
MySQL优化!记一次关于对十亿行的足球数据表进行分区!转载
公司开发了一个网络应用程序,供体育专家做出决策和探索数据。该应用程序支持任何运动。全世界每天玩的数百场游戏中的每一场都有数千行。在短短几个月内,我们应用程序中的 Events 表就达到了 50 亿行!
通过了解足球专家如何查询数据,我们可以对数据库进行智能分区。这个新表的平均时间改进速度提高了 20 倍到 40 倍。所有查询的平均时间改进为 5 到 10 倍。
现在让我们深入研究这个场景,了解为什么在对数据库进行分区时不能忽略数据上下文。
1
我们的体育应用程序提供原始数据和汇总数据,尽管采用它的专业人士更喜欢后者。底层数据库包含来自多个提供商的数 TB 的复杂、非结构化、异构数据。因此,最大的挑战是设计一个可靠、快速且易于探索的数据库。
应用领域
在这个行业中,许多供应商为他们的客户提供最重要的足球比赛赛事的访问权。具体来说,它们为您提供与比赛期间发生的事情相关的数据,例如进球、助攻、黄牌、传球等等。包含这些数据的表是迄今为止我们必须使用的最大的表。
VPS 规格、技术和架构
我的团队一直在开发提供最关键数据探索功能的后端应用程序。我们采用在 JVM( Java 虚拟机)之上运行的Kotlin v1.6作为编程语言,Spring Boot 2.5.3作为框架,Hibernate 5.4.32.Final作为 ORM(对象关系映射)。我们选择这种技术堆栈的主要原因是速度是最关键的业务需求之一。因此,我们需要一种可以利用繁重的多线程处理的技术,而 Spring Boot 被证明是一种可靠的解决方案。
我们通过Dokku管理的Docker容器将后端部署在 16GB 8CPU VPS上。它最多可以使用 15GB 的 RAM。这是因为 1 GB 的 RAM 专用于基于Redis的缓存系统。我们添加它是为了提高性能并避免重复操作使后端过载。
2
数据库和表结构
至于数据库,我们决定选择MySQL 8。一个 8GB 和 2 个 CPU VPS 当前托管数据库服务器,最多支持 200 个并发连接。后端应用程序和数据库位于同一服务器场中,以避免网络延迟。我们设计数据库结构以避免重复并考虑到性能。我们决定采用关系数据库,因为我们希望有一个一致的结构来转换从提供程序接收到的数据。通过这种方式,我们将体育数据标准化,使其更易于探索并将其呈现给最终用户。
当我们开始对 Events 表执行繁重的查询时,真正的挑战出现了。但在深入研究之前,让我们看看事件表是什么样子的:
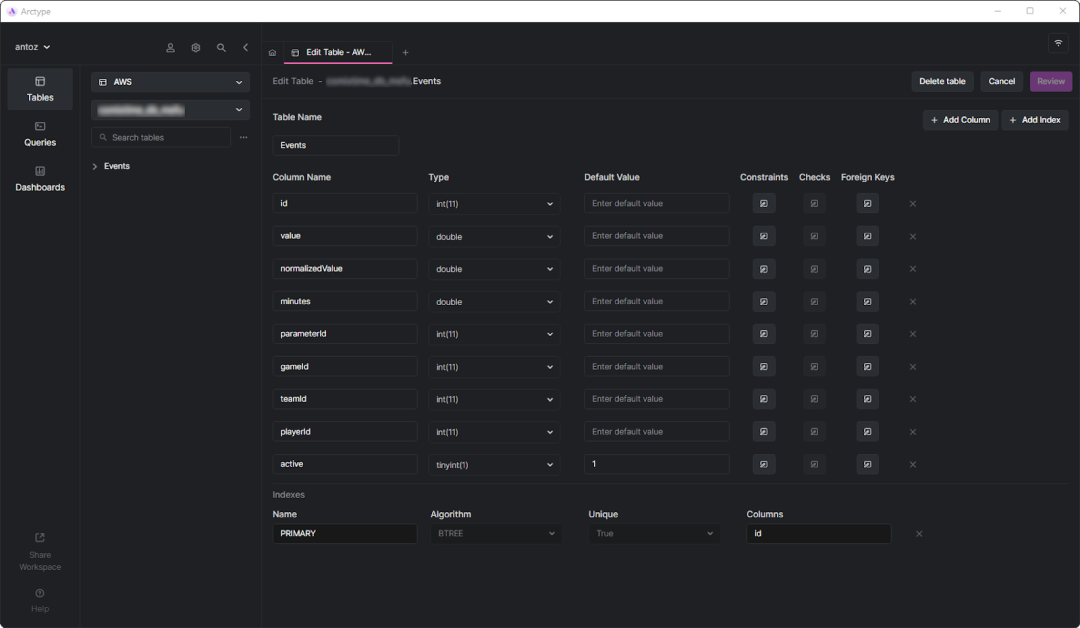
如您所见,它不涉及很多列,但请记住,出于保密原因,我不得不省略其中一些。但这里真正重要的是parameterId和gameId列。我们使用这两个外键来选择一种类型的参数(例如,进球、黄牌、传球、点球)和它发生的比赛。
3
事件表在短短几个月内就达到了十亿行。正如我们在这篇博文中已经深入介绍的那样,主要问题是我们需要使用慢速 IN 查询来执行聚合操作。这是因为比赛期间发生的事情并不那么重要。相反,体育专家希望分析汇总数据以发现趋势并根据它们做出决策。
此外,尽管他们通常会分析整个赛季或最近 5 或 10 场比赛,但用户通常希望从分析中排除某些特定比赛。这是因为他们不希望一场比赛打得特别差或特别好,从而使他们的结果两极分化。我们无法预先生成聚合数据,因为我们必须对所有可能的组合进行此操作,这是不可行的。因此,我们必须存储所有数据并即时汇总。
了解性能问题
现在,让我们深入探讨导致我们不得不面对的性能问题的核心方面。
百万行表很慢
如果您曾经处理过包含数亿行的表,您就会知道它们天生就很慢。您甚至无法想到在如此大的表上运行 JOIN。然而,您可以在合理的时间内执行 SELECT 查询。当这些查询涉及简单的 WHERE 条件时尤其如此。另一方面,当使用聚合函数或 IN 子句时,它们变得非常慢。在这些情况下,它们很容易占用 80 秒,这实在是太多了。
仅索引还不够
为了提高性能,我们决定定义一些索引。这是我们寻找性能问题解决方案的第一种方法。但是,不幸的是,这导致了另一个问题。索引需要时间和空间。这通常是微不足道的,但在处理如此大的表时并非如此。事实证明,根据最常见的查询定义复杂的索引需要几个小时和 GB 的空间。此外,索引很有帮助,但不是魔术。
基于数据上下文的数据库分区作为一种解决方案
由于我们无法使用自定义索引解决性能问题,我们决定尝试一种新方法。我们与其他专家交谈,在网上寻找解决方案,阅读基于类似场景的文章,最后决定对数据库进行分区是正确的做法。
为什么传统分区可能不是正确的方法
在对我们所有的最大表进行分区之前,我们在MySQL 官方文档和有趣的文章中都研究了这个主题。尽管我们都同意这是要走的路,但我们也意识到在不考虑我们特定的应用程序域的情况下应用分区是错误的。具体来说,我们了解在对数据库进行分区时找到合适的标准是多么重要。一些分区专家告诉我们,传统的方法是按行数进行分区。但我们想找到比这更智能、更高效的东西。
深入应用程序域以找到分区标准
通过分析应用程序领域和采访我们的用户,我们学到了重要的一课。体育专家倾向于分析同一比赛中比赛的汇总数据。例如,足球比赛可以是联赛、锦标赛或单场比赛,您可以在其中赢得奖杯。有成千上万种不同的比赛。欧洲最重要的联赛是冠军联赛、英超联赛、西甲联赛、意甲联赛、德甲联赛、荷甲联赛、西甲联赛和西甲联赛。
这意味着我们的用户很少考虑来自不同比赛的数据。此外,他们更喜欢逐季探索数据。换句话说,他们很少离开特定赛季的体育比赛所代表的背景。我们的数据库结构用一个名为 的表来表达这个概念SeasonCompetition,它的目标是将一场比赛与一个特定的赛季联系起来。因此,我们意识到一个好的方法是将较大的表划分为与特定SeasonCompetition实例相关的子表。
具体来说,我们为这些新表定义了以下名称格式:<tableName>_<seasonCompetitionId>.
因此,如果表中有 100 行SeasonCompetition,我们将不得不将大Events表拆分为较小的Events_1, Events_2, ...,Events_100表。根据我们的分析,这种方法在一般情况下会带来相当大的性能提升,尽管在极少数情况下会引入一些开销。
将标准与最常见的查询匹配
在编码和启动脚本以执行这个复杂且可能无法返回的操作之前,我们通过查看后端应用程序执行的最常见查询来验证我们的研究。但是这样做,我们发现绝大多数查询只涉及在 SeasonCompetition 中玩的游戏。这使我们确信我们是对的。所以我们用刚刚定义的方法对数据库中的所有大表进行分区。
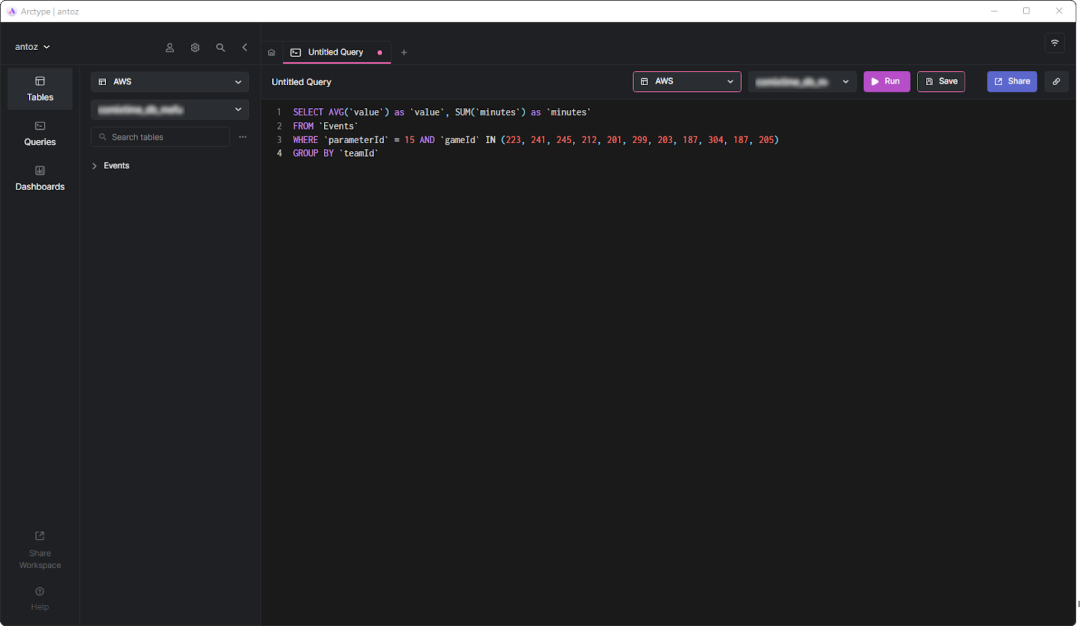
SQL
SELECT AVG('value') as 'value', SUM('minutes') as 'minutes'
FROM 'Events'
WHERE 'parameterId' = 15 AND 'gameId' IN(223,241,245,212,201,299,187,304,187,205)
GROUP BY 'teamId'
现在,让我们研究一下这个决定的利弊。
优点
-
在最多包含 50 万行的表上运行查询比在 50 亿行的表上运行性能要高得多,尤其是在聚合查询方面。
-
较小的表更易于管理和更新。添加列或索引在时间和空间方面甚至无法与以前相比。另外,每个SeasonCompetition都是不同的,需要不同的分析。因此,它可能需要特殊的列和索引,而前面提到的分区使我们能够轻松地处理这个问题。
-
提供者可能会修改一些数据。这迫使我们执行删除和更新查询,这些查询在如此小的表上要快得多。另外,他们总是只关注特定的一些游戏SeasonCompetition,所以我们现在只需要在一个表上操作。
缺点
-
在对这些子表进行查询之前,我们需要知道seasonCompetitionId与感兴趣的游戏相关联。这是因为seasonCompetitionId在表名中使用了该值。因此,我们的后端需要在运行查询之前通过查看分析中的游戏来检索此信息,这意味着开销很小。
-
当查询涉及一组涉及许多 的游戏时,SeasonCompetitions后端应用程序必须对每个子表运行查询。因此,在这些情况下,我们不能再在数据库级别聚合数据,而必须在应用程序级别进行。这在后端逻辑中引入了一些复杂性。同时,我们可以并行执行这些查询。此外,我们可以有效且并行地聚合检索到的数据。
-
管理一个包含数千个表的数据库并不容易,而且在客户端中进行探索可能具有挑战性。同样,在每个表中添加新列或更新现有列也很麻烦,需要自定义脚本。
基于数据上下文的分区对性能的影响
现在让我们看看在新的分区数据库中执行查询时实现的时间改进。
-
平均情况下的时间改进(查询只涉及一个SeasonCompetition):从 20 倍到 40 倍
-
一般情况下的时间改进(查询涉及一个或多个SeasonCompetitions):从 5 倍到 10 倍
4
对数据库进行分区无疑是提高性能的绝佳方式,尤其是在大型数据库上。但是,在不考虑您的特定应用程序域的情况下这样做可能是一个错误或导致低效的解决方案。相反,花时间通过采访专家和您的用户以及查看执行次数最多的查询来研究该领域对于构思高效的分区标准至关重要。本文向您展示了如何做到这一点,并通过真实案例研究展示了这种方法的结果。
文章来源:微信公众号


