
记录两次多端排查问题的过程原创
我们组会负责后端的一些服务,因此出现问题时不仅仅是界面的样式兼容问题,还有很多其他的后台服务问题。
排查后面这类问题,需要具备些服务端的排查手段,否则就会难以定位问题所在。
一、聊天问题
公司有一个即时聊天的功能,在 6 月 2 日周五,上了一个自动推送个性文案的功能,大受好评,访问量迅速蹿升。
UV 一度增加了六七千,在高兴的同时,问题也接踵而至,例如匹配不到聊天对象、跳转页面时卡住白屏和聊天界面卡顿问题。
其实这些问题之前也存在,但因为用户量小,没有被大规模的曝光。
这次用户量上来后,在 3、4、5 号端午三天,客服不间断地收到投诉。由此可见,量大后,再小的问题也会被放大。
鉴于问题的表现都是在我们 Web 这一端,所以需要我们先进行排查。
排查的步骤分三步:首先需要确定问题是由哪一端触发的,其次确定问题影响范围和制定优先级,最后联合相关组一同给出解决方案。
在让其他端配合排查之前,需要先确保自己那块没有问题。
在将目前上报的所有问题分类后,发现大部分遇到的是第三个问题:聊天卡顿,这部分要安排更多的精力来解决。
1)匹配不到
当匹配不到时,就会像下图那样一直处于等待匹配中,用户不得不关闭界面。
匹配失败是因为账号被锁住了,由我们组负责优化。
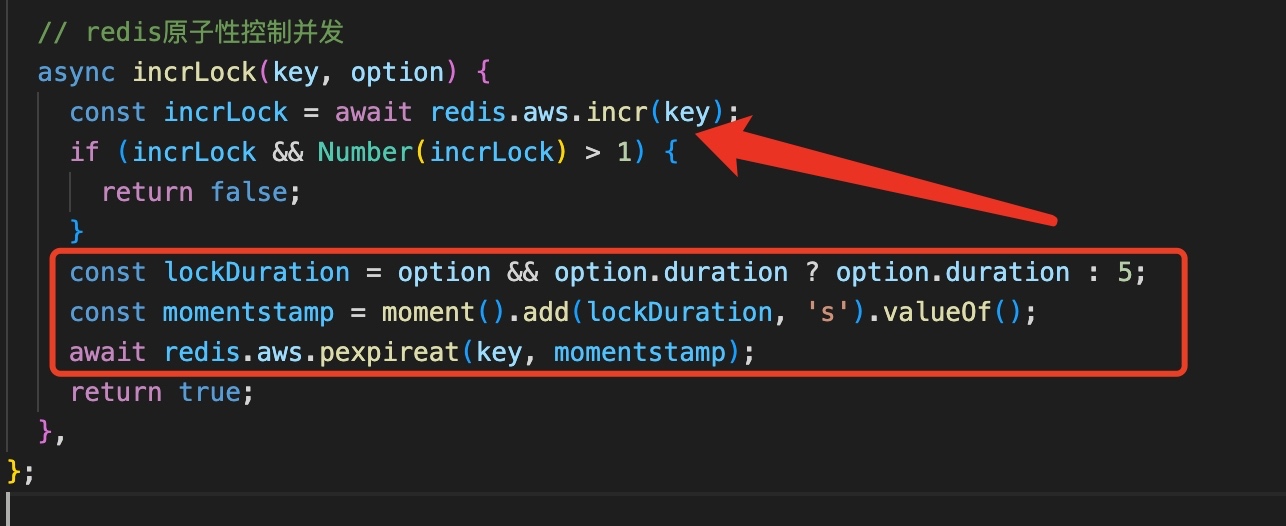
在匹配时会创建一个并发锁,正常情况是3秒后过期或在某个位置解锁,但出现异常后,没有成功解锁导致用户一直处于锁住状态。
// redis原子性控制并发
async incrLock(key, option) {
const incrLock = await redis.aws.incr(key);
if (incrLock && Number(incrLock) > 1) {
return false;
}
const lockDuration = option && option.duration ? option.duration : 5;
const momentstamp = moment().add(lockDuration, 's').valueOf();
await redis.aws.pexpireat(key, momentstamp);
return true;
}
为了保证锁能过期,将过期的配置提升至if语句之前。
2)跳转卡住
这个问题非常奇怪,遇到此问题的都是安卓用户(华为、VIVO 和小米),进度条卡在下图的位置就进行不下去了。
查看客户端日志,发现其实已经请求了聊天页面(chat.html)。
06-05 12:08:12.730 1 INFO/AppForeground: WebViewActivity onCreate true
06-05 12:08:12.841 1 INFO/WebViewActivity: loadUrl https://security.xxx.me/safe_redirect?url=https%3A%2F%2Fs.xxx.me%2Fc%2F1Gf4Gf
06-05 12:08:12.867 1 INFO/AppForeground: WebViewActivity onStart
06-05 12:08:12.872 1 INFO/ChatServiceManager: startService true
06-05 12:08:12.873 1 INFO/AppForeground: WebViewActivity onResume
06-05 12:08:13.074 1 INFO/WebViewActivity: processUrl else true url:https://s.xxx.me/c/1Gf4Gf
06-05 12:08:13.394 1 INFO/AppForeground: MainActivity onStop
06-05 12:08:13.669 1 INFO/WebViewActivity: processUrl else true url:https://www.xxx.me/game/chat.html?entry=appchatpush
06-05 12:08:15.063 1 INFO/AppForeground: WebViewActivity onPause
06-05 12:08:16.064 1 INFO/AppForeground: WebViewActivity onStop
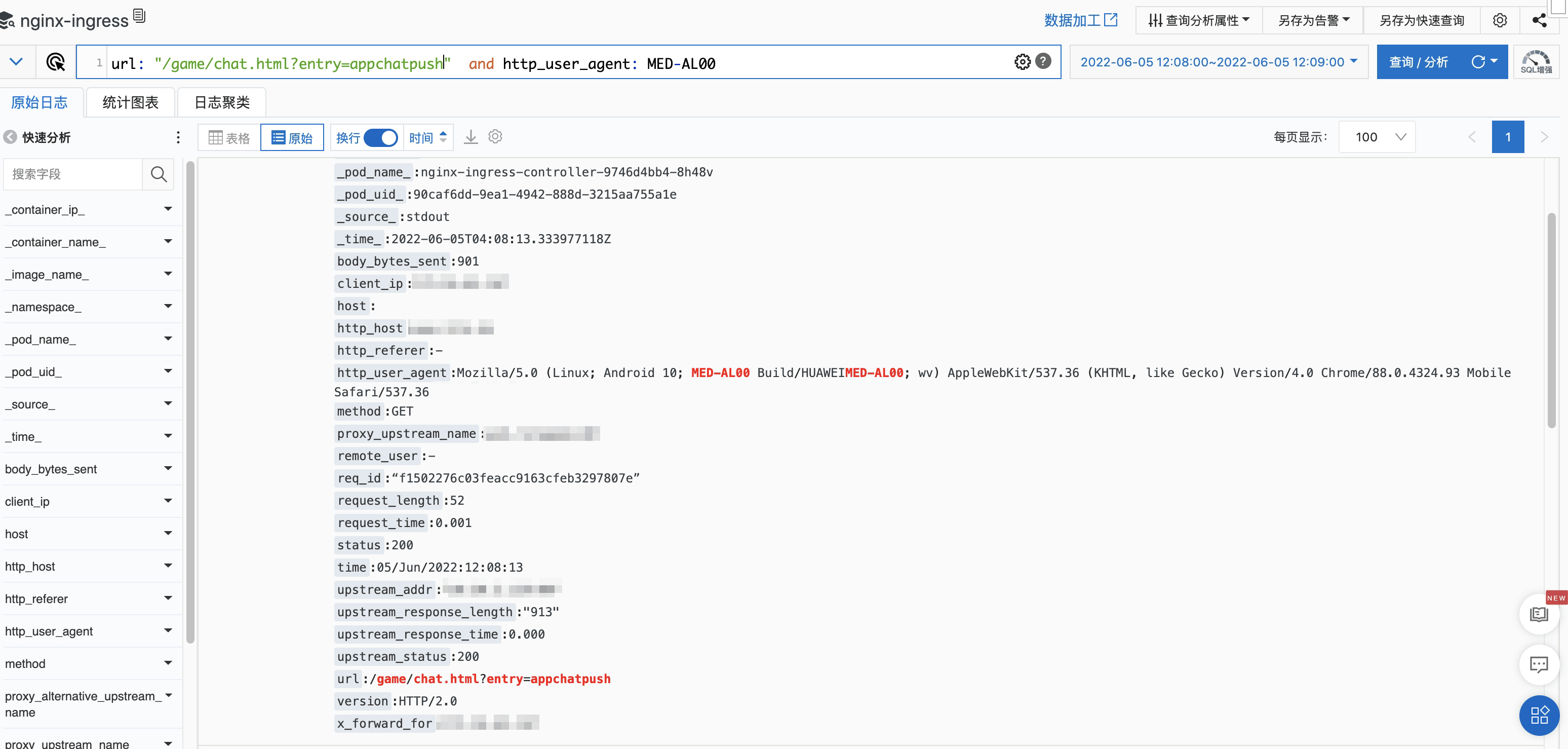
查看Nginx 服务器访问日志,发现的确在那个时刻收到了来自于客户端的请求。
url: "/game/chat.html?entry=appchatpush" not url: zh_cn and http_user_agent: MED-AL00
但是在查找脚本的请求日志时(game/js/chat.719c3c70.js 和 game/js/chunk-vendors.11311460.js),并没有发现。
由此可推断,要么就是客户端没有发送请求,要么就是服务器当时没有响应,需要客户端帮忙排查。
3)聊天卡顿
这个问题主要是客户端排查,我们组配合打印关键信息(console.warn())。
后面我们对页面脚本也做了一次优化,实现组件区域化的渲染,避免整个大组件的渲染。
4)异常流量
在将相关组拉在一起开会时,运维反馈,在 6 月 4 日 23:42-23:43 之间有股异常流量,而 22:00-01:00 也是公司 APP 最为活跃的时间。
这股异常流量促使短链服务和长连接发生大量的 502/503/504 的报错。
查看 Nginx 日志(如下图所示),发现有个明显的凸起高峰,也正好是在那段时间发生的。
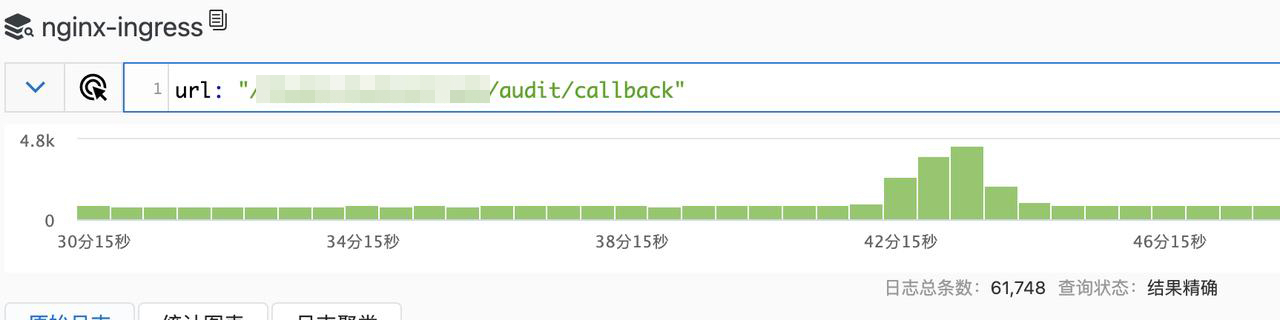
经查,在这段时间内,进入聊天页面的埋点只收到了 1 个。运维怀疑是 api 项目的一个回调接口影响了 api 的其他服务。
6 月 6 日晚上 20 点,将此接口服务迁出,单独作为一个服务(就是路由转发),当天晚上的错误从之前的 500 多降到了 60 多。
为了弄清楚长连接发生异常时,有哪些用户受到了影响,因此在 /socket 地址上还附带上了用户 ID。

5)下一步动作
在 6 号开完会议后,就马上修复了我们这边的几个问题,以及运维的问题。
查询聊天匹配完成的曲线图,发生呈明显的上升趋势,匹配率增幅 23% 以上,这是一个让人振奋的消息。
客户端因为无法复现,所以需要添加埋点,例如增加键盘交互等事件的监听,还需要优化键盘弹出方案,这些都得发布新版本。
所以要下一个版本中解决卡顿的问题。
二、内存问题
我们组的静态资源都单独放在一台服务器中,静态资源就是图片、HTML、JavaScript 和 CSS 等文件。
运维和我反馈说,这些服务器的内存会一直涨,除非重启容器后,内存才会降下来。
我的第一反应是内存是不是泄漏了,服务器中有个聊天的页面,会不会是建立了大量的 websocket 连接,没有被释放掉。
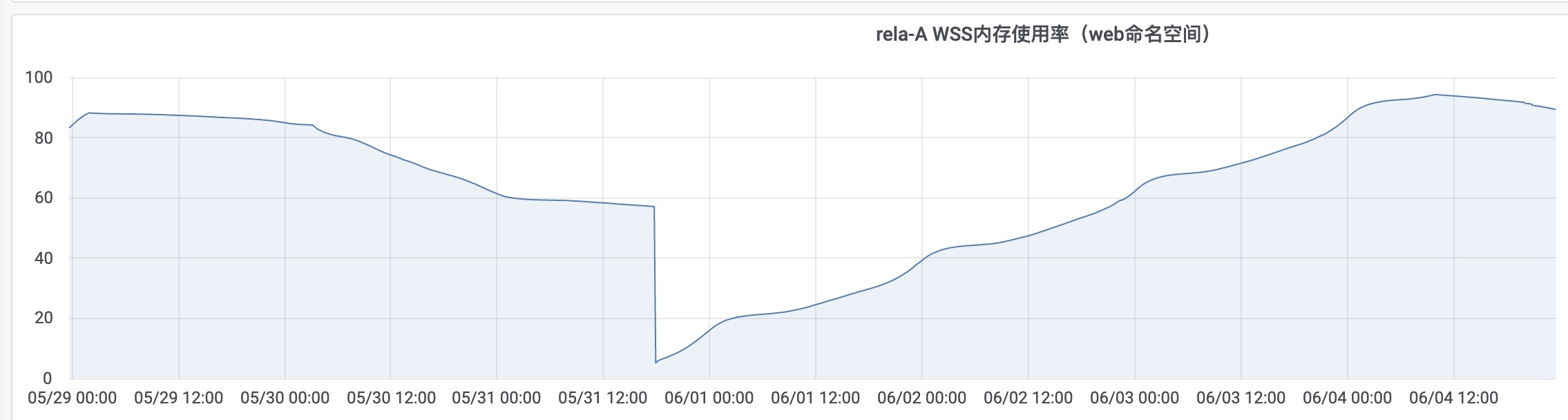
但是转而一想,应该不是,因为这些文件会被传输到用户浏览器中,发起的连接也是存在于客户端,不会影响服务端的内存。
进入到服务器中,输入 ps aux 命令,查看正在运行的进程,发现有好多 worker process。
问运维,说这些都是 Nginx 的进程,后面就让他去优化,他改了个配置,内存增长的幅度是变小,不过依然会慢慢增长。


