
一次JS优化实战转载
导语
本篇为实战篇,重点不在阐明内存管理、GC 算法干货也相对较少,更多的内容放在了实操步骤,JS优化的方法作者一共列出7种。希望大家能有所收获。
正文
工具
工欲善其事,必先利其器。既然要讲性能优化,就需要量化的指标来告诉我们性能到底被优化了没有,优化了多少。js 的性能优化主要优化的地方有两个,一个是内存管理,另一个就是 js 代码的执行效率。因此这里我们主要关注的是内存如何变化、执行效率如何
内存
内存问题一般有三种:频繁地垃圾回收、内存膨胀、内存泄漏
观察页面
表现
如果页面存在内存问题,通常会有下面这些外在表现
- 页面出现延迟加载或经常性暂停(若网络状态正常,则可能出现了频繁的垃圾回收)
- 页面持续性出现糟糕的性能(可能出现内存膨胀,所需空间超过最大内存上限)
- 页面性能随时间延长越来越差(可能出现内存泄漏)
- (V8 内存限制:64 位上限不超过 1.5G,32 位上限不超过 800M)
标准
页面出现上述情况,不一定就是内存问题,还需要进一步借助工具判断内存
- 内存泄漏:可观测到内存使用持续升高
- 内存膨胀:在多数设备上都存在性能问题
- 频繁垃圾回收:通过内存变化图进行分析
Performance
打开浏览器输入目标网址(不直接访问)
进入开发人员工具面板,选择性能
开启录制功能,访问具体界面(开始访问)
- 执行用户行为,一段时间后停止录制
- 勾选展示内存(js 堆)
- 分析 Timeline 时序图记录的内存情况
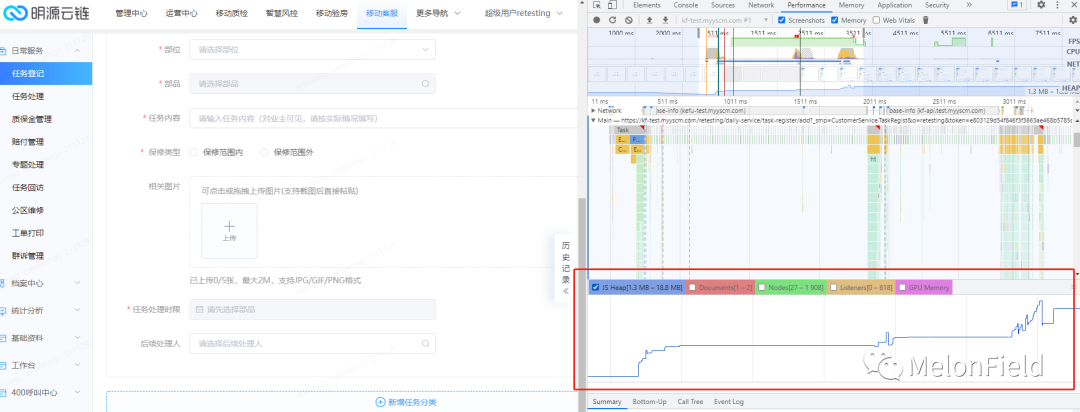
- 出现内存泄漏时,Timeline 中内存一路升高
- 出现频繁的垃圾回收时,Timeline 中出现频繁的上升下降
任务管理器监控内存
右上角更多工具里找到任务管理器(快捷键:Shift + Esc)
找到当前页面正在执行的脚本
右击选择展示 javaScript 内存
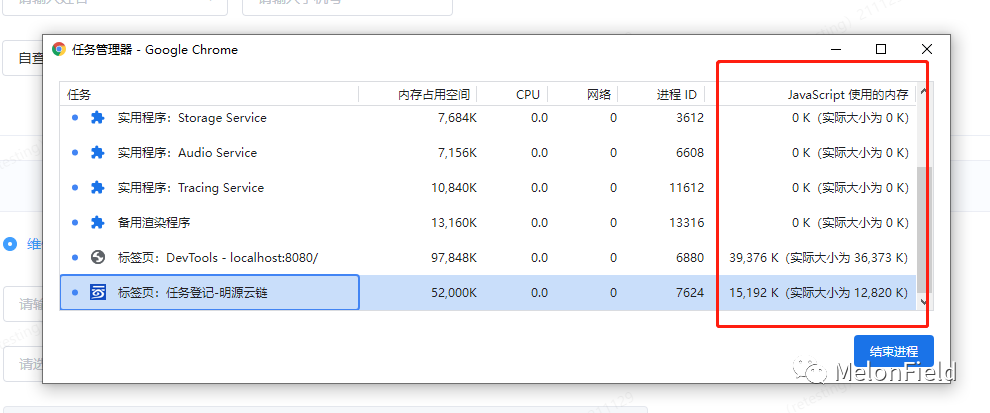
内存:Dom 节点所占据的内存
JavaScript 内存:js 的堆,小括号中表示所有可达对象正在使用的内存大小
堆快照
主要用途:查找分离 DOM
页面上的 DOM 节点都在 DOM 树上
当 DOM 节点脱离了 DOM 树,且 JS 中对其没有引用,这时候的 DOM 就是垃圾对象
如果只是脱离 DOM 树,但 JS 中仍在引用,这种就叫做分离 DOM
如何使用
开发工具中找到内存 Tab(Memory)
选择堆快照(Heap Snapshot)
获取快照(Take snapshot)
页面交互
再次获取交互后的快照
在快照中搜索 detached 关键字查找是否存在分离 DOM
上栗子
<body>
<button id="button">创建</button>
<script>
const oBtn = document.getElementById("button");
let template = null;
function example() {
var ul = document.createElement("ul");
for (let i = 0; i < 10; i++) {
var li = document.createElement("li");
ul.appendChild(li);
}
template = ul;
}
oBtn.addEventListener("click", example);
</script>
</body>
进入页面后获取一次快照
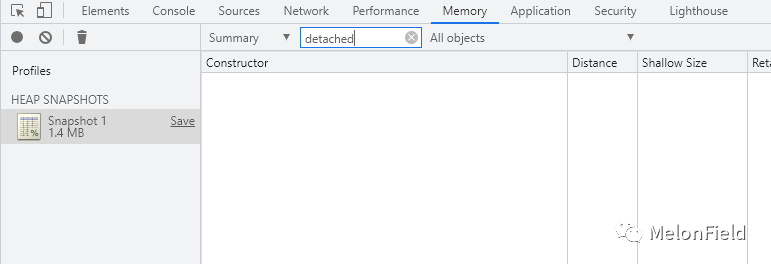
点击创建按钮后再获取一次快照
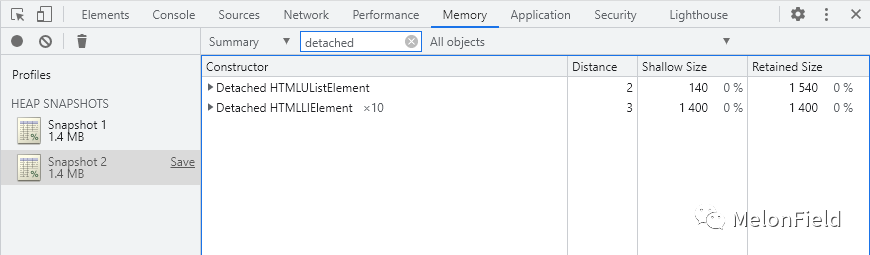
可以看到此时内存中存在分离的 ul 节点以及 10 个分离的 li 节点
原因就是这里创建的 ul 和 li 节点都没有挂载到 Dom 树上,同时 example 函数执行结束后,template 仍引用着 ul
执行效率
JSBench
JSBench 是一个在线测试 JS 代码执行效率的网站
大致分为以下模块
setup:前置条件,可以预设测试所需的 HTML 或 JS
test case:测试用例,主要就是使用 case 对比 js 的执行效率,用例名称可自定义,以下是我常用的用例名称,便于区分
before: 修改之前的代码
after:修改之后的代码
teardown:统一的收尾工作
关键数值:ops/s 每秒执行次数,越大越好
注意:
建议测试时只开一个标签页,防止其它标签页抢占资源
测试过程最好停留在当前页面,防止被挂起,影响准确性
多次测试
JS 性能优化
内存的问题多出现在业务逻辑中,场景复杂,没有通用的解决方式,只能在发现时再去定位问题解决问题,常见的手段包括:将不需要使用的引用对象手动置为 null,方便 GC 回收;使用了 setTimeout 及 setInterval 后记得清除
这里列举几个常用的提升 js 代码执行效率的写法习惯
变量局部化
变量能放局部作用域(私有上下文)尽量放在局部作用域中,可以提高代码的执行效率。
为什么能提高呢?本质上是减少了数据访问时需要查找的路径
上栗子
// before
var i,
str = "";
function packageDom1() {
for (i = 0; i < 100; i++) {
str += i;
}
}
packageDom1();
// after
function packageDom2() {
var str = "";
for (var i = 0; i < 100; i++) {
str += i;
}
}
packageDom2();
看到注释的 before、after 了吗?这里就需要使用一下 JSBench 来测一下两段代码的效率了
来看一下结果
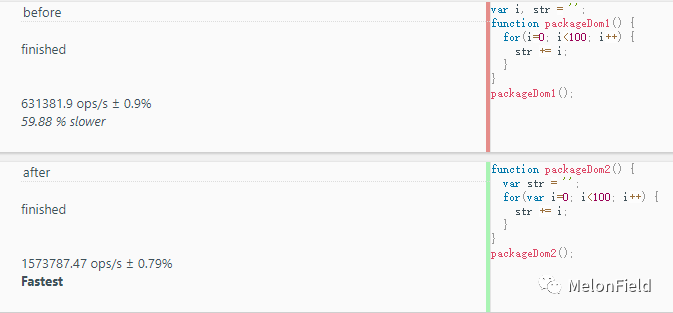
before:631381.9 ops/s
after:1573787.47 ops/s
明显 after 每秒执行次数远远高于 before 的代码,因此效率更高
下面来分析一下代码是如何执行的
before 的代码
- 全局变量对象 VO(G) 中存在变量 i 和变量 str
- packageDom1 函数需要一个堆内存空间,[[scope]] 就是全局执行上下文 EC(G),需要执行的函数就是它的函数体
- packageDom1 执行时会新开辟一个执行上下文,其作用域链就是当前执行上下文以及全局上下文,<EC(packageDom1), EC(G)>
- 开始执行函数体,需要变量 i,当前上下文没有,因此需要向上找,在全局上下文中找到;同样的,变量 s 也需要沿着作用域链向上查找
- 因此循环次数越多,查找的次数也就越多了
after 代码
- 前面的流程就不赘述了,packageDom2 在执行时,在当前上下文中就能找到变量 i 和 s,不需要再向上查找了
缓存数据
对于需要多次使用的数据进行提前保存,后续直接使用
上栗子
前置条件
// setup html
<div class="div-box" id="box"></div>;
// setup JS
var oBox = document.getElementById("box");
测试用例
// before
function hasClassName(ele, cls) {
return ele.className === cls;
}
// after
function hasClassName(ele, cls) {
var className = ele.className;
return className === cls;
}
后置 js
hasClassName(oBox, "box");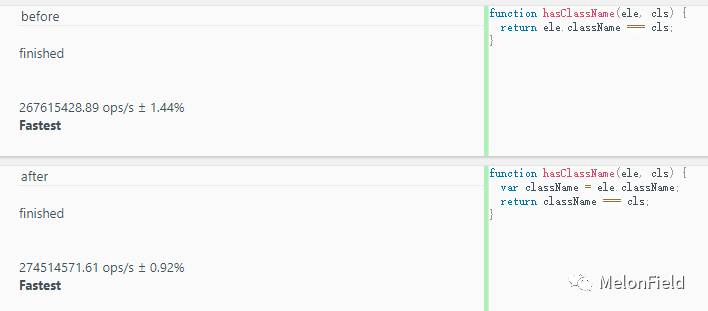
before: 267615428.89 ops/s
after: 274514571.61 ops/s
这里 after 效率不如 before,原因是函数体中对 className 的调用还比较少,且 after 函数体中的代码要比 before 中多,编译时间(词法分析)比 before 久
我们再来改造一下测试用例,通过循环增加 className 的访问次数
// before
function hasClassName(ele, cls) {
for (let i = 0; i < 100; i++) {
console.log(ele.className);
}
return ele.className === cls;
}
// after
function hasClassName(ele, cls) {
var className = ele.className;
for (let i = 0; i < 100; i++) {
console.log(className);
}
return className === cls;
}
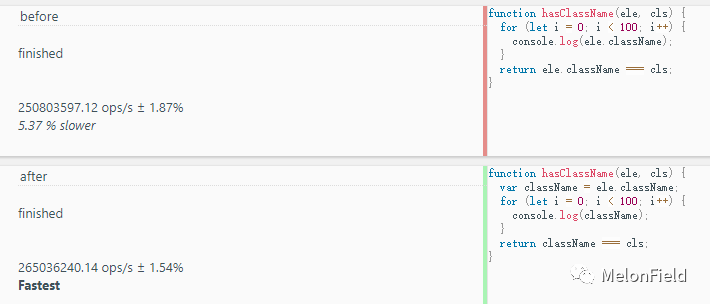
before: 250803597.12 ops/s
after: 265036240.14 ops/s
这里就能看到 after 效率要比 before 高,根本原因就是 after 中将 className 缓存到了 hasClassName 函数的执行上下文中,访问时不需要再到堆中去找 className 属性
可以看出来这是一种用空间换时间的做法
减少访问层级
这把直接上栗子
// before
function Person() {
this.name = "myy";
this.age = 23;
this.getAge = function () {
return this.age;
};
}
let p = new Person();
console.log(p.getAge());
// after
function Person() {
this.name = "myy";
this.age = 23;
}
let p = new Person();
console.log(p.age);
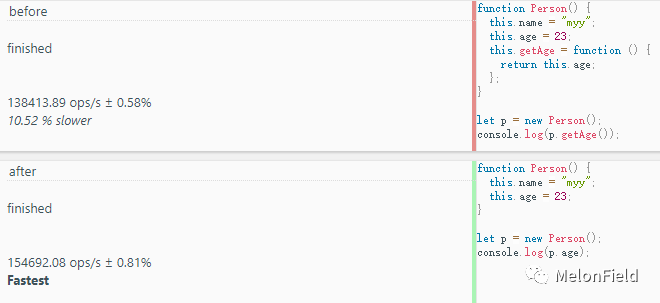
before: 138413.89 ops/s
after: 154692.08 ops/s
显然 after 的代码比 before 的代码更高效
这里主要还是看业务场景,是否允许直接读取属性
防抖与节流
目的:高频率事件触发的场景下,不希望对应的事件处理函数多次执行
常见应用场景:
滚动事件
输入的模糊匹配
轮播图的切换
点击操作
浏览器默认情况下都会有自己的监听事件间隔(4~6ms),如果监测到多次事件的监听执行,那么就会造成不必要的资源浪费。
防抖:对于高频操作,我们只希望识别一次点击、可以认为是第一次或是最后一次
节流:对于高频操作,可以自己来设置频率,让本来会执行多次的事件触发、按我们定义的频率减少触发次数
防抖
上栗子
<body>
<button id="btn">click</button>
<script>
var btn = document.getElementById("btn");
btn.onclick = btnClickHandle();
function btnClickHandle(ev) {
console.log("点我了!", this, ev);
}
</script>
</body>
这就是一般的事件点击,用户可以频繁点击
来看一下防抖版本的点击事件
btn.onclick = debounce(btnClickHandle, false);
/**
* @param {function} handle 最终需要执行的事件处理函数
* @param {number} wait 事件出发后多久开始执行
* @param {boolean} immediate 控制执行第一次还是最后一次
* @return {function}
*/
function debounce(handle, wait, immediate) {
// 首先对参数类型做一下判断
if (typeof handle !== "function") {
throw new Error("handle must be an function");
}
if (typeof wait === "undefined") {
wait = 300;
}
// 允许第二个参数传入的是布尔类型,即 immediate
if (typeof wait === "boolean") {
immediate = wait;
wait = 300;
}
if (typeof immediate !== "boolean") {
immediate = false;
}
// 第一种情况,immediate 为 false
// 效果:用户在高频操作后只执行最后一次操作(两次点击间隔不超过 300 ms 即视为高频操作)
let timer = null;
return function proxy(...args) {
// 清除上一次点击产生的定时器
clearTimeout(timer);
timer = setTimeout(() => {
handle.call(this, ...args);
}, wait);
};
}
第二种情况,immediate 为 true 效果:用户在高频操作后只执行第一次操作(300 ms 内视为一轮高频操作)
let timer = null;
return function proxy(...args) {
if (!timer) {
handle.call(this, ...args);
}
// 清除上一次点击产生的定时器
clearTimeout(timer);
timer = setTimeout(() => {
// 这一轮高频操作后重新将 timer 置为 null
timer = null;
}, wait);
};
整合一下两种情况
/**
* @param {function} handle 最终需要执行的事件处理函数
* @param {number} wait 事件出发后多久开始执行
* @param {boolean} immediate 控制执行第一次还是最后一次
* @return {function}
*/
function debounce(handle, wait, immediate) {
// 首先对参数类型做一下判断
if (typeof handle !== "function") {
throw new Error("handle must be an function");
}
if (typeof wait === "undefined") {
wait = 300;
}
// 允许第二个参数传入的是布尔类型,即 immediate
if (typeof wait === "boolean") {
immediate = wait;
wait = 300;
}
if (typeof immediate !== "boolean") {
immediate = false;
}
let timer = null;
return function proxy(...args) {
if (immediate && !timer) {
handle.call(this, ...args);
}
clearTimeout(timer);
timer = setTimeout(() => {
timer = null;
if (!immediate) {
handle.call(this, ...args);
}
}, wait);
};
}
节流
老规矩,上栗子
<style>
body {
height: 5000px;
}
</style>
<body>
<script>
// 节流:我们这里的节流指的就是在自定义的一段时间内让事件进行触发
// 定义滚动事件监听
function scrollHandle() {
console.log("滚了滚了");
}
window.onscroll = scrollHandle;
</script>
</body>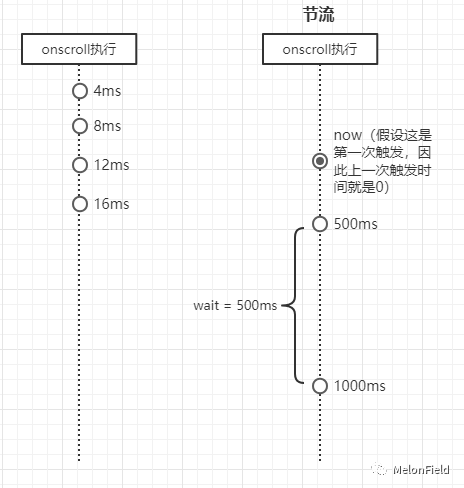
节流方式实现
- 假设当前在 5ms 的事件点上执行了一次 proxy,就是图上的 now 这个节点,我们就可以用这个时间减去上次执行的时间(0),得到一个时间差
- 假设我们定义 wait 就是 500 ms
- wait - (now - previous)
- 如果上述的计算结果大于 0,就意味着当前次的操作是一个高频操作,因此不能去执行 handle;如果上述结果小于等于 0,这就意味着当前次不是一个高频操作,那么就可以直接执行 handle
- 此时可以想办法让所有的高频操作在 500ms 内都只执行一次
function scrollHandle() {
console.log("滚了滚了");
}
window.onscroll = throttle(scrollHandle, 600);
/**
* @param {function} handle 最终需要执行的事件处理函数
* @param {number} wait 事件出发后多久开始执行
* @return {function}
*/
function throttle(handle, wait = 400) {
if (typeof handle !== "function") {
throw new Error("handle must be an function");
}
let previous = 0; // 定义变量记录上一次执行的时间
let timer = null; // 管理定时器
return function proxy(...args) {
let now = new Date(); // 定义变量记录当前执行的时刻时间点
let self = this;
let interval = wait - (now - previous);
if (interval <= 0) {
// 此时是一个非高频操作,可以执行 handle
clearTimeout(timer);
timer = null;
handle.call(self, ...args);
previous = new Date();
} else if (!timer) {
// 此时这次的操作发生在频次时间范围内,不应该执行 handle
// 可以自己定义一个定时器,让 handle 在 interval 之后去执行
timer = setTimeout(() => {
// 这里只是将系统中的定时器清除了,但是 timer 中的值还在
clearTimeout(timer);
timer = null;
handle.call(self, ...args);
previous = new Date();
}, interval);
}
};
}
减少判断层级
处理 if 嵌套,提前 return
上栗子
背景:视频播放列表中以模块划分,每个模块下分收费与免费,每个模块下的前 5 个小节内容为免费,超过了第 5 个小节,需要跳转到 vip 连接
// before
function play(part, chapter) {
const parts = ["ES2016", "工程化", "Vue", "React"];
if (part) {
if (parts.includes(part)) {
console.log("属于前端课程");
if (chapter > 5) {
console.log("您需要提供 VIP 身份");
}
}
} else {
console.log("请确认模块信息");
}
}
// after
function play(part, chapter) {
const parts = ["ES2016", "工程化", "Vue", "React"];
if (!part) {
console.log("请确认模块信息");
return;
}
if (!parts.includes(part)) {
return;
}
console.log("属于前端课程");
if (chapter > 5) {
console.log("您需要提供 VIP 身份");
}
}
后置脚本
play("Vue", 6);
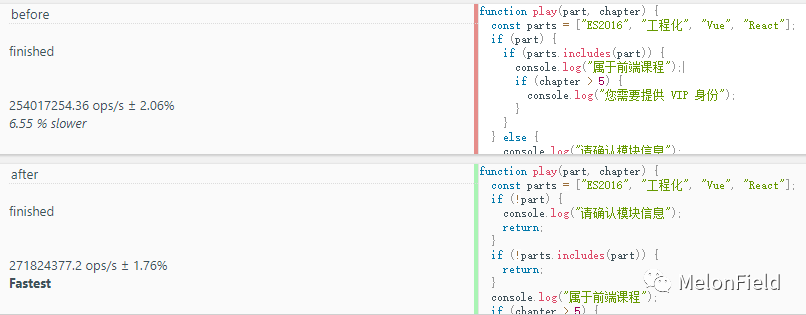
before: 254017254.36 ops/s
after: 271824377.2 ops/s
减少循环体活动
这里主要讨论循环的功能而不是讨论应该采用哪种循环的结构,因此这里以 for 循环演示
// before
var test = () => {
var arr = ["myy", 23, "0909.HK"];
for (var i = 0; i < arr.length; i++) {
console.log(arr[i]);
}
};
将循环体内不变的部分抽离出来
// after
var test = () => {
var arr = ["myy", 23, "0909.HK"];
var len = arr.length;
for (var i = 0; i < len; i++) {
console.log(arr[i]);
}
};
后置脚本
test();
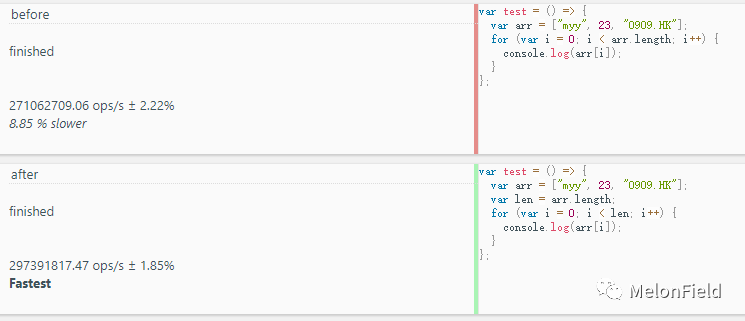
before: 271062709.06 ops/s
after: 297391817.47 ops/s
after 效率要比 before 要高
当对输出顺序没有要求时,可以考虑换一种循环结构,比如 while
// while
var test = () => {
var arr = ["myy", 23, "0909.HK"];
var len = arr.length;
while (len--) {
console.log(arr[len]);
}
};
如果单从代码量来看,while 这种方式最简洁,使用 JSBench 再来看一下执行效率
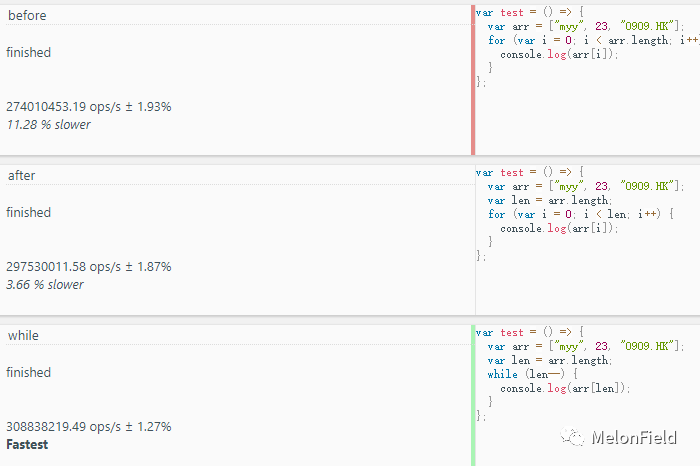
before: 274010453.19 ops/s
after: 297530011.58 ops/s
while: 308838219.49 ops/s
从图中可以看出,while 循环不但代码量少,执行效率也是最高的
字面量与构造式
引用类型
// before
var test = () => {
let obj = new Object();
obj.name = "myy";
obj.age = 23;
return obj;
};// after
var test = () => {
let obj = {
name: "myy",
age: 23,
};
return obj;
};
后置脚本
console.log(test());
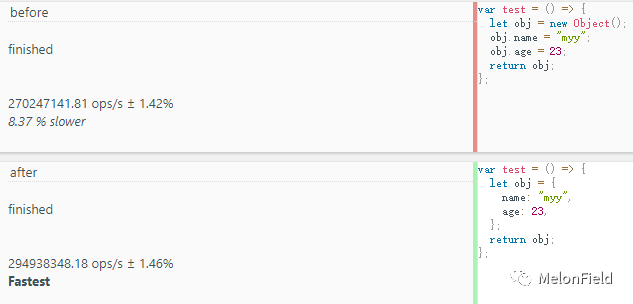
before: 270247141.81 ops/s
after: 294938348.18 ops/s
毫不意外,依然是 after 效率更高。before 中的代码涉及到函数的调用(Object());而 after 直接开辟了块空间,往里存数据就行了
基本数据类型
// before
var str1 = new String("myy"); // 字符串,内部默认将 str1 转成对象再去调用方法
console.log(str1);
// after
var str2 = "myy"; // 对象,沿着原型链直接调用 String 上的方法
console.log(str2);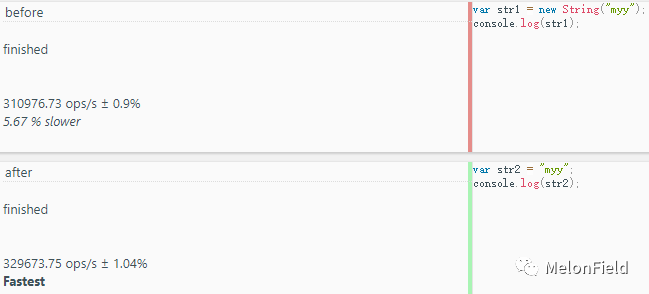
before: 310976.73 ops/s
after: 329673.75 ops/s
依旧是 after 效率高。
before 代码中的 str1 是个对象,可以沿着原型链直接调用 String 上的方法;after 的代码执行时,js 引擎默认将 str1 转成字符串对象再去调用方法
再来看个小栗子
前置条件
var str1 = new String("foo");
var str2 = "foo";
测试用例
// before
var result = str1.split("");
// after
var result = str2.split("");
后置条件
console.log(result);
这里我们测试的就是通过 new String 得到的字符串对象,在调用原型上的函数时是不是会更快
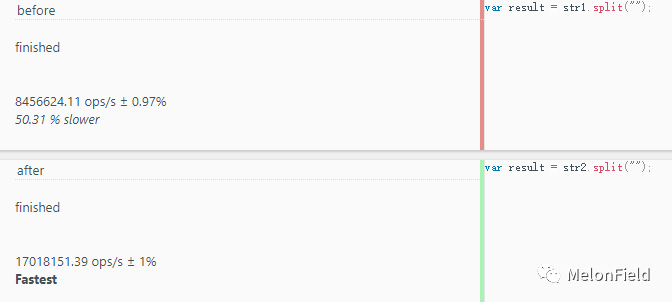
before: 8456624.11 ops/s
after: 17018151.39 ops/s
after 每秒执行次数接近 before 的两倍,可见字符串对象调用原型上函数的执行效率依然不如直接声明字符串


