
Kube-OVN:容器网络性能的自我救赎原创
4年前
732427
Kube-OVN优化之初
怎么想到要做性能优化?
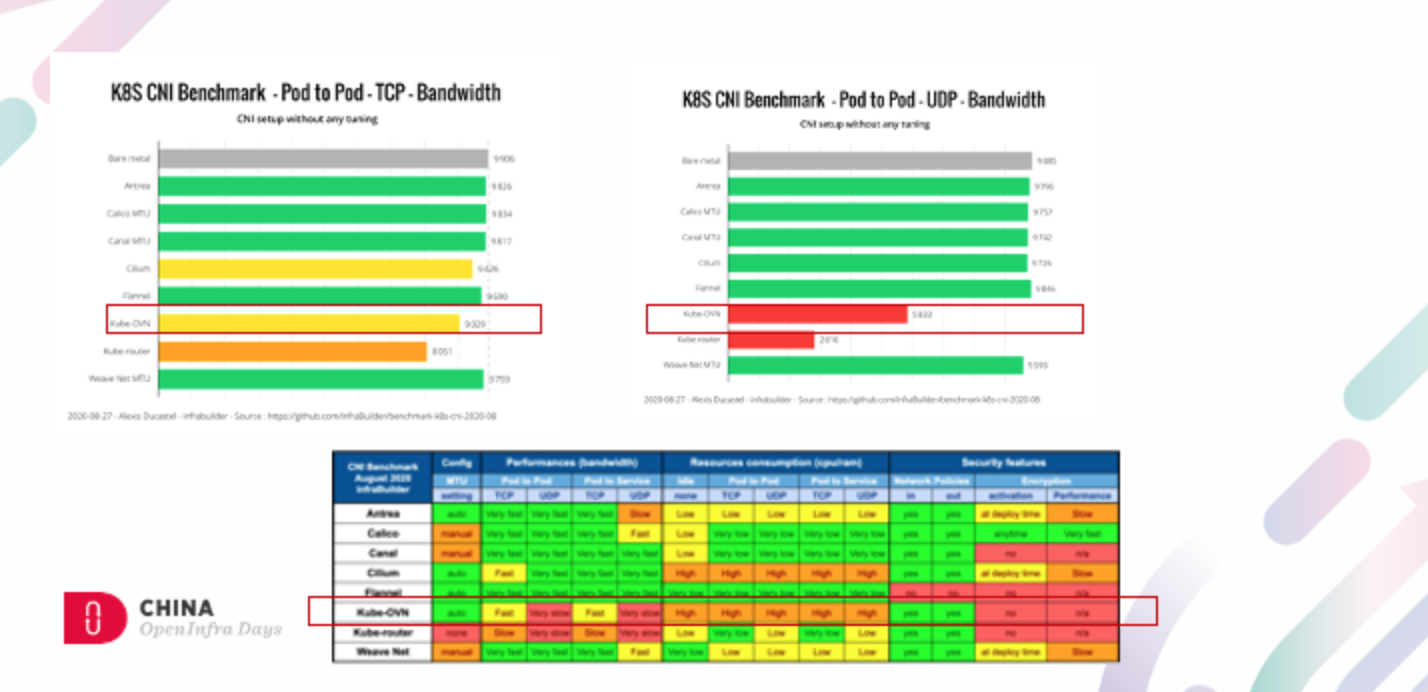
容器网络性能的自我救赎
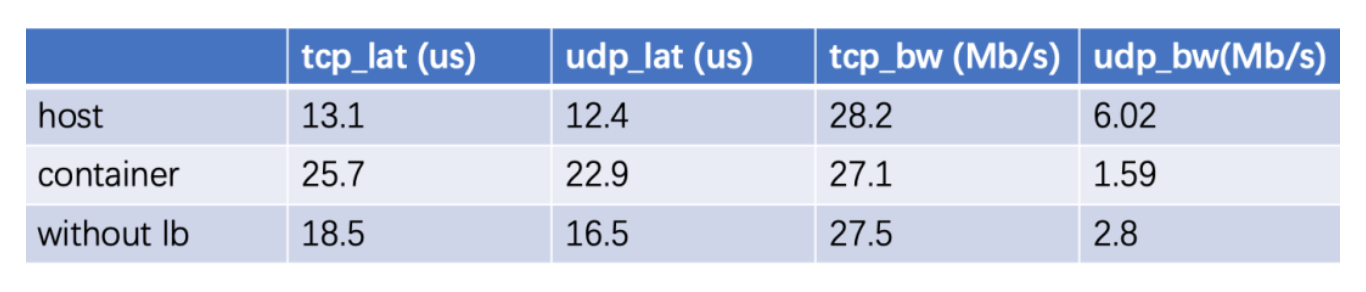
测试方法和测试基准

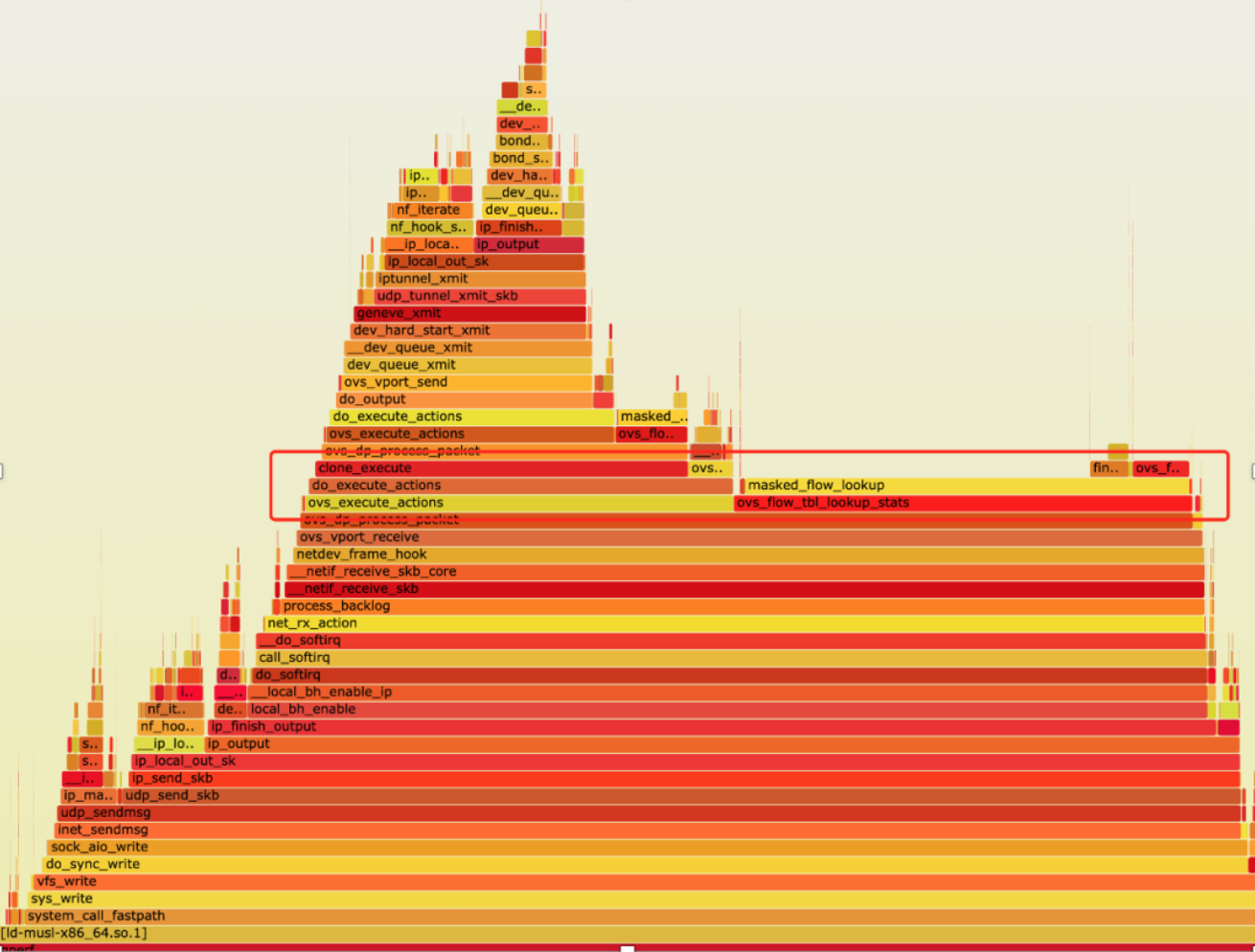
第一轮profile
第一轮优化
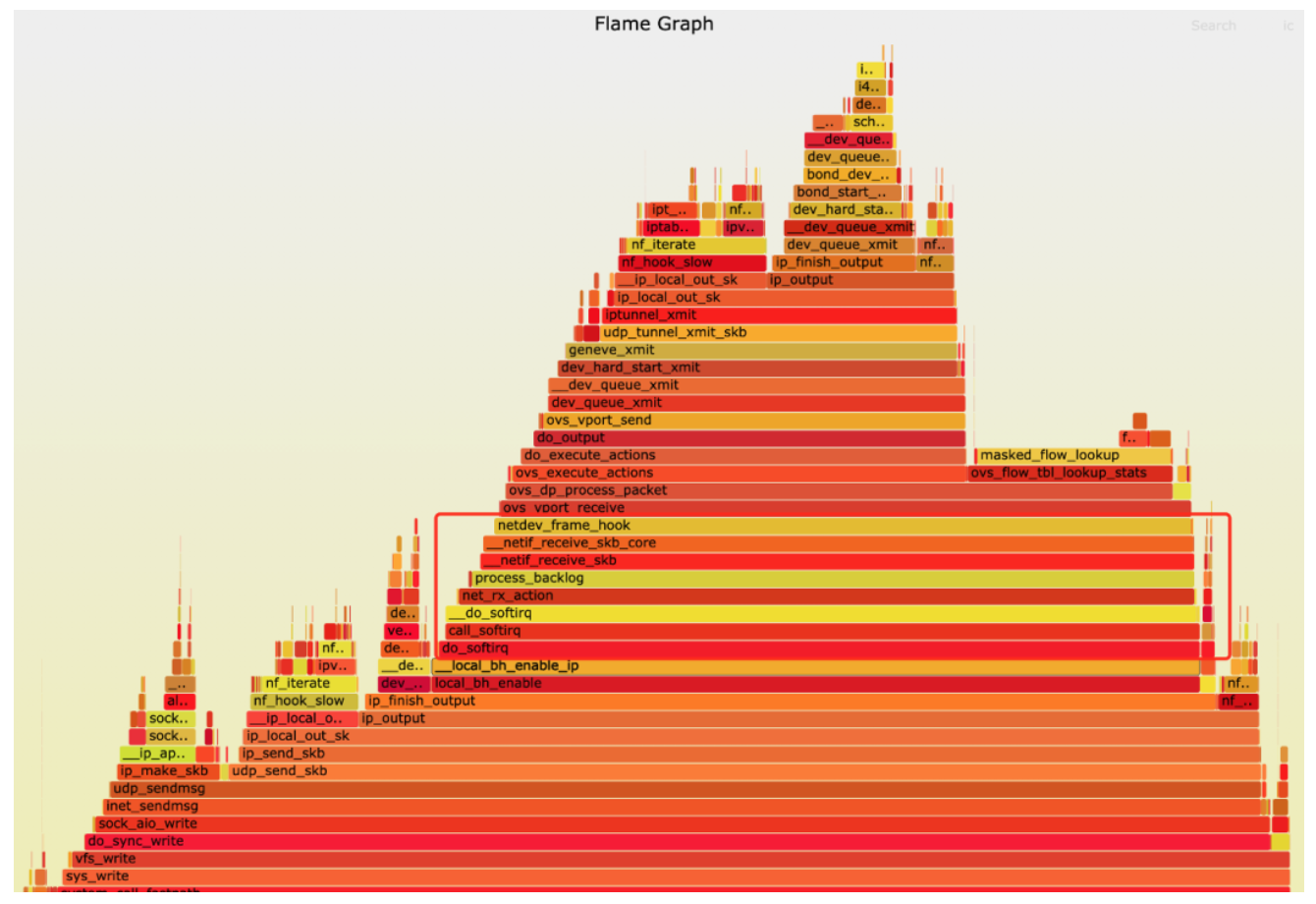
第二轮profile
第二轮优化
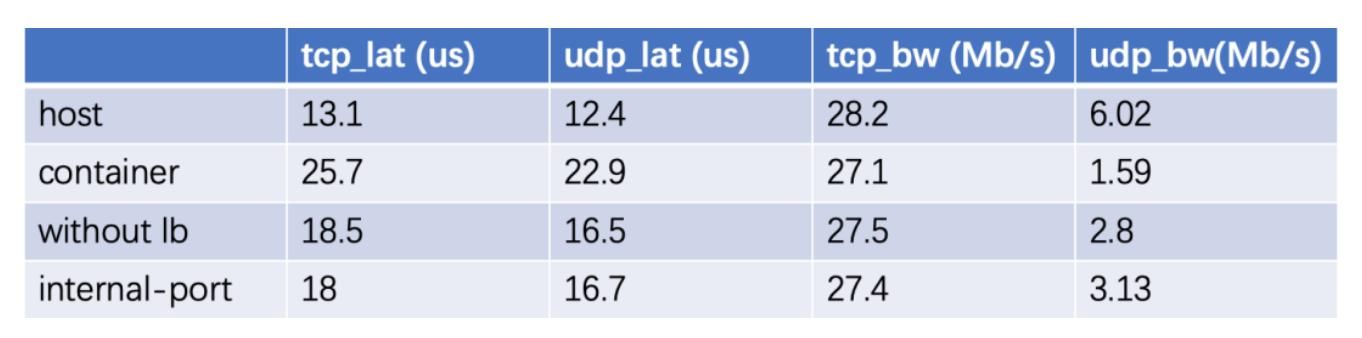
第三轮profile
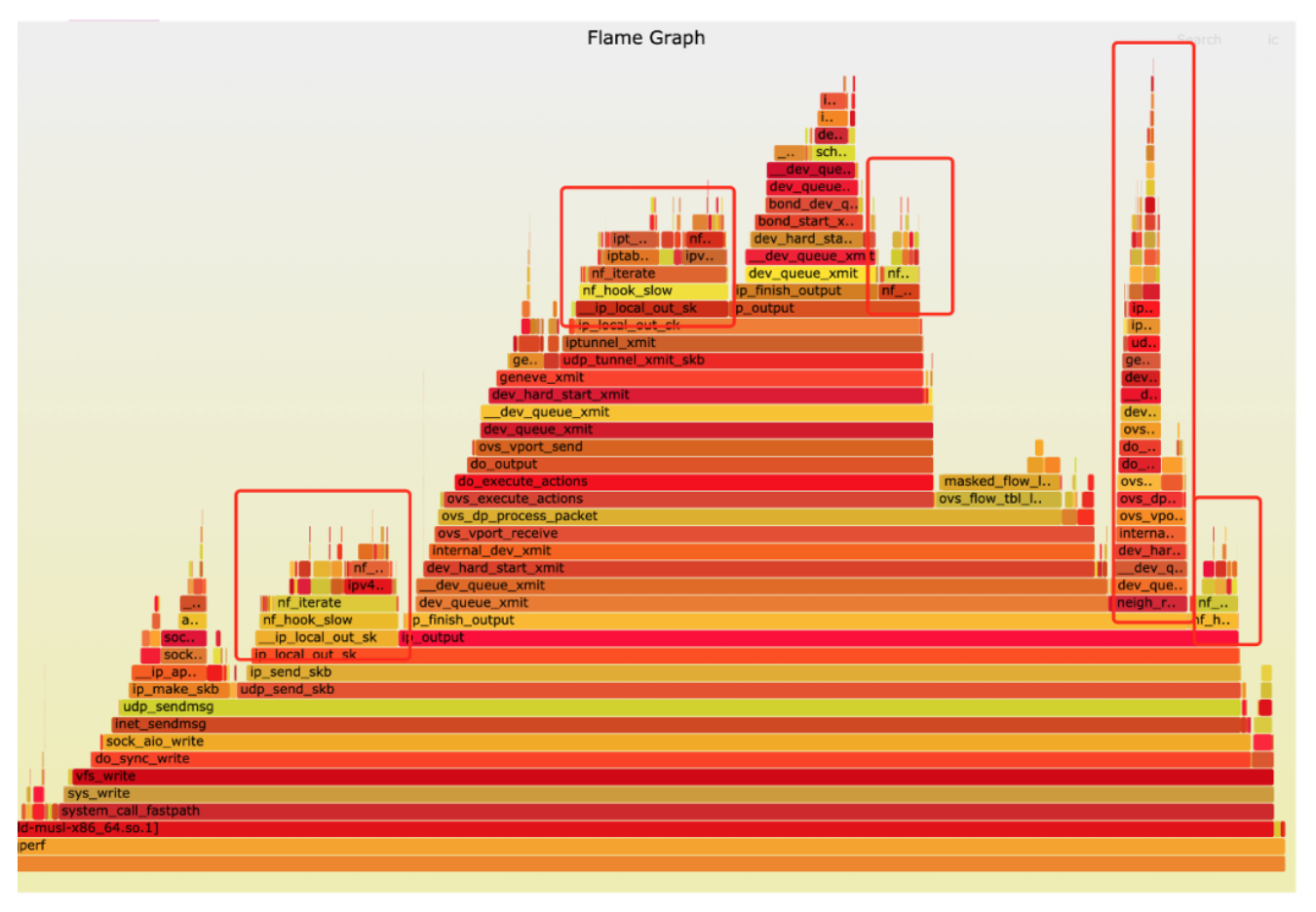
第三轮优化
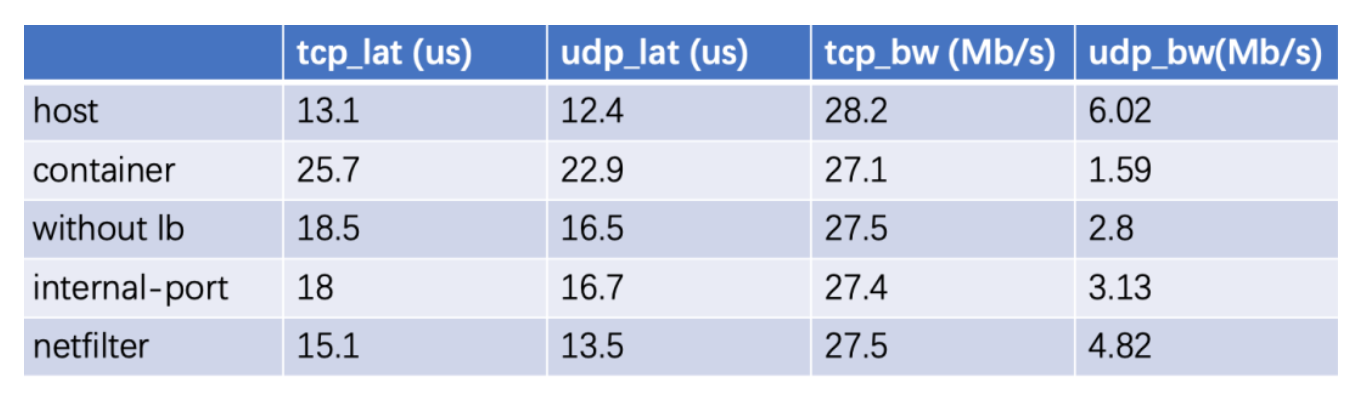
第四轮profile
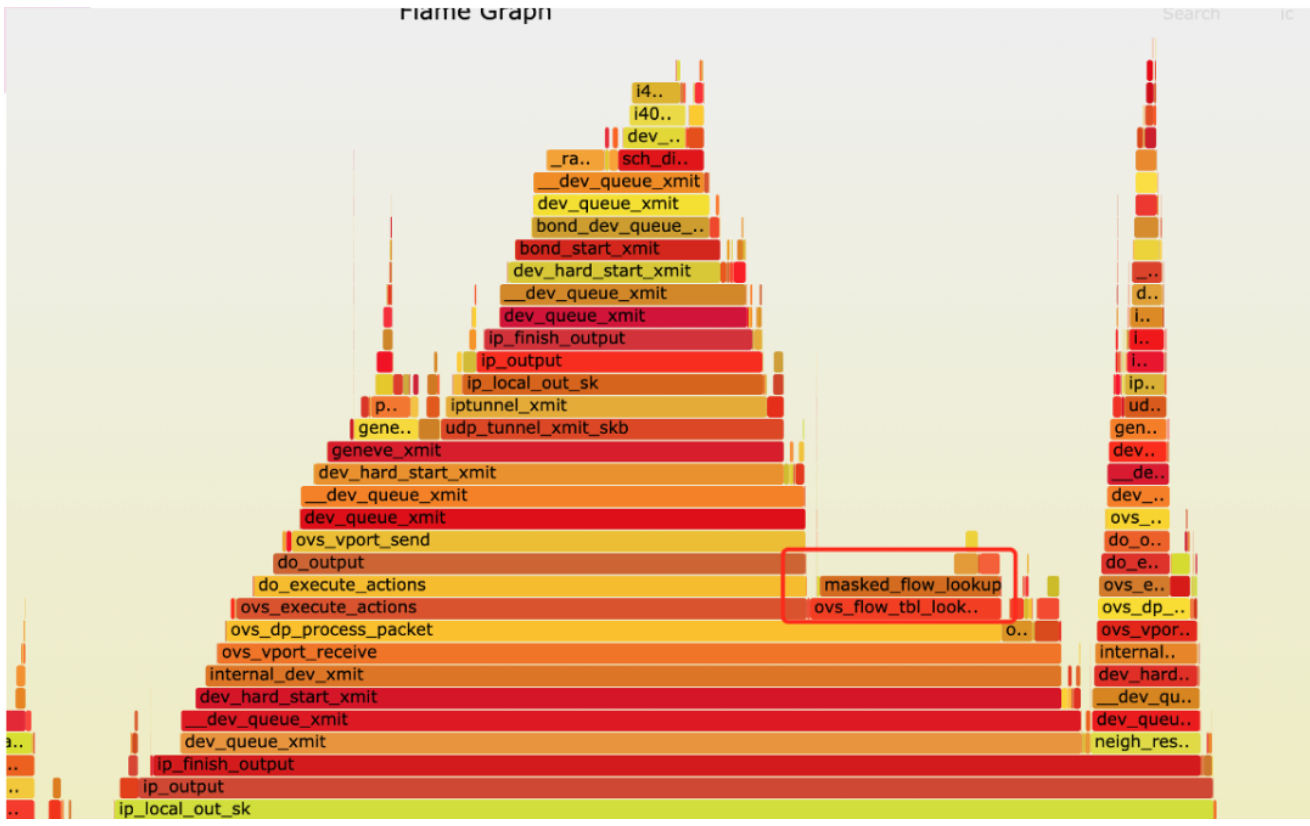
第四轮优化
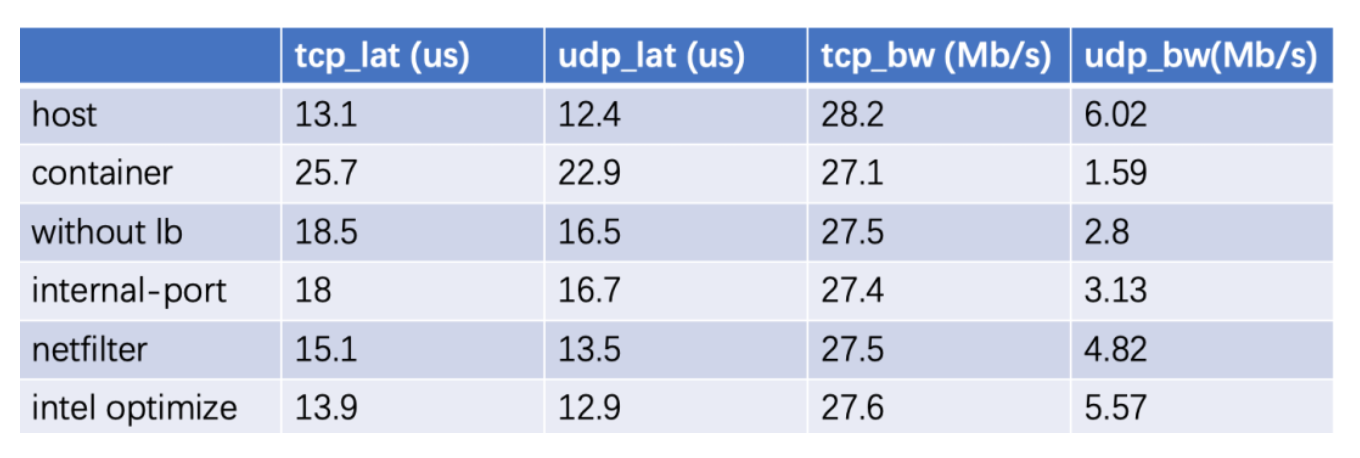
整体优化总结
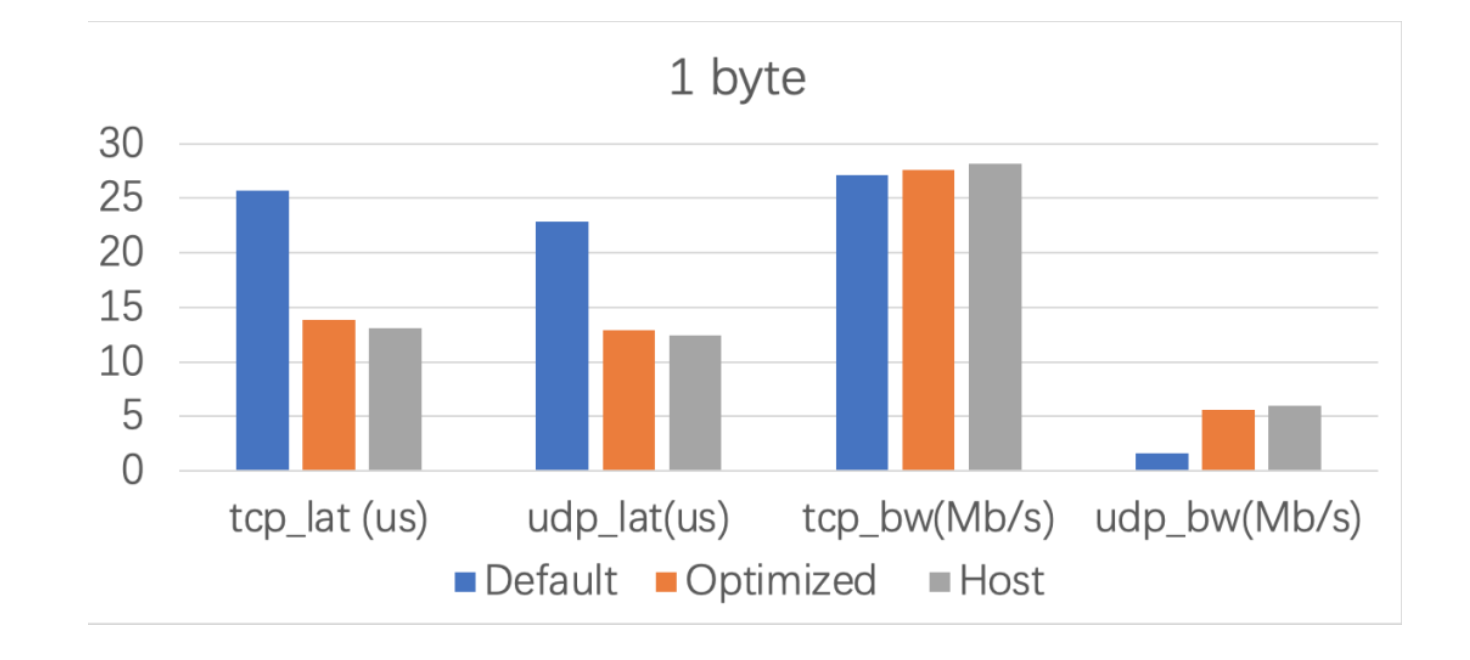
和其他网络插件对比
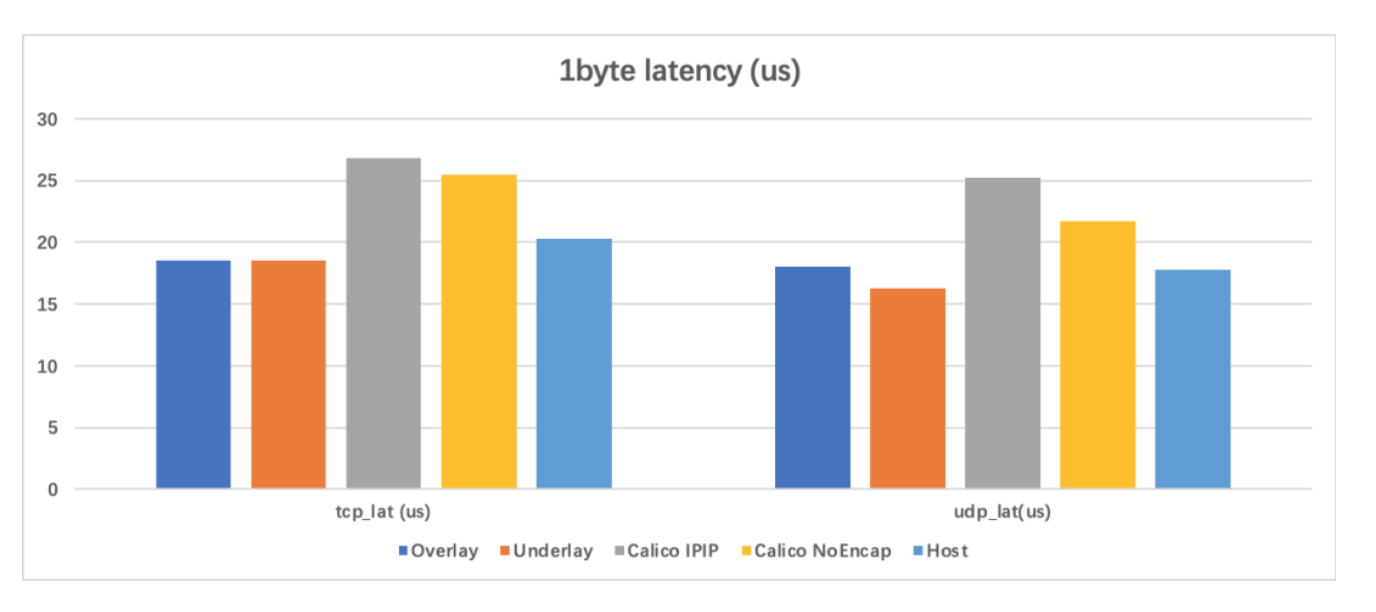
1k数据包吞吐量优化


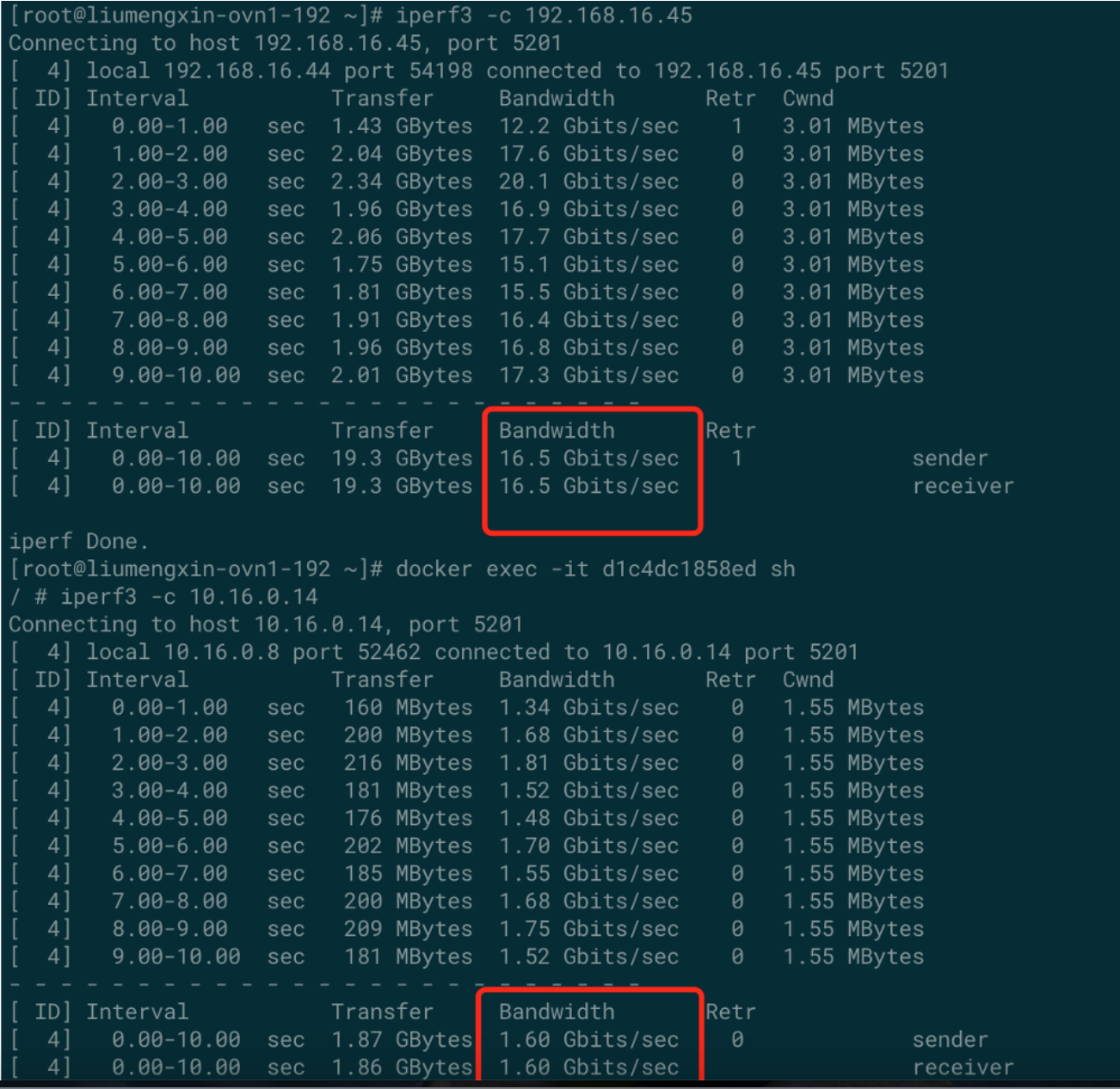
虚拟机吞吐量优化
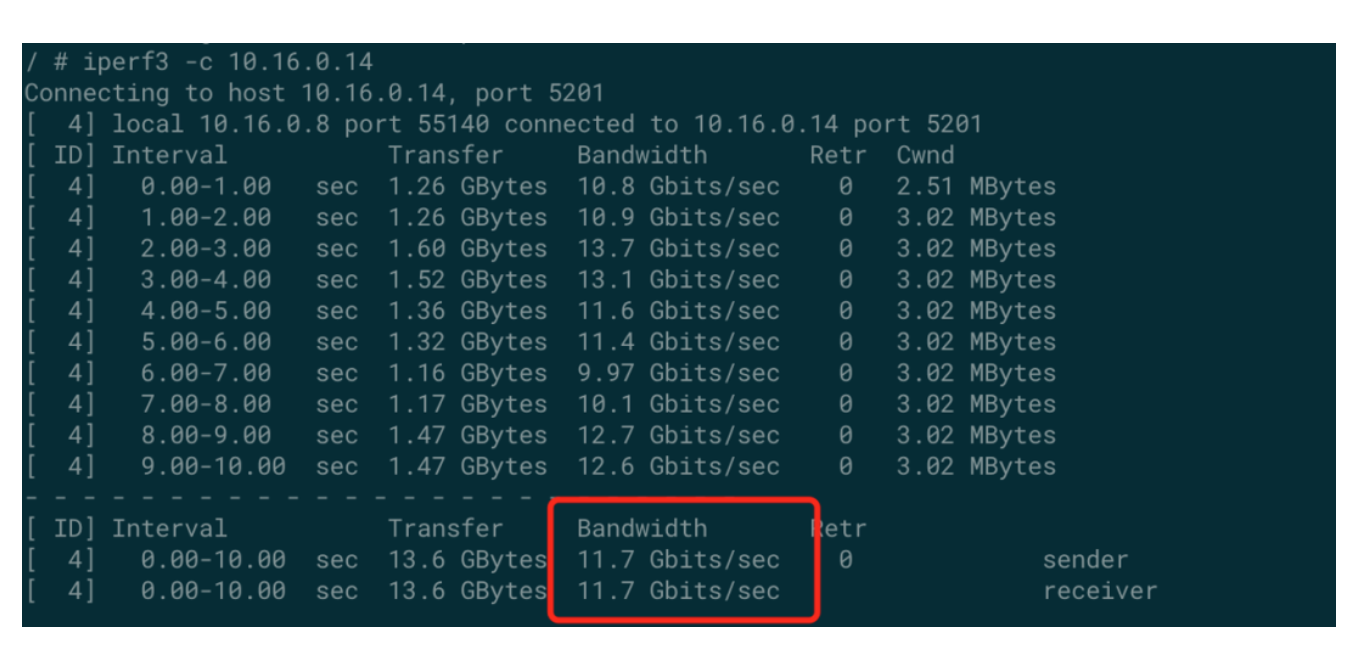
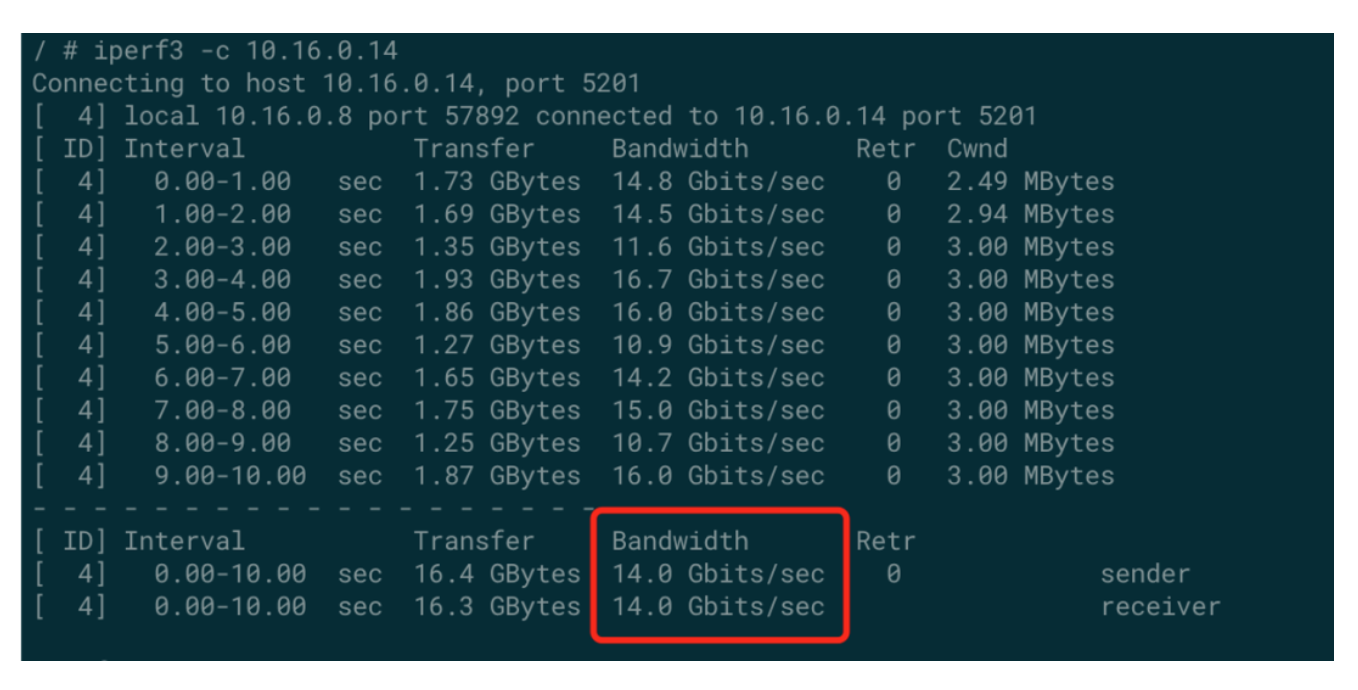
经验总结
优化建议
请关注Kube-OVN视频号
点赞收藏
分类:
Kube-OVN优化之初
怎么想到要做性能优化?
容器网络性能的自我救赎
测试方法和测试基准
第一轮profile
第一轮优化
第二轮profile
第二轮优化
第三轮profile
第三轮优化
第四轮profile
第四轮优化
整体优化总结
和其他网络插件对比
1k数据包吞吐量优化
虚拟机吞吐量优化
经验总结
优化建议
Kube-OVN, a CNCF Sandbox Level Project, integrates the OVN-based Network Virtualization with Kubernetes. It offers an advanced Container Network Fabric for Enterprises with the most functions.
Kube-OVN, a CNCF Sandbox Level Project, integrates the OVN-based Network Virtualization with Kubernetes. It offers an advanced Container Network Fabric for Enterprises with the most functions.


