
XRP:用eBPF优化内存存储功能原创
作者简介
李浩宇:目前为美国哥伦比亚大学计算机科学系的二年级博士生,在导师Asaf Cidon教授的指导下开展有关存储系统的研究。在此之前,李浩宇同学于上海交通大学先后取得本科及硕士学位,在并行与分布式系统研究所(IPADS)进行Java虚拟机内存管理方面的研究。
赵佳炜:一线码农,在某服务器公司担任存储研发工程师,日常喜欢研究存储相关技术、内核基本原理。
本文系基于李浩宇博士直播内容整理,感谢佳炜同学对本次直播内容进行整理。
1.背景

随着存储设备的升级与发展,当代的存储设备性能越来越高,延迟也越来越低。对于内核而言,Linux I/O 存储栈的软件所带来的性能开销已经越来越不可忽视。同样在 512B 的随机读条件下,在采用二代 Optane SSD 作为存储设备的测试例⼦中,内核软件( Linux 存储栈)所带来的性能开销已经⾼达 50%。
2.传统方式与XRP
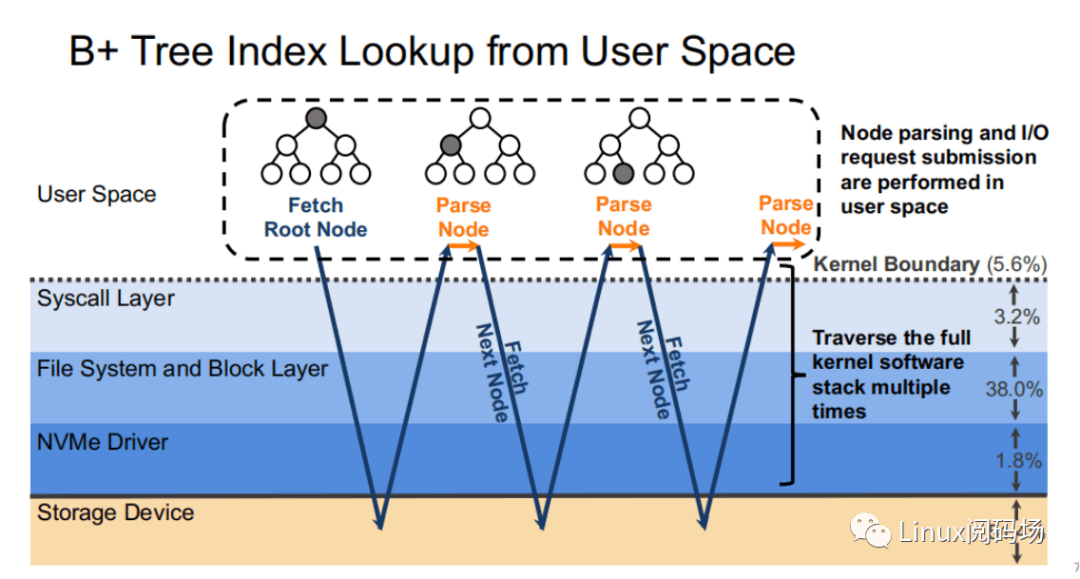
我们来看⼀个实际的例⼦,假设现在有⼀棵树⾼为 4 的 B+ tree 存储于存储设备当中。当我们从根节点出发,⼀共需要经过三次访盘才能获得最终的叶⼦节点,⽽中间的索引节点对于⽤户⽽⾔没有意义,但也需要经过⼀个完整的存储栈路径。⽽每次访盘的过程中,存储栈所花费的开销就要整个存储路径的 48.6%。
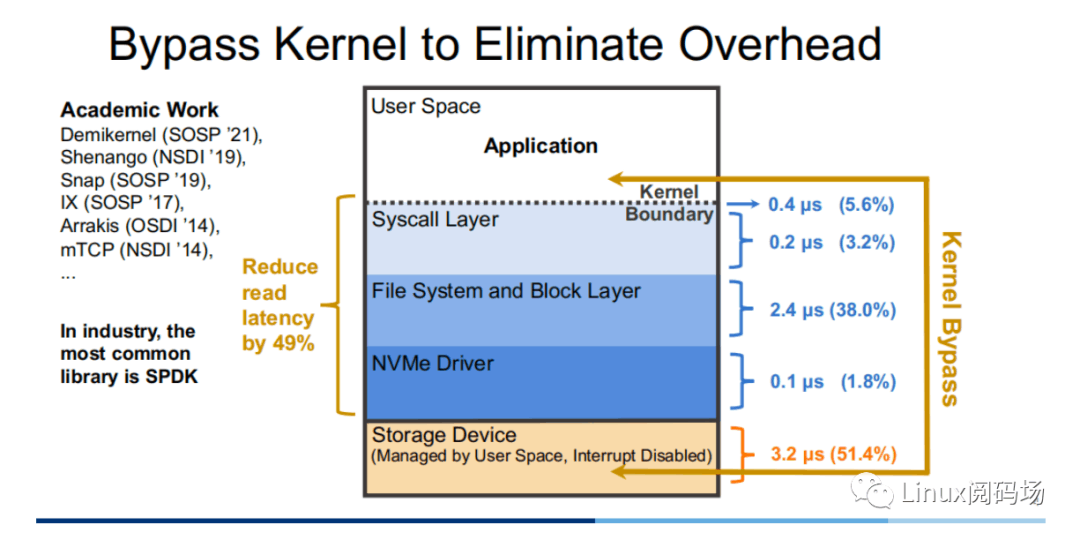
显然,冗⻓的存储栈路径钳制了⾼性能存储设备的发挥,那么⼀个直观的优化思路便是通过 Kernel Bypass 的⽅式,绕开内核中存储栈,以提升存储性能。⽬前在学术界中,对于这⽅⾯的⼯作有 Demikernel、Shenango、Snap 等,⽽⼯业界中最为⼴泛使⽤的则是 Intel 的 SPDK。
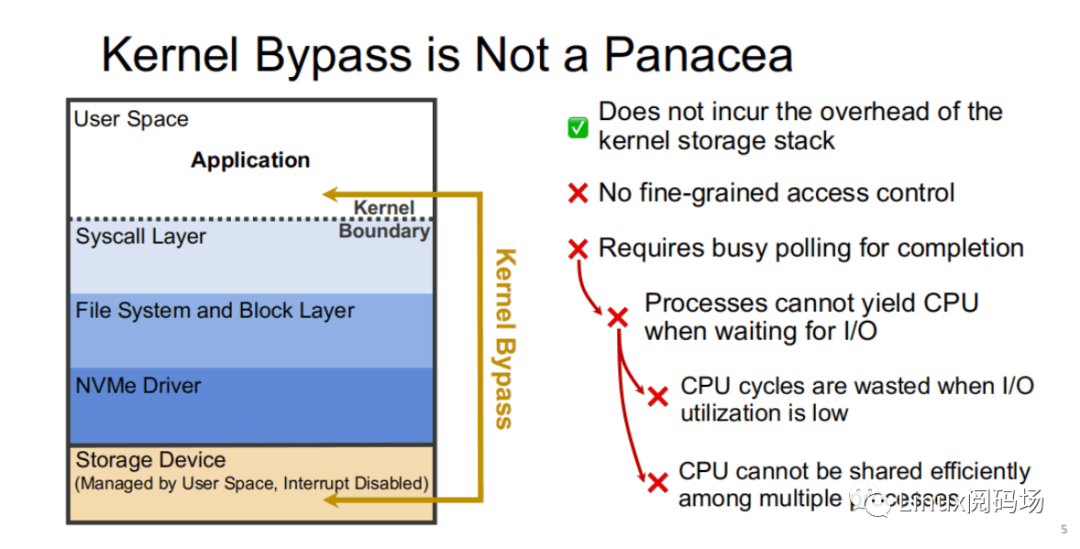
然⽽,Kernel Bypass 技术并⾮银弹,它虽然能够降低内核存储栈的开销,但也存在着如下缺点:
1. 没有适当粒度的访问控制
2. 需要采⽤ polling ⽅式来判断 I/O 是否完成,这会导致在 I/O 利⽤率低时,Polling 进程所在的 CPU ⼤部分情况下只是在空转,浪费 CPU 周期,同时 CPU 资源不能⾼效地在多进程中共享。
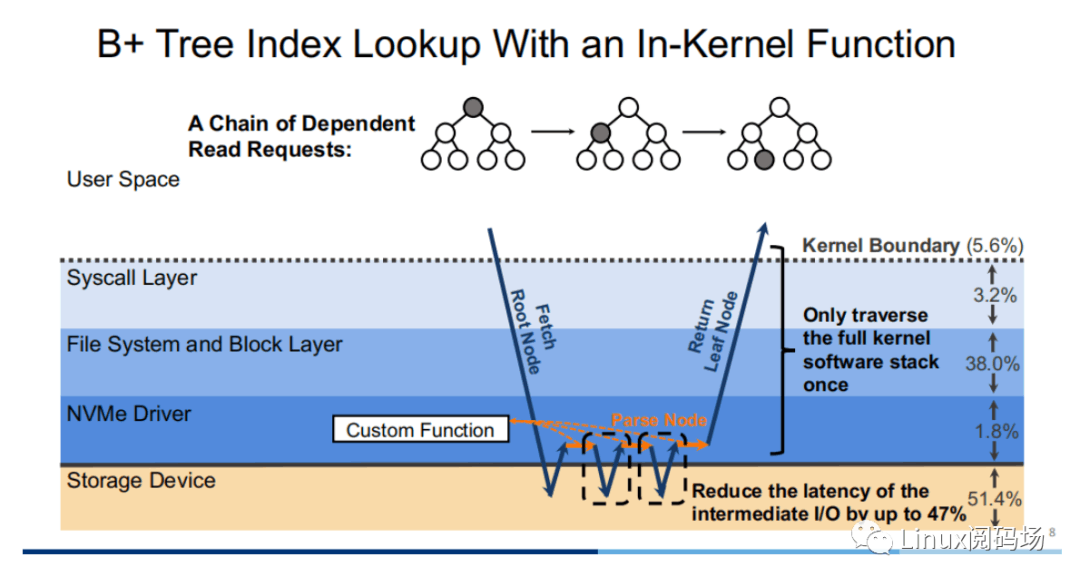
所谓 XRP 的全称是 eXpress Resubmission Path(快速重提交路径)。与 SPDK 完全绕开内核存储栈,采⽤ polling的⽅式来访问存储的⽅式不同,XRP 则是通过将中间请求直接在 NVMe 驱动层进⾏ resubmission,从⽽避免让中间请求通过冗⻓的存储栈后再提交,从⽽达到加速的⽬的。反映到上⾯的例⼦当中,可以明显地看到使⽤ XRP 存储访问⽅式中,只有第⼀次请求和最后⼀次响应会经过⼀个完整的存储栈路径。显然,在允许范围内,B+ tree的树⾼越⾼,XRP 的加速效果也就越明显。
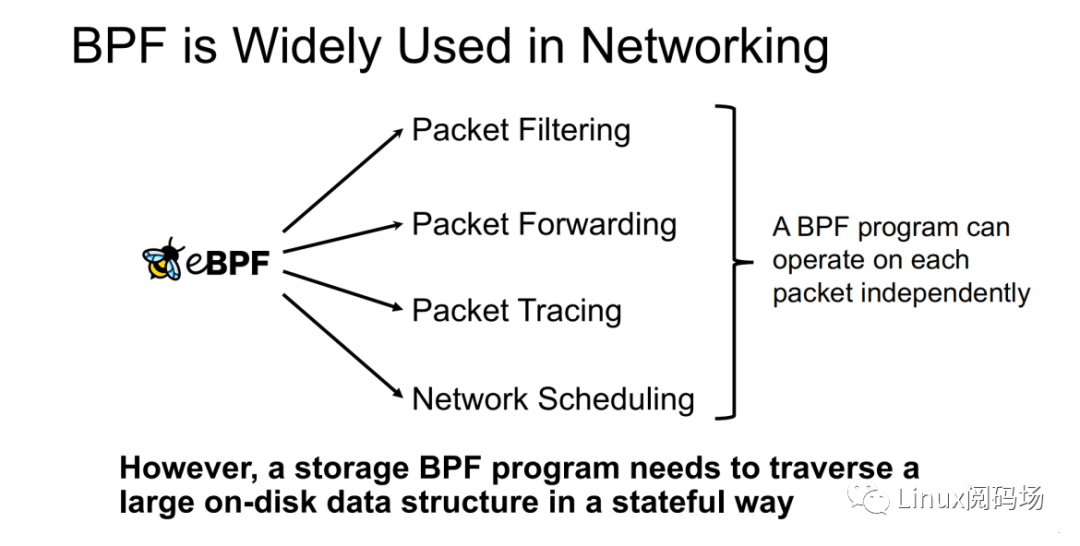
既然优化思路有了,那么应当如何才能将请求重提交于 NVMe 驱动层呢?这⾥可以借鉴 XDP 的实现思路。XDP 通过 eBPF 来实现对每个数据包进⾏独⽴的操作(数据包过滤、数据包转发、数据包追踪、⽹络调度)。XRP 也可以通过 BPF 程序来实现。
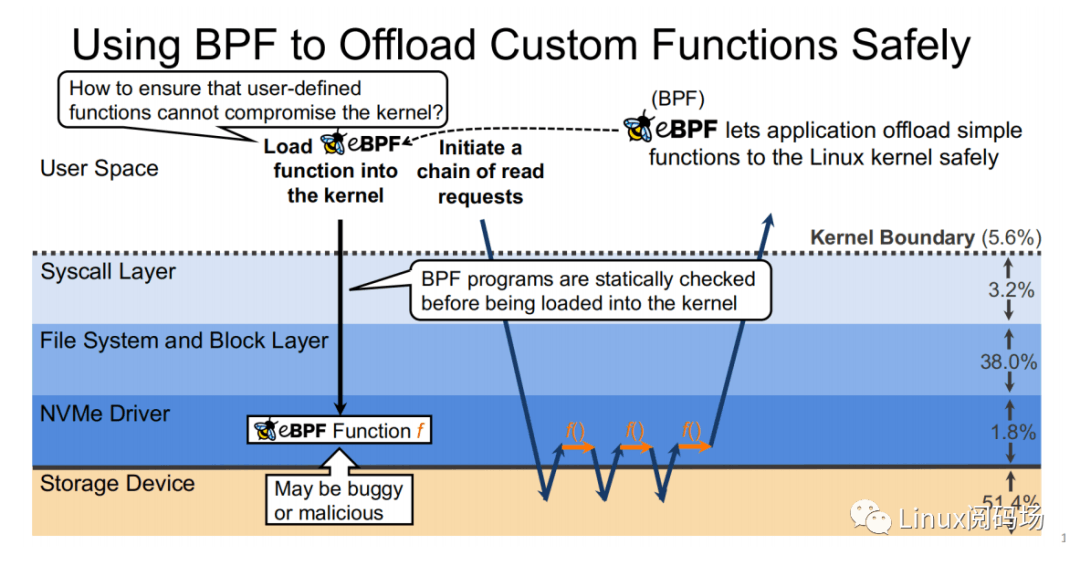

XRP 是⾸个使⽤ eBPF 来降低内核存储软件开销的系统。它所⾯临的挑战主要有:
1. 如何在 NVMe 驱动层实现对⽂件偏移的翻译
2. 如何强化 eBPF verifier 以⽀持存储应⽤场景
3. 如何重新提交 NVMe 请求
4. 如何与应⽤层 Cache 进⾏交互

XRP 引⼊了⼀种新的 BPF 类型(BPF_PROG_TYPE_XRP),包含了 5 个字段,分别是
1. char* data:⼀个缓冲区,⽤于缓冲从磁盘中读取出来的数据
2. int done:布尔语意,表示 resubmission 逻辑是否应当返回给 user,还是应当继续 resubmitting I/O 请求
3. uint64_t next_addr[16]:逻辑地址数组,存放的是下次 resubmission 的逻辑地址
4. uint64_t size[16]:存放的是下次 resubmission 的请求的⼤⼩5. char* scratch:user 和 BPF 函数的私有空间,⽤来传递从 user 到 BPF 函数的参数。BPF 函数也可以⽤这段
空间来保存中间数据。处于简单考虑,默认 scratch 的⼤⼩是 4KB。
同时,为了避免因存在⽆限循环⽽导致 BPF Verifier 验证失败,代码中指定了 B+ tree 的最⼤扇出数为
MAX_FANOUT,其值为 16。

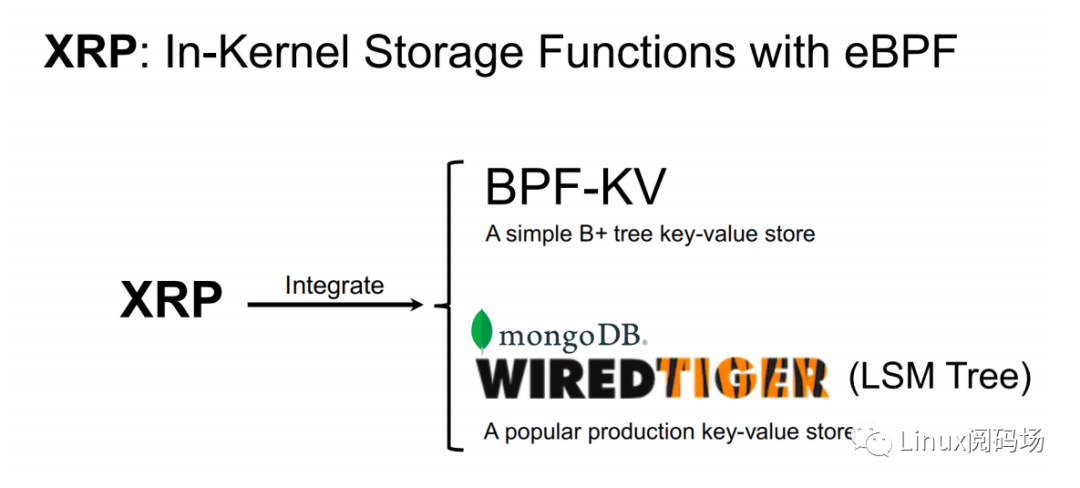
⽬前,最常⻅链式读请求主要有 B-Tree 和 LSM Tree 两种,⽽ XRP 分别继承了 BPF-KV(⼀个简易的基于 B+ Tree的键值存储引擎) 和 WIREDTIGER(mongoDB 的后端键值存储引擎)。
3.实验测试
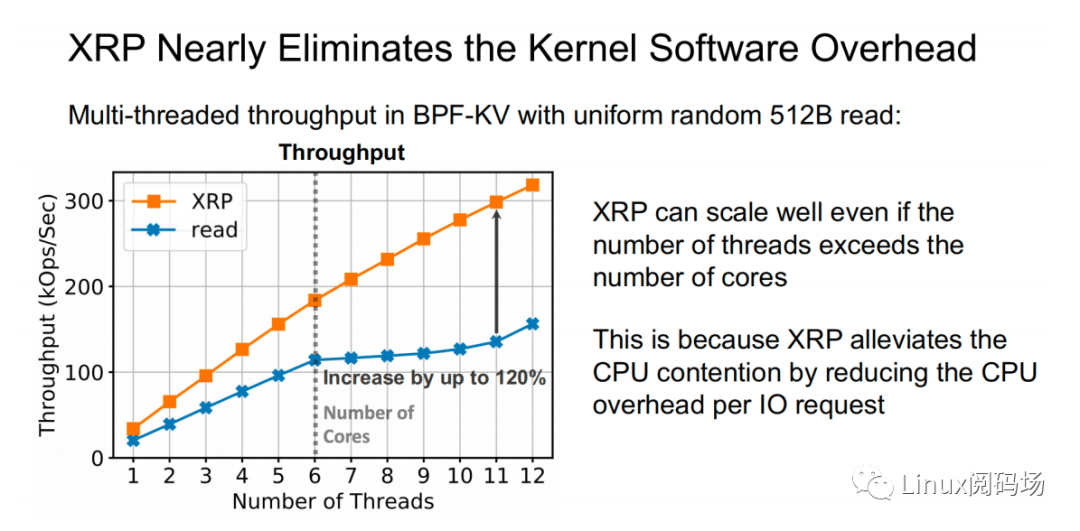
上图为在 512B 随机读测试中,标准 read 和 XRP 之间的性能对⽐测试。可以看到随着线程数的增加,XRP 的吞吐保持线性增⻓的态势,同时 XRP 通过降低每次 I/O 请求时的 CPU 开销,从⽽缓解了 CPU 争⽤问题。
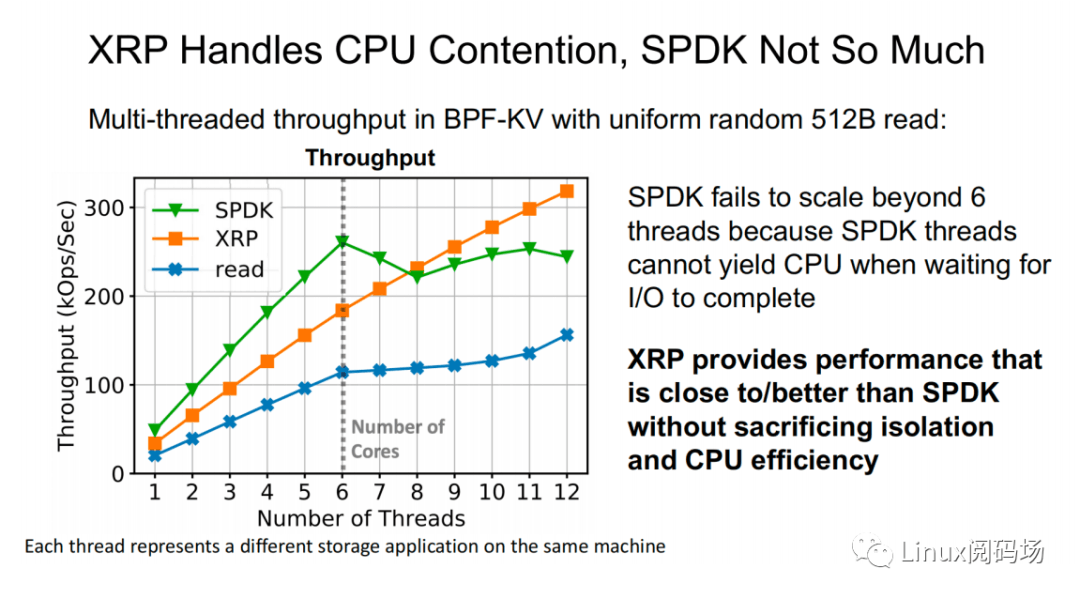
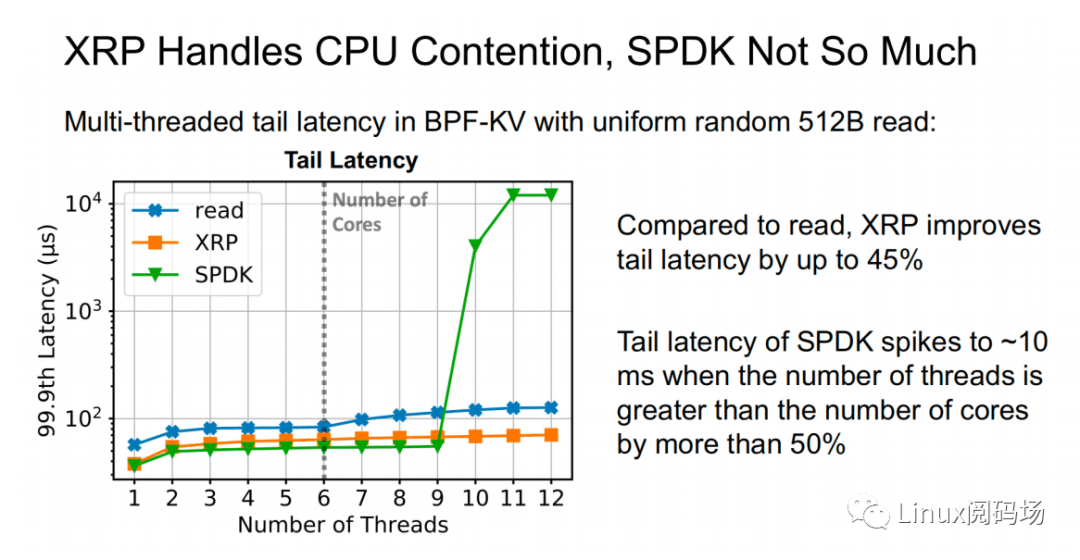
上⾯两幅图中,同样表示了在 512B 随机读测试中(CPU 核⼼数为 6),标准 read、XRP 和 SPDK 之间的吞吐量以及尾延迟的对⽐。在线程数⼩于等于 CPU 核⼼数时,三者性能变化稳定,从⾼到低依次为 SPDK > XRP >read。⽽当线程数超过了核⼼数时,SPDK 性能开始出现严重的下跌,标准 read 性能轻微下滑,⽽ XRP 依然保持着稳定的线性增⻓。这主要是因为 SPDK 采⽤ polling 的⽅式访问存储设备的完成队列,当线程数超过核⼼数,线程之间对 CPU 的争夺加上缺乏同步性,会导致所有线程都经历尾部延迟显著提升和整体吞吐量的显著下降。
4.总结

XRP 是⾸个将 BPF 应⽤来通⽤存储函数的加速上的系统,它既能享受到 kernel bypass 的性能优势,同时⼜⽆须牺牲 CPU 的使⽤率和访问控制。⽬前,XRP 团队依然在积极地将 XRP 与其他⼀些流⾏的键值存储引擎,如 RocksDB进⾏集成。

