
mcp内核稳定性问题定位思路与方法原创
简介
任何系统,硬件故障和软件故障都不可避免。比如车载系统,由于汽车行驶过程中的震动,发热,电瓶馈电等,很容易影响电子元件的特性,这对设备是致命的影响,会直接改变程序逻辑及运行结果从而产生各种不可预测的异常情况,本文描述常见问题的排查方法帮助快速排查定位问题所在也提出一些系统性设计来规避这些问题.
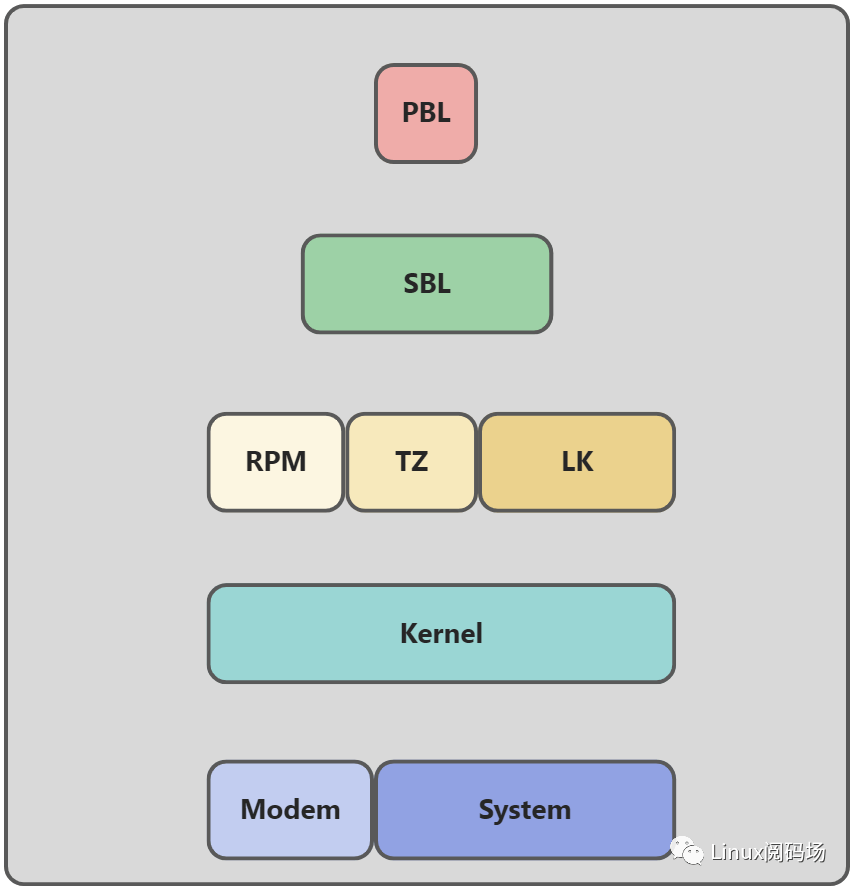
启动流程初判断
我们对稳定性分析第一手分析本上是从debug log开始,它可以直观的给我们信息反馈, 想对debug log 中的问题进行判断还需要我们对设备的启动流程有充分的了解,在什么阶段使用了哪些资源同时又有哪些硬件参与其中。
通过分割流程,细化加载过程可以对当前疑问点从合理性进行解释,以高通启动为例:
B - 381616 - clock_init, Start
D - 183 - clock_init, Delta
B - 381860 - Image Load, Start
D - 87230 - QSEE Image Loaded, Delta - (1541808 Bytes)
B - 469120 - Image Load, Start
D - 335 - SEC Image Loaded, Delta - (2048 Bytes)
B - 506391 - sbl1_efs_handle_cookies, Start
D - 671 - sbl1_efs_handle_cookies, Delta
B - 508282 - Image Load, Start
D - 12383 - DEVCFG Image Loaded, Delta - (55764 Bytes)
B - 521184 - Image Load, Start
D - 20099 - RPM Image Loaded, Delta - (180504 Bytes)
B - 541314 - Image Load, Start
D - 52277 - APPSBL Image Loaded, Delta - (579748 Bytes)
B - 593621 - QSEE Execution, Start
D - 122 - QSEE Execution, Delta
从启动流程可以知道每一个阶段的启动都包含着数据完整性检查,当secboot开启时还有合法性检查; 通过这个帮助我们初步判断异常位置明确下一步分析方向;
Nand Flash排查
针对nand flash的分析要先了解其构造;
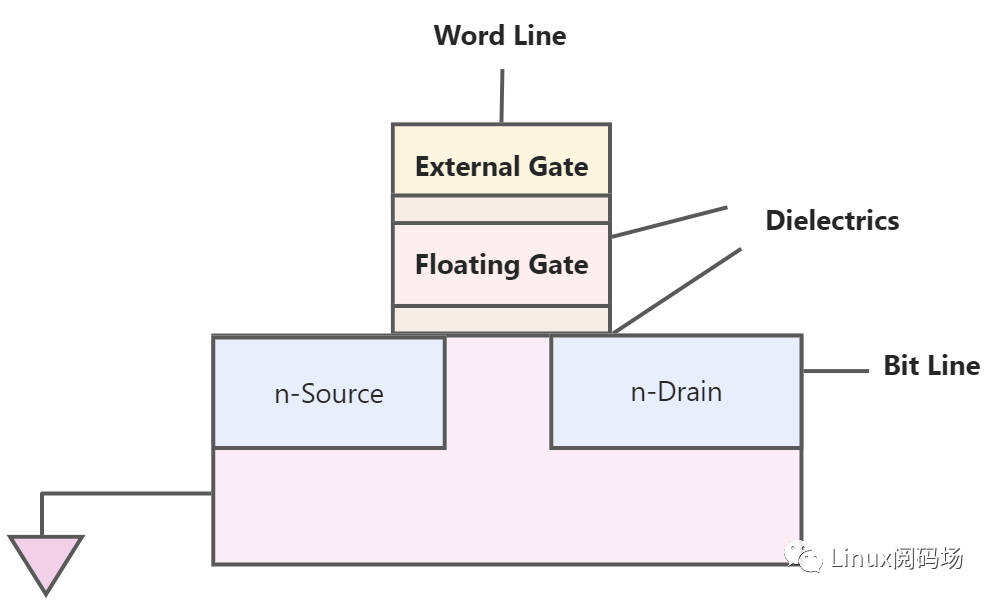
Flash的内部存储是MOSFET,里面有个悬浮门(Floating Gate),是真正存储数据的单元。
数据在Flash内存单元中是以电荷(electrical charge) 形式存储的。存储电荷的多少,取决于图中的外部门(external gate)所被施加的电压,其控制了是向存储单元中冲入电荷还是使其释放电荷。而数据的表示,以所存储的电荷的电压是否超过一个特定的阈值Vth来表示,因此,Flash的存储单元的默认值,不是0(,而是1,而如果将电荷释放掉,电压降低到一定程度,表述数字0。
Nand 的缺点数据读写容易出错,所以一般都需要有对应的软件或者硬件的数据校验算法,统称为ECC, 每一个页,对应还有一块区域,叫做空闲区域(spare area)/冗余区域(redundant area),而Linux系统中,一般叫做OOB(Out Of Band),这个区域,是最初基于Nand Flash的硬件特性:数据在读写时候相对容易错误,所以为了保证数据的正确性,必须要有对应的检测和纠错机制,此机制被叫做EDC(Error Detection Code)/ECC(Error Code Correction, 或者 Error Checking and Correcting),所以设计了多余的区域,用于放置数据的校验值。
Oob的读写操作,一般是随着页的操作一起完成的,即读写页的时候,对应地就读写了oob。
关于oob具体用途,总结起来有:
1.标记是否是坏快
2.存储ECC数据
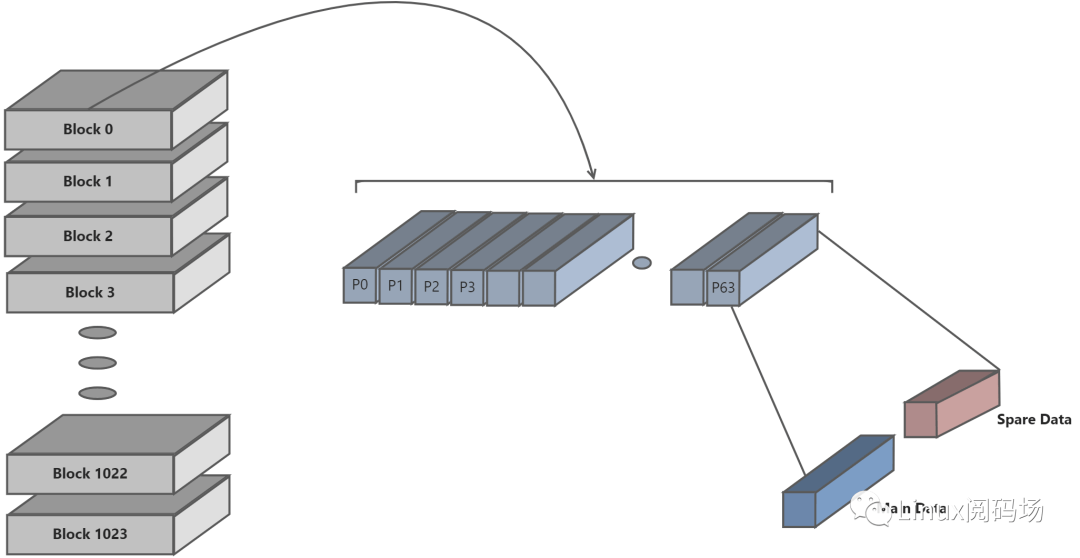
Nand Flash 结构
坏块
为什么会出现坏块?
由于 NAND Flash的工艺不能保证NAND的Memory Array在其生命周期中保持性能的可靠,因此,在NAND的生产中及使用过程中会产生坏块。坏块的特性是:当编程/擦除这个块时,不能将某些位拉高,这会造成Page Program和Block Erase操作时的错误,相应地反映到Status Register的相应位。
坏块的分类
总体上,坏块可以分为两大类
(1) 固有坏块:这是生产过程中产生的坏块,一般 芯片 原厂都会在出厂时都会将坏块第一个page的spare area的第6个byte标记为不等于0xff的值。
(2)使用坏块:这是在NAND Flash使用过程中,如果Block Erase或者Page Program错误,就可以简单地将这个块作为坏块来处理,这个时候需要把坏块标记起来。
坏块如何检测
坏块的判断方法非常简单对目标块擦除就可判断是否是坏块。
坏块的影响性
判断坏块并不是技术难点,问题是在于当产生坏块时系统稳定性如何去保障,这里就涉及到项目前期对整体稳定性设计;
根据固件格式大致可以分为三种:只读镜像,只读文件系统和数据分区
1.只读镜像
这里只读镜像在固件中SBL ,LK,Boot.img 等等镜像文件, 当镜像存储区域由于某种异常产生坏块就会破坏数据的完整性;
只读镜像大部分只会在加载过程中读取,后续运行在内存中,所以问题会在坏块产生后的下一次启动;
2.只读文件系统
文件系统跟只读镜像比较类似,差别在于文件系统并不是一次全部加载校验换句话说就是用哪里加载哪里,同样原理如果加载数据因坏块而导致失效系统也会崩溃;
3.数据分区
数据分区基本操作就是写入和擦除,所以当坏块产生时影响的是在分区中存储的数据;
数据存储根据使用功能的不同丢失的影响性也存在较大差异,文件系统中文件数据丢失表现为文件数据无法访问或者文件不存在访问失败;但当重要配置文件丢失, 证书文件,加密裸数据丢失同样会导致系统崩溃无法正常使用;
预防性设计
万幸的是使用过程中产生连续三个坏块的概率极低,这就给我们机会针对坏块预防性设计;那我们如何去解决这个问题呢?
了解坏块的产生和影响性,可以知道想要规避坏块需要我们在系统设计初就要考虑,在设备使用过程中有坏块产生时如何保证系统的稳定性;
针对产生的影响性加强系统稳定性设计:
1.只读镜像&只读文件系统
加大分区冗余度是可以降低坏块是在数据区的概率也会避免连续坏块导致烧录失败但会加大空间损耗,不过由于只读镜像基本不大可以选择加大冗余;
只是降低损坏概率还是完全无法保证系统的稳定性, 镜像分区设计可以帮助解决这个问题,通过启动流程异常检测可以帮助我们选择完整分区进行加载并恢复损坏分区;
两种设计可以大大增加系统整体的稳定性,不过多分区设计要注意邻区干扰要适当的分开;
2.数据分区
根据存储数据的必要性可以分为重要分区和普通分区;
多分区设计也适用于重要分区 通过多个分区保存重要文件和数据可以避免数据缺失而引发的问题;
分区文件丢失通过备份分区恢复文件;
分区损坏先格式化问题分区后在通过备份分区恢复文件;
由于空间限制重要文件和数据要与普通分区
普通分区由于坏块导致的异常完全可以通过格式化进行恢复;
Nand Flash Bit Flip
由于Nand物理特性最常见的异常问题就是产生Bit Flip(位反转) ;
什么是Bit Flip?
所谓的位反转,bit flip,指的是原先Nand Flash中的某个bit位,发生电容的0和1状态的切换, 这种情况称之为位反转(Bit Flip)
Bit Flip 产生的原因?
借鉴业内总结产生Bit Flip原因有如下几种:
1.漂移效应(Drifting Effects)
漂移效应指的是,Nand Flash中cell的电压值,慢慢地变了,变的和原始值不一样了。
2.编程干扰所产生的错误(Program-Disturb Errors)
此现象有时候也叫做,过度编程效应(over-program effect)。
对于某个页面的编程操作,即写操作,引起非相关的其他的页面的某个位跳变了。
3.读操作干扰产生的错误(Read-Disturb Errors)
此效应是,对一个页进行数据读取操作,却使得对应的某个位的数据,产生了永久性的变化,即Nand Flash上的该位的值变了。
在Nand Flash使用过程中可以总结一下几点:
1.读取干扰:读取 NAND flash page会对同一块中附近的存储单元产生干扰,过度读取最终会导致存储单元失去电荷丢失存储的数据。
2. 长期数据保留:存储在 NAND flash中的数据会随着时间的推移而损坏(即使不使用)。
3. 高温干扰:高温可能会导致电荷逃逸。随着温度的升高,数据损坏的速度会迅速增加。
4. 电磁干扰:电磁干扰可能会导致电荷不稳定。
Bit Flip 判断方法
我们知道Nand Flash 为了防止Bit Flip设计了ECC算法进行纠正位反转数据,我们也可通过ECC来判断Nand Flash是否产生了Bit Flip;
模拟page size 为2K ECC 能力为8 byte 的 ecc 分布 Layout
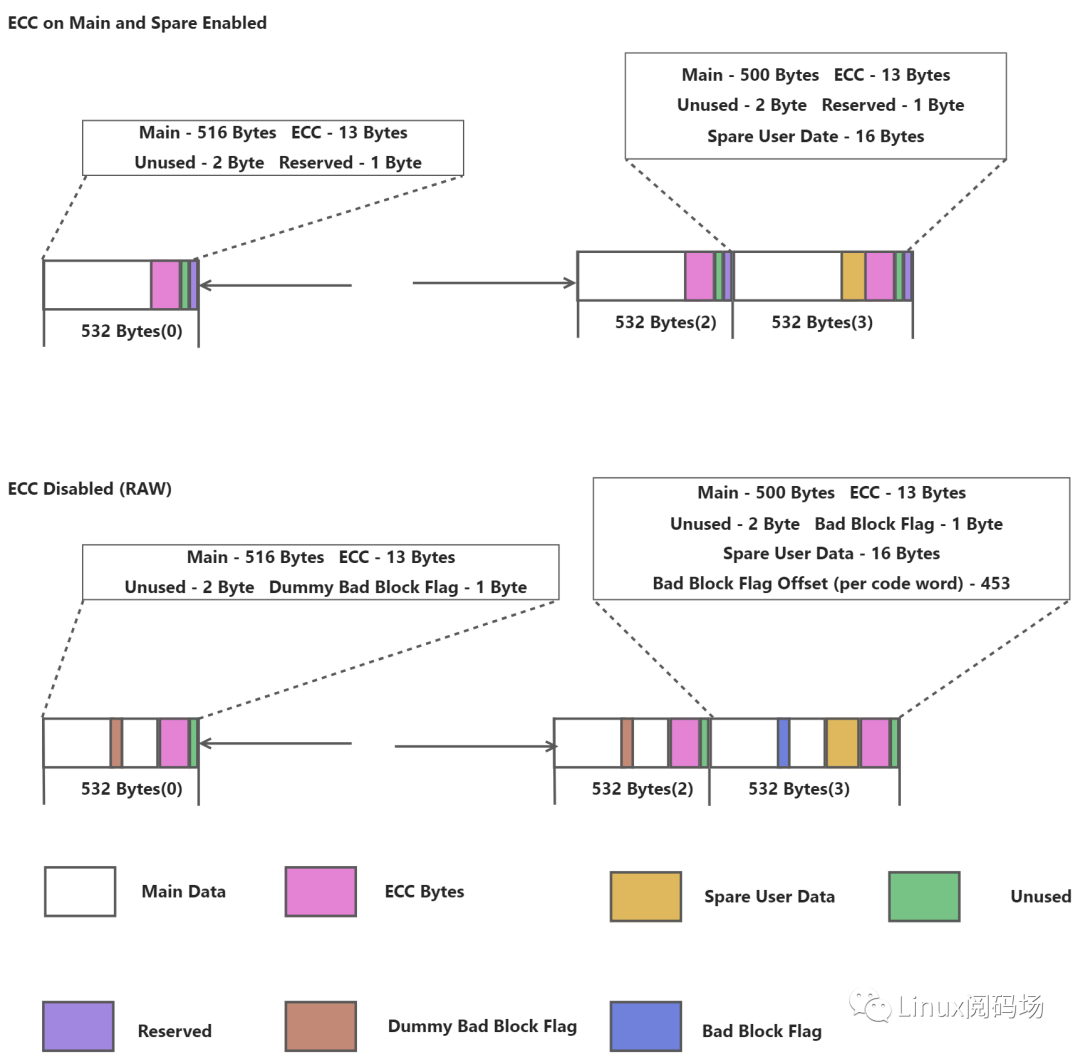
通过Layout 可以发现ECC 其实和OOB区域是Nand Flash 存储的一部分,Bit Flip 产生的随机性同样也会影响 ECC数据和OOB 数据;
文件系统
这里要特殊说明下文件系统, 文件系统的问题可以分为两种:
1.由于异常掉电导致数据写入未完成,或文件处理逻辑未完成产生的系统性校验错误;
2.文件系统数据存储格式完全依赖于文件系统类型, 同时读写分区的频繁读写, 空间占用大也导致位反转在文件系统区域概率大大增加;
分析方法
Nand Flash 的Meta Data数据能直观反应问题发生的原因,通过Dump Nand Flash数据可以快速排除存储数据本身是否异常;
1.enable ECC dump Nand Flash数据就可以获取当前ECC值;
2.使用相同固件在另一块Nand Flash 中操作步骤1 获取正常的Meta Data;
3.通过对比不同Nand Flash相同数据的ECC 值,可以帮助我们确定是否发生过位反转;
而文件系统需要我们对文件系统机制有一定的了解进而分析异常原因;
Bit Flip 解决方法
多分区,多冗余的方法也同样可以解决Bit Flip 问题;
只读镜像
只读镜像分区可以依赖通用的错误处理来解决异常产生后的行为,这样可以做到处理行为统一;
文件系统
如果有安全考虑的情况下只读文件系统可以依赖dm-verity功能进行异常检查, 由于文件系统的复杂性针对读写分区的异常检测点需要我们从概率性和必要性进行考虑异常处理的合理性;
还有一种Nand Flash 处于不稳定状态的情况存在, 这种情况暂时没有好的解决方案, 在重新烧录后表现良好使用一段时间后产生大量Bit Flip 也无法通过检测机制标记成坏块,对特征值(0x55 0xaa)验证表现正常;
如果怀疑是这种问题可以创建由随机数组成的文件对问题区域进行写入和读取验证, 同时也可加上低温环境加大问题复现几率;
DDR Bit Flip
还有一种位反转在DDR中产生, 这种情况下产生的异常结果与Nand Flash Bit Flip基本一致, 区别在于Nand Flash ECC纠正范围内可保证数据的完整性,而 DDR Bit Flip 会直接改变程序逻辑及运行结果从而产生各种不可预测的异常情况;
DDR 分析前我们已经通过启动流程定位启动阶段,排除了是由于Nand Flash数据导致的异常,所以我们需要对DDR 进行诊断是否发生异常。在系统侧可以依赖内存自我检测方式Slub Debug、KASAN等进行检测,但启动阶段会在各个阶段遇到DDR Bit Flip无法依赖于系统侧同时系统侧诊断会受到内存分配Layout限制无法全局诊断;
SBL 是很多平台固件加载的第一启动镜像,在SBl运行阶段大部分内存以物理内存方式直接访问,这样我们可以利用这一性质进行内存诊断,回读校验可以帮助我们快速定位问题点;
导致DDR Bit Flip原因有哪些?
DDR 本身损坏导致Bit Flip的情况非常多这源于DDR 设计的复杂性, 能够通过回读校验直接检测出来的我们都可归于DDR 本身问题
举两个特殊又比较常见的例子进行说明:
Margin问题
Magin 问题通常都是时序问题,问题的来源可能是设计或者材料上的缺陷导致;
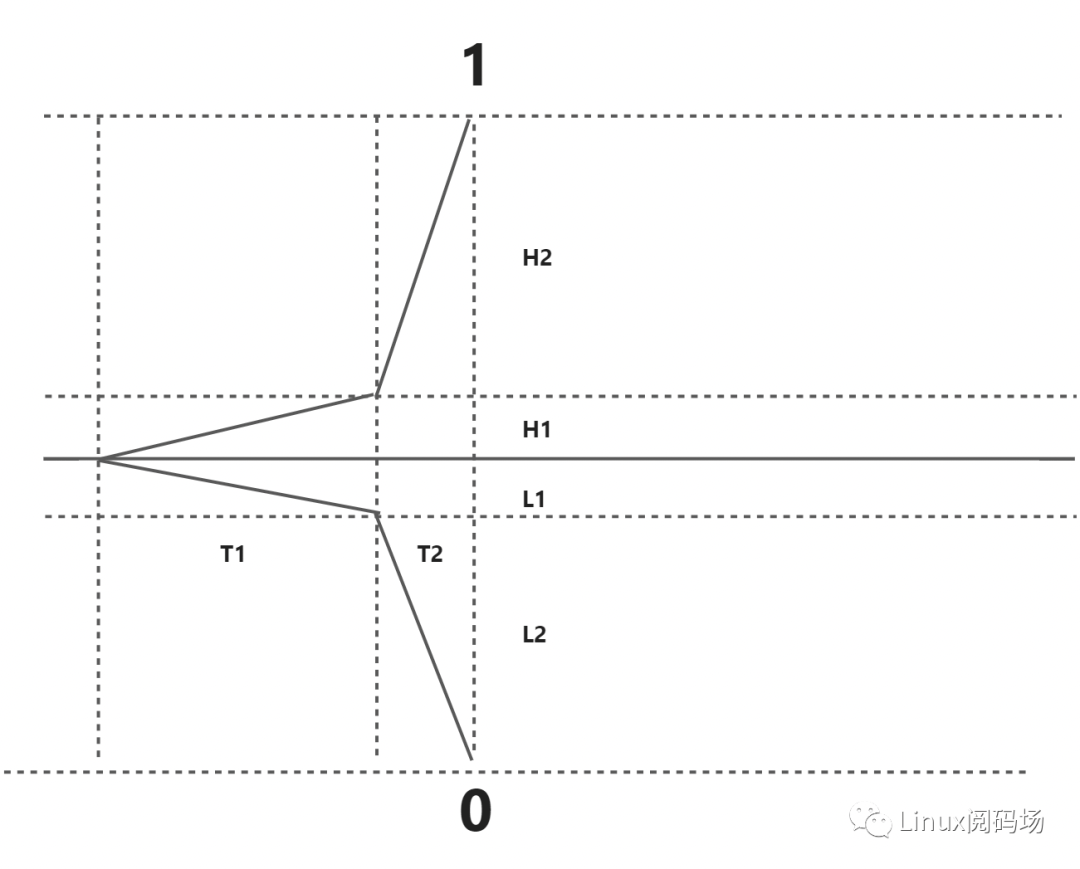
DDR 的0和1是由基本电路控制门电路最终达到标准的"0","1", 如下图所示当在T1时间内无法达到电压阈值H1或者L1门电路将会切到另一端也就是Margin 导致的Bit Flip;
ROW HAMMER 特性,指DDR 内存单元之间电子的互相影响,在足够多临近行列的访问次数后让某个单元的值从1变成0现象。
DDR 会定时刷新ceil电荷,但是每次对ceil读写的时候,会导致临近的ceil电荷流失,如果针对特定ceil 进行高频读写,那么会出现在刷新时间到达前,出现bitflip问题 。导致程序运行异常
Kernel crash
Kernel Crash的分析是一个老生常谈的问题,本文从crash开始 通过启动流程,Nand Flash,DDR逐一排除最后又回到crash 这里,Kernel 的分析方法与硬件设计和实际问题有关,所以本文不做专项介绍;
小结
本文只是工作经验的总结并无太多细节展示,希望通过这种从宏观到微观剖析的方法帮助大家找到解决问题的思路,分析的方法有很多甚至法律上的“有罪论”、“无罪论”也可以帮助我们梳理当前的问题;


