
前端性能优化网页渲染原理简介转载
导语
关于前端性能优化的方式有很多,本篇着重介绍了网页渲染优化的原理和方法,适合初级开发者阅读,希望对大家的工作有所帮助!
正文
渲染原理
在讨论性能优化之前,我们有必要了解一些浏览器的渲染原理。不同的浏览器进行渲染有着不同的实现方式,但是大体流程都是差不多的,我们通过 Chrome 浏览器来大致了解一下这个渲染流程。
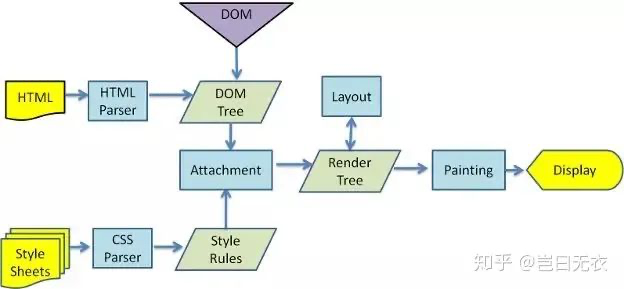
关键渲染路径
关键渲染路径是指浏览器将 HTML、CSS 和 JavaScript 转换成实际运作的网站必须采取的一系列步骤,通过渲染流程图我们可以大致概括如下:
1、处理 HTML 并构建 DOM Tree。
2、处理 CSS 并构建 CSSOM Tree。
3、将 DOM Tree 和 CSSOM Tree 合并成 Render Object Tree。
4、根据 Render Object Tree 计算节点的几何信息并以此进行布局。
5、绘制页面需要先构建 Render Layer Tree 以便用正确的顺序展示页面,这棵树的生成与 Render Object Tree 的构建同步进行。然后还要构建 Graphics Layer Tree 来避免不必要的绘制和使用硬件加速渲染,最终才能在屏幕上展示页面。
DOM Tree
DOM(Document Object Model——文档对象模型)是用来呈现以及与任意 HTML 或 XML 交互的 API 文档。DOM 是载入到浏览器中的文档模型,它用节点树的形式来表现文档,每个节点代表文档的构成部分。
需要说明的是 DOM 只是构建了文档标记的属性和关系,并没有说明元素需要呈现的样式,这需要 CSSOM 来处理。
构建流程
获取到 HTML 字节数据后,会通过以下流程构建 DOM Tree:
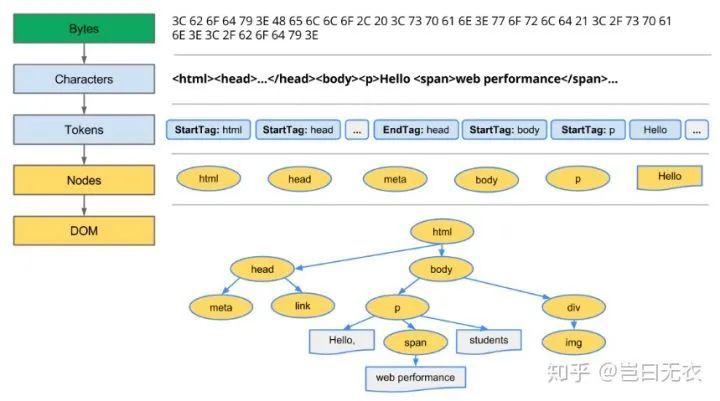
1、编码:HTML 原始字节数据转换为文件指定编码的字符串。
2、词法分析(标记化):对输入字符串进行逐字扫描,根据 构词规则 识别单词和符号,分割成一个个我们可以理解的词汇(学名叫 Token )的过程。
3、语法分析(解析器):对 Tokens 应用 HTML 的语法规则,进行配对标记、确立节点关系和绑定属性等操作,从而构建 DOM Tree 的过程。
词法分析和语法分析在每次处理 HTML 字符串时都会执行这个过程,比如使用 document.write 方法。
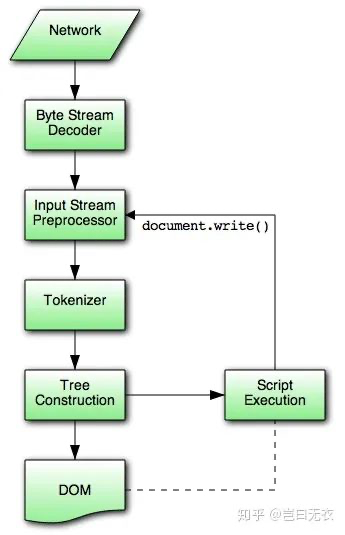
词法分析(标记化)
HTML 结构不算太复杂,大部分情况下识别的标记会有开始标记、内容标记和结束标记,对应一个 HTML 元素。除此之外还有 DOCTYPE、Comment、EndOfFile 等标记。
标记化是通过状态机来实现的,状态机模型在 W3C 中已经定义好了。
想要得到一个标记,必须要经历一些状态,才能完成解析。我们通过一个简单的例子来了解一下流程。
<a href="www.w3c.org">W3C</a>
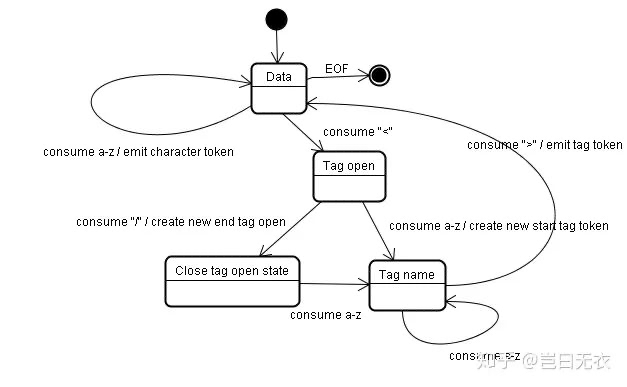
开始标记:
- Data state:碰到 <,进入 Tag open state
- Tag open state:碰到 a,进入 Tag name state 状态
- Tag name state:碰到 空格,进入 Before attribute name state
- Before attribute name state:碰到 h,进入 Attribute name state
- Attribute name state:碰到 =,进入 Before attribute value state
- Before attribute value state:碰到 ",进入 Attribute value (double-quoted) state
- Attribute value (double-quoted) state:碰到 w,保持当前状态
- Attribute value (double-quoted) state:碰到 ",进入 After attribute value (quoted) state
- After attribute value (quoted) state:碰到 >,进入 Data state,完成解析
- 内容标记:W3C
- Data state:碰到 W,保持当前状态,提取内容
- Data state:碰到 <,进入 Tag open state,完成解析
- 结束标记:
- Tag open state:碰到 /,进入 End tag open state
- End tag open state:碰到 a,进入 Tag name state
- Tag name state:碰到 >,进入 Data state,完成解析
通过上面这个例子,可以发现属性是开始标记的一部分。
语法分析(解析器)
在创建解析器后,会关联一个 Document 对象作为根节点。
我会简单介绍一下流程,具体的实现过程可以在 Tree construction 查看。
解析器在运行过程中,会对 Tokens 进行迭代;并根据当前 Token 的类型转换到对应的模式,再在当前模式下处理 Token;此时,如果 Token 是一个开始标记,就会创建对应的元素,添加到 DOM Tree 中,并压入还未遇到结束标记的开始标记栈中;此栈的主要目的是实现浏览器的容错机制,纠正嵌套错误,具体的策略在 W3C 中定义。更多标记的处理可以在 状态机算法 中查看。
CSSOM Tree
加载
在构建 DOM Tree 的过程中,如果遇到 link 标记,浏览器就会立即发送请求获取样式文件。当然我们也可以直接使用内联样式或嵌入样式,来减少请求;但是会失去模块化和可维护性,并且像缓存和其他一些优化措施也无效了,利大于弊,性价比实在太低了;除非是为了极致优化首页加载等操作,否则不推荐这样做。
阻塞
CSS 的加载和解析并不会阻塞 DOM Tree 的构建,因为 DOM Tree 和 CSSOM Tree 是两棵相互独立的树结构。但是这个过程会阻塞页面渲染,也就是说在没有处理完 CSS 之前,文档是不会在页面上显示出来的,这个策略的好处在于页面不会重复渲染;如果 DOM Tree 构建完毕直接渲染,这时显示的是一个原始的样式,等待 CSSOM Tree 构建完毕,再重新渲染又会突然变成另外一个模样,除了开销变大之外,用户体验也是相当差劲的。另外 link 标记会阻塞 JavaScript 运行,在这种情况下,DOM Tree 是不会继续构建的,因为 JavaScript 也会阻塞 DOM Tree 的构建,这就会造成很长时间的白屏。
通过一个例子来更加详细的说明:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<script>
var startDate = new Date();
</script>
<link href="https://cdn.bootcss.com/bootstrap/4.0.0-alpha.6/css/bootstrap.css" rel="stylesheet">
<script>
console.log("link after script", document.querySelector("h2"));
console.log("经过 " + (new Date() - startDate) + " ms");
</script>
<title>性能</title>
</head>
<body>
<h1>标题</h1>
<h2>标题2</h2>
</body>
</html>
首先需要在 Chrome 控制台的 Network 面板设置网络节流,让网络速度变慢,以便更好进行调试。
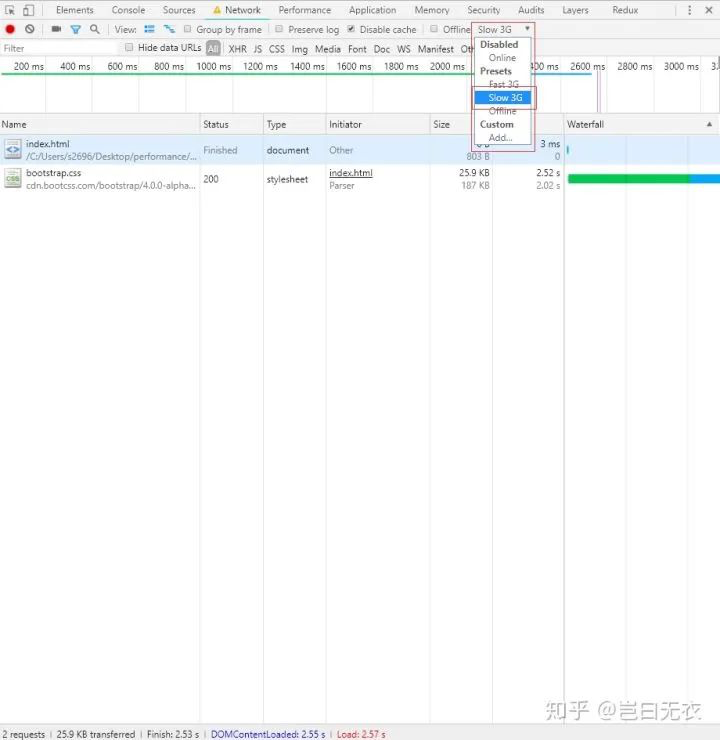
下图说明 JavaScript 的确需要在 CSS 加载并解析完毕之后才会执行。
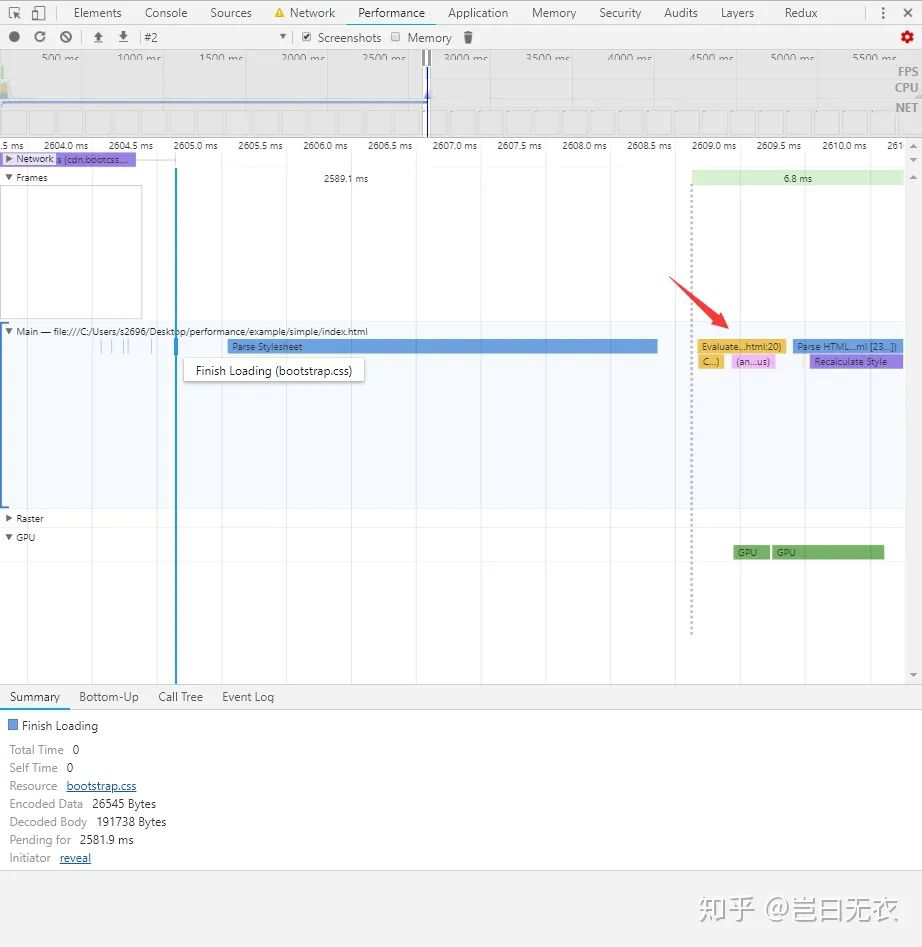
为什么需要阻塞 JavaScript 的运行呢?
因为 JavaScript 可以操作 DOM 和 CSSOM,如果 link 标记不阻塞 JavaScript 运行,这时 JavaScript 操作 CSSOM,就会发生冲突。更详细的说明可以在 使用 JavaScript 添加交互 这篇文章中查阅。
解析
CSS 解析的步骤与 HTML 的解析是非常类似的。
词法分析
CSS 会被拆分成如下一些标记:

CSS 的色值使用十六进制优于函数形式的表示?
函数形式是需要再次计算的,在进行词法分析时会将它变成一个函数标记,由此看来使用十六进制的确有所优化。

语法分析
每个 CSS 文件或嵌入样式都会对应一个 CSSStyleSheet 对象(authorStyleSheet),这个对象由一系列的 Rule(规则) 组成;每一条 Rule 都会包含 Selectors(选择器) 和若干 Declearation(声明),Declearation 又由 Property(属性)和 Value(值)组成。另外,浏览器默认样式表(defaultStyleSheet)和用户样式表(UserStyleSheet)也会有对应的 CSSStyleSheet 对象,因为它们都是单独的 CSS 文件。至于内联样式,在构建 DOM Tree 的时候会直接解析成 Declearation 集合。
内联样式和 authorStyleSheet 的区别
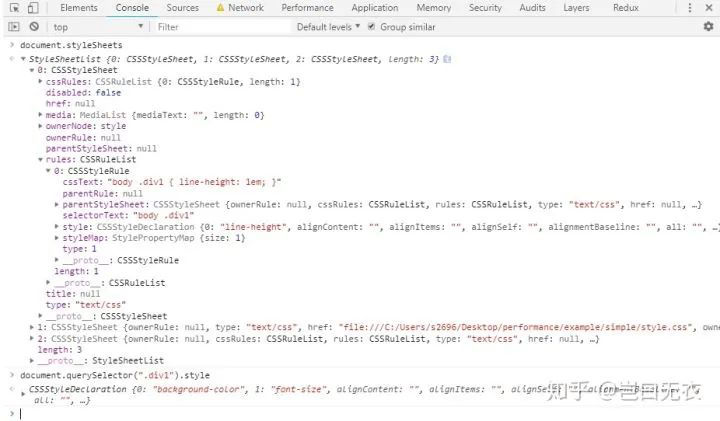
所有的 authorStyleSheet 都挂载在 document 节点上,我们可以在浏览器中通过 document.styleSheets 获取到这个集合。内联样式可以直接通过节点的 style 属性查看。
通过一个例子,来了解下内联样式和 authorStyleSheet 的区别:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<style>
body .div1 {
line-height: 1em;
}
</style>
<link rel="stylesheet" href="./style.css">
<style>
.div1 {
background-color: #f0f;
height: 20px;
}
</style>
<title>Document</title>
</head>
<body>
<div class="div1" >test</div>
</body>
</html>
可以看到一共有三个 CSSStyleSheet 对象,每个 CSSStyleSheet 对象的 rules 里面会有一个 CSSStyleDeclaration,而内联样式获取到的直接就是 CSSStyleDeclaration。
需要属性合并吗?
在解析 Declearation 时遇到属性合并,会把单条声明转变成对应的多条声明,比如:
.box {
margin: 20px;
}
margin: 20px 就会被转变成四条声明;这说明 CSS 虽然提倡属性合并,但是最终还是会进行拆分的;所以属性合并的作用应该在于减少 CSS 的代码量。
计算
为什么需要计算?
因为一个节点可能会有多个 Selector 命中它,这就需要把所有匹配的 Rule 组合起来,再设置最后的样式。
准备工作
为了便于计算,在生成 CSSStyleSheet 对象后,会把 CSSStyleSheet 对象最右边 Selector 类型相同的 Rules 存放到对应的 Hash Map 中,比如说所有最右边 Selector 类型是 id 的 Rules 就会存放到 ID Rule Map 中;使用最右边 Selector 的原因是为了更快的匹配当前元素的所有 Rule,然后每条 Rule 再检查自己的下一个 Selector 是否匹配当前元素。
idRules
classRules
tagRules
...
*
选择器命中
一个节点想要获取到所有匹配的 Rule,需要依次判断 Hash Map 中的 Selector 类型(id、class、tagName 等)是否匹配当前节点,如果匹配就会筛选当前 Selector 类型的所有 Rule,找到符合的 Rule 就会放入结果集合中;需要注意的是通配符总会在最后进行筛选。
从右向左匹配规则
上文说过 Hash Map 存放的是最右边 Selector 类型的 Rule,所以在查找符合的 Rule 最开始,检验的是当前 Rule 最右边的 Selector;如果这一步通过,下面就要判断当前的 Selector 是不是最左边的 Selector;如果是,匹配成功,放入结果集合;否则,说明左边还有 Selector,递归检查左边的 Selector 是否匹配,如果不匹配,继续检查下一个 Rule。
为什么需要从右向左匹配呢?
先思考一下正向匹配是什么流程,我们用 div p .yellow 来举例,先查找所有 div 节点,再向下查找后代是否是 p 节点,如果是,再向下查找是否存在包含 class="yellow" 的节点,如果存在则匹配;但是不存在呢?就浪费一次查询,如果一个页面有上千个 div 节点,而只有一个节点符合 Rule,就会造成大量无效查询,并且如果大多数无效查询都在最后发现,那损失的性能就实在太大了。
这时再思考从右向左匹配的好处,如果一个节点想要找到匹配的 Rule,会先查询最右边 Selector 是当前节点的 Rule,再向左依次检验 Selector;在这种匹配规则下,开始就能避免大多无效的查询,当然性能就更好,速度更快了。
设置样式
设置样式的顺序是先继承父节点,然后使用用户代理的样式,最后使用开发者(authorStyleSheet)的样式。
authorStyleSheet 优先级
放入结果集合的同时会计算这条 Rule 的优先级;来看看 blink 内核对优先级权重的定义:
switch (m_match) {
case Id:
return 0x010000;
case PseudoClass:
return 0x000100;
case Class:
case PseudoElement:
case AttributeExact:
case AttributeSet:
case AttributeList:
case AttributeHyphen:
case AttributeContain:
case AttributeBegin:
case AttributeEnd:
return 0x000100;
case Tag:
return 0x000001;
case Unknown:
return 0;
}
return 0;
因为解析 Rule 的顺序是从右向左进行的,所以计算优先级也会按照这个顺序取得对应 Selector 的权重后相加。来看几个例子:
/*
* 65793 = 65536 + 1 + 256
*/
#container p .text {
font-size: 16px;
}
/*
* 2 = 1 + 1
*/
div p {
font-size: 14px;
}
当前节点所有匹配的 Rule 都放入结果集合之后,先根据优先级从小到大排序,如果有优先级相同的 Rule,则比较它们的位置。
内联样式优先级
authorStyleSheet 的 Rule 处理完毕,才会设置内联样式;内联样式在构建 DOM Tree 的时候就已经处理完成并存放到节点的 style 属性上了。
内联样式会放到已经排序的结果集合最后,所以如果不设置 !important,内联样式的优先级是最大的。
!important 优先级
在设置 !important 的声明前,会先设置不包含 !important 的所有声明,之后再添加到结果集合的尾部;因为这个集合是按照优先级从小到大排序好的,所以 !important 的优先级就变成最大的了。
书写 CSS 的规则
结果集合最后会生成 ComputedStyle 对象,可以通过 window.getComputedStyle 方法来查看所有声明。
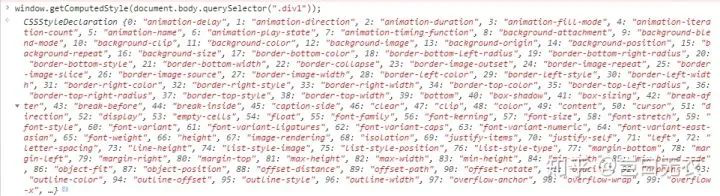

可以发现图中的声明是没有顺序的,说明书写规则的最大作用是为了良好的阅读体验,利于团队协作。
调整 Style
这一步会调整相关的声明;例如声明了 position: absolute;,当前节点的 display 就会设置成 block。
Render Object Tree
在 DOM Tree 和 CSSOM Tree 构建完毕之后,才会开始生成 Render Object Tree(Document 节点是特例)。
创建 Render Object
在创建 Document 节点的时候,会同时创建一个 Render Object 作为树根。Render Object 是一个描述节点位置、大小等样式的可视化对象。
每个非 display: none | contents 的节点都会创建一个 Render Object,流程大致如下:生成 ComputedStyle(在 CSSOM Tree 计算这一节中有讲),之后比较新旧 ComputedStyle(开始时旧的 ComputedStyle 默认是空);不同则创建一个新的 Render Object,并与当前处理的节点关联,再建立父子兄弟关系,从而形成一棵完整的 Render Object Tree。
布局(重排)
Render Object 在添加到树之后,还需要重新计算位置和大小;ComputedStyle 里面已经包含了这些信息,为什么还需要重新计算呢?因为像 margin: 0 auto; 这样的声明是不能直接使用的,需要转化成实际的大小,才能通过绘图引擎绘制节点;这也是 DOM Tree 和 CSSOM Tree 需要组合成 Render Object Tree 的原因之一。
布局是从 Root Render Object 开始递归的,每一个 Render Object 都有对自身进行布局的方法。为什么需要递归(也就是先计算子节点再回头计算父节点)计算位置和大小呢?因为有些布局信息需要子节点先计算,之后才能通过子节点的布局信息计算出父节点的位置和大小;例如父节点的高度需要子节点撑起。如果子节点的宽度是父节点高度的 50%,要怎么办呢?这就需要在计算子节点之前,先计算自身的布局信息,再传递给子节点,子节点根据这些信息计算好之后就会告诉父节点是否需要重新计算。
数值类型
所有相对的测量值(rem、em、百分比...)都必须转换成屏幕上的绝对像素。如果是 em 或 rem,则需要根据父节点或根节点计算出像素。如果是百分比,则需要乘以父节点宽或高的最大值。如果是 auto,需要用 (父节点的宽或高 - 当前节点的宽或高) / 2 计算出两侧的值。
盒模型
众所周知,文档的每个元素都被表示为一个矩形的盒子(盒模型),通过它可以清晰的描述 Render Object 的布局结构;在 blink 的源码注释中,已经生动的描述了盒模型,与原先耳熟能详的不同,滚动条也包含在了盒模型中,但是滚动条的大小并不是所有的浏览器都能修改的。
// ***** THE BOX MODEL *****
// The CSS box model is based on a series of nested boxes:
// http://www.w3.org/TR/CSS21/box.html
// top
// |----------------------------------------------------|
// | |
// | margin-top |
// | |
// | |-----------------------------------------| |
// | | | |
// | | border-top | |
// | | | |
// | | |--------------------------|----| | |
// | | | | | | |
// | | | padding-top |####| | |
// | | | |####| | |
// | | | |----------------| |####| | |
// | | | | | | | | |
// left | ML | BL | PL | content box | PR | SW | BR | MR |
// | | | | | | | | |
// | | | |----------------| | | | |
// | | | | | | |
// | | | padding-bottom | | | |
// | | |--------------------------|----| | |
// | | | ####| | | |
// | | | scrollbar height ####| SC | | |
// | | | ####| | | |
// | | |-------------------------------| | |
// | | | |
// | | border-bottom | |
// | | | |
// | |-----------------------------------------| |
// | |
// | margin-bottom |
// | |
// |----------------------------------------------------|
//
// BL = border-left
// BR = border-right
// ML = margin-left
// MR = margin-right
// PL = padding-left
// PR = padding-right
// SC = scroll corner (contains UI for resizing (see the 'resize' property)
// SW = scrollbar width
box-sizing
box-sizing: content-box | border-box,content-box 遵循标准的 W3C 盒子模型,border-box 遵守 IE 盒子模型。
它们的区别在于 content-box 只包含 content area,而 border-box 则一直包含到 border。通过一个例子说明:
// width
// content-box: 40
// border-box: 40 + (2 * 2) + (1 * 2)
div {
width: 40px;
height: 40px;
padding: 2px;
border: 1px solid #ccc;
}
Render Layer Tree
Render Layer 是在 Render Object 创建的同时生成的,具有相同坐标空间的 Render Object 属于同一个 Render Layer。这棵树主要用来实现层叠上下文,以保证用正确的顺序合成页面。
创建 Render Layer
满足层叠上下文条件的 Render Object 一定会为其创建新的 Render Layer,不过一些特殊的 Render Object 也会创建一个新的 Render Layer。
创建 Render Layer 的原因如下:
- NormalLayer
- position 属性为 relative、fixed、sticky、absolute
- 透明的(opacity 小于 1)、滤镜(filter)、遮罩(mask)、混合模式(mix-blend-mode 不为 normal)
- 剪切路径(clip-path)
- 2D 或 3D 转换(transform 不为 none)
- 隐藏背面(backface-visibility: hidden)
- 倒影(box-reflect)
- column-count(不为 auto)或者column-widthZ(不为 auto)
- 对不透明度(opacity)、变换(transform)、滤镜(filter)应用动画
- OverflowClipLayer
- 剪切溢出内容(overflow: hidden)
另外以下 DOM 元素对应的 Render Object 也会创建单独的 Render Layer:
- Document
- HTML
- Canvas
- Video
如果是 NoLayer 类型,那它并不会创建 Render Layer,而是与其第一个拥有 Render Layer 的父节点共用一个。
Graphics Layer Tree
软件渲染
软件渲染是浏览器最早采用的渲染方式。在这种方式中,渲染是从后向前(递归)绘制 Render Layer 的;在绘制一个 Render Layer 的过程中,它的 Render Objects 不断向一个共享的 Graphics Context 发送绘制请求来将自己绘制到一张共享的位图中。
硬件渲染
有些特殊的 Render Layer 会绘制到自己的后端存储(当前 Render Layer 会有自己的位图),而不是整个网页共享的位图中,这些 Layer 被称为 Composited Layer(Graphics Layer)。最后,当所有的 Composited Layer 都绘制完成之后,会将它们合成到一张最终的位图中,这一过程被称为 Compositing;这意味着如果网页某个 Render Layer 成为 Composited Layer,那整个网页只能通过合成来渲染。除此之外,Compositing 还包括 transform、scale、opacity 等操作,所以这就是硬件加速性能好的原因,上面的动画操作不需要重绘,只需要重新合成就好。
上文提到软件渲染只会有一个 Graphics Context,并且所有的 Render Layer 都会使用同一个 Graphics Context 绘制。而硬件渲染需要多张位图合成才能得到一张完整的图像,这就需要引入 Graphics Layer Tree。
Graphics Layer Tree 是根据 Render Layer Tree 创建的,但并不是每一个 Render Layer 都会有对应的 Composited Layer;这是因为创建大量的 Composited Layer 会消耗非常多的系统内存,所以 Render Layer 想要成为 Composited Layer,必须要给出创建的理由,这些理由实际上就是在描述 Render Layer 具备的特征。如果一个 Render Layer 不是 Compositing Layer,那就和它的祖先共用一个。
每一个 Graphics Layer 都会有对应的 Graphics Context。Graphics Context 负责输出当前 Render Layer 的位图,位图存储在系统内存中,作为纹理(可以理解为 GPU 中的位图)上传到 GPU 中,最后 GPU 将多张位图合成,然后绘制到屏幕上。因为 Graphics Layer 会有单独的位图,所以在一般情况下更新网页的时候硬件渲染不像软件渲染那样重新绘制相关的 Render Layer;而是重新绘制发生更新的 Graphics Layer。
提升原因
Render Layer 提升为 Composited Layer 的理由大致概括如下,更为详细的说明可以查看 无线性能优化:Composite —— 从 PaintLayers 到 GraphicsLayers。
- iframe 元素具有 Composited Layer。
- video 元素及它的控制栏。
- 使用 WebGL 的 canvas 元素。
- 硬件加速插件,例如 flash。
- 3D 或透视变换(perspective transform) CSS 属性。
- backface-visibility 为 hidden。
- 对 opacity、transform、fliter、backdropfilter 应用了 animation 或者 transition(需要是 active 的 animation 或者 transition,当 animation 或者 transition 效果未开始或结束后,提升的 Composited Layer 会恢复成普通图层)。
- will-change 设置为 opacity、transform、top、left、bottom、right(其中 top、left 等需要设置明确的定位属性,如 relative 等)。
- 有 Composited Layer 后代并本身具有某些属性。
- 元素有一个 z-index 较低且为 Composited Layer 的兄弟元素。
为什么需要 Composited Layer?
避免不必要的重绘。例如网页中有两个 Layer a 和 b,如果 a Layer 的元素发生改变,b Layer 没有发生改变;那只需要重新绘制 a Layer,然后再与 b Layer 进行 Compositing,就可以得到整个网页。
利用硬件加速高效实现某些 UI 特性。例如滚动、3D 变换、透明度或者滤镜效果,可以通过 GPU(硬件渲染)高效实现。
层压缩
由于重叠的原因,可能会产生大量的 Composited Layer,就会浪费很多资源,严重影响性能,这个问题被称为层爆炸。浏览器通过 Layer Squashing(层压缩)处理这个问题,当有多个 Render Layer 与 Composited Layer 重叠,这些 Render Layer 会被压缩到同一个 Composited Layer。来看一个例子:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<style>
div {
position: absolute;
width: 100px;
height: 100px;
}
.div1 {
z-index: 1;
top: 10px;
left: 10px;
will-change: transform;
background-color: #f00;
}
.div2 {
z-index: 2;
top: 80px;
left: 80px;
background-color: #f0f;
}
.div3 {
z-index: 2;
top: 100px;
left: 100px;
background-color: #ff0;
}
</style>
<title>Document</title>
</head>
<body>
<div class="div1"></div>
<div class="div2"></div>
<div class="div3"></div>
</body>
</html>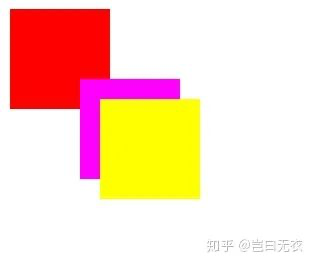
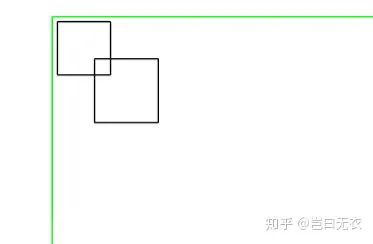
可以看到后面两个节点重叠而压缩到了同一个 Composited Layer。
有一些不能被压缩的情况,可以在 无线性能优化:Composite —— 层压缩 中查看。

