name": "backend",
"pid": 26,
"level": 20,
"msg": "4df3f997e7dc6c03eeaac3e1e01ee0f5 SELECT `id`, `title` FROM `app_global` AS `AppGlobal` WHERE `AppGlobal`.`key` = 'xxxxx' LIMIT 1",
"time": "2022-08-23T10:25:21.928Z",
"v": 0
}
其中第一条的req_id和第二条msg的第一段字符串是一个标识符,可将通信和其他日志串联起来,这样就能在几百万条日志中准确的查到,这次通信查了什么表、打印了什么内容等。
还有一部分业务监控需要自己搭建,包括前端的脚本错误、异步通信、性能参数等。
目前已研发出SDK,嵌入到线上各个H5网页,以及小程序。
配套的管理后台也在稳定运行中,可实时查监控各个项目的异常,异步通信的JSON响应。
虽然代码日志可以记录Ajax请求的地址,但是无法输出Ajax响应的JSON数据,如下所示。
所以才又重新研发了一套前端监控系统,补充服务端日志的不足。
{
"type": "GET",
"url": "//web-api.xx.me/game/detail",
"status": 200,
"endBytes": "0.17KB",
"header": {
"req-id": "4df3f997e7dc6c03eeaac3e1e01ee0f5"
},
"interval": "195.7ms",
"network": {
"bandwidth": 0,
"type": "4G"
},
"response": {
"status": 1,
"data": {
"count": 3,
"isExperience": true,
}
}
}
注意,在日志中也有一个req-id字段,用于和服务端的代码日志做关联,便于排查。
性能监控也是业务监控的一部分,主要监控着白屏、首屏、各个阶段的耗时等,如下所示,单位ms。
{
"unloadEventTime": 0,
"loadEventTime": 1,
"interactiveTime": 580,
"firstPaintStart": 771,
"firstContentfulPaint": 0,
"parseDomTime": 188,
"initDomTreeTime": 307,
"readyStart": 1,
"redirectCount": 0,
"compression": 0,
"redirectTime": 0,
"appcacheTime": 0,
"lookupDomainTime": 0,
"connectSslTime": 0,
"connectTime": 0,
"requestTime": 273,
"requestDocumentTime": 271,
"responseDocumentTime": 2,
"TTFB": 272,
"now": 775,
}
在搜集到用户手机中页面的真实性能情况后,就可针对性的做各种优化。
2)系统监控
系统监控包括服务器CPU、内存、负载、QPS等信息。
这部分没有自研,而是直接接入了阿里云的Node.js性能平台。

当线上出现内存泄漏时,就能通过下载的堆快照导入Chrome中,以此来分析泄漏原因。
还引入了阿里云的数据库监控,可以实时看到慢查询,并且还能智能的给出优化建议,自动生成相关索引,效果可以说立竿见影。
3)监控大盘
监控大盘便于观察核心指标的走向,包括慢响应,5XX接口数量、白屏和首屏各阶段占比等。
监控大盘也是为了能主动发现异常,而不是由用户上报。
因为一旦发现曲线有异常情况,即迅速上升(例如下图),那么就需要抽调资源来排查是什么问题导致的。
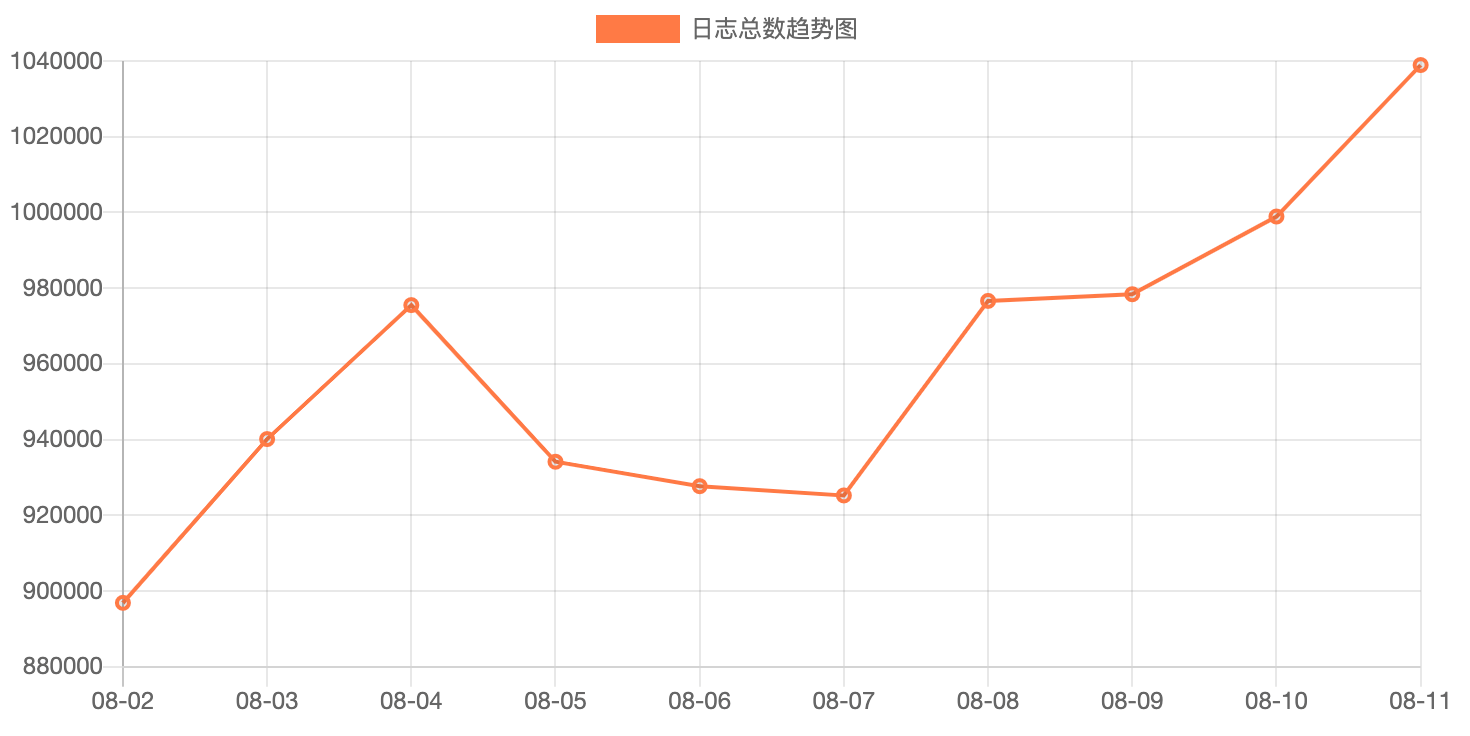
通过监控大盘,还可以发现一些用户并不关注的问题,例如前端监控在接收比较大的数据时会报大量的500错误,还有一些比较隐蔽的边界条件错误等。
这些错误并不会非常影响用户体验,所以一般也很少会上报到客服,只能通过主动监控来发现。
二、告警
告警也是为了能主动发现问题,及时处理,以免让用户感知,降低体验。
告警主要还是针对后端用Node编写的服务。
1)业务接口
业务接口就包括对外的H5网页和对内的管理后台所涉及的接口。
目前的规则是每分钟5个以上5XX接口,就会自动在飞书中发消息告警。
nginx状态码告警
- 告警名称: 主站-5xx错误状态码
- 首次触发: 2022-08-23 02:24:46
- 告警时间: 2022-08-23 02:24:46
- 告警状态: 触发
- 告警严重度: 中级
- 错误状态码: 500
- 日志详细:
{
'proxy_upstream_name': 'web-website',
'req_id': '92072872edf58909e3f8f2edce6bc5f0',
'status': '500',
'url': '/share/live/xxx.html'
}
2)定时任务
定时任务与接口不同,所以不能套用之前的规则。
很多定时任务都是5分钟运行一次,那如果报错的话,也是5分钟一次。
如果采用上面的规则,那么将永远无法收到告警。
所以改成每5分钟有一次500的错误,就会发出告警。
三、事故
当线上出现问题时,需要提前准备好应急方案。
每一次线上事故,都是一次昂贵的付费学习机会,做好复盘,以免重蹈覆辙。
1)留一手
如果能预判线上可能出现的问题,那么可以留一手,迅速响应。
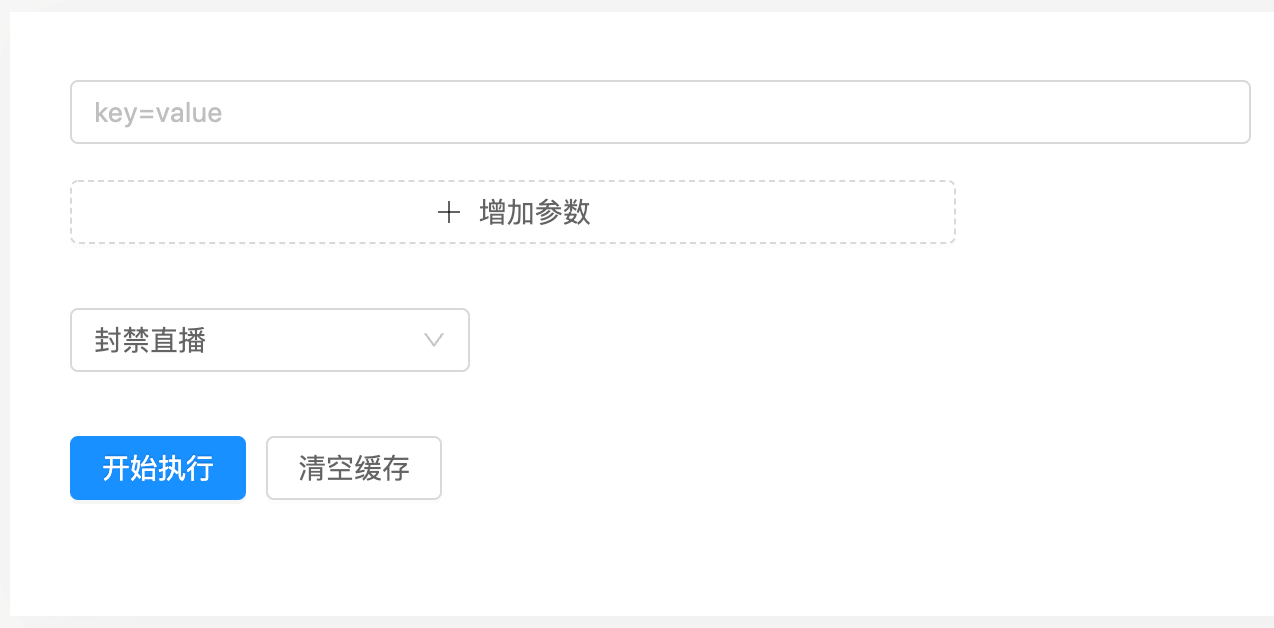
例如在某一时刻榜单定时任务可能会运行失败,那么就预设个页面,手动触发。
页面可以像下图这样,下拉框就是各类接口名称,可自定义参数,按钮请求接口。
2)责任人
公司内部有个技术问题对接大群,各类版本和H5需求还有单独的群。
所以在将问题抛到群里后,可相对比较快的找到责任人。
对于最近上线的业务,我们都会安排专门的人随时待命解决问题。
在解决问题后,马上预估影响面,并告知业务方。
3)做复盘
复盘有固定的格式,包括名称、持续时间、影响范围、经过、原因和解决方案。
写好后发一封公司邮件,告知所有人这次事故的来龙去脉。
复盘不是为了批斗,而是为了更好的找出问题,更好的修复问题,不要再犯相同的错误。
有必要的话,还可以将所有相关人员拉上,组织一场会议。
大家各自发言,看看是否还有其他没有注意到的问题,都抛出来。
四、测试
公司有一个测试团队,当大家研发完成后,后面的流程就会转到他们那边。
1)自行测试
测试团队会出一份测试用例文档,他们会给出部分需要自测的用例。
当自测完成后,再去发一封提测邮件,然后他们再接手。
之所以要自测,是因为在测试验收时经常发生主流程都跑不通的情况。
还需要让研发修改,这样来来回回非常影响效率,所以才会要求自测。
2)单元测试
单元测试是我们组内部一直在推,但收效并不明显。
好处毋庸置疑,之前专门做过分析。
上次升级Node环境版本时,因为一个服务没有连接,导致一个接口报错。
因为影响范围很小,所以也没有在第一时间收到反馈。
后面与运维沟通,发现可以在线上发布的时候增加一个单元测试的流程。
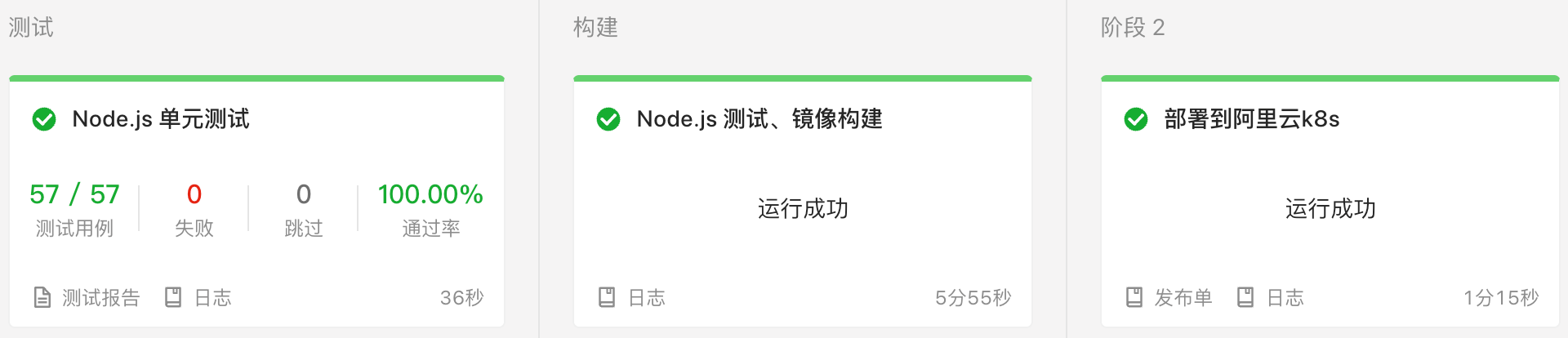
在单元测试中,写一些代码验证服务是否连通,若无法连通就断言失败,从而阻止后续的构建和部署。点击测试报告,还有专门的分析页面可以查看。
需要注意的是,在单元测试中不能在数据库中增加数据,以免造成线上数据的混乱。
3)回归测试
测试组会在我们修改完BUG后,会做回归测试,不过目前是依赖人工回归。
测试组最近正在研发自动化的回归,有望以后也集成到代码发布流程中。
对于一些有特殊要求的业务,测试组还会做压力和性能测试。
五、工具
有句话叫能依靠工具就不要依赖流程,能建立流程就不要依赖人的主动性。
在我们团队内部已经发布了协作流程、活动配置、Git分支管理等规范。
在制订规范后,解决了很多问题,不过如果有工具加持,那么工作效率可以提升的更高。
1)自研
根据公司业务和技术栈,我们组自研了很多工具。
榜单活动配置直接释放了4个组的人力,从原先的3天开发时间,降低到了1小时,经过时间的沉淀,活动也能更稳定。
通用配置已服务于5个小组,大大降低了开发和测试成本,不用再为一个小需求大动干戈。
BFF平台减少了接口的开发和调试成本,以及冗余的增删改查代码,加速与页面的联调。
依托VSCode开放的API,自研了一个插件,可以选中某个方法,直接从路由层跳转到服务层的声明处,便于查看源码逻辑。
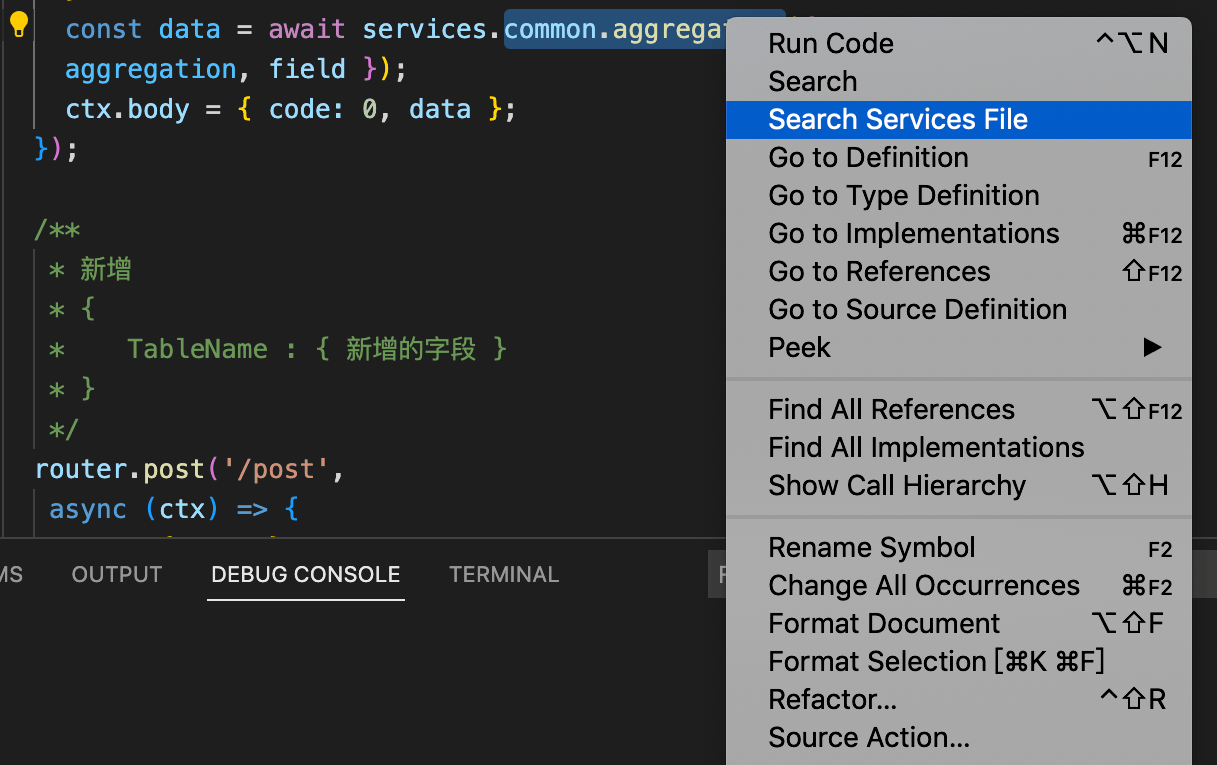
2)第三方
有些工具还是需要第三方提供,我们或是直接使用,或是做一层封装。
在研发过程中,我们会频繁地将自己分支与测试分支合并,然后再手动发布代码。
后面将合并与发布自动关联,合并后就自动去发布代码,减少了枯燥的手动操作。
要访问公司的管理后台需要进入内网,内网会限制IP,需要先将IP加入到白名单内,才能访问。
原先是运维手动添加,但是有点工作量,后面就根据阿里云提供的接口,我们自行创建了一套管理界面。
后续增加、删除和查询都在此管理界面中操作,权限也开放给了相关人员。
3)Code Review
Code Review的好处在有很多人分析过,不再赘述,团队内部已举办十多场。
我们组会对比较重要且复杂的业务做Code Review,目的是为了发现研发人员没有想到的问题。
当大家在看代码和理解其思路时,可以对写法、逻辑提出自己的看法。
还可以避免在协作时才会发现的问题,尽早解决减少损失。
顺便说下,为了提升技术氛围,内部的技术分享也在持续推进中,已举办二十多场,成员轮流主讲。


