
【全网首发】Linux:十五条网络性能优化建议原创
大家好,我是飞哥!
如果你具备了一定对网络的理解后,我们在性能方面有哪些优化手段可用呢?我这里给出一些开发或者运维中的性能优化建议。不过要注意的是,每一种性能优化方法都有它适用或者不适用的应用场景。你应当根据你当前的项目现状灵活来选择用或者不用。
建议1:尽量减少不必要的网络 IO
我要给出的第一个建议就是不必要用网络 IO 的尽量不用。
是的,网络在现代的互联网世界里承载了很重要的角色。用户通过网络请求线上服务、服务器通过网络读取数据库中数据,通过网络构建能力无比强大分布式系统。网络很好,能降低模块的开发难度,也能用它搭建出更强大的系统。但是这不是你滥用它的理由!
原因是即使是本机网络 IO 开销仍然是很大的。先说发送一个网络包,首先得从用户态切换到内核态,花费一次系统调用的开销。进入到内核以后,又得经过冗长的协议栈,这会花费不少的 CPU 周期,最后进入环回设备的“驱动程序”。接收端呢,软中断花费不少的 CPU 周期又得经过接收协议栈的处理,最后唤醒或者通知用户进程来处理。当服务端处理完以后,还得把结果再发过来。又得来这么一遍,最后你的进程才能收到结果。你说麻烦不麻烦。另外还有个问题就是多个进程协作来完成一项工作就必然会引入更多的进程上下文切换开销,这些开销从开发视角来看,做的其实都是无用功。
上面我们还分析的只是本机网络 IO,如果是跨机器的还得会有双方网卡的 DMA 拷贝过程,以及两端之间的网络 RTT 耗时延迟。所以,网络虽好,但也不能随意滥用!
建议2:尽量合并网络请求
在可能的情况下,尽可能地把多次的网络请求合并到一次,这样既节约了双端的 CPU 开销,也能降低多次 RTT 导致的耗时。
我们举个实践中的例子可能更好理解。假如有一个 redis,里面存了每一个 App 的信息(应用名、包名、版本、截图等等)。你现在需要根据用户安装应用列表来查询数据库中有哪些应用比用户的版本更新,如果有则提醒用户更新。
那么最好不要写出如下的代码:
<?php
for(安装列表 as 包名){
redis->get(包名)
...
}
上面这段代码功能上实现上没问题,问题在于性能。据我们统计现代用户平均安装 App 的数量在 60 个左右。那这段代码在运行的时候,每当用户来请求一次,你的服务器就需要和 redis 进行 60 次网络请求。 总耗时最少是 60 个 RTT 起。更好的方法是应该使用 redis 中提供的批量获取命令,如 hmget、pipeline等,经过一次网络 IO 就获取到所有想要的数据,如图。
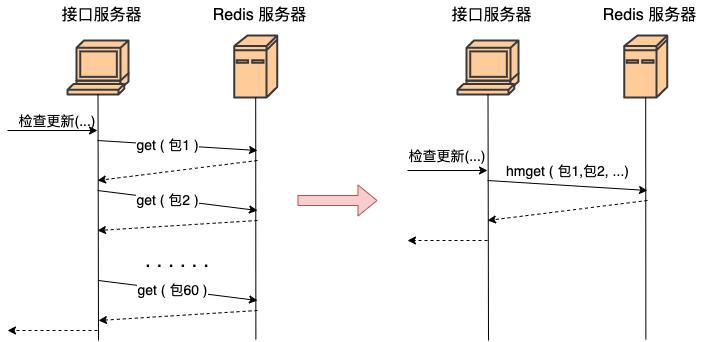
建议3:调用者与被调用机器尽可能部署的近一些
在前面的章节中我们看到在握手一切正常的情况下, TCP 握手的时间基本取决于两台机器之间的 RTT 耗时。虽然我们没办法彻底去掉这个耗时,但是我们却有办法把 RTT 降低,那就是把客户端和服务器放的足够地近一些。尽量把每个机房内部的数据请求都在本地机房解决,减少跨地网络传输。
举例,假如你的服务是部署在北京机房的,你调用的 mysql、redis最好都位于北京机房内部。尽量不要跨过千里万里跑到广东机房去请求数据,即使你有专线,耗时也会大大增加!在机房内部的服务器之间的 RTT 延迟大概只有零点几毫秒,同地区的不同机房之间大约是 1 ms 多一些。但如果从北京跨到广东的话,延迟将是 30 - 40 ms 左右,几十倍的上涨!
建议4:内网调用不要用外网域名
假如说你所在负责的服务需要调用兄弟部门的一个搜索接口,假设接口是:"http://www.sogou.com/wq?key=开发内功**"。
那既然是兄弟部门,那很可能这个接口和你的服务是部署在一个机房的。即使没有部署在一个机房,一般也是有专线可达的。所以不要直接请求 www.sogou.com, 而是应该使用该服务在公司对应的内网域名。在我们公司内部,每一个外网服务都会配置一个对应的内网域名,我相信你们公司也有。
为什么要这么做,原因有以下几点
1)外网接口慢。本来内网可能过个交换机就能达到兄弟部门的机器,非得上外网兜一圈再回来,时间上肯定会慢。
2)带宽成本高。在互联网服务里,除了机器以外,另外一块很大的成本就是 IDC 机房的出入口带宽成本。 两台机器在内网不管如何通信都不涉及到带宽的计算。但是一旦你去外网兜了一圈回来,行了,一进一出全部要缴带宽费,你说亏不亏!!
3)NAT 单点瓶颈。一般的服务器都没有外网 IP,所以要想请求外网的资源,必须要经过 NAT 服务器。但是一个公司的机房里几千台服务器中,承担 NAT 角色的可能就那么几台。它很容易成为瓶颈。我们的业务就遇到过好几次 NAT 故障导致外网请求失败的情形。 NAT 机器挂了,你的服务可能也就挂了,故障率大大增加。
建议5:调整网卡 RingBuffer 大小
在 Linux 的整个网络栈中,RingBuffer 起到一个任务的收发中转站的角色。对于接收过程来讲,网卡负责往 RingBuffer 中写入收到的数据帧,ksoftirqd 内核线程负责从中取走处理。只要 ksoftirqd 线程工作的足够快,RingBuffer 这个中转站就不会出现问题。
但是我们设想一下,假如某一时刻,瞬间来了特别多的包,而 ksoftirqd 处理不过来了,会发生什么?这时 RingBuffer 可能瞬间就被填满了,后面再来的包网卡直接就会丢弃,不做任何处理!

通过 ethtool 就可以加大 RingBuffer 这个“中转仓库”的大小。
# ethtool -G eth1 rx 4096 tx 4096
这样网卡会被分配更大一点的”中转站“,可以解决偶发的瞬时的丢包。不过这种方法有个小副作用,那就是排队的包过多会增加处理网络包的延时。所以应该让内核处理网络包的速度更快一些更好,而不是让网络包傻傻地在 RingBuffer 中排队。我们后面会再介绍到 RSS ,它可以让更多的核来参与网络包接收。
建议6:减少内存拷贝
假如你要发送一个文件给另外一台机器上,那么比较基础的做法是先调用 read 把文件读出来,再调用 send 把数据把数据发出去。这样数据需要频繁地在内核态内存和用户态内存之间拷贝,如图。
目前减少内存拷贝主要有两种方法,分别是使用 mmap 和 sendfile 两个系统调用。使用 mmap 系统调用的话,映射进来的这段地址空间的内存在用户态和内核态都是可以使用的。如果你发送数据是发的是 mmap 映射进来的数据,则内核直接就可以从地址空间中读取,如图 9.7,这样就节约了一次从内核态到用户态的拷贝过程。
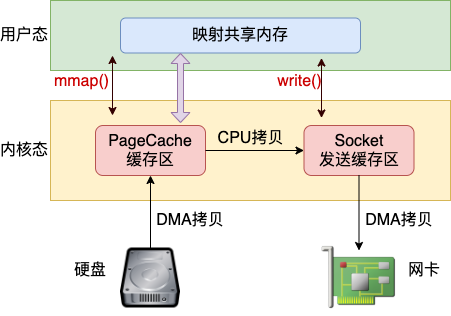
不过在 mmap 发送文件的方式里,系统调用的开销并没有减少,还是发生两次内核态和用户态的上下文切换。 如果你只是想把一个文件发送出去,而不关心它的内容,则可以调用另外一个做的更极致的系统调用 - sendfile。在这个系统调用里,彻底把读文件和发送文件给合并起来了,系统调用的开销又省了一次。再配合绝大多数网卡都支持的"分散-收集"(Scatter-gather)DMA 功能。可以直接从 PageCache 缓存区中 DMA 拷贝到网卡中,如图 9.8。这样绝大部分的 CPU 拷贝操作就都省去了。
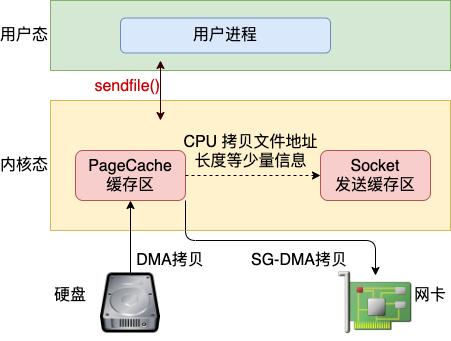
建议7:使用 eBPF 绕开协议栈的本机 IO
如果你的业务中涉及到大量的本机网络 IO 可以考虑这个优化方案。本机网络 IO 和跨机 IO 比较起来,确实是节约了驱动上的一些开销。发送数据不需要进 RingBuffer 的驱动队列,直接把 skb 传给接收协议栈(经过软中断)。但是在内核其它组件上,可是一点都没少,系统调用、协议栈(传输层、网络层等)、设备子系统整个走 了一个遍。连“驱动”程序都走了(虽然对于回环设备来说这个驱动只是一个纯软件的虚拟出来的东东)。
如果想用本机网络 IO,但是又不想频繁地在协议栈中绕来绕去。那么你可以试试 eBPF。使用 eBPF 的 sockmap 和 sk redirect 可以绕过 TCP/IP 协议栈,而被直接发送给接收端的 socket,业界已经有公司在这么做了。
建议8: 尽量少用 recvfrom 等进程阻塞的方式
在使用了 recvfrom 阻塞方式来接收 socket 上数据的时候。每次一个进程专⻔为了等一个 socket 上的数据就得被从 CPU 上拿下来。然后再换上另一个 进程。等到数据 ready 了,睡眠的进程又会被唤醒。总共两次进程上下文切换开销。如果我们服务器上需要有大量的用户请求需要处理,那就需要有很多的进程存在,而且不停地切换来切换去。这样的缺点有如下这么几个:
-
因为每个进程只能同时等待一条连接,所以需要大量的进程。 -
进程之间互相切换的时候需要消耗很多 CPU 周期,一次切换大约是 3 - 5 us 左右。 -
频繁的切换导致 L1、L2、L3 等高速缓存的效果大打折扣
大家可能以为这种网络 IO 模型很少见了。但其实在很多传统的客户端 SDK 中,比如 mysql、redis 和 kafka 仍然是沿用了这种方式。
建议9:使用成熟的网络库
使用 epoll 可以高效地管理海量的 socket。在服务器端。我们有各种成熟的网络库进行使用。这些网络库都对 epoll 使用了不同程度的封装。
首先第一个要给大家参考的是 Redis。老版本的 Redis 里单进程高效地使用 epoll 就能支持每秒数万 QPS 的高性能。如果你的服务是单进程的,可以参考 Redis 在网络 IO 这块的源码。
如果是多线程的,线程之间的分工有很多种模式。那么哪个线程负责等待读 IO 事件,那个线程负责处理用户请求,哪个线程又负责给用户写返回。根据分工的不同,又衍生出单 Reactor、多 Reactor、以及 Proactor 等多种模式。大家也不必头疼,只要理解了这些原理之后选择一个性能不错的网络库就可以了。比如 PHP 中的 Swoole、Golang 的 net 包、Java 中的 netty 、C++ 中的 Sogou Workflow 都封装的非常的不错。
建议10:使用 Kernel-ByPass 新技术
如果你的服务对网络要求确实特别特特别的高,而且各种优化措施也都用过了,那么现在还有终极优化大招 -- Kernel-ByPass 技术。
内核在接收网络包的时候要经过很⻓的收发路径。在这期间牵涉到很多内核组件之间的协同、协议栈的处理、以及内核态和用户态的拷贝和切换。 Kernel-ByPass 这类的技术方案就是绕开内核协议栈,自己在用户态来实现网络包的收发。这样不但避开了繁杂的内核协议栈处理,也减少了频繁了内核态用户态之间的拷贝和切换,性能将发挥到极致!
目前我所知道的方案有 SOLARFLARE 的软硬件方案、DPDK 等等。如果大家感兴趣,可以多去了解一下!
建议11:配置充足的端口范围
客户端在调用 connect 系统调用发起连接的时候,需要先选择一个可用的端口。内核在选用端口的时候,是采用从可用端口范围中某一个随机位置开始遍历的方式。如果端口不充足的话,内核可能需要循环撞很多次才能选上一个可用的。这也会导致花费更多的 CPU 周期在内部的哈希表查找以及可能的自旋锁等待上。因此不要等到端口用尽报错了才开始加大端口范围,而且应该一开始的时候就保持一个比较充足的值。
# vi /etc/sysctl.conf
net.ipv4.ip_local_port_range = 5000 65000
# sysctl -p //使配置生效如果端口加大了仍然不够用,那么可以考虑开启端口 reuse 和 recycle。这样端口在连接断开的时候就不需要等待 2MSL 的时间了,可以快速回收。开启这个参数之前需要保证 tcp_timestamps 是开启的。
# vi /etc/sysctl.conf
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tw_recycle = 1
# sysctl -p建议12:小心连接队列溢出
服务器端使用了两个连接队列来响应来自客户端的握手请求。这两个队列的长度是在服务器 listen 的时候就确定好了的。如果发生溢出,很可能会丢包。所以如果你的业务使用的是短连接且流量比较大,那么一定得学会观察这两个队列是否存在溢出的情况。因为一旦出现因为连接队列导致的握手问题,那么 TCP 连接耗时都是秒级以上了。
对于半连接队列, 有个简单的办法。那就是只要保证 tcp_syncookies 这个内核参数是 1 就能保证不会有因为半连接队列满而发生的丢包。
对于全连接队列来说,可以通过 netstat -s 来观察。netstat -s 可查看到当前系统全连接队列满导致的丢包统计。但该数字记录的是总丢包数,所以你需要再借助 watch 命令动态监控。
# watch 'netstat -s | grep overflowed'
160 times the listen queue of a socket overflowed //全连接队列满导致的丢包如果输出的数字在你监控的过程中变了,那说明当前服务器有因为全连接队列满而产生的丢包。你就需要加大你的全连接队列的⻓度了。全连接队列是应用程序调用 listen时传入的 backlog 以及内核参数 net.core.somaxconn 二者之中较小的那个。如果需要加大,可能两个参数都需要改。
如果你手头并没有服务器的权限,只是发现自己的客户端机连接某个 server 出现耗时长,想定位一下是否是因为握手队列的问题。那也有间接的办法,可以 tcpdump 抓包查看是否有 SYN 的 TCP Retran**ission。如果有偶发的 TCP Retran**ission, 那就说明对应的服务端连接队列可能有问题了。
建议13:减少握手重试
在 6.5 节我们看到如果握手发生异常,客户端或者服务端就会启动超时重传机制。这个超时重试的时间间隔是翻倍地增长的,1 秒、3 秒、7 秒、15 秒、31 秒、63 秒 ......。对于我们提供给用户直接访问的接口来说,重试第一次耗时 1 秒多已经是严重影响用户体验了。如果重试到第三次以后,很有可能某一个环节已经报错返回 504 了。所以在这种应用场景下,维护这么多的超时次数其实没有任何意义。倒不如把他们设置的小一些,尽早放弃。 其中客户端的 syn 重传次数由 tcp_syn_retries 控制,服务器半连接队列中的超时次数是由 tcp_synack_retries 来控制。把它们两个调成你想要的值。
建议14: 如果请求频繁,请弃用短连接改用长连接
如果你的服务器频繁请求某个 server,比如 redis 缓存。和建议 1 比起来,一个更好一点的方法是使用长连接。这样的好处有
1)节约了握手开销。短连接中每次请求都需要服务和缓存之间进行握手,这样每次都得让用户多等一个握手的时间开销。
2)规避了队列满的问题。前面我们看到当全连接或者半连接队列溢出的时候,服务器直接丢包。而客户端呢并不知情,所以傻傻地等 3 秒才会重试。要知道 tcp 本身并不是专门为互联网服务设计的。这个 3 秒的超时对于互联网用户的体验影响是致命的。
3)端口数不容易出问题。端连接中,在释放连接的时候,客户端使用的端口需要进入 TIME_WAIT 状态,等待 2 MSL的时间才能释放。所以如果连接频繁,端口数量很容易不够用。而长连接就固定使用那么几十上百个端口就够用了。
建议15:TIME_WAIT 的优化
很多线上服务如果使用了短连接的情况下,就会出现大量的 TIME_WAIT。
首先,我想说的是没有必要见到两三万个 TIME_WAIT 就恐慌的不行。从内存的⻆度来考虑,一条 TIME_WAIT 状态的连接仅仅是 0.5 KB 的内存而已。从端口占用的角度来说,确实是消耗掉了一个端口。但假如你下次再连接的是不同的 Server 的话,该端口仍然可以使用。只有在所有 TIME_WAIT 都聚集在和一个 Server 的连接上的时候才会有问题。
那怎么解决呢? 其实办法有很多。第一个办法是按上面建议开启端口 reuse 和 recycle。 第二个办法是限制 TIME_WAIT 状态的连接的最大数量。
# vi /etc/sysctl.conf
net.ipv4.tcp_max_tw_buckets = 32768
# sysctl -p如果再彻底一些,也可以干脆直接用⻓连接代替频繁的短连接。连接频率大大降低以后,自然也就没有 TIME_WAIT 的问题了。



