
18000 台服务器整整瘫痪了三天:因 BoltDB 糟糕的设计转载
Roblox为其平台上5000万要求极高的青少年和青春期前的儿童提供游戏制作服务。

本周,该公司发布了一份内容冗长、极其详细的事后分析报告,描述了去年持续整整三天的重大故障事件,所有从事企业基础架构工作的人都应该认真读一读。
Roblox声称:“无论持续时间还是复杂程度,这次故障都是独一无二的。”而这种说法未免轻描淡写。在互联网上,三天这段时间实在太长了;去年10月的一天,Facebook宕机了短短几小时,全世界就一度为之抓狂。
Roblox管理自己的基础架构,这对于一家成立于2004年的公司来说并不罕见。该公司在这套基础架构上拥有的服务器超过18000台,还部署和管理自己的存储设备和网络设备。
它广泛依赖HashiCorp公司开发的技术,包括 Nomad、Vault和Consul。Consul 是一类名为服务网格(service mesh)的新兴企业技术的一部分,它在帮助厘清导致这起故障的情形方面发挥了关键作用。与大多数故障一样,这次故障一开始时是无害的,但随后在用于运行Roblox基础架构的软件层的深处发现了一个新的错误(bug)。
像Consul这样的服务网格其功能类似网络上的交通管制员,允许各个微服务相互通信,并交换完成工作所需要的数据。乍一看,这似乎只是运行Consul集群的硬件出现的简单故障,但更换所有服务器后,性能依然受到影响。
由Roblox工程师和HashiCorp工程师组成的联合团队最终查明,在Consul核心一个名为BoltDB的开源日志记录项目在设计上所做的选择导致了瓶颈,而这完全是因Roblox的独特架构而暴露出来的。之所以花那么长的时间来诊断问题,一方面原因是团队无法确定导致问题的到底是Roblox的选择,还是Consul内部某个存在缺陷的组件。事实证明,这两个因素多少都有所牵涉。
在过去的三个月间,Roblox对其基础架构进行了数次更改。该公司表示:“在一个Consul集群上运行所有Roblox后端服务使我们遇到了这种性质的故障。”因此,它增加了第二个数据中心来运行后端服务,还计划在那些数据中心区域里面实施可用区(AZ)。
HashiCorp还在开发新版本的Consul,以取代BoltDB。但是尽管如此,三大云提供商的销售代表还是没有从Roblox获得任何大笔的新业务。
“总的来说,我们发现,公共云对于并不注重性能和延迟,且在规模有限的环境下运行的应用程序来说是一种很好的工具。然而,针对我们那些非常注重性能和延迟的工作负载,我们所做的选择是在本地构建和管理我们自己的基础架构,”该公司表示。
衷心感谢Roblox对这起可能是该公司发展史上最严重的事件之一进行了如此详尽细致的分析。不过幸运的是,其核心受众很快就忘了这荏事。

BoltDB问题似乎直接归咎于糟糕的设计。需要空闲链表(freelist)很好,在每次追加后都需要将整个空闲链表同步到磁盘很可笑很荒唐。
我是BoltDB的开发者。是的,这是糟糕的设计。该项目从未打算投入到生产环境中,而是作为LMDB的移植版,因此我可以理解其内部结构。我简化了空闲链表的处理,因为这是一个小儿科项目。当时(2014年前后)Shopify在LMDB或Go驱动程序方面遇到了一些严重的问题,几个月后我们还是无法解决,于是我们换成了Bolt。遗憾的是,我这个糟糕的设计仍然存在。
LMDB使用常规bucket用于空闲链表,而Bolt只是将该链表作为数组来存储。它在相当大的程度上简化了逻辑,在大多数使用场合下通常不会引发问题。只有当有人写入了大量数据,然后删除数据、从不使用这些数据时,才会出现这个问题。Roblox声称有4G的闲置页面,这意味着一个含有4字节页面数的庞大数组。

我认为设计方面的选择该由我来负责,但是与大多数开源软件(OSS)软件一样,责任还是在于最终用户。看到一个错误给其他人带来这么大的麻烦总是糟透了。
至于HashiCorp,他们是一群很出色的人。没有几个开发人员比他们的CTO Armond Dadger更受本人尊敬的了。他是个绝顶聪明的家伙。话虽如此,实际生产环境中还是有很多不定因素,有时候错误还是趁虚而入。
Roblox公告故障「根本原因」部分:
几个月前,我们在自己的一部分服务上启用了新的Consul流式传输(streaming)功能。这项功能旨在降低Consul集群的CPU使用量和网络带宽,它按预期的方式正常工作,因此在接下来的几个月,我们逐步在更多的后端服务上启用了该功能。
10月27日14:00,即出现故障前一天,我们在负责流量路由的后端服务上启用了该功能。作为这次部署的一个方面,为了准备迎接我们通常在年底看到的流量增加现象,我们还将支持流量路由的节点数量增加了50%。在故障事件开始前一天,整个系统在这个层级的流式传输方面运行良好,因此起初并不清楚为什么性能发生了变化。
然而,我们对来自Consul服务器的性能报告和火焰图(flame graph)进行分析后,看到了表明引起资源争用的流式传输代码路径导致了CPU使用量高的证据。于是,我们禁用了所有Consul系统的流式传输功能,其中包括流量路由节点。
配置更改在15:51完成传播,此时Consul KV写入的第50个百分位降低到了300ms。我们终于取得了突破。
为什么流式传输是个问题?
HashiCorp解释道,虽然流式传输总体上更高效,但与长轮询(long polling)相比,它在实现中所用的并发控制元素(Go通道)较少。在负载非常高的情况下(具体来说,读取负载和写入负载都非常高),流式传输的设计加剧了单单一条Go通道上的资源争用程度,这导致写入期间出现阻塞,从而大幅降低效率。
这种行为也解释了核心数量更多的服务器带来的影响:这些服务器是采用NUMA内存模型的双插槽架构。因此,在这种架构下,共享资源的额外争用现象变得更严重。我们关闭流式传输后,显著改善了Consul集群的健康状况。
尽管取得了这一突破,但我们还是没有摆脱困境。
我们看到Consul间歇性地选举新的集群主节点(leader),这很正常,但我们也看到一些主节点表现出了与我们在禁用流式传输之前看到的同样的延迟问题,而这不正常。在没有任何明显的线索表明主节点速度缓慢问题的根本原因这一情况下,并且又有证据表明只要某些服务器没有被选为主节点,整个集群就健康运行,于是团队做出了务实的决定,通过防止有问题的主节点保持处于被选举的状态,从而规避这个问题。这使团队能够专注于将依赖Consul的Roblox服务恢复到健康状态。
但是那些速度缓慢的主节点发生了什么?
我们在故障事件期间没有弄清楚这一点,但HashiCorp的工程师在故障后的几天内查明了根本原因。Consul使用了一个名为BoltDB的流行的开源持久性库来存储Raft日志。它并不用于存储Consul里面的当前状态,而是滚动记录所采用的操作。为了防止BoltDB无限止地变大,Consul定期执行快照。快照操作将Consul的当前状态写入到磁盘,然后从BoltDB中删除最旧的日志条目。
但是,由于BoltDB的设计使然,即使明明已删除了最旧的日志条目,BoltDB在磁盘上使用的空间也不会缩小。相反,所有用于存储已删除数据的页面(文件中的4kb段)而是都被标记为“空闲”,并重新用于后续的写入。BoltDB在一种名为“空闲链表”(freelist)的结构中跟踪这些空闲页面。通常,写入延迟并不受更新空闲链表所需的时间的显著影响,但Roblox的工作负载暴露了BoltDB中一个病态的性能问题,从而使得空闲链表维护起来开销极大。
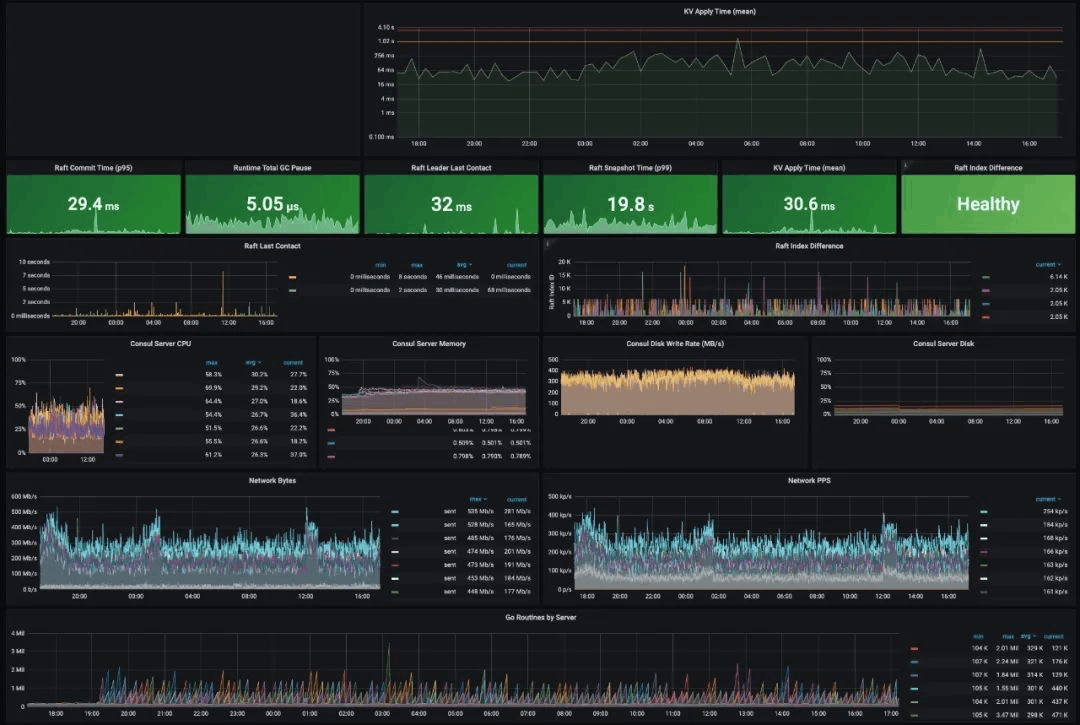
在Roblox的Consul的正常运作情况
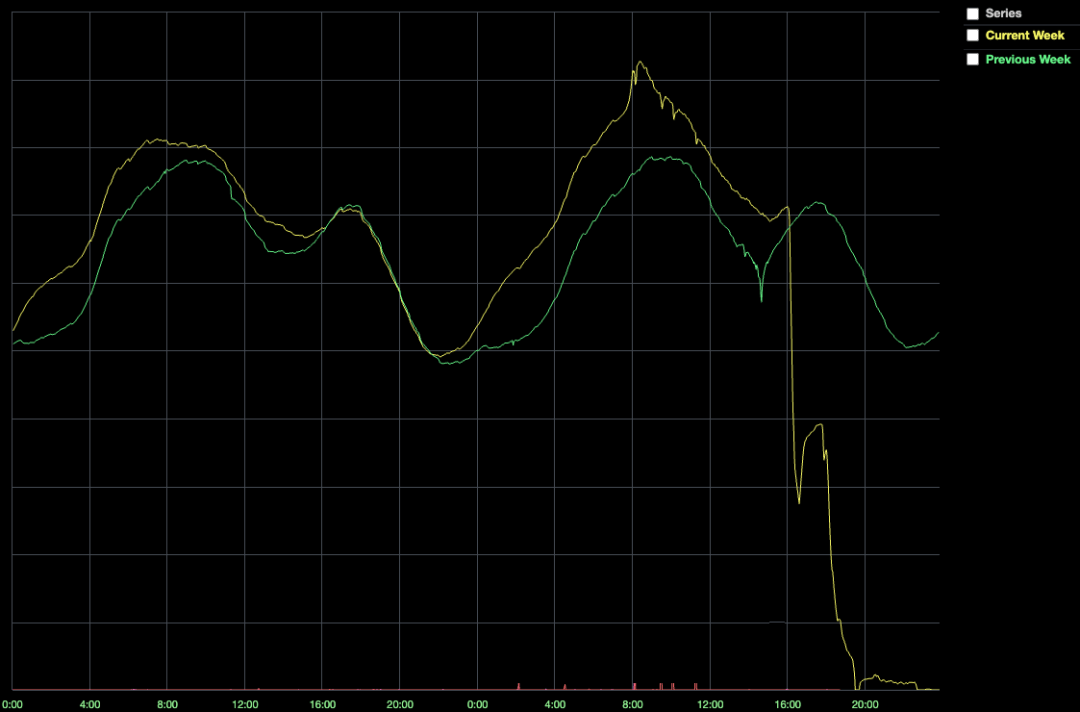
16:35 PST玩家数量减少期间的CCU
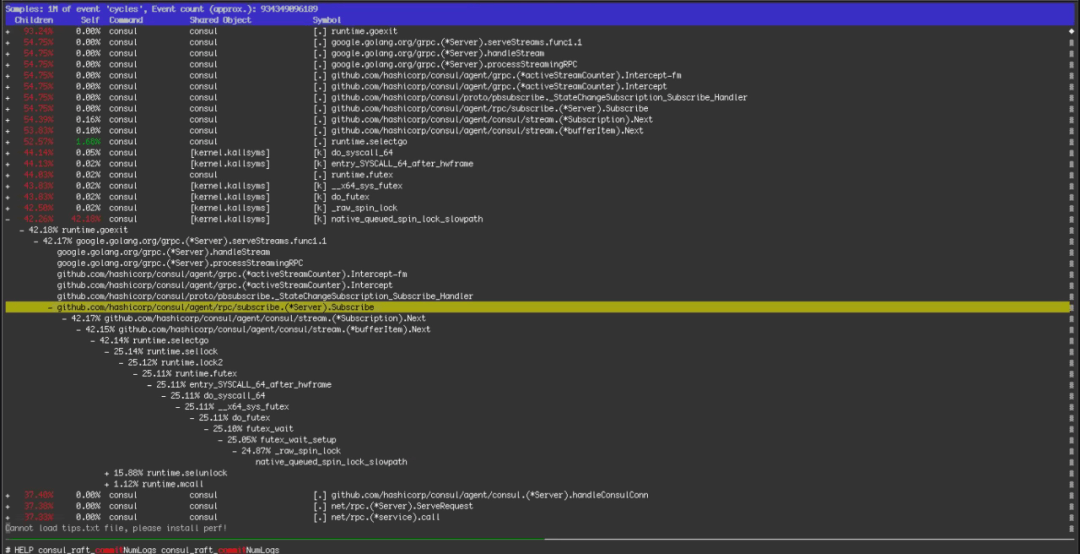
Roblox随后用上面所示的perf报告显示了该内容。绝大多数时间花费在了通过流式传输订阅代码路径的内核自旋锁上。
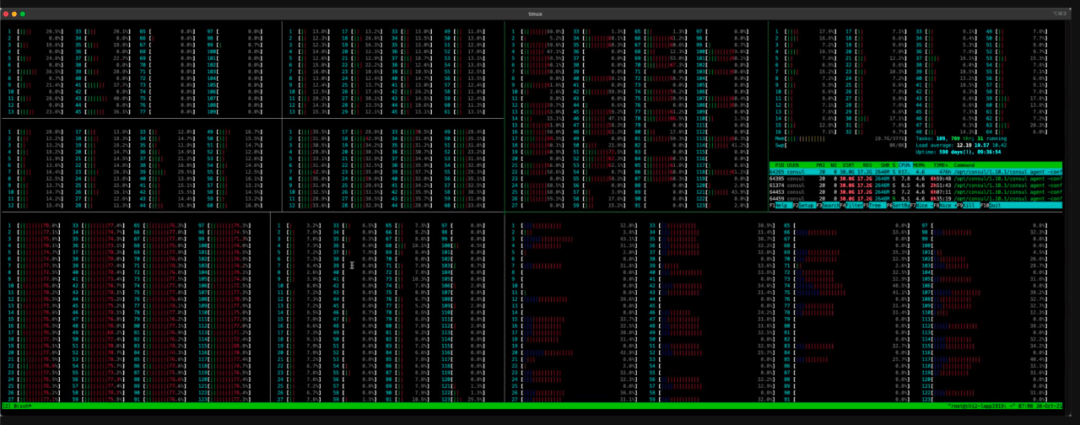
HTOP显示了128个核心上的CPU使用情况

BoltDB空闲链表操作分析
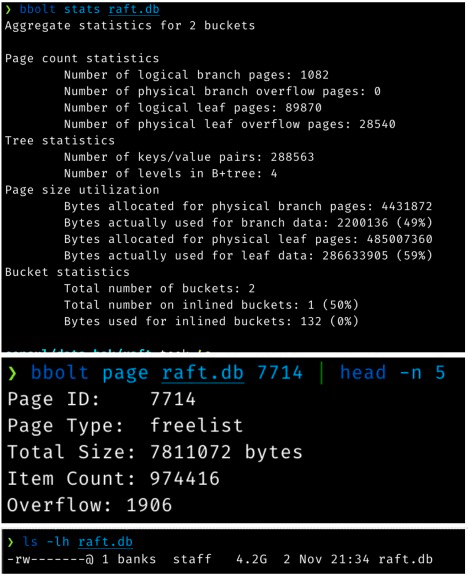
分析中所使用的详细的BoldDB统计信息
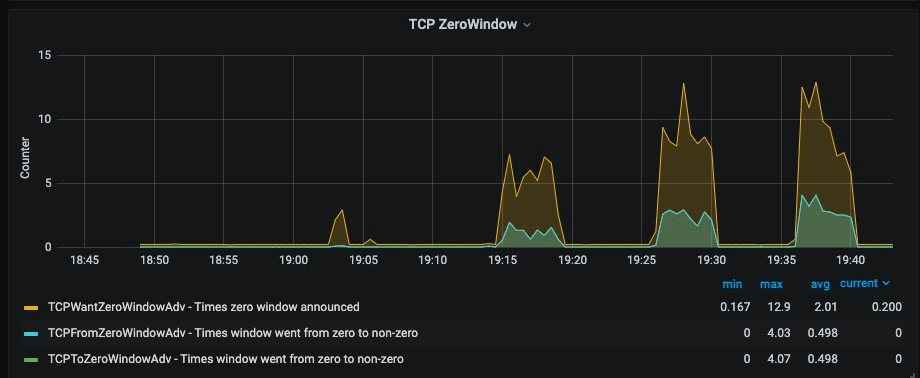
深入研究TCP零窗口。当TCP接收方的缓冲器开始填充时,它会缩小接收窗口。如果它填满,会将窗口缩小至0,这会命令TCP发送端停止发送。
故障报告英文原文:https://blog.roblox.com/2022/01/roblox-return-to-service-10-28-10-31-2021/
本文转载自:云头条


