
宁可信鬼,也不信 iowait 这张嘴!原创
我们经常遇到iowait这个名词,在top命令中,vmstat中,sar命令中,都有它的身影。很多同学按照经验,当看到iowait非常高的时候,一般判定为磁盘I/O有瓶颈,但这并不完全正确。 io并不是一个可靠值。
比如下面几个问题。
iowait处于100%时,还能够运行其他CPU密集型应用么?
iowait处于90%以上,就一定证明io有问题么?
iowait占用非常少时,就一定证明io没问题么?
1、数值来自哪?
上面提到的这些监控工具,看起来监控的值包容万象,但这些数字都不是它们去算的。这些数字,静悄悄的躺在内存文件系统/proc/stat中,而进程的数据,躺在/proc/${pid}/stat中。但是如果不经过这些工具的加工,我们去辨识这些数值的话,是由难度的。
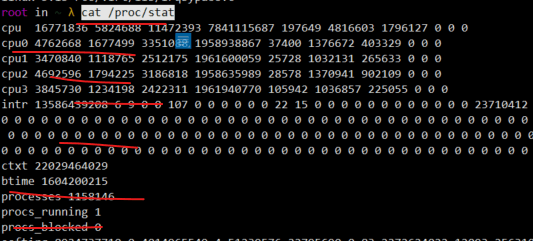
在info命令中,可以看到iowait的解释。
%iowait
Percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.
解释模糊不清,但显然是和磁盘I/O有关的。这里没有提到网络I/O,所以和网络I/O关系不大,但与网络文件系统如NFS等密切相关。
每一个cpu都会有下多种状态中的一个。
- user 处于用户态进程执行
- sys 处于系统态内核执行
- idle 处于空闲状态,但不证明cpu不运行,由于处于空转状态,所以能耗特别低
- iowait 处于等待I/O的状态
总体上,遵循下面的公式。
CPU时间=user+sys+nice+idle+iowait+irq+softirq+steal
从字面上的意思来看,iowait像是一直阻塞在那里等待I/O操作完成,但实际情况是,CPU并不会做这种无谓的等待,它只是反映了等待I/O完成的一个比例。
为什么CPU不会等待磁盘I/O呢?因为磁盘实在是太慢了,磁盘上的文件块,读入内核缓冲区的这个过程,是交给DMA去做的。cpu只是响应一下中断,就进入了被中断完成的唤醒状态。此时,如果有新的任务到来,这些cpu资源依然能够挪动身躯去做。
内核会周期性的记录这些统计数据,它首先判断cpu是不是空闲的,如果不是,则判断是在内核态还是用户态;如果不是,则会判断是否有磁盘I/O请求被当前的CPU发起,如果有则增加iowait的值,如果没有则增加idle的值。
sar等命令,会读取/proc/stat中的数据,进行二次加工。由于sar本身也有一个刷新频率,所以它展现的是统计值。
2. 从现象看本质
为了弄清楚iowait的表现,我们来看几个例子。
案例1
假如我们写了一个小型的数据库,运行在1核的机器上。这个数据库,会使用cpu计算一些数据,花费10ms,然后同步写入磁盘,花费20ms,那么整个操作下来,要花费30ms,也就是tps = 33。此时,iowait就是66%,而user就是33%。
而如果换成了ssd,写磁盘只花费了1ms。那么此时的tps = 90,iowait就变成了 8%左右。
案例2
我们再来想想一下,现在cpu计算数据的过程,换成了dd命令,它不会做过多的计算,几乎不耗费时间,此时,写磁盘依然花费1-2ms的时间,我们的tps达到了500-1000左右。iowait增加了,但我们的吞吐量竟然也增加了,可以说工作的更好。
案例3
现在考虑另外一种相反的极端情况。我们的应用cpu产生文件只需要1ms,但写入磁盘需要1秒。那么此时iowait会达到99%左右。此时,我们再启动另外一个进程,它是一个死循环,会耗尽所有的CPU资源。这个进程一加入,就抢占了空闲的CPU时间片。现在去看系统显示,iowait的状态会降低到接近0,idle的状态也会接近0。但这可怜的系统,此时并不是没有问题,因为我们的磁盘,可一直是在I/O操作之中。
100%的iowait没有问题,但1%的iowait问题却很大。
参考:https://blog.pregos.info/wp-content/uploads/2010/09/iowait.txt
由于多核的参与,事情会更复杂。因为iowait是个统计值,sar等命令直接观测的也是多个核数的统计值,所以在两台机器上运行良好的程序,指标的显示也会相差很大。
关键就在于,iowait和idle是一个此消彼长的关系,它们两个加起来,就是系统目前可以被使用的cpu时间片。iowait过高,不代表它不能够运行其他计算性任务了,其他的进程或者线程,还能够继续运行。我更愿意把iowait认为是idle的一部分,这样更容易理解一些。
3. 经验来源
那iowait过高,磁盘有问题,这个印象是怎么养成的呢?
原因还是由于IO资源的规划问题。假如你的系统写了非常非常多的日志,此时iowait应该是跑满了。假如你用的是同步写日志的方式(大多数都是),那么大多数线程就要等待这些繁忙的I/O请求。这个等待,是真的等待,因为这些线程在磁盘写成功之前,什么都干不了。以tomcat默认200个线程为例,请求量一增加,就全部占满了,进入了BLOCKED状态。
此时的应用反应是:应用几乎什么都响应不了。机器上的其他进程,也响应缓慢。但是注意,应用的线程不能运行了,不代表其他应用的线程不能运行。线程处于BLOCKED状态,并不会占用CPU。只要多加一块磁盘,和其他磁盘隔离开来,就能解决问题。
xjjdog这里抛出一个遇到过的极品问题。
ElasticSearch 的速度是非常快的,我们为了压榨它的性能,对磁盘的读写几乎是全速的。它在后台做了很多 Merge 动作,将小块的索引合并成大块的索引。还有 TransLog 等预写动作,都是 I/O 大户。
问题是,我们有一套 ES 集群,在访问高峰时,有多个 ES 节点发生了严重的 STW 问题。有的节点竟停顿了足足有 7~8 秒。
[Times: user=0.42 sys=0.03, real=7.62 secs]
从日志可以看到在 GC 时用户态只停顿了 420ms,但真实的停顿时间却有 7.62 秒。盘点一下资源,唯一超额利用的可能就是 I/O 资源了(%util 保持在 90 以上),GC 可能在等待 I/O。
原因就在于,写 GC 日志的 write 动作,是统计在 STW 的时间里的。在我们的场景中,由于 ES 的索引数据,和 GC 日志放在了一个磁盘,GC 时写日志的动作,就和写数据文件的动作产生了资源争用。
解决方式也是比较容易的,把 ES 的日志文件,单独放在一块普通 HDD 磁盘上就可以了。所以在这种情况下,iowait不变,却能解决问题。
End
问题是,现在的很多企业,已经上了docker等虚拟化环境,iowait就更成为一个操蛋的指标。Linux的8种namespace:挂载点、进程、网络、ipc、uts、user、cgroup、time等。其中,cgroup能限额cpu、限额内存、限额磁盘容量,也能限额磁盘io,限制磁盘的读写iops,这会让本身就慢的磁盘用起来更慢。但如果不限制io,完全放开,对于宿主机的磁盘使用,大家就会哄抢,就要看运气!所以限制业务无限制的日志io需求,一直在进行中。
电池和磁盘技术,可真是限制科技发展的两大枷锁啊。
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。我的个人微信xjjdog0,欢迎添加好友,进一步交流。



