
作业帮云原生容器在大规模任务场景下的落地和优化转载
导语
作业帮的云原生容器在cronjob规模较小的情况下运行是正常的,但是当cronjob的规模扩大后集群内节点变的不稳定,集群资源利用率也不高,本篇主要针对这两点来做优化;
正文
1.背景
在作业帮的云原生容器化改造进程中,各业务线原本部署在虚拟机上的定时任务逐渐迁移到 Kubernetes 集群 cronjob 上。起初,cronjob 规模较小,数量在 1000 以下,运行正常,随着 cronjob 的规模扩大到上万个后,问题就逐渐显现出来。
2.问题
当时主要面临两个问题:一是集群内节点稳定性问题;二是集群资源利用率不高。
第一个问题:集群内节点稳定性
由于业务上存在很多分钟级执行的定时任务,导致 pod 的创建和销毁非常频繁,单个节点平均每分钟有上百个容器创建和销毁,机器的稳定性问题频繁出现。
一个典型的问题是频繁创建 pod 导致节点上 cgroup 过多,特别是 memory cgroup 不能及时回收,读取 /sys/fs/cgroup/memory/memory.stat 变慢,由于 kubelet 会定期读取该文件来统计各个 cgroup namespace 的内存消耗,CPU 内核态逐渐上升,上升到一定程度时,部分 CPU 核心会长时间陷入内核态,导致明显的网络收发包延迟。
在节点perf record cat /sys/fs/cgroup/memory/memory.stat 和 perf report 会发现,CPU 主要消耗在 memcg_stat_show 上:
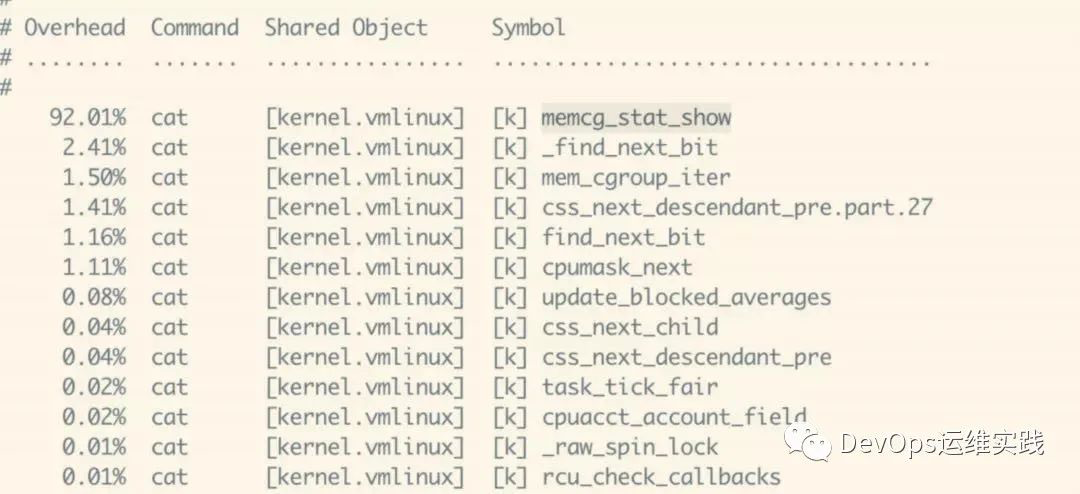
而 cgroup-v1 的 memcg_stat_show 函数会对每个 CPU 核心遍历多次 memcg tree,而在一个 memcg tress 的节点数量达到几十万级别时,其带来的耗时是灾难性的。
为什么 memory cgroup 没有随着容器的销毁而立即释放呢?主要是因为 memory cgroup 释放时会遍历所有缓存页,这可能很慢,内核会在这些内存需要用到时才回收,当所有内存页被清理后,相应的 memory cgroup 才会释放。整体来看,这个策略是通过延迟回收来分摊直接整体回收的耗时,一般情况下,一台机器上创建容器不会太多,通常几百到几千基本都没什么问题,但是在大规模定时任务场景下,一台机器每分钟都有上百个容器被创建和销毁,而节点并不存在内存压力,memory cgroup 没有被回收,一段时间后机器上的 memory cgroup 数量达到了几十万,读取一次 memory.stat 耗时达到了十几秒,CPU 内核态大幅上升,导致了明显的网络延迟。
除此之外,dockerd 负载过高、响应变慢、kubelet PLEG 超时导致节点 unready 等问题。
第二个问题:集群的节点资源利用率
由于我们使用的智能卡 CNI 网络模式,单个节点上的 pod 数量存在上限,节点有几乎一半的 pod 数量是为定时任务的 pod 保留的,而定时任务的 pod 运行时间普遍很短,资源使用率很低,这就导致了集群为定时任务预留的资源产生了较多闲置,不利于整体的机器资源使用率提升。
其他问题:调度速度、服务间隔离性
在某些时段,比如每天 0 点,会同时产生几千个 Job 需要运行。而原生调度器是 K8s 调度 pod 本身对集群资源分配,反应在调度流程上则是预选和打分阶段是顺序进行的,也就是串行。几千个 Job 调度完成需要几分钟,而大部分业务是要求 00:00:00 准时运行或者业务接受误差在 3s 内。
有些服务 pod 是计算或者 IO 密集型,这种服务会大量抢占节点 CPU 或者 IO,而 cgroup 的隔离并不彻底,所以会干扰其他正常在线服务运行。
3.在K8s集群中使用 serverless
所以,对 CRONJOB 型任务我们需要一个更彻底的隔离方式,更细粒度的节点,更快的调度模式。
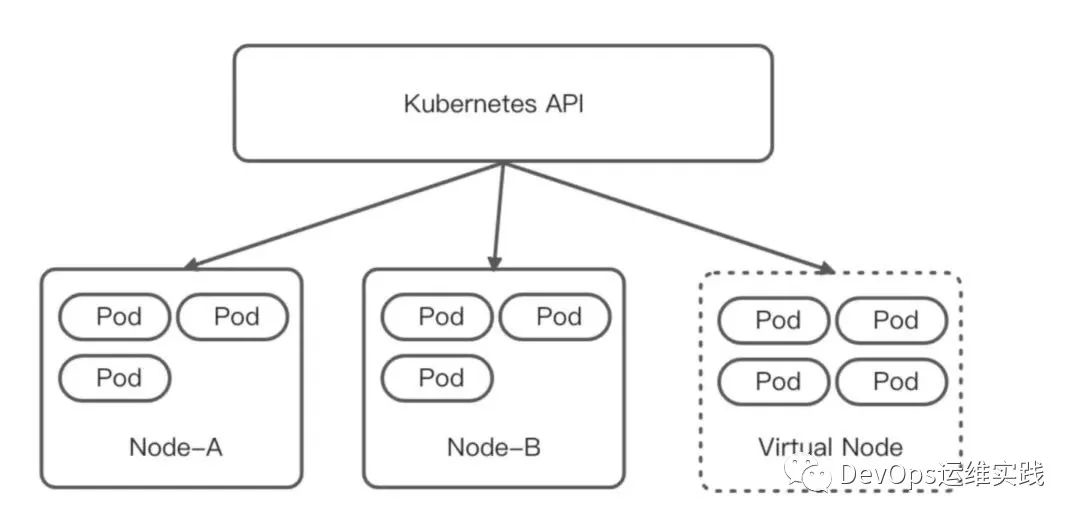
为了解决上述问题,我们考虑将定时任务 pod 和普通在线服务的 pod 隔离开,但是由于很多定时任务需要和集群内服务互通,最终确定了一种将定时任务 pod 在集群内隔离开来的解决办法 —— K8s serverless。我们引入了虚拟节点,来实现在现有 K8s 体系下使用 K8s serverless。部署在虚拟节点上的 pod 具备与部署在集群既有节点 pod 一致的安全隔离性、网络连通性,又具有无需预留资源,按量计费的特性。如图所示:
任务调度器
所有 cronjob 型 workload 都使用任务调度器,任务调度器批量并行调度任务 pod 到 Serverless 的节点,调度上非串行,实现完整并行,调度速度 ms 级,也支持 Serverless 节点故障时或者资源不足时调度回正常节点。
解决和正常节点上 pod 差异
在使用 K8s Serverless 前首先要解决 Serverless pod 和运行在正常节点上的 pod 差异,做到对业务研发无感。
1.日志采集统一
在日志采集方面,由于虚拟节点是云厂商维护的,无法运行 DaemonSet,而我们的日志采集组件是以 DaemonSet 形式运行的,这就需要对虚拟节点上的日志做单独的采集方案。云厂商将容器的标准输出收集到各自的日志服务里,各个云厂商日志服务的接口各不一样,所以我们自研了日志消费服务,通过插件的形式集成云厂商日志 client,消费各云厂商的日志和集群统一的日志组件采集的日志打平后放到统一的 Kafka 集群里以供后续消费。
2. 监控报警统一
在监控方面,我们对 Serverless 上的 pod 做了实时 CPU/ 内存 / 磁盘 / 网络流量等监控,做到了和普通节点上的 pod 一致,暴露 pod sanbox 的 export 接口,promethus 负责统一采集,迁移到 Serverless 时做到了业务完全无感。
提升启动性能
Serverless JOB 需要具备秒级的启动速度才能满足定时任务对启动速度的要求,比如业务要求 00:00:00 准时运行或者业务接受误差在 3s 内。
主要耗时在以下两个步骤:
- 底层 sanbox 创建或者运行环境初始化
- 业务镜像拉取
主要是做到同一个 workload 的 sanbox 能够被复用,这样主要耗时就在服务启动时长,除了首次耗时较长,后续基本在秒级启动。
4.总结
通过自定义 JOB 调度器、解决和正常节点上 pod 的差异、提升 Serverless pod的启动性能措施,做到了业务无感切换到 Serverless,有效利用 Serverless 免运维、强隔离、按量计费的特性,既实现了和普通业务 pod 隔离,使得集群不用再为定时任务预留机器资源,释放了集群内自有节点的上万个 pod,约占总量的 10%;同时避免节点上 pod 创建过于频繁引发的问题,业务对定时任务的稳定性也有了更好的体验。定时任务迁移到 Serverless,释放了整个集群约 10% 的机器,定时任务的资源成本降低了 70% 左右。

