
谈谈Linux内核的栈回溯与妙用原创
前言
说起linux内核的栈回溯功能,我想这对每个Linux内核或驱动开发人员来说,太常见了。如下演示的是linux内核崩溃的一个栈回溯打印,有了这个崩溃打印我们能很快定位到在内核哪个函数崩溃,大概在函数什么位置,大大简化了问题排查过程。

网上或多或少都能找到栈回溯的一些文章,但是讲的都并不完整,没有将内核栈回溯的功能用于实际的内核、应用程序调试,这是本篇文章的核心:尽可能引导读者将栈回溯的功能用于实际项目调试,栈回溯的功能很强大。
本文详细讲解了基于mips、arm架构linux内核栈回溯原理,通过不少例子,尽可能全面给读者展示各种栈回溯的原理,期望读者理解透彻栈回溯。在这个基础上,讲解笔者近几年项目开发过程中使用linux内核栈回溯功能的几处重点应用。
1、当内核某处陷入死循环,有时运行sysrq的内核线程栈回溯功能可以排查,但并不适用所用情况,笔者实际项目遇到过。最后是在系统定时钟中断函数,对死循环线程栈回溯20多级终于找到死循环的函数。
2、当应用程序段错误,内核捕捉到崩溃,对崩溃的应用空间进程/线程栈回溯,像内核栈回溯一样,打印应用段错误进程/线程的层层函数调用关系。虽然运用core文件分析或者gdb也很简便排查应用崩溃问题,但是对于不容易复现、测试部偶先的、客户现场偶先的,这二者就很难发挥作用。还有就是如果崩溃发生在C库中,CPU的pc和lr(arm架构)寄存器指向的函数指令在C库的用户空间,很难找到应用的代码哪里调用了C库的函数。arm架构网上能找到应用层栈回溯的例子,但是编译较麻烦,代码并不容易理解,况且mips能在应用层实现吗?还是在内核实现应用程序栈回溯比较方便。
3、应用程序发生double free,运用内核的栈回溯功能,找到应用代码哪里发生了double free。double free是C库层发现并截获该事件,然后向当前进程/线程发送SIGABRT进程终止信号,后续就是内核强制清理该进程/线程。double free比应用程序段错误更麻烦,后者内核还会打印出错进程/线程名字、pid、pc和lr寄存器值,double free这些打印全没有。笔者做过的一个项目,发布前,遇到一例double free崩溃问题,极难复现,当初要是把double free内核对出问题进程/线程栈回溯的功能做进内核,就能找到出问题的应用函数了。
4 、当应用程序出现锁死问题,对应用所有线程栈回溯,分析每个线程的函数执行流程,对查找锁死问题有帮助。
以上几例应用,在笔者所做的项目中,内核已经合入相关代码,功能得到验证。
正文
2、栈回溯的原理解释
2.1 基于fp栈帧寄存器形式的栈回溯
笔者最初学习栈回溯,首先看到的资料就是arm架构基于fp寄存器的栈回溯,这种资料网上比较多,这里按照自己理解再描述一遍。这种形式的栈回溯相对来说并不复杂,也容易理解,遵循APCS(ARM Procedure Call Standard)规范, APCS规范了arm寄存器的使用、函数调用过程出栈和入栈的约定。如下图所示,是一个传统的arm架构下函数栈数据分布,函数栈由fp和sp寄存器分别指向栈底和栈顶(这里举的例子函数无形参,无局部变量,方便理解)。
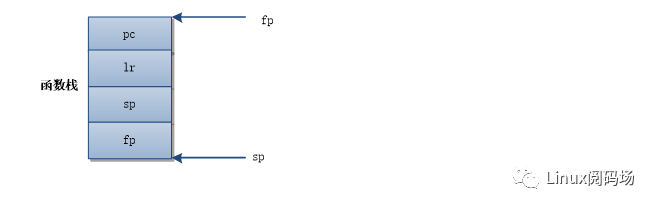
通过fp寄存器就可以找到存储在栈中lr寄存器数据,这个数据就是函数返回地址。同时也可以找到保存在函数栈中的上一级函数fp寄存器数据,这个数据指向了上一级函数的栈底,如此就可以按照同样的方法找出上一级函数栈中存储的lr和fp数据,就知道哪个函数调用了上一级函数以及这个函数的栈底地址。这样就构成了一个栈回溯过程,整个流程以fp为核心,依次找出每个函数栈中存储的lr和fp数据,计算出函数返回地址和上一级函数栈底地址,从而找出每一级函数调用关系。
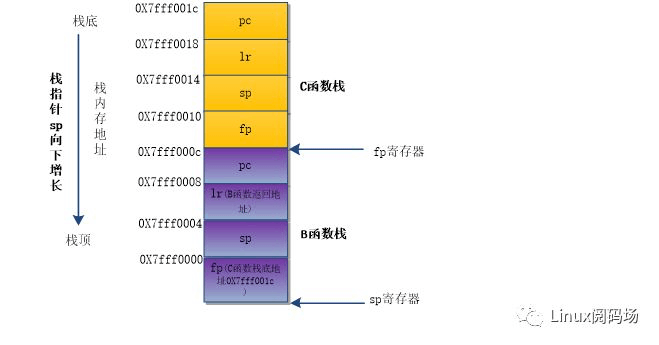
为了使读者理解更充分,举一个简单的例子。以C函数调用了B函数为例,两个函数无形参,无局部变量,此时的入栈情况最简单。两个函数以伪代码的形式列出,演示入栈过程,寄存器的入栈及赋值,与实际的汇编代码有偏差。

假设C函数的栈底地址是0x7fff001c,C函数的前5条入栈指令执行后,pc等寄存器的值保存到C函数栈中,此时fp寄存器的值是C函数栈底地址0x7fff001c。然后C函数跳转到B函数,B函数前5条指令执行后,pc、lr、fp寄存器的值依次保存到B函数栈中:B函数栈的第二片内存保存的就是lr值,即B函数的返回地址;第四片内存保存的是fp值,就是C函数栈底地址0x7fff001c(在开始执行B函数指令前,fp寄存器的值是C函数的栈底地址,B函数的第4条指令又是令fp寄存器入栈);B函数第五条指令执行后,fp寄存器已经更新,其数据是B函数栈的栈底地址0x7fff000c。当B函数发生崩溃,根据fp寄存器找到B函数栈底地址,从B函数栈第二片内存取出的数据就是lr,即B函数返回地址,第4片内存取出的数据就是fp,即C函数栈底地址。有了C函数栈底地址,就能按照上述方法找出C函数栈中保存的的lr和fp,实现栈回溯…..
2.2 unwind 形式的栈回溯
在arm架构下,不少32位系统用的是unwind形式的栈回溯,这种栈回溯要复杂很多。首先需要程序有一个特殊的段.ARM.unwind_idx 或者.ARM.unwind_tab,linux内核本身由多段组成,比如内核驱动初始化函数的init段。在System.map文件可以搜索到__start_unwind_idx,这就是ARM.unwind_idx段的起始地址。这个unwind段中存储着跟函数入栈相关的关键数据。当函数执行入栈指令后,在unwind段会保存跟入栈指令一一对应的编码数据,根据这些编码数据,就能计算出当前函数栈大小和cpu的哪些寄存器入栈了,在栈中什么位置。当栈回溯时,首先根据当前函数中的指令地址,就可以计算出函数unwind段的地址,然后从unwind段取出跟入栈有关的编码数据,根据这些编码数据就能计算出当前函数栈的大小以及入栈时lr寄存器数据在栈中的存储地址。这样就可以找到lr寄存器数据,就是当前函数返回地址,也就是上一级函数的指令地址。此时sp一般指向的函数栈顶,sp+函数栈大小就是上一级函数的栈顶。这样就完成了一次栈回溯,并且知道了上一级函数的指令地址和栈顶地址,按照同样的方法就能对上一级函数栈回溯,类推就能实现整个栈回溯流程。为了方便理解,下方举一个实际调试的示例。该示例中首先列出栈回溯过程每个函数unwind段的编码数据和栈数据。

假设函数调用过程C->B->A,另外每个函数中只有一个printk打印。这种情况下函数的入栈和unwind段的信息就很规则和简单,这里就以简单的来讲解,便于理解。此时每个函数第一条指令一般是push{r4,lr},这表示将lr和r4寄存器入栈,此时系统会将跟push{r4,lr}指令相关的编码数据0x80a8b0b0存入C函数的unwind段中,0x7fffff10跟偏移有关,但是实际用处不大。0x80a8b0b0分离成0x80,0xa8 ,0xb0又有不同的意义,最重要的是0xa8,表示出栈指令pop {r4 r14},r14就是lr寄存器,与push{r4,lr}入栈指令正好相反。C函数跳转到B函数后,会把B函数的返回地址0xbf004068存入B函数栈。B函数按照同样的方法执行,当执行到A函数最后,几个函数的栈信息和unwind段信息就如图所示。假设在A函数中崩溃了,会首先根据崩溃的pc值,找到崩溃A函数的unwind段(每个函数的指令地址和unwind段都是对应的,内核有标准的函数可以查找)。如图所示,从地址0xbf00416c的A函数unwind段中取出数据0x80a8b0b0,分析出其中的0xa8,就知道对应的pop {r4 r14}出栈指令,相应就知道函数入栈时执行的是push{r4,lr}指令,其中有两个重要信息,一个是函数入栈时只有lr和r4寄存器入栈,并且函数栈大小是2*4=8个字节,函数崩溃时栈指针sp指向崩溃函数A的栈顶,根据sp就能找到lr寄存器存储在A函数栈的数据0xbf004038,就是崩溃函数的返回地址,上一级函数B的指令地址,而sp+ 2*4就是上一级B函数的栈顶。知道了B函数的指令地址和栈顶地址,就能根据指令地址找到B函数的unwind段,分析出B函数的入栈指令,按照同样的方法,就能找到C函数的返回地址和栈顶。这只是几个很简单unwind栈回溯过程的演示,省去了很多细节,读者想研究清楚的话,可以阅读内核arm架构unwind_frame函数实现流程,其中最核心的是在unwind_exec_insn函数,根据0xa8,0xb0这些跟函数入栈过程有关的编码数据,分析入栈过程的详细信息,计算出函数lr寄存器保存在栈中的地址和上一级函数的栈顶地址。
不同的入栈指令在函数的unwind段对应不同的编码,0x80a8b0b0只是其中比较简单的的编码,还有0x80acb0b0,0x80aab0b0等等很多。可以执行 readelf -u .ARM.unwind_idx vmlinux查看内核init段函数的unwind段数据。比如:

这就表示match_dev_by_uuid函数在unwind段编码数据是0x808ab0b0,0xc0008af8是该函数指令首地址。其中有用的是0xa8 ,表示pop {r4,r14}出栈指令,0xb0表示unwind段结束。
为了方便读者分析对应的栈回溯内核源码,这里把关键点列出,并添加必要注释。内核版本3.10.104。
arch/arm/kernel/unwind.c


2.3 fp和unwind形式栈回溯的比较
上文介绍了两种常用的栈回溯形式的基本原理,并辅助了例子说明。基于fp寄存器的栈回溯和unwind形式的栈回溯,各有优点和缺点。fp形式的栈回溯,基于APCS规范,入栈过程必须要将pc、lr、fp等4个寄存器入栈(其实没必要这样做,只需把lr和fp入栈),并且消耗的入栈指令要多(除了入栈pc、lr、fp等4个寄存器,还得将栈底地址保存到fp),同时还浪费了寄存器,至少fp寄存器是浪费了,不能参与指令数据运算,CPU寄存器是很宝贵的,多一个对加快指令数据运算是有积极意义的。而unwind形式的栈回溯,就没有这些缺点,仅仅只是将入栈相关的指令的编码保存到unwind段中,不用把无关的寄存器保存到栈中,也不用浪费fp寄存器。unwind形式栈回溯是有缺点的,首先栈回溯的速度肯定比fp形式栈回溯慢,理解难度要比fp形式大很多,并且,站在开发者角度,使用前还得对每个入栈指令编码,这都是需要工作量的。但是站在使用者角度,这些缺点影响并不大,所以现在有很多arm32系统用的是unwind形式的栈回溯。
3、linux内核栈回溯的原理
当内核崩溃,将会执行异常处理程序,这里以mips架构为例,崩溃函数执行流程是:
do_page_fault()->die()->show_registers()->show_stacktrace()->show_backtrace()
栈回溯的过程就是在show_backtrace()函数,arm架构最终是在dump_backtrace()函数,内核崩溃处理流程与mips不同。arm架构栈回溯过程相对来说更简单,首先讲解arm架构的栈回溯过程。
不同内核版本,内核代码有差异,本内核版本3.10.104
3.1 arm架构内核栈回溯的分析
内核实际的栈回溯代码还是有点复杂的,在正式讲解代码前,先通过一个简单演示,进一步详细的介绍栈回溯的原理。这次演示是基于fp形式的栈回溯,与上文介绍传统的fp形式栈回溯稍有差异,但是原理是一样的。
下方以伪汇编指令,演示一个完整的函数指令执行与跳转流程:C函数执行B函数,B函数执行A函数,然后A函数发生空指针崩溃。
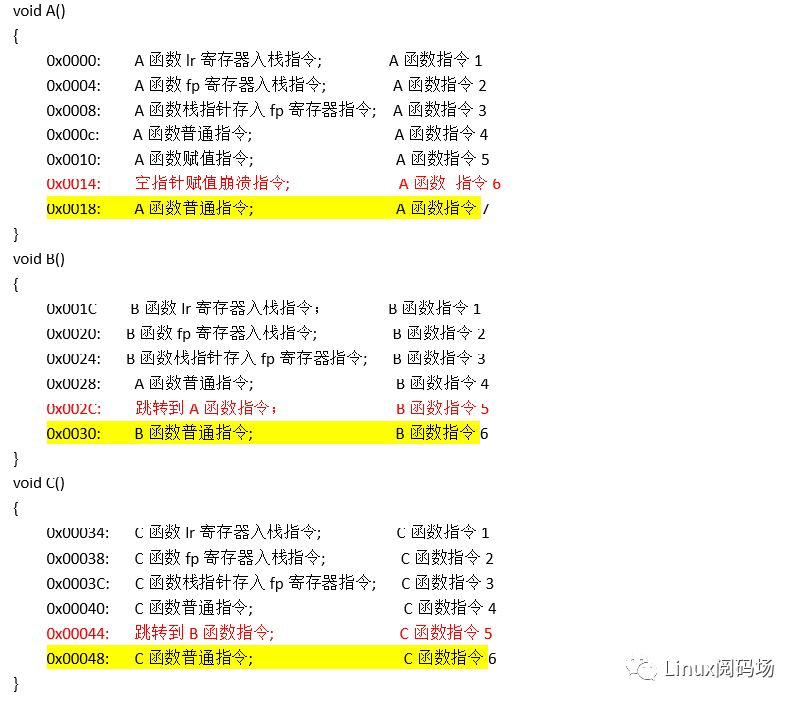
为了帮助读者理解,做一下解释,以C函数的第一条指令为例:
0x00034: C函数返回地址lr入栈指令; C函数指令1
0x00034:表示汇编指令的内存地址,反汇编的读者应该熟悉
C函数返回地址lr入栈指令:表示具体指令的意思,不再用实际汇编指令表示,理解简单
C函数指令1:表示C函数第一条指令,为了引用的简单
其中提到的lr,做过arm内核开发的读者肯定熟悉,是CPU的一个寄存器,存储函数返回地址,当C函数跳转到B函数时,CPU自动将C函数的指令地址0x00048存入lr寄存器,这表示B函数执行完返回后,CPU将从0x00048地址取指令继续运行(mips架构是ra寄存器,先以arm为例)。fp寄存器也是arm架构的一个CPU寄存器,英文释义是frame point,中文有称为栈帧寄存器,我们这里用来存储每个函数栈的第2片内存地址(一片内存地址4个字节,这样称呼是为了叙述方便),下方有详细讲解。为了方便读者理解,特画出函数执行过程函数栈数据示意图。
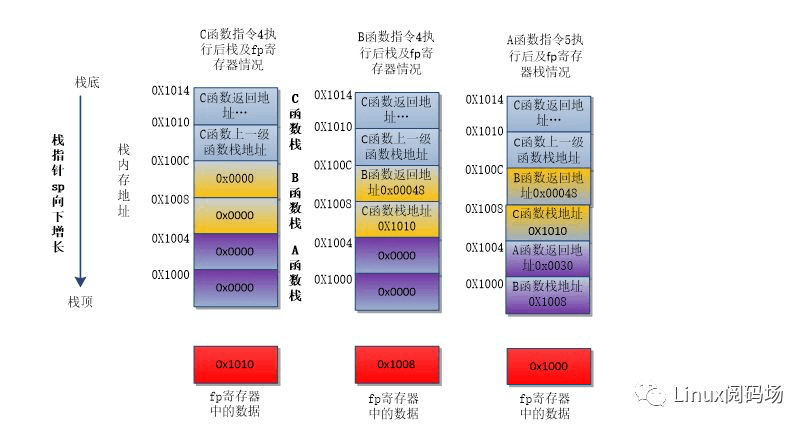
矩形框表示函数栈,初始化全为0,0x1000、0x1004等表示函数栈处于内存的地址,函数栈向下增长。每个函数前两条指令都是入栈指令,每个函数指令执行后只占用两片内存。由于C函数是初始函数,栈回溯过程C函数栈意义不大,就从C函数跳转到B函数指令开始分析。此时fp寄存器保存的数据是C函数栈地址0x1010,原因下文会分析到。当执行C函数指令5,跳转到B函数后,栈指针sp指向地址0x100C(先假设,下文的讲解可以验证),B函数的返回地址也就是C函数的指令6的地址0x00048就会自动保存到CPU的lr寄存器,然后执行B函数指令1, 就会将0x00048存入B函数栈地址0x100C,栈指针sp减一,指向B函数栈地址0X1008。接着执行B函数的指令2,将fp寄存器中的数据0x1010存入栈指针sp指向的内存地址0x1008,示意图已经标明。接着执行B函数指令3,将此时栈指针sp指向的地址0x1008(就是B函数的第二片内存)存入fp寄存器。指令接着执行,由B函数跳转到A函数,A函数前三条指令与B函数执行情况类似,重点就三处,A函数栈的第一片内存存储A函数的返回地址,A函数栈的第二片内存存储B函数栈的第二片内存地址,当A函数执行到指令5后,fp寄存器保存的是A函数栈的第二片内存地址,示意图中全部标出。当A函数执行指令6崩溃,怎么栈回溯?
A函数崩溃时,按照上文的分析,fp寄存器保存的数据是A函数栈的第二片内存首地址0X1000。0X1000地址中存储的数据就是B函数的栈地址0x1008(就是B函数的栈的第二片内存),0x1000+4=0X1004地址就是A函数栈的第一片内存,存储的数据是A函数的返回地址0X0030,这个指令地址就是B函数的指令6地址,这样就知道了时B函数调用了A函数。因为此时已经知道了B函数栈的第二片内存地址,该地址的数据就是C函数栈的第二片内存地址,B函数栈的第一片内存地址中的数据是B函数的返回地址0X0048(C函数的指令6内存地址)。这样就倒着推出函数调用关系:A函数ßB函数ßC函数。
笔者认为,这种情况栈回溯的核心是:每个函数栈的第二片内存地址存储的数据是上一级函数栈的第二片内存地址,每个函数栈的第一片内存地址存储的数据是函数返回地址。只要获取到崩溃函数栈的第二片内存地址(此时就是fp寄存器的数据),就能循环计算出每一级调用的函数。
3.1.1 内核源码分析
如果读者对上一节的演示理解的话,理解下方的源码就比较容易。
arch/arm64/kerneltraps.c

内核崩溃时,产生异常,内核的异常处理程序自动将崩溃时的CPU寄存器存入struct pt_regs结构体,并传入该函数,相关代码不再列出。这样栈回溯的关键环节就是红色标注的代码,先对frame.fp,frame.sp,frame.pc赋值。下方进入while循环,先执行unwind_frame(&frame) 找出崩溃过程的每个函数中的汇编指令地址,存入frame.pc(第一次while循环是直接where = frame.pc赋值,这就是当前崩溃函数的崩溃指令地址),下次循环存入where变量,再传入dump_backtrace_entry函数,在该函数中打印诸如[<c016c873>] chrdev_open+0x12/0x4B1 的字符串。

这个打印的其实是在print_ip_sym函数中做的,将ip按照%pS形式打印,就能打印出该函数指令所在的函数,以及相对函数首指令的偏移。栈回溯的重点是在unwind_frame函数。
在正式贴出代码前,先介绍一下栈回溯过程的三个核心CPU寄存器:pc、lr、fp。pc指向运行的汇编指令地址;sp指向函数栈;fp是栈帧指针,不同架构情况不同,但笔者认为它是栈回溯过程中,联系两个有调用关系函数的纽带,下面的分析就能体现出来。
arch/arm64/kernel/stacktrace.c

首先说明一下,这是arm64位系统,一个long型数据8个字节大小。为了叙述方便,假设内核代码的崩溃函数流程还是 C函数->B函数->A函数,在A函数崩溃,最后在unwind_frame函数中栈回溯。
接着针对代码介绍栈回溯的原理。第一次执行unwind_frame函数时,第二行,frame->fp保存的就是崩溃时CPU的fp寄存器的值,就是A函数栈第二片内存地址,frame->sp = fp + 0x10赋值后,frame->sp就是A函数的栈底地址;frame->fp= *(unsigned long *)(fp)获取的是存储在A函数栈第二片内存中的数据,就是调用A函数的B函数的栈的第二片内存地址;frame->pc = *(unsigned long *)(fp + 8)是获取A函数栈的第一片内存中的数据,就是A函数的返回地址(就是B函数中指令地址),这样就知道了是B函数调用了A函数;经过一次unwind_frame函数调用,就知道了A函数的返回地址和B函数的栈的第二片内存地址,有了B函数栈的第二片内存地址,就能按照上述过程推出B函数的返回地址(C函数的指令地址)和C函数栈的第二片内存地址,这样就知道了时C函数调用了B函数,如此循环,不管有多少级函数调用,都能按照这个规律找出函数调用关系。当然这里的关系是是AßBßC。
为什么栈回溯的原理是这样?首先这个原理笔者都是实际验证过的,细心的读者应该会发现,这个栈回溯的流程跟前文第2节演示的简单栈回溯原理一样。是的,第2节就是笔者按照自己对arm 64位系统栈回溯的理解,用简单的形式表达出来,还附了演示图,这里不了解的读者可以回到第2节分析一下。
3.1.2 arm架构从汇编代码角度解释栈回溯的原理
为了使读者理解的更充分,下文列出一段应用层C语言代码和反汇编后的代码
C代码

汇编代码

分析test_2函数的汇编代码,第一条指令stpx29, x30,[sp,#-16],x29就是fp寄存器,x30就是lr寄存器,指令执行过程:将x30(lr)、x29(fp)寄存器的值随着栈指针sp向下偏移依次入栈,栈指针sp共偏移两次8+8=16个字节(arm 64位系统栈指针sp减一偏移8个字节,并且栈是向下增长,所以指令是-16)。mov x29,sp 指令就是将栈指针赋予fp寄存器,此时sp就指向test_2函数栈的第二片内存,因为sp偏移了两次,fp寄存器的值就是test_2函数栈的第二片内存地址。去除不相关的指令,直接从test_2函数跳转到test_1函数开始分析,看test_1函数的第一条指令stp x29, x30,[sp,#-16],首先栈指针sp减一,将x30(lr)寄存器的数据存入test_1函数栈的第一片内存,这就是test_1函数的返回地址,接着栈指针sp减一,将x29(fp)寄存器值入栈,存入test_1函数的第二片内存,此时fp寄存器的值正是test_2函数栈的第二片内存地址,本质就是将test_2函数栈的第二片内存地址存入test_1函数栈的第二片内存中。接着执行mov x29,sp 指令,就是将栈指针sp赋予fp寄存器,此时sp指向test_1函数栈的第二片内存…..
这样就与上一小结的分析一致了, 这里就对arm栈回溯的一般过程,做个较为系统的总结:当C函数跳转的B函数时,先将B函数的返回地址存入B函数栈的第一片内存,然后将C函数栈的第二片内存地址存入B函数栈的第二片内存,接着将B函数栈的第二片内存地址存入fp寄存器,B函数跳转到A函数流程也是这样。当A函数中崩溃时,先从fp寄存器中获取A函数栈的第二片内存地址,从中取出B函数栈的第二片内存地址,再从A函数栈的第一片内存取出A函数的返回地址,也就是B函数中的指令地址,这样就推导出B函数调用了A函数,同理推导出C函数调用了B函数。
演示的代码很简答,但是这个分析是适用于复杂函数的,已经实际验证过。
3.1.3 arm 内核栈回溯的“bug”
这个不是我危言耸听,是实际测出来的。比如如下代码:

这个函数调用流程在内核崩溃了,内核栈回溯是不会打印上边的b函数,有arm 64系统的读者可以验证一下,我多次验证得出的结论是,如果崩溃的函数没有执行其他函数,就会打乱栈回溯规则,为什么呢?请回头看上一节的代码演示
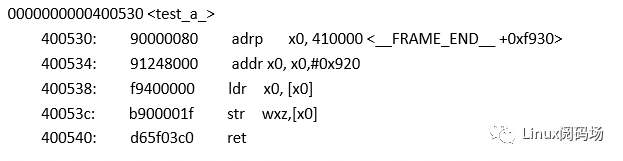
汇编代码是
可以发现,test_a_函数前两条指令不是stpx29, x30,[sp,#-16]和mov x29,sp,这两条指令可是栈回溯的关键环节。怎么解决呢?仔细分析的话,是可以解决的。一般情况,函数崩溃,fp寄存器保存的数据是当前函数栈的第二片内存地址,当前函数栈的第一片内存地址保存的是函数返回地址,从该地址取出的数据与lr寄存器的数据应是一致的,因为lr寄存器保存的也是函数返回地址,如果不相同,说明该函数中没有执行stp x29, x30,[sp,#-16]指令,此时应使用lr寄存器的值作为函数返回地址,并且此时fp寄存器本身就是上一级函数栈的第二片内存地址,有了这个数据就能按照前文的方法栈回溯了。解决方法就是这样,读者可以仔细体会一下我的分析。
3.2 mips 栈回溯过程
前文说过,mips内核崩溃处理流程是
do_page_fault()->die()->show_registers()->show_stacktrace()->show_backtrace()
打印崩溃函数流程是在show_backtrace()函数。
3.2.1 mips 架构内核栈回溯原理分析
arch/mips/kernel/ traps.c

可以发现,与arm架构栈回溯流程基本一致。函数开头是对sp、ra、pc寄存器器赋值,sp和pc与arm架构一致,ra相当于arm架构的lr寄存器,没有arm架构的fp寄存器。print_ip_sym函数就是根据pc值打印形如[<c016c873>] chrdev_open+0x12/0x4B1的字符串,不再介绍。关键还是unwind_stack_by_address函数。mips架构由于没有像arm架构的fp寄存器,导致栈回溯的过程比arm架构复杂很多,为了读者理解方便,决定先从mips架构汇编代码分析,指出与栈回溯有关的指令,推出栈回溯的流程,最后讲解内核代码。
如下是mips架构内核驱动ko文件的 C代码和汇编代码。
C代码

汇编代码
这里说明一下,驱动ko反汇编出来的指令是从0地址开始的,为了叙述方便,笔者加了0x80000000,实际的汇编代码不是这样的。

这里直接介绍根据笔者的分析,总结mips架构内核栈回溯的原理,分析完后再结合源码验证。mips架构没有fp寄存器,假设在test_c函数中0X80000048地址处指令崩溃了,首先利用内核的kallsyms模块,根据崩溃时的指令地址找出该指令是哪个函数的指令,并且找出该指令地址相对函数指令首地址的偏移ofs,在本案例中ofs = 0X10(0X80000048 – 0X80000038 =0X10),这样就能算出test_c函数的指令首地址是 0X80000048 - 0X10 = 0X80000038。然后就从地址0X80000038开始,依次取出每条指令,找到addiu sp,sp,-24 和sw ra,20(sp),内核有标准函数可以判断出这两条指令,下文可以看到。addiu sp,sp,-24是test_c函数的第一条指令,栈指针向下偏移24个字节,笔者认为是为test_c函数分配栈大小( 24个字节);sw ra,20(sp)指令将test_c函数返回地址存入sp +20 内存地址处,此时sp指向的是test_c函数的栈顶,sp+20就是test_c函数栈的第二片内存,该函数栈大小24字节,一共24/4=6片内存。
根据sw ra,20(sp)指令知道test_c函数返回地址在test_c函数栈的存储位置,取出该地址的数据,就知道是test_a函数的指令地址,当然就知道是test_a函数调用了test_c函数。并根据addiu sp,sp,-24指令知道test_c函数栈总计24字节,因为test_c函数崩溃时,栈指针sp指向test_c函数栈顶,sp+24就是test_a函数的栈顶,因为test_a函数调用了test_c函数,两个函数的栈必是紧挨着的。按照上述推断,首先知道了test_a函数中的指令地址了,使用内核kallsyms功能就推算出test_a函数的指令首地址,同时也计算出test_a函数的栈顶,就能按照上述规律找出谁调用了test_a函数,以及该函数的栈顶。依次就能找出所有函数调用关系。
关于内核的kallsyms,笔者的理解是:执行过cat /proc/kallsyms命令的读者,应该了解过,该命令会打印内核所有的函数的首地址和函数名称,还有内核编译后生成的System.map文件,记录内核函数、变量的名称与内存地址等等,kallsyms也是记录了这些内容,当执行kallsyms_lookup_size_offset(0X80000048, &size,&ofs)函数,就能根据0X80000048指令地址计算出处于test_c函数,并将相对于test_c函数指令首地址的偏移0X10存入ofs,test_c函数指令总字节数存入size。笔者没有研究过kallsyms模块,但是可以理解到,内核的所有函数都是按照分配的地址,顺序排布。如果记录了每个函数的首地址和名称,当知道函数的任何一条指令地址,就能在其中搜索比对,找到该指令处于按个函数,计算出函数首地址,该指令的偏移。
3.2.2 mips 架构内核栈回溯核心源码分析
3.2.1详细讲述了mips栈回溯的原理,接着讲解栈回溯的核心函数unwind_stack_by_address。




上述源码已经在关键点做了详细注释,其实就是对3.2.1节栈回溯原理的完善,请读者自己分析,这里不再赘述。但是有一点请注意,就是蓝色注释,这是针对崩溃的函数没有执行其他函数的情况,此时该函数没有类似汇编指令sw ra,20(sp) 将函数返回地址保存到栈中,计算方法就变了,要直接使用ra寄存器的值作为函数返回地址,计算上一级函数栈顶的方法还是一致的,后续栈回溯的方法与前文相同。
4、 linux内核栈回溯的应用
文章最开头说过,笔者在实际项目开发过程,已经总结出了3个内核栈回溯的应用:
1 应用程序崩溃,像内核栈回溯一样打印整个崩溃过程,应用函数的调用关系
2 应用程序发生double free,像内核栈回溯一样打印double free过程,应用函数的调用关系
3 内核陷入死循环,sysrq的内核线程栈回溯功能无法发挥作用时,在系统定时钟中断函数中对卡死线程栈回溯,找出卡死位置
下文逐一讲解。
4.1 应用程序崩溃栈回溯
笔者在研究过内核栈回溯功能后,不禁发问,为什么不能用同样的方法对应用程序的崩溃栈回溯呢?不管是内核空间,应用空间,程序的指令是一样的,无非是地址有差异,函数入栈出栈原理是一样的。栈回溯的入口,arm架构是获取崩溃线程/进程的pc、fp、lr寄存器值,mips架构是获取pc、ra、sp寄存器值,有了这些值就能按照各自的回溯规律,实现栈回溯。从理论上来说,完全是可以实现的。
4.1 .1 arm架构应用程序栈回溯的实现
当应用程序发生崩溃,与内核一样,系统自动将崩溃时所有的CPU寄存器存入struct pt_regs结构,一般崩溃入口函数是do_page_fault,又因为是应用程序崩溃,所以是__do_user_fault函数,这里直接分析__do_user_fault。

在该函数中,tsk就是崩溃的线程,struct pt_regs *regs就指向线程/进程崩溃时的CPU寄存器结构。regs->[29]就是fp寄存器,regs->[30]是lr寄存器, regs->pc的意义很直观。现在有了崩溃应用线程/进程当时的fp、sp、lr寄存器,就能栈回溯了,完全仿照内核dump_backtrace的方法,请看笔者写在user_thread_ dump_backtrace函数中的演示代码。


与内核栈回溯原理一致,打印崩溃过程每个函数的指令地址,然后在应用程序的反汇编文件中查找,就能找到该指令处于的函数,如果不理解,请看文章前方讲解的内核栈回溯代码与原理。请注意,这不是笔者项目实际用的栈回溯代码,实际的改动完善了很多,这只是演示原理的示例代码。
还有一点就是,笔者在3.1.3节提到的,假如崩溃的函数中没有调用其他函数,那上述栈回溯就会有问题,就不会打印第二级函数,解决方法讲的也有,解决的代码这里就不再列出了。
4.1 .2 mips架构应用程序栈回溯的实现
mips 架构不仅内核栈回溯的代码比arm复杂,应用程序的栈回溯更复杂,还有未知bug,即便这样,还是讲解一下具体的解决思路,最后讲一下存在的问题。
先简单回顾一下内核栈回溯的原理,首先根据崩溃函数的pc值,运用内核kallsyms模块,计算出该函数的指令首地址,然后从指令首地址开始分析,找出类似addiu sp,sp,-24和sw ra,20(sp)指令,前者可以找到该函数的栈大小,栈指针sp加上这个数值,就知道上一级函数的栈顶地址(崩溃时sp指向崩溃函数的栈顶);后者知道函数返回地址在该函数栈中存储的地址,从该地址就能获取该函数的返回地址,就是上一级函数的指令地址,也就知道了上一级函数是哪个(同样使用内核kallsyms模块)。知道了上一级函数的指令地址和栈顶地址,按照同样方法,就能知道再上一级的函数…….
问题来了,内核有kallsyms模块记录了每个函数的首地址和函数名字,函数还是顺序排布。应用程序并没有kallsyms模块,即便知道了崩溃函数的pc值,也无法按照同样的方法找到崩溃函数的指令首地址,真的没有方法?其实还有一个最简单的方法。先列出一段一个应用程序函数的汇编代码,如下所示,与内核态的有小的差别。

现在假如从0X4006a4地址处取指,运行后崩溃了。崩溃发生时,能像arm架构一样获取崩溃前的CPU寄存器值,最重要就是pc、sp、ra值。pc值就是0X4006a4,然后令一个unsigned long型指针指向该内存地址0X4006a4,每次减一,并取出该地址的指令数据分析,这样肯定能分析到addiu sp,sp,-32 和sw ra,28(sp)指令,我想看到这里,读者应该可以清楚方法了。没错,就是以崩溃时pc值作为基地址,每次减1并从对应地址取出指令分析,直到分析出久违的addiu sp,sp,-32 和sw ra,28(sp)类似指令,再结合崩溃时的栈指针值sp,就能计算出该函数的返回地址和上一级函数的栈顶地址。后续的方法,就与内核栈回溯的过程一致了。下方列出演示的代码。

为了一致性,应用程序栈回溯的函数还是采用名字user_thread_ dump_backtrace。



如上就是mips应用程序栈回溯的示例代码,只是一个演示,笔者实际使用的代码要复杂太多。读者使用时,要基于这个基本原理,多调试,才能应对各种情况,笔者前后调试几周才稳定。由于这个方法并不是标准的,实际使用时还是会出现误报函数现象,分析了发生误报的汇编代码及C代码,发现当函数代码复杂时,函数的汇编指令会变得非常复杂,会出现相似指令等等,读者实际调试时就会发现。这个mips应用程序栈回溯的方法,可以应对大部分崩溃情况,但是有误报的可能,优化的空间非常大,这点请读者注意。
4.2 应用程序double free 内核栈回溯
double free是在C库层发生的,正常情况内核无能为力,但是笔者研究过后,发现照样可以实现对发生double free应用进程的栈回溯。
以arm架构为例,doublefree C库层的代码,大体原理是,当检测到double free(本人实验时,一片malloc分配的内存free两次就会发生),就会执行kill系统调用函数,向出问题的进程发送SIGABRT信号,既然是系统调用,从用户空间进入内核空间时,就会将应用进程用户空间运行时的CPU寄存器pc、sp、lr等保存到进程的内核栈中,发送信号内核必然执行send_signal函数。在该函数中,使用struct pt_regs *regs = task_pt_regs(current)方法就能从当前进程内核栈中获取进入内核空间前,用户空间运行指令的pc、sp、fp等CPU寄存器值,有了这些值,就能按照用户空间进程崩溃栈回溯方法一样,对double free的进程栈回溯了。比如,A函数double free,A函数->C库函数1-> C库函数2->C库函数3(检测到double free并发送SIGABRT信号,执行系统调用进入内核空间发送信号)。回溯的结果是:C库函数3 ß C库函数2 ß C库函数1ß A函数。
源码不再列出,相信读者理解的话是可以自己开发的。其中task_pt_regs函数的使用,需要读者对进程内核栈有一定的了解。
笔者有个理解,当获取某个进程运行指令某一时间点的CPU寄存器pc、lr、fp的值,就能对该进程进行栈回溯。
4.3 内核发生死循环sysrq无效时栈回溯的应用
内核的sysrq中有一个方法,执行后可以对所有线程进行内核空间函数栈回溯,但是本人遇到过一次因某个外设导致的死循环,该方法打印的栈回溯信息都是内核级的函数,没有头绪。于是,尝试在系统定时钟中断函数中实现卡死线程的栈回溯(也可以在account_process_tick内核标准函数中,系统定时钟中断函数会执行到)。原理是,当一个内核线程卡死时,首先考虑在某个函数陷入死循环,系统定时钟中断是不断产生的,此时current线程很大概率就是卡死线程(要考虑内核抢占,内核支持抢占时,内核某处陷入死循环照样可以调度出去),然后使用struct pt_regs *regs = get_irq_regs()方法,就能获取中断前线程的pc、sp、fp等寄存器值,有了这些值,就能按照内核线程崩溃栈回溯原理,对卡死线程函数调用过程栈回溯,找到卡死函数。mips架构栈回溯的核心函数show_backtrace()定义如下,只要传入内核线程的struct task_struct和structpt_regs结构,就能对内核线程当时指令的执行进行栈回溯。
static void show_backtrace(struct task_struct *task, const struct pt_regs *regs)
4.4 应用程序锁死时对所有应用线程的栈回溯
以arm架构为例。当应用锁死,尤其是偶现的锁死卡死问题,可以使用栈回溯的思路解决。以单核CPU为例,应用程序的所有线程,正常情况,两种状态:正在运行和其他状态(大部分情况是休眠)。休眠的应用线程,一般要先进入内核空间,将应用层运行时的pc、lr、fp等寄存器存入内核栈,执行schdule函数让出CPU使用权,最后线程休眠。此时可以通过tesk_pt_regs函数从线程内核栈中获取线程进入内核空间前的pc、lr、fp等寄存器的数据。正在运行的应用线程,系统定时钟中断产生后,系统要执行硬件定时器中断,此时可以通过get_irq_regs函数获取中断前的pc、lr、fp等寄存器的值。不管应用线程是否正在运行,都可以获取线程当时用户空间运行指令的pc、lr、fp等寄存器数据。当应用某个线程,不管是使用锁异常而长时间休眠,还是陷入死循环,从内核的进程运行队列中,依次获取到所有应用线程的pc、lr、fp等寄存器的数据后(可以考虑在account_process_tick函数实现),就可以按照前文思路对应用线程栈回溯,找出怀疑点。
实际使用时,要防止内核线程的干扰,task->mm可以用来判断,内核线程为NULL。当然也可以通过线程名字加限制,对疑似的几个线程栈回溯。应用线程正在内核空间运行时,这种情况用这个方法就有问题,这时需加限制,比如通过get_irq_regs函数获取到 pc值后,判断是在内核空间还是用户空间。读者实现该功能时,有不少其他细节要注意,这里不再一一列出。
5、应用程序栈回溯的展望
关于应用程序的栈回溯,笔者正在考虑一个方法,使应用程序的栈回溯能真正像内核一样打印出函数的符号及偏移,比如
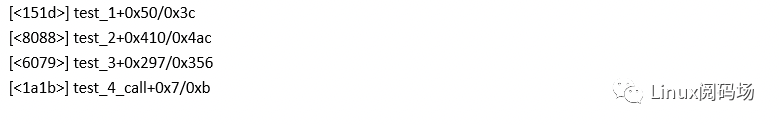
现有的方法只能实现如下效果:
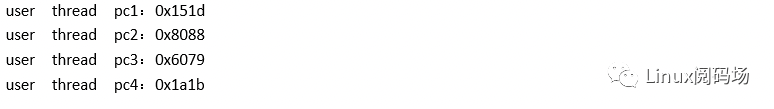
之后还得对应用程序反汇编才能找到崩溃的函数。
笔者的分析是,理论上是可以实现的,只要仿照内核的kallsyms方法,按照顺序记录每个应用函数的函数首地址和函数名字到一个文件中,当应用程序崩溃时,内核中读取这个文件,根据崩溃的指令地址在这个文件中搜索,就能找到该指令处于哪个函数中,本质还是实现了与内核kallsyms类似的方法。有了这个功能,不仅应用程序栈回溯能打印函数的名称与偏移,还能让mips架构应用程序崩溃的栈回溯按照内核崩溃栈回溯的原理来实现,不会再出现函数误报现象,不知读者是否理解我的思路?后续有机会,会尝试开发这个功能并分享出来。
6、总结
实际项目调试时,发现栈回溯的应用价值非常大,掌握栈回溯的原理,不仅对内核调试有很大帮助,对加深内核的理解也是有不少益处。



