
前端监控系列2 |聊聊 JS 错误监控那些事儿原创
作者:彭莉,火山引擎 APM 研发工程师。2020年加入字节,负责前端监控 SDK 的开发维护、平台数据消费的探索和落地。
有必要针对 JS 错误做监控吗?
我们可以先假设不对 JS 错误做监控,试想会出现什么问题?
JS 错误可能会导致渲染出错、用户操作意外终止,如果没有 JS 错误监控,开发者完全感知不到线上这些异常情况。特别是像电商、支付这类业务,用户无法下单和付款。即便站点有反馈渠道,但是等到有用户反馈的时候,说明影响面已经不小了。
因此像 JS 错误监控这类异常监控的存在,就是为了能及时发现线上问题、帮助快速定位问题,从而提升站点稳定性。
如何监控 JS 错误
大多数的 JS 错误都是由 JS 引擎自动生成的,比如 TypeError ,常常在值的类型不是预期的类型时触发、SyntaxError 常常在 JS 引擎解析遇到无效语法时触发。
对于一些可预见的错误,通常可以使用 try/catch 捕获,而一般不可预见的错误都抛到了全局,因此可以通过监听全局的 error 事件收集到 JS 错误。
const handleError = (ev: ErrorEvent) => report(normalizeError(ev))
window.addEventListener('error', handleError)
不过浏览器中未处理的 Promise 错误比较特殊,它需要额外监听全局 unhandledrejection 事件来收集。
const handleRejection = (ev: PromiseRejectionEvent) => report(normalizeException(ev))
window.addEventListener('unhandledrejection', handleRejection)
通过上面的全局监听,我们可以采集到错误的基本信息,包括错误类型、错误信息(错误的简短描述)、错误的堆栈、引发此错误的行列号和文件路径等信息。
不过这些信息都太过简略,无法帮助定位问题,无法感知到用户做了怎样的操作触发了这个错误、用户当前的浏览器型号、系统版本是怎样的、用户当前在哪个页面以及是通过怎样的方式进到页面的。
如何帮助定位问题
我们需要收集更多的 JS 错误发生时/发生前的上下文,为排查 JS 错误提供更多的思路。
怎样采集用户当前的环境信息
环境信息包括用户当前的浏览器类型和版本、系统类型和版本、设备品牌等信息。监控 SDK 主要是通过采集 UserAgent 来获取基础信息,但是解析出具体浏览器、系统和设备品牌其实是十分复杂的,具体的解析工作需要由服务端承担。
有了这些数据,我们就能很快从单个 JS 错误的分布情况判断出这个 JS 错误的影响范围,特别是如果这个 JS 错误是一个兼容性问题,一眼就能看出来,比如它只发生在特定浏览器上。
怎样为堆栈不完整的错误补充更多上下文
同步的错误通常是带有完整的堆栈信息的,但是异步的堆栈却只包含极少的堆栈信息。举个例子, 在页面上增加一个按钮,按钮的点击会触发如下一段代码。
const triggerJSError = () => {
const data = {
not: { found: 'test' },
}
delete data.not
console.log(data.not.found)
}
这种同步代码触发的 JS 错误的堆栈能提供很多信息。比如在这个例子中,从堆栈中可以看出这个错误是经由 click 事件,而后触发了 triggerJSError 方法,最后发生了这个 JS 错误。
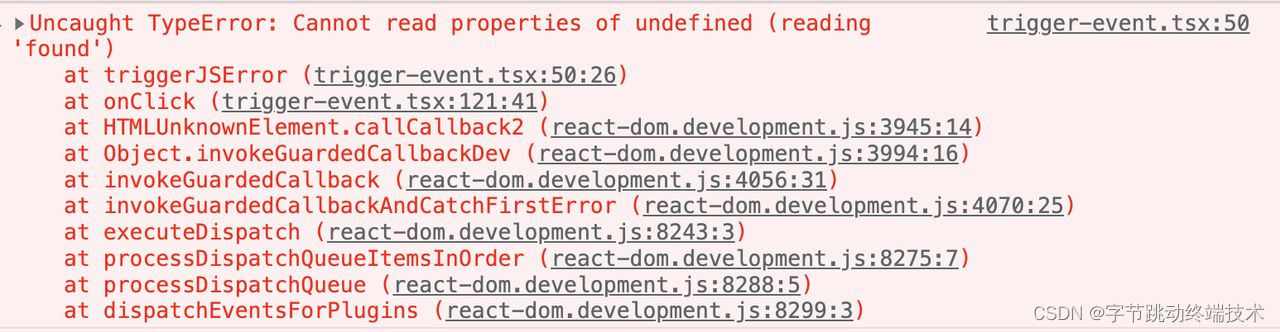
但是异步代码的报错却很难提供更多的信息。比如下面这个例子,错误由异步调用触发,从报错的堆栈里完全看不出来它是经由 click 事件,也看不出来是触发了 triggerJSError 方法。
const triggerJSError = () => {
const data = {
not: { found: 'test' },
}
delete data.not
+ setTimeout(() => {
console.log(data.not.found)
+ })
}

这是浏览器本身的事件循环机制导致的。异步任务需要等到同步任务执行完成后,再从异步队列里取出异步任务并执行,这个时候是无法沿着调用栈回溯这个异步任务的创建时的堆栈信息的。
为了更方便地排查这类错误,监控 SDK 会对一些全局的异步 API 以及全局事件 API 进行 try/catch包装,捕获到错误时补充 API 调用信息,再原封不动地将错误抛出去。虽然堆栈信息并没有填补完整,但是能提供一些辅助信息,比如 当前这个异步调用的JS 错误是经由哪个 API 调用,最终触发了这个 JS 错误的。
关于采集 JS 错误的部分看起来已经结束了? 但当我们看线上真实的JS错误时,发现线上错误的堆栈难以理解,方法名都被压缩过了,文件名也变成了打包后的文件名,无法提供有用的信息。
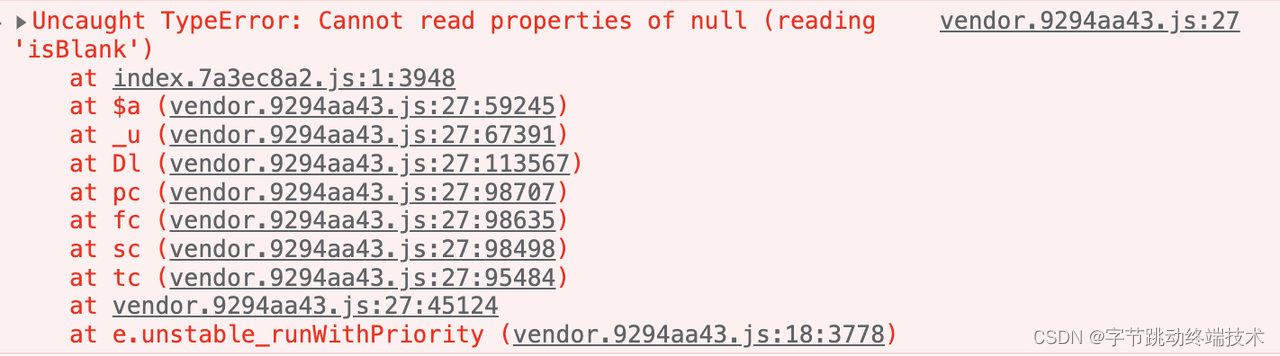
那么监控平台是如何做到错误一上传就能显示原始堆栈的呢?
如何自动解析出原始堆栈
线上的 JS 错误堆栈为什么看不懂
研发编写的代码与线上实际运行的代码之间存在着很多处理,比如:
-
打包并压缩代码。将多个 JS 文件打包成一个 JS 文件来减少资源请求数量;通过缩短变量名、去除空格和其他复杂的压缩方式来减少资源体积,以便更快的加载 JS 文件;
-
兼容处理。工程师往往热衷使用新的 JS 特性。但是由于浏览器对这些特性支持度低,在编译时,往往需要利用 Babel 等工具将这些新特性转换成更兼容的形式;
-
从另一种语言编译成 JS 。使用另一种语言编写,最终编译成 JS 。比如 TypeScript、PureScript 等等。
这些处理不仅可以提升编码体验,还能优化性能、提升用户体验。
当然有利就有弊,这也导致线上的代码与最初编写的代码相差甚远,让排查问题就变得非常棘手,而source map 正是用来解决这个问题的。
什么是 source map
简单来说,source map 维护了混淆后的代码行列与原代码行列的映射关系,就算只知道混淆后的堆栈信息,也能通过它得到原始堆栈信息,从而定位到真实的报错位置。
下方是一个source map 的示例,它通常包含 version / file / sources / mappings 等等字段,这些字段里也隐含着它为什么能反解出原始代码的奥秘。
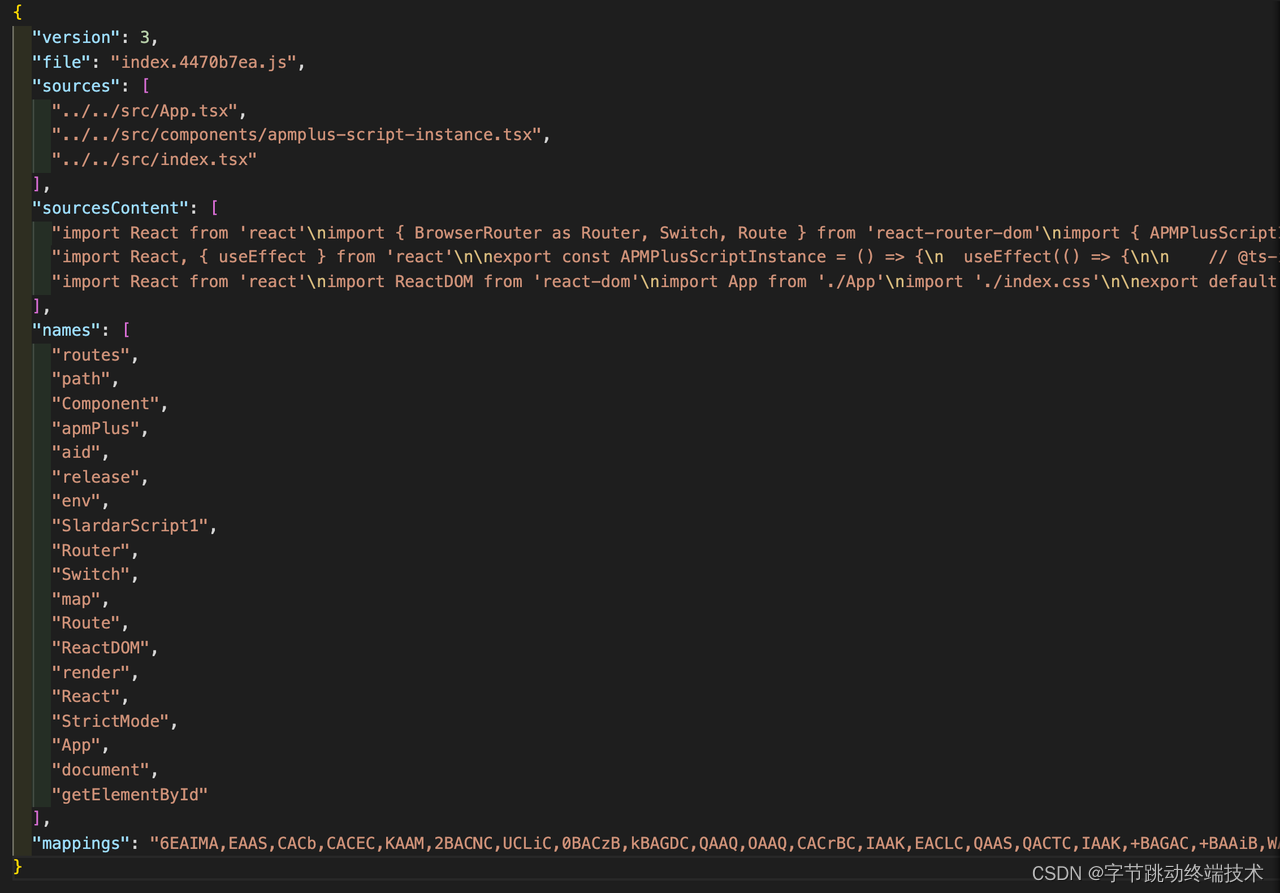
sources 包含转换前的文件路径,names 包含转换前的所有变量名和属性名,sourcesContent 包含转换前文件的内容,file 包含转换后的文件名。
mappings 字段看起来很神秘,简而言之,mappings 字段维护的是压缩代码到源代码之间的映射关系,可以映射到源代码的任何部分,包括标识符、运算符、函数调用等等。它分为三层, 一层是行对应, 一层是位置对应,还有一层是位置转换,以 VLQ 编码表示位置对应的转换前的源码位置。这样就能实现从混淆代码到源码的映射关系,从而实现堆栈反解。
常规的监控平台都会提供自动上传 source map 的工具,这样 JS 错误上报到平台后就能自动显示原始错误的堆栈。
下面这个截图就是反解成功后展示的原始堆栈示例,从原始堆栈可以看出,这个 JS 错误是因为 250 行的 blankInfo 没有判空导致。
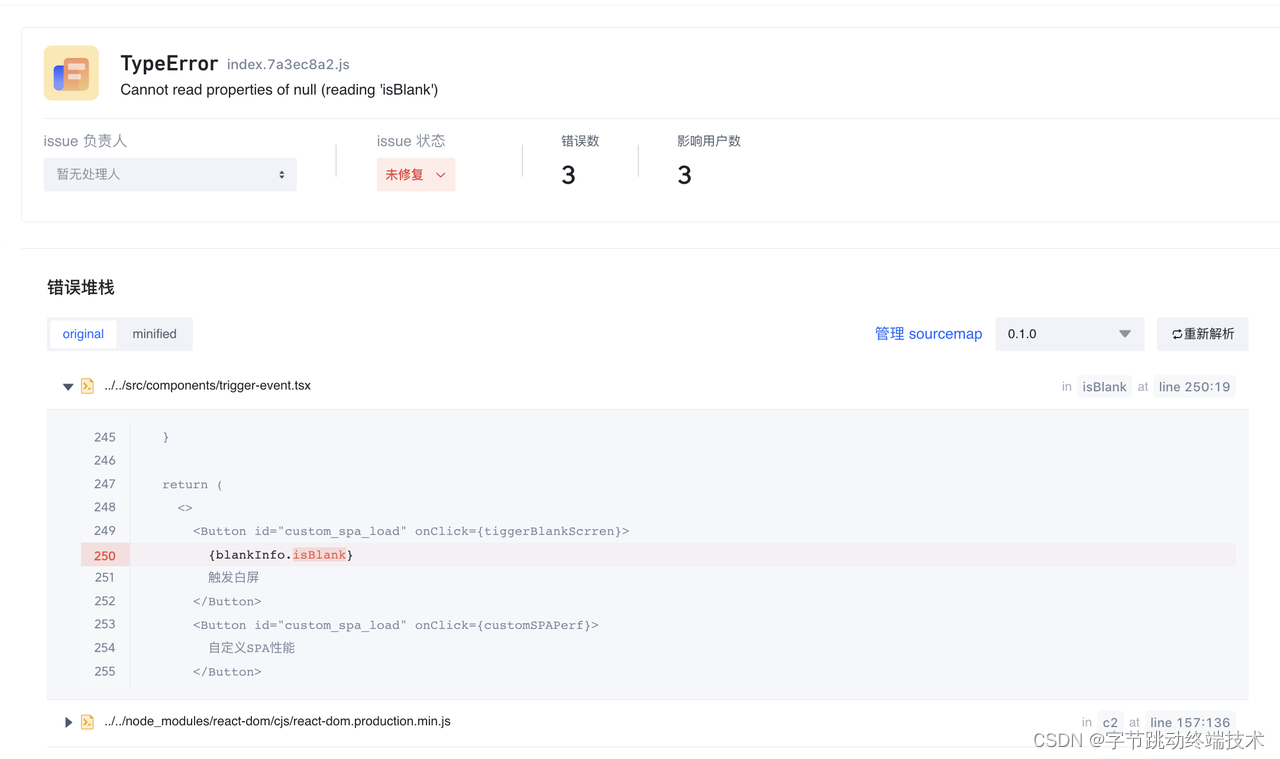
现在原始堆栈也有了,错误的上下文信息也有了。打开监控平台一看,发现确实监控到了很多的JS错误,但是有很多重复的错误,一眼望不到头。

有没有什么办法,能够只看到不同的错误呢?毕竟从研发的角度讲,无论一个错误上报千次万次,终究都只是对应一个需要修复的问题。
如何判断两个错误是否相同
假设能做到这一点,那么就能将相同的错误归类在一起,研发看到的就是每一个不同的错误,就能减少噪音。但是如果聚合的方式有问题,就会导致不同的 JS 错误聚合在了一起,这样可能造成错误的遗漏。
那么怎样的聚合算法才是合适的呢?
same name + same message !== same error
在上报的错误属性中,只有 name 和 message 是标准属性,其他属性都是非标准属性,是不是使用这两个字段聚合错误就可以?
在实际应用中,我们发现仅靠 name 和 message 并不能做到有效聚合错误。两个错误 name 和 message 相同,但是可能来源于不同的代码段。这样可能导致我们修复了其中一个错误后,误以为相关的所有错误都被修复了,从而遗漏错误。
将堆栈信息纳入聚合算法中
在实际聚合算法中,我们将反解后的堆栈纳入了计算,将堆栈拆分为一系列的 frame, 更细致的提取堆栈特征,在每一个 frame 内重点关注其调用函数名、调用文件名以及当前执行的代码行,如果这些信息都相同,可以认为是同一个错误。
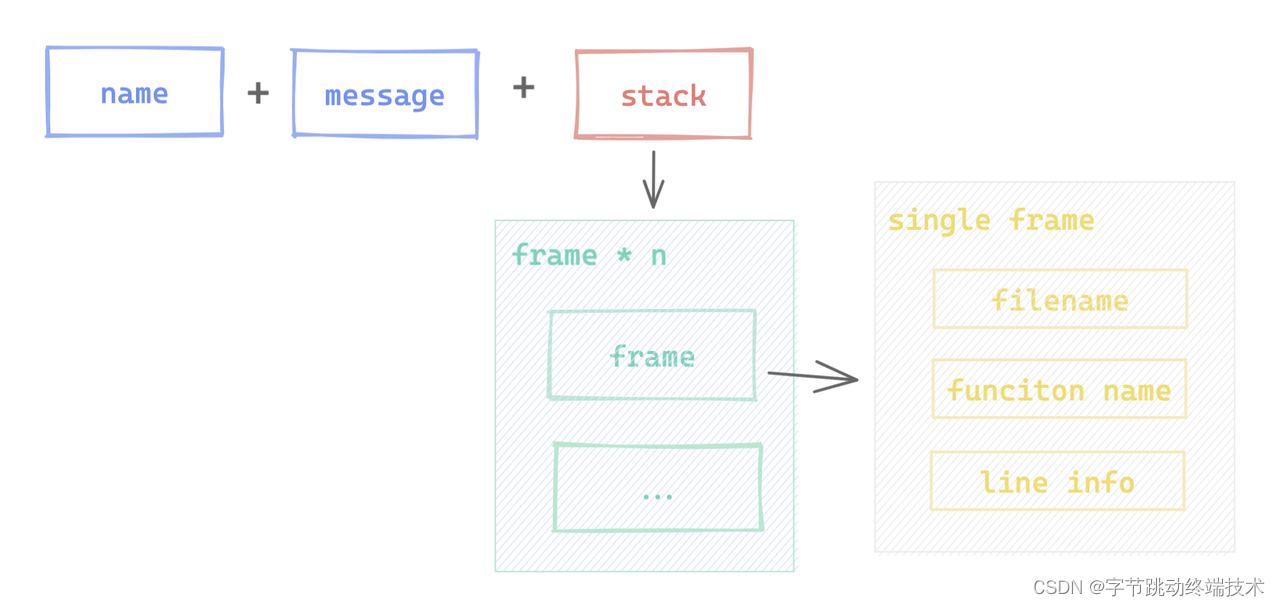
为了方便识别,我们会利用上述信息,通过 hash 计算最后生成一个 issueId 作为我们识别相同错误的标识。生成 hash 的过程比较复杂,除了常规提取计算外,会针对递归调用、匿名路径、匿名函数等进行跳过,也会避开某些计算开销过大的 case 。
久而久之,监控平台上出现了很多 JS 错误,但是这些错误好多都是已经在处理的错误,有没有办法能只在出现新的 JS 错误的时候通知到我呢? 这样既能及时关注到、又可以做到不遗漏。
如何判断一个新的错误的出现
刚刚提到,我们通过聚合算法把同类的错误聚合在了一起,并且标记成了一个 issueId 。那么我们就可以通过判断这个 issueId 是不是一个新的 issueId 来实现目的。如果是的话,就代表有新增的 JS 错误。
当然这种新增的思路不仅可以用在 JS 错误这种异常数据上,也同样可以用在其他异常数据上。只要识别到了一个新增的异常,就可以自动发通知,研发就能立即关注并开始处理。
那么问题来了,所找到的 JS 错误出现的原因如果是另一个同事写的代码导致的,应该怎么办?
是直接告知他去修复这个问题呢?还是先不管了?或者有没有办法,能够自动把这个“锅”给到他,这样尴尬的问题就解决了。
线上 bug 自动分“锅”
手动指定处理人的方式比较生硬,完全依赖团队的主动性。实际上,既然已经知道原始堆栈,如果还能知道线上代码对应的仓库,我们就可以做得更细致一些。比如根据对应报错的代码行,结合 Gitlab / Github 的 open-api ,实现自动分“锅”。
如何找到某条 JS 错误对应的处理人
以 Git Blame 为例,通过下面的命令就能获取到特定文件对应行的相关 commit 信息,包括提交者/ 改动内容 / 提交时间,足够定位谁是处理人。
git blame -L <range> <file>
-
file 对应是文件路径,也就是解析出来的原始堆栈的文件路径信息
-
range 对应的是查找的范围,也就是解析出来的原始堆栈的行号范围
分“锅”不够准?
默认用来 blame 的文件都是最新版本,但线上跑的不一定是最新版本的代码。
我们可以认为一次新的发布就是一个新版本的产生,不同版本的代码可能发生行的变动,从而影响实际代码的行号。如果无法将线上运行版本和用来 blame 的文件版本对齐,就很有可能突然背“锅”。
因此我们需要知道两个问题:线上发生的错误是属于哪个版本的?如何拿到对应版本的仓库文件代码?
问题一比较好实现,在编译时注入一个版本的环境变量,保证监控时能够带上这个信息就行。
import client from '@apmplus/web'
client('init', {
...
release: 'v0.1.10'
...
})
问题二不好解决,仓库代码不可能给到监控平台方,更别说拿到对应版本的仓库代码了。
其实不用拿到整个仓库代码,也可以做一些 commits 关联来实现,通过相关的二进制工具,在代码发布前的脚本中,将 commits 关联上同一个版本号。这样线上发生 JS 错误后,我们就可以通过线上报错的版本找到原始代码文件对应的版本,再通过前面提到的 Gitlab / Github 的 open-api 定位到真正的处理人,就可以直接通知对应的处理人处理问题。
由此,JS 错误监控实现了闭环。
欢迎使用
目前字节的这套前端监控解决方案已同步在火山引擎上,接入即可对 Web 端真实数据进行实时监控、报警归因、聚类分析和细节定位,解决白屏、性能瓶颈、慢查询等关键问题,欢迎体验。
扫描下方二维码,立即申请免费使用⬇️



