
详解MySql性能优化的几种可行方案!转载
导语
一个优秀开发的必备技能:性能优化,包括:JVM调优、缓存、Sql性能优化等。本文主要讲基于Mysql的索引优化。本文为一篇SQL通用的干货,主要以干货和思路为主,性能优化也是一种进阶内容,希望大家掌握基础知识学以致用!
正文
MySql索引结构
「B树」
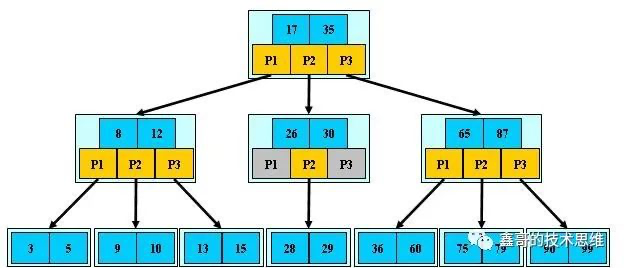
「B+树」
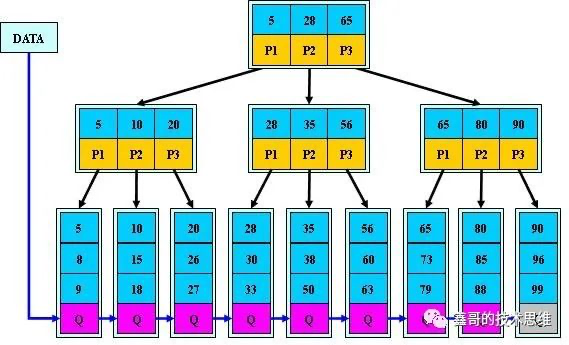
「B树」 VS 「B+树」
B+树的「非叶子」节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加。
B+树「叶子」节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样。
B+树「叶子」节点的关键字从小到大「有序」排列,左边结尾数据都会保存右边节点开始数据的指针。
B+树的「层级更少」:相较于B树,B+每个「非叶子」节点存储的关键字数更多,树的层级更少所以查询数据更快;
B+树「查询速度更稳定」:B+所有关键字数据地址都存在「叶子」节点上,所以每次查找的次数都相同,所以查询速度要比B树更稳定;
B+树「天然具备排序功能」:B+树所有的「叶子」节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
B+树「全节点遍历更快」:B+树遍历整棵树只需要遍历所有的「叶子」节点即可,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
存储引擎
两个主要的存储引擎:「InnoDB」 & 「MyISAM」。
它们默认都会创建一个主键索引,且默认使用的是 B+树 索引。
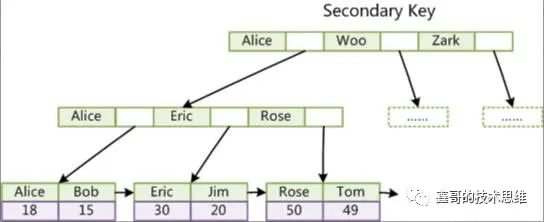
InnoDB 默认创建的主键索引是「聚簇索引」,其它索引都属于「辅助索引」,也被称为「二级索引」或「非聚簇索引」。
不过虽然这两个存储引擎都支持 B+树 索引,但它们在具体的「数据存储结构方面有所不同」。
「MyISAM」索引文件和数据文件是分开的
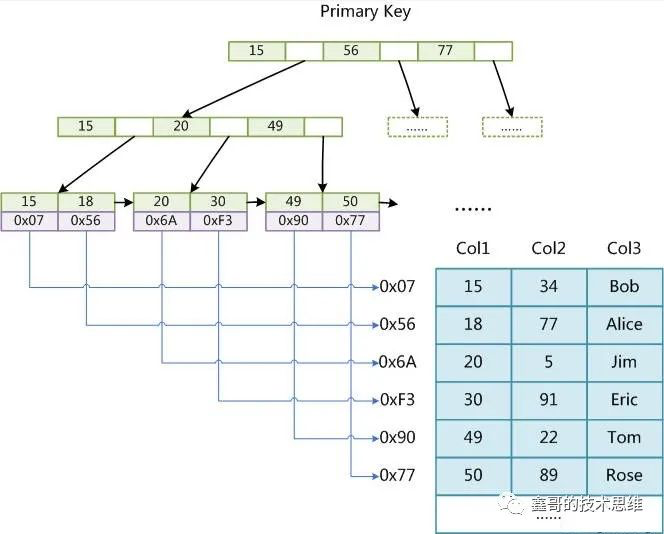
「InnoDB」InnoDB索引树需要分情况
「主键索引」
索引和数据放在一棵索引树上面,由于主键索引是聚簇索引,整行数据都存储在叶子节点上,通过索引可以直接拿到数据。
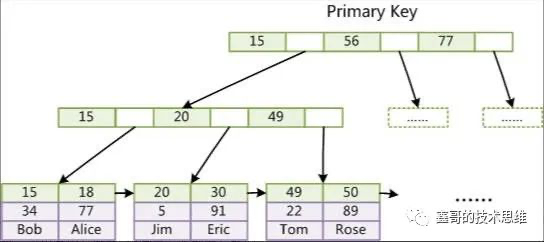
「非主键索引」
会再开一棵 B+树,而它的叶子节点存储的data数据是索引所在行数据的主键。如果要通过非主键索引查找数据的话,分两步:
1.先查找到它的主键
2.再去主键索引里查找相应的数据(回表)
索引优化建议
覆盖索引优化
假设我们需要查询商品的条码、名称、价格信息。为了避免回表,可以将商品条码、名称、价格建立一个组合索引,那么索引中就会存在这些数据,查询将不会再次检索主键索引,从而避免回表,不需要查询出包含整行记录的所有信息,可以减少大量的 I/O 操作。
自增主键
InnoDB 创建主键索引默认是聚簇索引,整行数据都存储在叶子节点上,同一个叶子节点内的各个数据是按主键顺序存放的,每当有一条新的数据插入时,数据库会根据主键将其插入到对应的叶子节点中。
如果使用自增主键,每次插入的新数据就会按顺序添加到当前索引节点的位置,不需要移动已有的数据,当页面写满,就会自动开辟一个新页面。因为不需要重新移动数据,所以这种插入数据的方法效率非常高。
如果使用非自增主键,每次插入新的数据时,就可能会插入到现有数据页中间的某个位置,导致不得不移动其它数据,可能会造成大量的内存碎片,导致索引结构不紧凑,影响查询效率。
前缀索引
当我们索引的字段是很长的字符串时,可以用到前缀索引。即定义字符串的一部分当做索引,指定前缀字节长度,而不是把整个字符串当做索引。
前缀索引存储了更少的数据,他耗费的空间也就相比较少,这是他的一个优点。同样的也就相对增加了扫描行数。因为前缀字符串的重复概率要比覆盖索引大,查询时在前缀索引中找到包含这个前缀的主键id后,还要去主键索引中找到完整字符串,不正确时还需要再次查询前缀索引树,因此前缀索引增加了扫描行数,比覆盖索引多了一步回表。
防止索引失效

可能命中的索引
联合索引最左匹配原则:比如以a、b、c这3个字段作为联合索引,只会走a、a,b、a,b,c 三种类型的查询。不过要说明一点,a,c也走,但是只走a字段索引,不会走c字段。不以a开头都不会走索引。
如果查询条件中使用 or,且 or 的前后条件中有一个列没有索引,那么该查询不会走任何索引。
对索引进行函数操作或者表达式计算也会导致索引的失效
以 % 开头的 LIKE 查询,将无法利用节点查询数据
高并发事务与死锁
原因分析
数据库事务有四个基本属性(ACID):原子性(Atomicity)、一致性(Consistent)、隔离性(Isolation)以及持久性(Durable)。
MySQL中,MyISAM 存储引擎不支持事务
并发事务带来的问题
数据丢失

脏读

幻读

不可重复读

并发事务问题的解决方案
数据丢失
可以基于数据库中的「悲观锁」来避免,在查询时通过在事务中使用 select xx for update 语句来实现排他锁,保证在该事务结束之前其他事务无法更新该数据。
也可以基于「乐观锁」来避免,将某一字段作为版本号,如果更新时的版本号跟之前的版本一致,则更新,否则更新失败。
事务隔离级别
结合业务场景,使用低级别事务隔离
避免行锁升级表锁
控制事务的大小,减少锁定的资源量和锁定时间长度
InnoDB 实现了「共享锁」和「排他锁」
共享锁:允许一个事务读数据,不允许修改
数据排他锁:修改数据时加的锁,可以读取和修改数据。
申请前提 : 没有线程对该结果集中的任何行数据使用排他锁或共享锁,否则申请会阻塞
「事务隔离级别介绍(级别越高,并发性越低)」
「读未提交(Read Uncommitted):」 事务 A 已经开始写数据,则事务 B 不允许同时进行写操作,但允许读此行数据(事务 A 还未提交)。会导致脏读、幻读、不可重复读。
「读已提交(Read Committed):」 如果事务 A 是读事务,则允许其他事务读写;如果事务 A 是写事务,将会禁止其他事务读该行未提交的数据。事务 A 事先读取了数据,事务 B 紧接着更新了数据,并提交了事务,而事务 A 再次读取该数据时,数据已经发生了改变。可以「避免脏读」,但依然存在幻读和不可重复读的问题。
「可重复读(Repeatable Read):」 在一个事务内,多次读同一个数据,在这个事务还没结束时,其他事务不能读写该数据,这样就可以在同一个事务内两次读到的数据是一样的。可以「避免脏读、不可重复读」,但依然存在幻读的问题。
「串行化(Serializable):」 最严格的事务隔离,要求事务序列化执行,事务只能一个接着一个地执行,但不能并发执行,解决了脏读、不可重复读、幻读等问题,但隔离级别越来越高的同时,并发性会越来越低。
InnoDB 中的 RC 和 RR 隔离事务是基于多版本并发控制(MVCC)实现高性能事务。
「MVCC」 对普通的 Select 不加锁,如果读取的数据正在执行 Delete 或 Update 操作,这时读取操作不会等待排它锁的释放,而是直接利用 MVCC 读取该行的数据快照(数据快照是指在该行的之前版本的数据,而数据快照的版本是基于 undo 实现的,undo 是用来做事务回滚的,记录了回滚的不同版本的行记录)。MVCC 避免了对数据重复加锁的过程,大大提高了读操作的性能。
「锁的具体实现算法」
InnoDB 既实现了行锁,也实现了表锁。行锁是通过索引实现的,如果不通过索引条件检索数据,那么 InnoDB 将为表锁。
行锁的具体实现算法有三种:
1、「record lock」:专门对索引项加锁
2、「gap lock」:对索引项之间的间隙加锁
3、「next-key lock」:是前面两种的组合,对索引项及其之间的间隙加锁只在「可重复读或以上隔离级别」下的特定操作才会取得 gap lock 或 next-key lock,在 Select 、Update 和 Delete 时,除了基于唯一索引的查询之外,其他索引查询时都会获取 gap lock 或 next-key lock,锁住其扫描的范围。
慢查询优化
慢查询的原因
无索引、索引失效
- 在千万条数据表中一个索引也没有,任何非主键查询都会导致全表扫描。
- 即使有了索引,在某些场景下也要确定是否会导致索引失效。
锁等待
- InnoDB支持行锁和表锁,MyISAM只支持表锁
- InnoDB 存储引擎支持的行锁更适合高并发场景,行锁是基于索引加的锁,如果在更新操作时,条件索引失效,那么行锁也会升级为表锁,在批量更新操作时,行锁也很可能会升级为表锁。
- 基于表锁的数据库操作,会导致 SQL 阻塞等待,影响执行速度。
- 行锁相对表锁来说,虽然粒度更细,并发能力提升了,但也带来了新的问题:「死锁」
SQL语句不当
- 使用 SELECT *,SELECT COUNT(*)
- 在大表中使用 LIMIT M,N 分页
- 对非索引字段进行排序
慢查询常见优化方法
避免死锁
- 在 InnoDB 中,设置超时时间。当一个事务的等待时间超过阈值,就对这个事务进行回滚,另一个事务就可以继续执行了
- 用「分布式锁」代替数据库实现幂等性校验。
- 在允许幻读和不可重复读的情况下,尽量使用 RC 事务隔离级别,避免 gap lock 导致的死锁
- 更新表时,尽量使用主键更新
- 避免长事务,尽量将长事务拆分
SQL语句优化
通过 EXPLAIN 分析 SQL 执行计划图片图中每个字段说明

「id」:每个执行计划都有一个 id,如果是一个联合查询,这里还将有多个 id。
「select_type」:表示 SELECT 查询类型,常见的有 SIMPLE(普通查询,即没有联合查询、子查询)、PRIMARY(主查询)、UNION(UNION 中后面的查询)、SUBQUERY(子查询)等。
「table」:当前执行计划查询的表,如果给表起别名了,则显示别名信息。
「partitions」:访问的分区表信息。
「type」:表示从表中查询到行所执行的方式,查询方式是 SQL 优化中一个很重要的指标,结果值从好到差依次是:system > const > eq_ref > ref > range > index > ALL。
「system/const」:表中只有一行数据匹配,根据索引查询一次就能找到对应的数据。
「eq_ref」:使用唯一索引扫描,常见于多表连接中使用主键和唯一索引作为关联条件。
「ref」:非唯一索引扫描,还可见于唯一索引最左原则匹配扫描。
「range」:索引范围扫描,比如,<,>,between 等操作。
「index」:索引全表扫描,此时遍历整个索引树。
「ALL」:表示全表扫描,需要遍历全表来找到对应的行。
「possible_keys」:可能使用到的索引。
「key」:实际使用到的索引。
「key_len」:当前使用的索引的长度。
「ref」:关联 id 等信息。
「rows」:查找到记录所扫描的行数。
「filtered」:查找到所需记录占总扫描记录数的比例。
「Extra」:额外的信息。
优化分页查询
优化前:select * from goods order by id limit 90000,5;
优化后:select * from goods where id > (select id from goods order by id limit 99999,1) order by id limit 5;
优化 SELECT COUNT(*)
COUNT()函数在有条件的情况下,需要扫描全表进行统计,对大表进行 SELECT COUNT(*) 显然效率低下
使用近似值:某些业务场景并不需要返回一个精确的 COUNT 值,使用 EXPLAIN 对表进行估算,并不会真正去执行查询,而是返回一个估算的近似值。
使用中间统计表:这种方式在新增和删除时有一定的成本,但却可以大大提升 COUNT() 的性能。
优化 SELECT *
查询具体需要的列:如 select a,b from table where id=1,假设存在a和b的联合索引,那么 select * 会导致回表
InnoDB 存储引擎参数优化
「innodb_buffer_pool_size」
IBP 默认的内存大小是 128M。MySQL 推荐配置 IBP 的大小为服务器物理内存的 80%。
「innodb_buffer_pool_instances」
该参数项仅在将 innodb_buffer_pool_size 设置为 1GB 或更大时才会生效。
如果 innodb_buffer_pool_size 大小超过 1GB,innodb_buffer_pool_instances 值就默认为 8;否则,默认为 1。
建议指定 innodb_buffer_pool_instances 的大小,并保证每个缓冲池实例至少有 1GB 内存。
建议 innodb_buffer_pool_instances 的大小不超过 innodb_read_io_threads + innodb_write_io_threads 之和,建议实例和线程数量比例为 1:1。
「innodb_read_io_threads」 / 「innodb_write_io_threads」
根据业务场景,读大于写时,读线程数量可以大于写线程数量,否则,反之
读写线程数量值默认各为 4,但需要与 innodb_buffer_pool_instances 的大小协同优化
( innodb_read_io_threads + innodb_write_io_threads ) = innodb_buffe_pool_instances
「innodb_log_file_size」
InnoDB 中有一个 redo log 文件,InnoDB 用它来存储服务器处理的每个写请求的重做活动。
理论上 innodb_log_file_size 设置得越大,缓冲池中需要的检查点刷新活动就越少,节省磁盘 I/O。但并不是设置得越大越好呢,否则恢复时间就会变长。通常设置为 1GB
「innodb_log_buffer_size」
这个参数决定了 InnoDB 重做日志缓冲池的大小,默认值为 8MB。适当调大可以减少磁盘 I/O ,提高并发事务性能
「max_connections」
连接到 MySQL 的最大连接数,默认为151。结合业务场景适当调大该参数
「back_log」
TCP 连接请求排队等待栈,适当调大该参数,增加高并发时短时间内处理连接请求量
更多思考
以上就是优化SQL性能的几点思路,更多关于Sql实战的内容可以阅读以下文章:


