

聊聊闲天:四月的西安阳光明媚,温度舒适,本应该是个全家出去春游的日子,奈何病毒再一次攻破了西安的严防死守,让大家本就悬着的心又紧绷起来,为了安全还是在家猫着吧,另一方面项目组内4月12号开始要开启一波996,意味着又要过一段加班狗的日子,估计顾不上写点东西了,避免四月留下空档,还是在家润色一篇技术贴。
最近一年多在一家toB业务的公司,主营疑难杂症的解决、性能优化,和过往待过的公司相比,开发除了编码之外还需要兼任一部分dba、一部分运维,实话讲有点累,有时遇到一些奇怪问题一度让人很暴躁
“为什么没个专业的dba呢?”
“啥时候能有个专业的运维呢?”
“这一天天弄啥呢,打杂的一样”
躁归躁,发泄完了还得接着干啊,经过一年多的摸爬滚打也算是对常见问题有一些中规中矩的解决办法,冷静下来想想还是有些许收获,待我娓娓道来。
排名第一 数据库问题
这是发生频率最高的,目前团队的toB业务,融合了OLTP和OLAP两种模式,然而底层只有RDS在负隅顽抗,经常会因为慢查导致数据库cpu 100%,也许你会说OLAP用RDS本身就不合适,但是没办法,试图去说服客户接受大数据那一套复杂玩意实属不易,毕竟系统是部署在客户私有化机房的,不是你想加就能加的,再者说团队之前没有这方面的使用经验。
主要从五个方面优化数据库问题:
-
升级数据库配置,能用钱解决最好,见效快;
-
优化数据库参数,最大限度利用硬件,比如我之前提到的innodb_buffer_pool_size的调整,参考终于做了一把MySQL调参boy,效果非常显著;
-
加索引,利用索引将查询的效率提上去,这块可以借用云厂商的数据库诊断工具,为你推荐合适的索引,最后结合自己的经验进行适当的改造,索引加多了本身也会成为数据库的负担,简单体验下某云的诊断功能
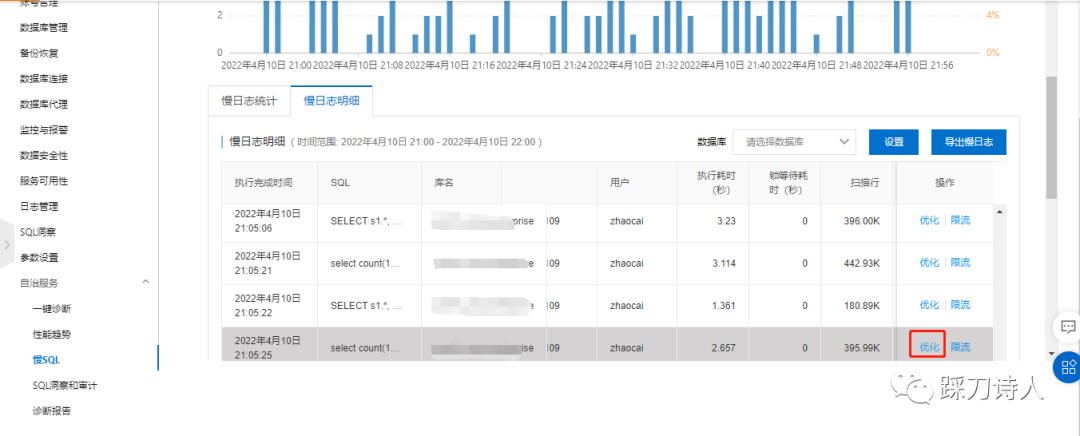
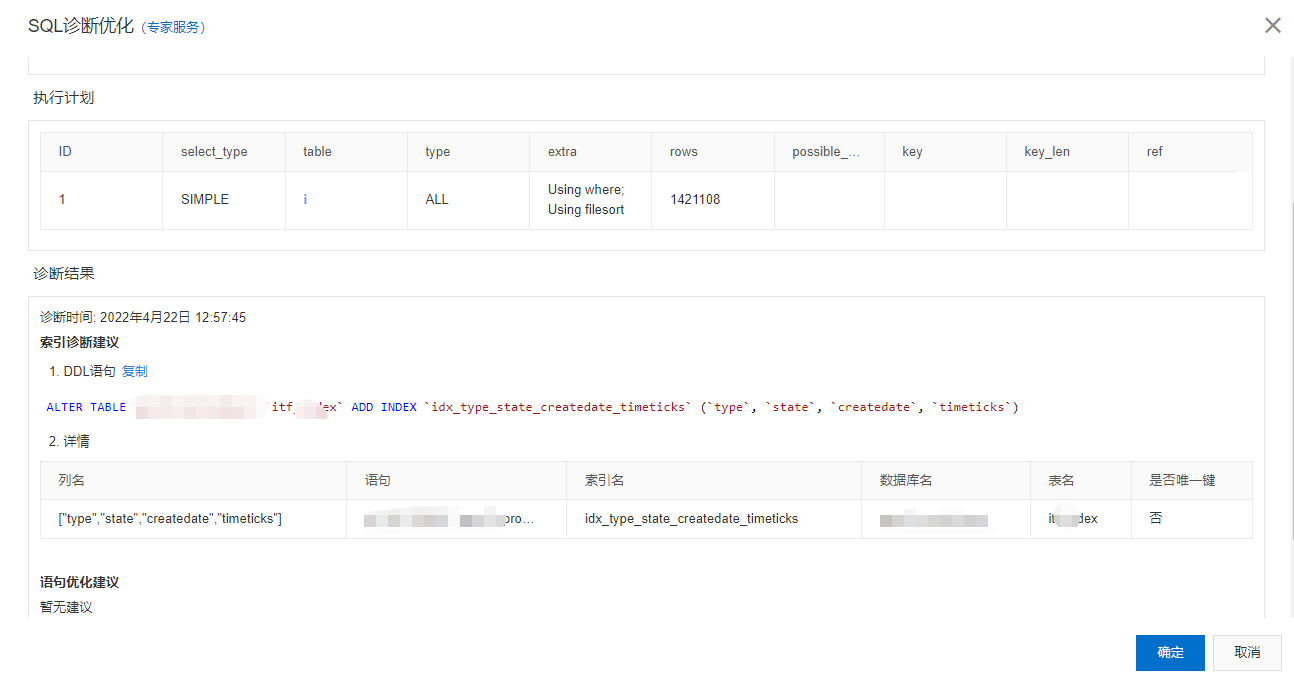
-
优化SQL, 复杂SQL拆分、去除不必要的语句等,比如下面这个sql
select distinct A.* from A union select distinct B.* from B
union本身在做结果合并的时候就会去重,为什么还要对结果集分别做distinct,徒增RDS的负担。
-
在架构上做一些优化,按照2/8原则来讲,80%的请求都是读操作,可以通过增加读库的方式来提升读的吞吐量,也就是常说的读写分离,做了读写分离以后,报表查询只会导致读库cpu 100%,读库一般可以挂多个,可以缓解原来RDS单库的压力,如何接入读写分离也是个需要重点考虑的点:
1.代码实现,常见方式是配置读写数据源,代码中指定读还是写操作,由框架层做切换;
2.通过数据库代理,比如MyCAT、ShardingSphere、云厂商的读写分离服务等,该方案的好处是对代码无侵入,开发无感知,只需要更换数据库链接即可。
交代下我们的背景,系统运行多年,框架上并不支持读写分离,需要新开发,而且要驱动业务开发对代码进行改造,标识哪些走写库,哪些走读库,再加上充分的测试,战线会比较长,似乎选择数据库代理方案更合适,但是代理类软件有一个绕不过的问题就是协议兼容性,比如我用了一个MySQL数据库的私有函数,代理不认识就会解析报错,不能等着代理软件去兼容吧,推动开发改成通用的就更费劲了,可能连方案都要重做了,考虑再三,还是回到了方案一,分阶段处理,先处理查询耗时特别严重的,每个迭代处理几个,小步快跑。
做方案就是这样,提出目标,设想方案,推翻自己,借鉴历史,取得真经。
排名第二 cpu跑满,fullgc频繁
-
cpu被某个大任务占满,导致其他服务受到牵连,目前有两种处理方式
1.代码上优化:大任务拆分为小任务,小任务之间增加休眠期,比如每100条sleep 1秒,让cpu做到雨露均沾;
2.限制pod的资源占用,limit cpu 等,降低pod相互影响,一次业务应用被一个基础服务影响,一看监控该基础服务几乎跑满宿主机的cpu

-
fullgc频繁导致长时间STW,前端大量超时,看下某客户环境猖狂的gc log
2021-11-01T01:41:28.604+0000: 1460.617: [Full GC (Allocation Failure) 2021-11-01T01:41:28.604+0000: 1460.617: [Tenured: 2097151K->2097151K(2097152K), 2.3259098 secs] 3040895K->2417455K(3040896K), [Metaspace: 122544K->122544K(1163264K)], 2.3260359 secs] [Times: user=2.32 sys=0.01, real=2.32 secs] 2021-11-01T01:41:31.429+0000: 1463.442: [Full GC (Allocation Failure) 2021-11-01T01:41:31.429+0000: 1463.442: [Tenured: 2097151K->2097151K(2097152K), 3.0093385 secs] 3040246K->2392920K(3040896K), [Metaspace: 122575K->122575K(1163264K)], 3.0094839 secs] [Times: user=3.02 sys=0.02, real=3.01 secs] 2021-11-01T01:41:34.861+0000: 1466.874: [Full GC (Allocation Failure) 2021-11-01T01:41:34.861+0000: 1466.874: [Tenured: 2097151K->2097151K(2097152K), 2.4219892 secs] 3040364K->2397366K(3040896K), [Metaspace: 122590K->122590K(1163264K)], 2.4221382 secs] [Times: user=2.42 sys=0.00, real=2.42 secs]
每次持续时间2.5s左右,每次的开始几乎紧跟着上一次的结束,jvm基本干不了别的,全用来处理gc了,再看看arthas dashboard的监控,cpu几乎全让vm thread给占了
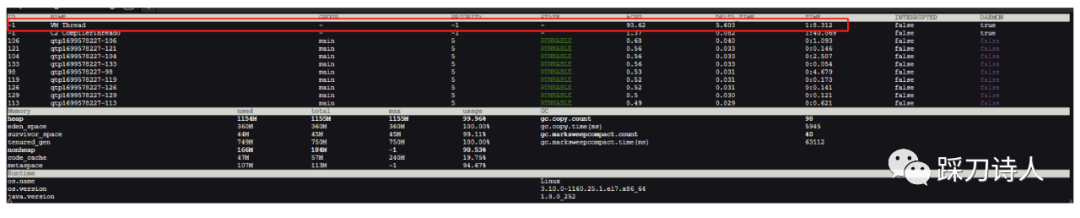
优化思路是设置合理的jvm内存,降低fullgc频率,具体设置方式如下:
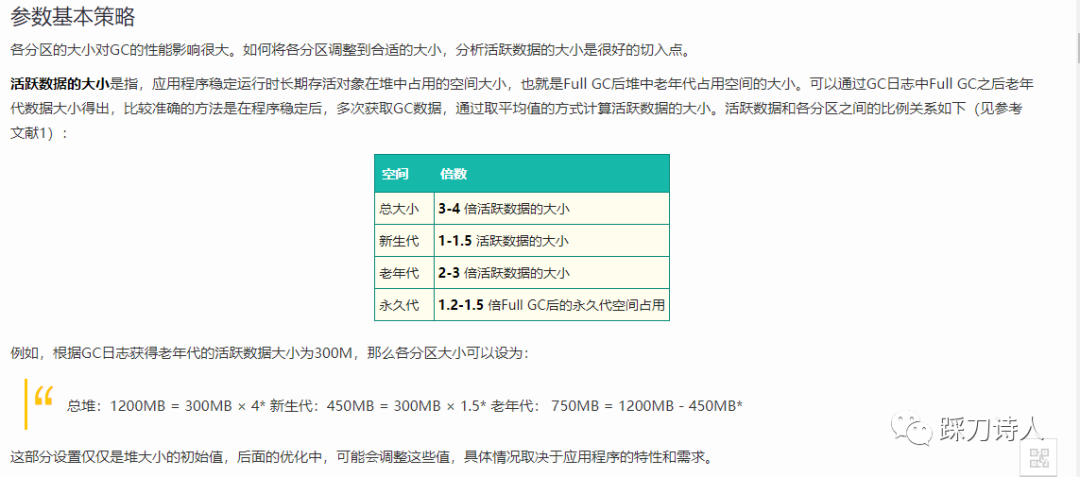
图片内容来源于https://tech.meituan.com/2017/12/29/jvm-optimize.html
我在之前的一篇文章中做了一点分析,有兴趣的可以移步记一次k8s pod频繁重启的优化之旅。
排名第三 外部依赖故障、超时带来的连锁反应
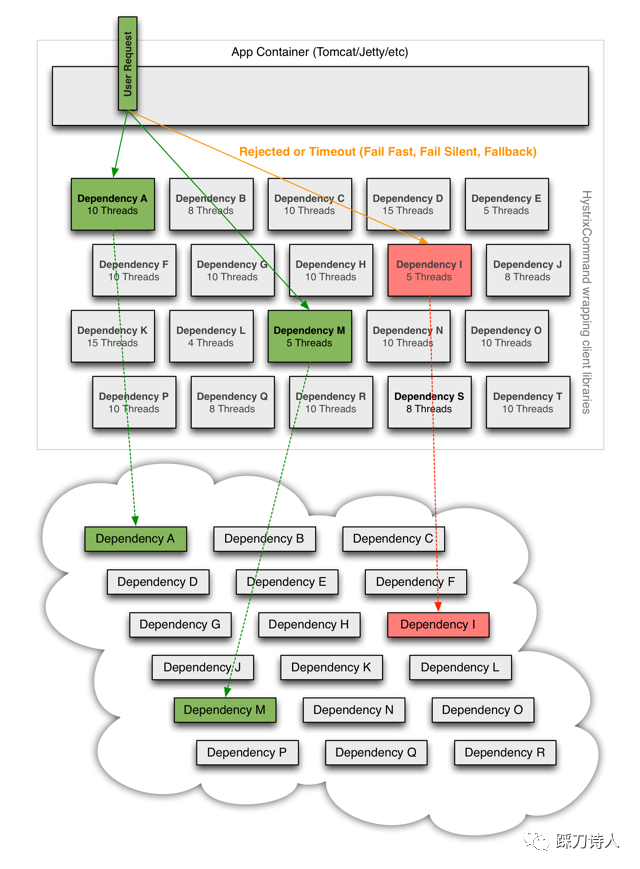
客户为了打通内部信息化流程,会要求我们和其他系统做集成,比如待办同步到OA,业务数据同步到数据中台等,交互方式也是多种多样,http、webservice、直接写库等,因为这块相对于业务来讲比较独立,所以和外部的交互这块是外包出去的,负责人界限模糊,人员流动大等导致了“屎山堆积“,第一版的代码可能还会按照规范来写,到了第N版的时候就是怎么方便怎么来了,本应该异步的做了同步,本应该配置超时的就是不配置,正常的时候比谁都正常,出事的时候牵一发动全身,怎么办呢,这种就只能指望重构了,异步化、检查超时等是否缺失,不能异步化的引入熔断降级等策略,贴一张比较经典的图脑补一下。
排名第四 内网丢包
这个确实之前没有遇到过,也许没留意过(想到前领导说过一句话,有些问题你没发现说明能力不够),一个简单的请求,耗时居然十几秒,内部只有查询数据库的操作,太不应该了,机器负载很低,数据库负载可以忽略不计,抱着碰运气的心态,我ping数据库,居然有丢包,丢包率最高有8%,怀疑是不是走外网了,跟客户一反馈,客户说这都是内网有线连接的机器,万分之一的丢包都不正常,他们立马排查。

排名第五 受WAF影响
WAF是什么,看下阿里云官网的介绍:
Web应用防火墙(Web Application Firewall,简称 WAF)为您的网站或App业务提供一站式安全防护。WAF可以有效识别Web业务流量的恶意特征,在对流量进行清洗和过滤后,将正常、安全的流量返回给服务器,避免网站服务器被恶意入侵导致服务器性能异常等问题,保障网站的业务安全和数据安全。
主要功能
-
提供Web应用攻击防护。
-
缓解恶意CC攻击,过滤恶意的Bot流量,保障服务器性能正常。
-
提供业务风控方案,解决业务接口被恶意滥刷等业务安全风险。
-
提供网站一键HTTPS和HTTP回源,降低源站负载压力。
-
支持对HTTP和HTTPS流量进行精准的访问控制。
-
支持超长时长的全量日志实时存储、分析和自定义报表服务,支持日志线上同步第三方平台,助力满足等保合规要求。
看下接了WAF以后请求链路发生了什么变化,最直观的就是用户到真实服务器之间多了一层WAF,如下图所示:
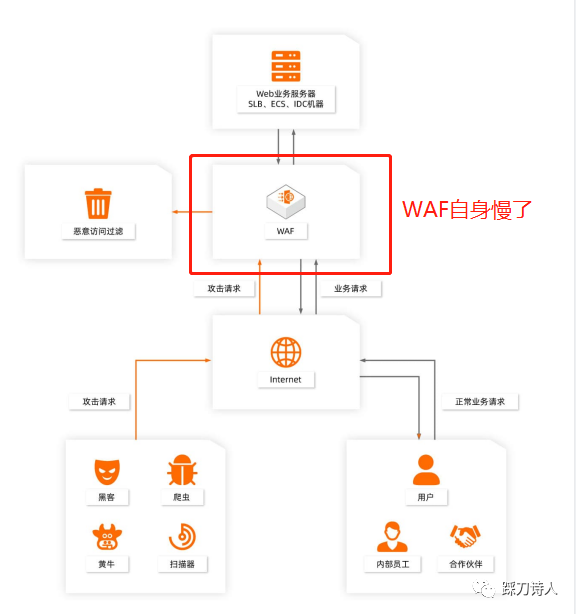
引入新事物的同时势必会带来新问题,通过WAF解决了安全问题,同时就会带来一些性能损耗。
假设WAF慢了,用户到源站的访问时间势必会变长,而用户一定会投诉是源站出了问题,WAF于ta们而言是透明的,作为源站负责人的我们怎么甩锅呢?
1.ping
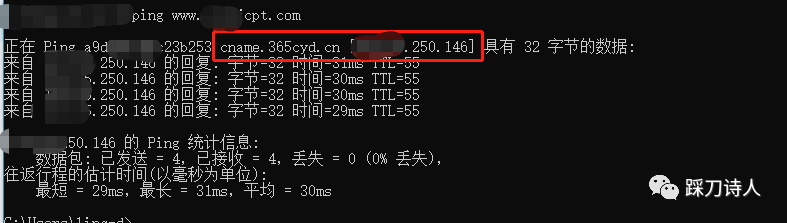
最开始是想用ping测试一下延迟的,但是发现显示的ip和运维提供的ip不一致,第一反应是不是网站被黑了,跟客户说了我们的疑惑后得知,应信息部门的要求,所有外网域名必须接入某政务云防御平台(WAF),所以现在域名解析的ip是WAF的ip,这样请求就会先进入到WAF进行防护,防护完成以后回源到真实的服务器,可以将WAF简单理解为反向代理的角色。
2.绕过WAF测试响应速度
既然请求链路上多了一个节点,那我们想办法将这个节点摘除以后再测试,两者对比就可以评估出这个节点带来的性能损耗,具体怎么摘除呢,其实很简单,本地修改hosts文件将域名直接指向源站ip即可,最终测试发现,WAF在高峰期带来的性能损耗有数秒。
将这些证据发给客户以后,客户“已读未回。”
一个小时以后,客户拉了个群,里面有WAF的开发,至此,甩锅成功。

结语
本想着上周末就完成,写的过程中发现有些东西自己不熟,又顺带学习了一下,好在拖了一周终于结束了,希望能让来到的同学不虚此行,最后送上一张自己拍的趣图,名为“打工人的卑微。”




