
通过一条慢SQL分析,从架构的角度进行选型来解决问题转载
前言
闲鱼服务端在做数据库查询时,对每一条SQL都需要仔细优化,尽可能使延时更低,带给用户更好的体验。但是在生产中偶尔会有一些情况怎么优化都无法满足业务场景。本文通过对一条慢SQL的真实改造,介绍解决复杂查询的一种思路,以及如何使得一条平均RT接近2s的SQL,最终耗时下降30倍。
背景
先来看一条SQL
select id,userid,itemid,status,type,modifiedtime ···
from table1
where userid = 123
and status in (0,1,2)
and type in ('a','b','c')
order by status,modifiedtime desc limit 0,20
查询条件并不多,也不存在join操作,却在项目中引起了慢SQL。在大数据量和高QPS的情况下,这条SQL的平均查询RT已经接近2s,并且此查询还应用在很多关键性的用户场景下,已经到了无法容忍的程度,需要对其进行改造。
分析
索引
对于慢SQL,最先想到的就是查询没有走索引或索引失效导致的全表扫描。首先用explain对此SQL 进行分析。对于此表,已经建立了index(userid,status,type,modifiedtime)组合索引。
MySQL的索引采用的是B+树,需要符合最左前缀匹配,分析SQL可以看出,由于存在多条in条件,虽然userid和status走了索引,但是status的范围查找导致之后的索引失效。通过Using index condition也可以看出走了索引条件下推,只使用了部分索引,而Using filesort可以看出使用了文件排序,而没有使用索引排序,查询速度自然很慢。想从索引的角度是无法解决这条慢SQL的。

分库分表
阿里巴巴开发规约中提过,单表行数超过500万行或者单表容量超过2GB,推荐进行分库分表。通常单表数据量如果过大,数据库性能也会下降。对于亿级数据量的表,单表将不足以支撑业务,需要采用分库分表的方式来提升性能,此处也已经对userid取模进行了水平拆分,并不是问题所在。
结论:对于MySQL已经没有可以优化的地方,只能从架构上的角度进行思考优化方案。
选型
搜索引擎
对于复杂的数据查询,很容易想到通过搜索引擎进行查找。搜索引擎的数据分析即使面对多种复杂条件,也能达到毫秒级别的召回,稳定,可靠,快速,且门槛低,成本低。最常见的例如Elasticsearch。
和数据库里的B+树所建立的组合索引不同,搜索引擎的倒排索引,可以快速查找符合单个条件的文档ID,最后通过取交集的方式过滤出符合条件的结果,查询速度上可以得到满足。
虽然搜索引擎可以容纳大量的数据,也可以快速的召回,但是在构建索引的速度上确不尽人意,对于短时间大量的数据写入,想要能在秒级实时存入并构建索引并召回搜索引擎是无法保证的,可能在分钟级别的延迟后才能查询到结果。无法满足当前场景。
OLAP(AnalyticDB MySQL)
传统的关系型数据库如MySQL,一般称为联机事务处理(OLTP,On-line Transaction Processing)。联机分析处理(OLAP,On-line Analytical Processing)又称为数据仓库。OLAP专门为海量数据提供高速查询能力,通常采用列式存储,在读取数据时,可以只读取指定的列进行过滤筛选,从而减少I/O,同时由于减少了读取的数据总量,从而使缓存中可以容纳更多的数据行数,可以对海量的数据进行更快的计算。
云原生数据仓库AnalyticDB MySQL(简称ADB)是云端托管的PB级高并发实时数据仓库,专注于服务OLAP领域。采用关系模型进行数据存储,可以使用SQL进行自由灵活的计算分析,无需预先建模。利用云端的无缝伸缩能力,在处理百亿条甚至更多量级的数据时真正实现毫秒级计算。支持高吞吐的数据实时增删改、低延时的实时分析和复杂ETL,兼容上下游生态工具,可用于构建企业级报表系统、数据仓库和数据服务引擎。
本业务场景上存在大数据量计算和快速查询场景,ADB在写入性能,计算性能都能满足要求。且ADB能直接兼容MySQL数据库语法,降低代码的改造和使用成本。
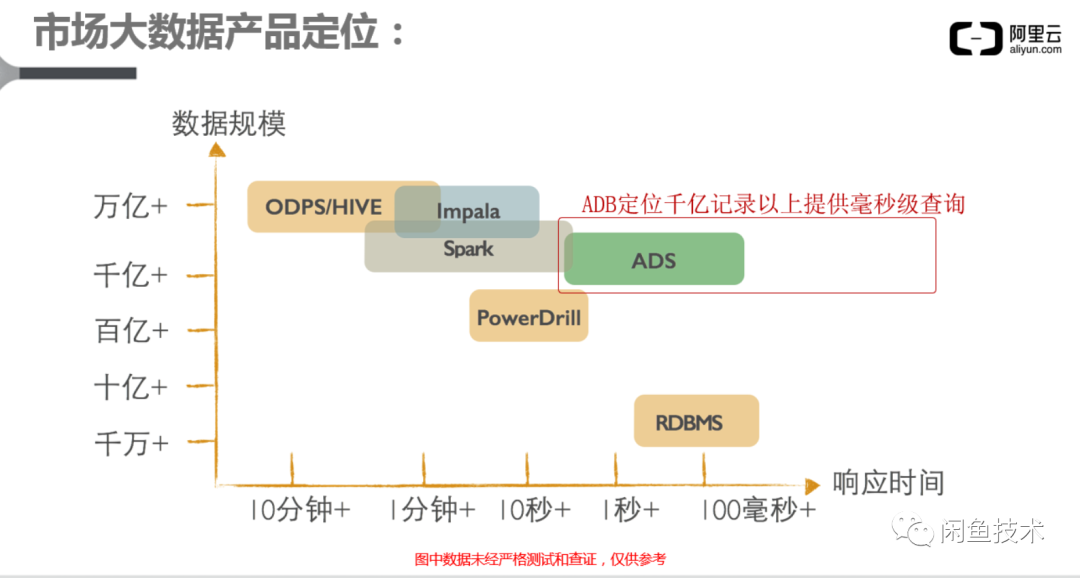
结论:对于当前SQL,通过将查询数据源改为ADB,替代直接读取MySQL,可以有效提高查询速度同时减少MySQL的读压力。
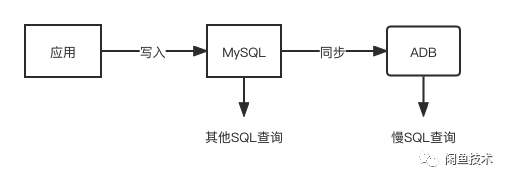
数据同步
选型好之后就是考虑如何将MySQL的数据同步进ADB,并保持数据库一致性,这里主要考虑增量数据如何同步。这里提供如下三种思路。
双写
想保持数据库一致,可以在写入MySQL之后,再写入ADB中。
优点:实现简单,延时低。
缺点:修改的地方多,不符合开闭原则。增加系统复杂度,如果后期有代码只更新了MySQL而忘记添加写入ADB的逻辑,则会导致数据库不一致。同步写入增加耗时,同时,如果更新ADB出错时,也很难进行异常处理。
DTS
阿里云数据传输(Data Tran**ission)DTS的数据同步功能旨在帮助用户实现两个数据源之间的数据实时同步。数据同步功能可应用于异地多活、数据异地灾备、本地数据灾备、数据异地多活、跨境数据同步、查询与报表分流、云BI及实时数据仓库等多种业务场景。
通过数据同步功能,可以将MySQL中的数据同步至ADB中,其中MySQL可以是RDS MySQL、其他云厂商或线上IDC自建MySQL或者ECS自建MySQL。
优点:稳定,高效,基本是最合适的解决方案
缺点:由于项目原因,不支持使用DTS,故没有采用
监听binlog
通过监听MySQL的binlog,可以对数据变更做统一的处理。在此处,可以通过监听新增删改消息进行对ADB进行写入操作。
由于ADB全面兼容MySQL语法,所以新增和删除可以使用如下语法进行统一处理
insert into ··· on dumplicate key update ···
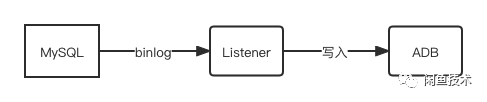
结论:增量数据的同步,最终采用在binlog处做统一收口,通过异步写入,不会影响用户体验,也能可以自定义重试方法,保证同步的可用性。其他项目如果可以,尽量考虑使用DTS。
实时同步处理完成后,可以再进行数据离线同步将存量数据导入,导入时忽略主键冲突的数据,导入完成后,新库就可以正常使用了。ADB支持多种数据导入工具,详情可以参考用户文档。
数据同步
慢SQL
ADB数据同步完成后,立刻开始进行切流了千分之一开始验证效果,平均执行耗时果然有所减小。
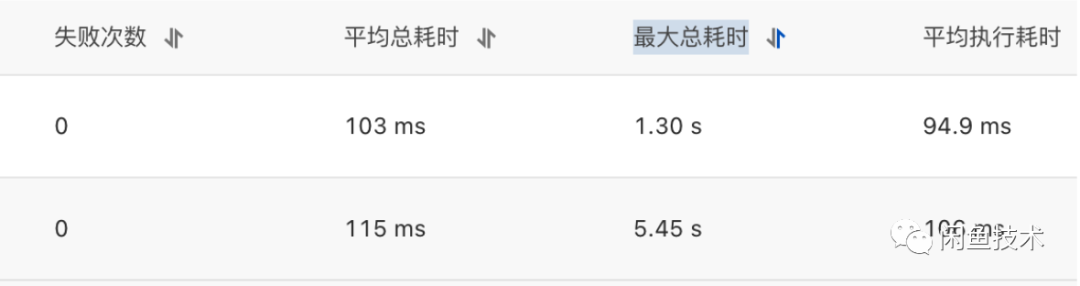
平均执行耗时仅有100ms,耗时分布统计如下,一秒以内的查询已经占到了98.31%
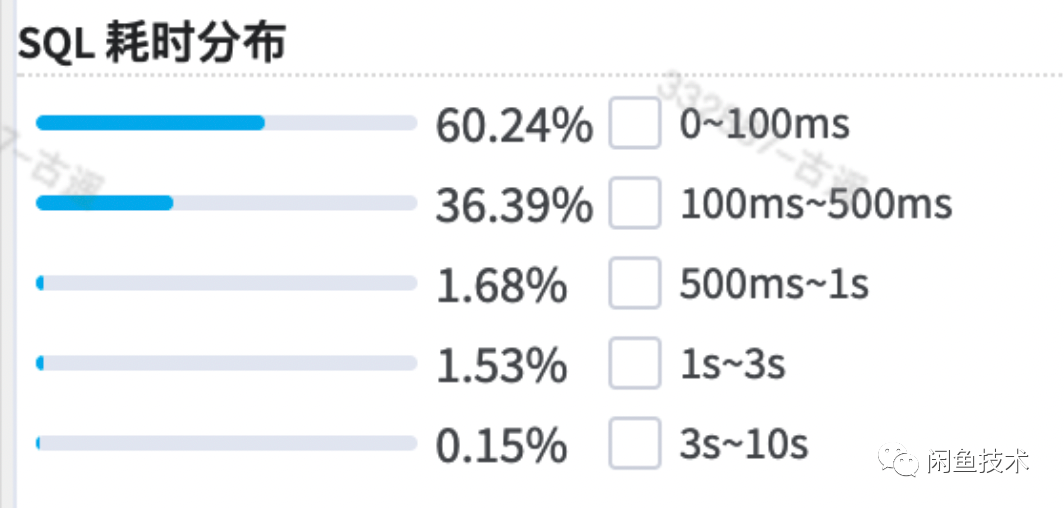
可是,整体来看,依然和预期有一些差距。考虑进一步优化。
建表优化
聚集列:在ADB中,数据存储支持按一列或多列进行排序(先按第一列排序,第一列相同情况下使用第二列排序),以保证该列中值相同或相近的数据保存在磁盘同一位置,这样的列称之为聚集列。当以聚集列为查询条件时,相比未设置聚集列的查询,SQL语句的访问I/O将减少数百倍。
前期建表时,已经设置userid做为聚集列。
执行计划
ADB自带的执行计划分析工具,可以进行SQL诊断,找了一条耗时长的SQL实例进行分析。
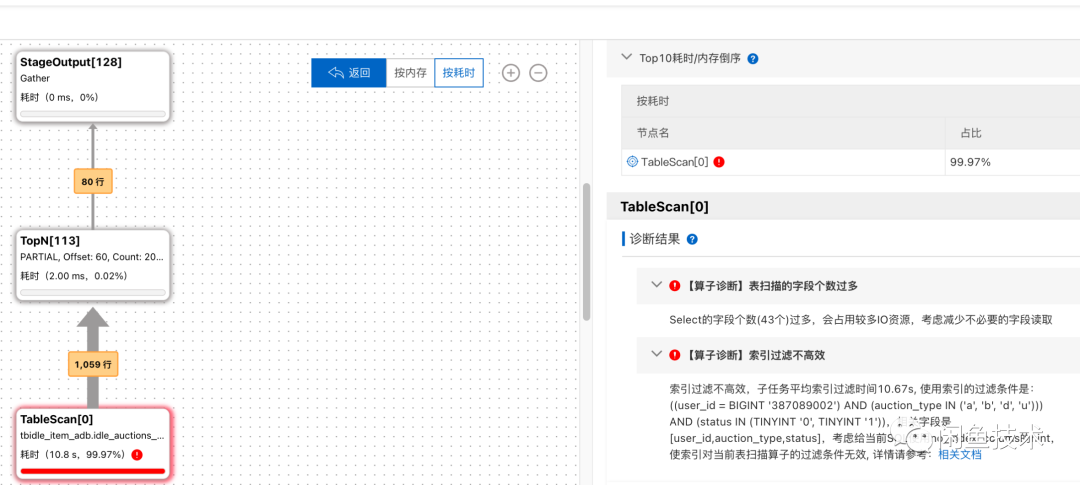
可以看出有两条优化项
第一条先不考虑,由于各个字段都需要使用,所以不能删除,所以从第二条索引过滤不高效进行分析
那么ADB的索引是什么样的呢?
经过了解,OLAP场景下需要支持任意维度查询,传统的OLTP单列或组合索引难以满足该需求。ADB中的玄武采用了自适应列级自动索引技术,针对字符串、数字、文本、JSON、向量等列类型都有自动配置的索引数据结构,并且可以做到列级索引任意维度组合检索、多路渐进流式归并,大幅提升了数据过滤性能。
目前索引类型主要有:倒排索引(字符型字段)、BKD-Tree索引(数值型字段)和Bitmap索引。同时索引的性能主要受数据分布特征影响,包括:cardinality(散列程度),范围查询的记录数/表记录数。
什么时候索引会不高效呢?

查看文档,我们知道了,ADB会默认对所有列建立索引(可以在建表是选择对某些列不建索引)。但是有些列由于其区分度不高,走了索引反而可能不高效。
要如何解决呢?
ADB提供了查询级别关闭特定字段的过滤条件下推能力。针对某个查询,使用Hint关闭某些字段的过滤条件下推。只对使用了Hint的查询生效,其他查询不受影响。
通过在SQL前直接拼接加上如下语句即可。
/*+ filter_not_pushdown_columns=[${database}.${tableName}:${col1Name}|${col2Name}] */结果
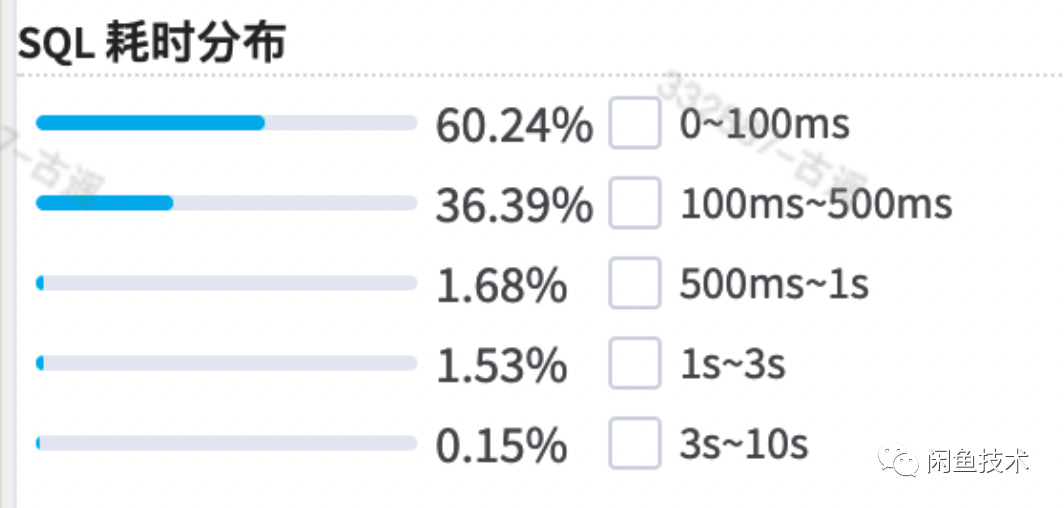
在去添加hint语法去除了type和statu索引后,果然有了显著提升
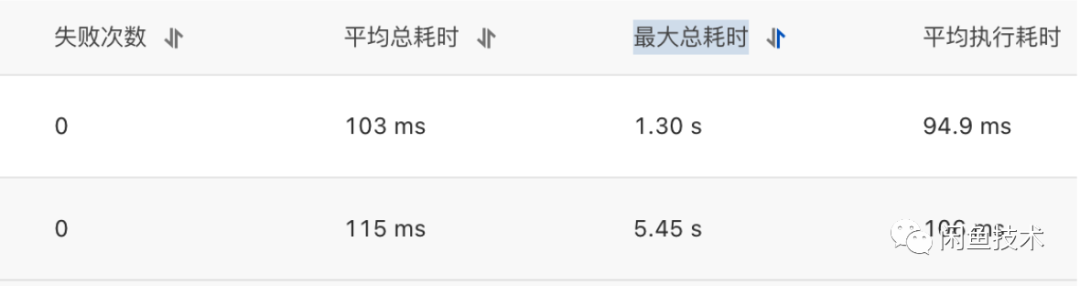
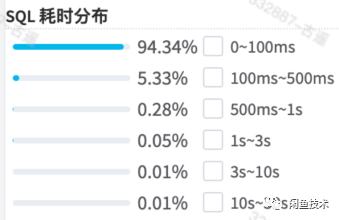
添加之后如下图所示,耗时在1s以内的已经达到了99.15%,且平均耗时也再次降低了一半。
参数优化
经过上述优化完后,依然有0.86%的SQL需要耗时1s以上,再次咨询ADB官方答疑,经过排查,帮忙调小了block_size相关参数,减少捞取过多数据进行扫描。
在ADB进行数据读取时,每次是按照block_size大小进行读入内存进行计算的,如果设置的过大,则可能会导致扫描的无用数据行数过多,从而耗费时间。
对于参数的设置,官方不建议自行修改,而是让其代为分析调试,以降低发生风险。
经过这次优化,效果还是很明显的,执行耗时在0.5秒以内的占了99.67%,而耗时1s以内的,已经占比高达99.94%,符合预期目标。
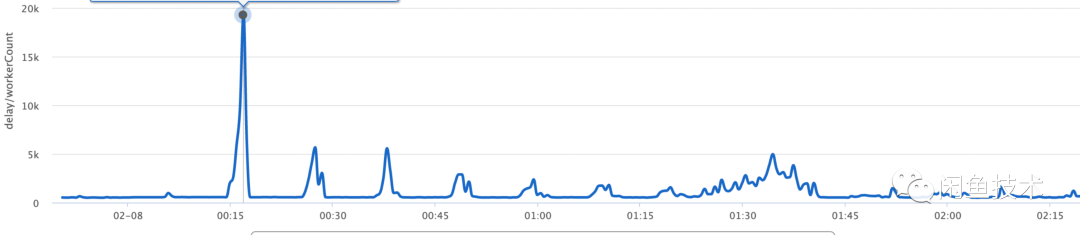
实时同步延时
在某些用户高峰期,实时同步的写入队列出现了大量延时,最多延时高达10分钟。
提高运行内存
查看gc情况,发现在高峰期,由于数据大量涌入,频繁出现gc,甚至很多fullGC。
fullGC引起STW,对于系统的延迟会造成很大影响。


在将内存扩大至2048M后,fullGC不再出现,youngGC的频率也下降了很多。不过延迟依然存在。
写入SQL优化
前期对于每条binlog变更消息单独进行写入处理,想要让其速度更快,使用批量操作的方式,将获取到的消息,拼接成一个list后由mybatis的foreach语法统一拼接成一条SQL后执行,减少和数据库间的交互,同时也将吞吐量提升一个量级。
</insert>
insert into table1 (id,itemid,userid,······)
values
<foreach collection="list" item="item" index="index" separator=",">
(#{item.id},#{item.itemId},#{item.userId},······
</foreach>
on DUPLICATE key update
item_id=values(item_id),······
</insert>
经过优化后,非高峰期延时在500ms以内,高峰期最高延迟不到20s,也符合预期。
总结
本文通过对一条慢SQL的分析,介绍了如何从架构的角度进行选型来解决问题。之后又从实际使用时的数据同步方式,以及使用过后的问题调优,给大家展示了一次改造的完整经过。在实际生产中遇到的问题往往是不同的,这里仅通过介绍使用AnalyticDB的方式进行解决,仅供参考。
事实上,由于MySQL的innodb引擎,同一条SQL即使非常复杂,第一次查询走数据文件,在第二次查询时会走buffer_pool,查询速度通常也会很快,但是对于用户的首次加载体验将会非常不友好。
虽然目前引入ADB只解决了一条慢SQL,但可以预见的,对于此表往后仍然会出现很多MySQL无法解决的复杂查询,通过ADB都可以解决。除了查询外也可以用于数据分析,在面对海量数据时也能有流畅的体验。ADB的功能非常强大,这里对其的使用和了解,也仅仅是冰山一角,对其有兴趣的读者可以去官网查看相关文档。
更多思考:
关于SQL慢查询的问题在我们日常中经常见到,大家可以通过阅读以下内容加深学习:
记一次慢SQL优化
千万级数据表选错索引导致的线上慢查询事故
感谢咸鱼技术古遥的内容分享


