
系统性能优化,必知的一些延时数据(CPU仅1s,磁盘1个月,TCP包重传100年)原创
4年前
8254113
Google AppEngine Numbers
英文原文:
http://highscalability.com/blog/2009/2/18/numbers-everyone-should-know.html演讲视频和PPT:
https://sites.google.com/site/io/building-scalable-web-applications-with-google-app-engine
写操作是昂贵的
-
数据存储是事务性的:写操作需要进行磁盘访问; -
磁盘访问,意味着需要进行磁盘寻道; -
经验法则:一次磁盘寻道需要10ms; -
简单的数学计算:1s / 10ms = 100次寻道/s(最大值); -
影响因素包括: -
数据的大小和形式(数据实体有多少个属性,属性的大小,是否为索引属性等); -
分批进行处理(批量写入和读取)。
读操作是廉价的
-
读操作要保证一致性,但不需要具备事务性; -
一旦从磁盘读取了数据,就可以很容易的将它缓存起来; -
而后续的所有读取操作,可以直接从内存中读取; -
经验法则:从内存中读取1MB数据需要250us(微秒); -
简单的数学计算:1s / 250us = 4000MB/s = 4GB/s(最大值); -
对于1MB的实体数据,1s可以读取4000次。
数字杂项
-
访问L1缓存:0.5ns; -
分支预测失败:5ns; -
访问L2缓存:7ns; -
对互斥量(Mutex)的加锁/解锁操作:100ns; -
访问主存:100ns; -
使用Zippy压缩1KB数据:10,000ns = 10us; -
通过1Gbps的网络发送2KB数据:20,000ns = 20us = 0.02ms; -
从内存中顺序读取1MB数据:250,000ns = 250us = 0.25ms; -
同一个数据中心的RTT(往返时间):500,000ns = 500us = 0.5ms; -
磁盘寻道:10,000,000ns = 10ms; -
从网络中顺序读取1MB数据:10,000,000ns = 10ms; -
从磁盘中顺序读取1MB数据:30,000,000ns = 30ms; -
发送一个包,从加拿大到荷兰的RTT:150,000,000ns = 150ms;
经验教训
-
写操作的成本,是读操作的40倍; -
全局共享数据非常昂贵。这是分布式系统的基本限制。对共享对象的大量写操作产生的锁竞争,会由于事务的串行化和缓慢而导致性能下降。 -
支持可扩展写的架构; -
尽可能消除写入的竞争; -
尽可能让写操作并行化。
时间
响应时间
延时
-
DNS延时。指整个DNS操作的时间; -
TCP连接延时。指连接的初始化,即TCP三次握手; -
TCP数据传输时间。
时间单位

系统的各种延时

磁盘IO延时
-
一种是磁盘缓存命中(低于100us); -
另一种是缓存未命中(1~8ms,甚至更慢,取决于访问模式和磁盘类型)。

常用系统操作响应时间表
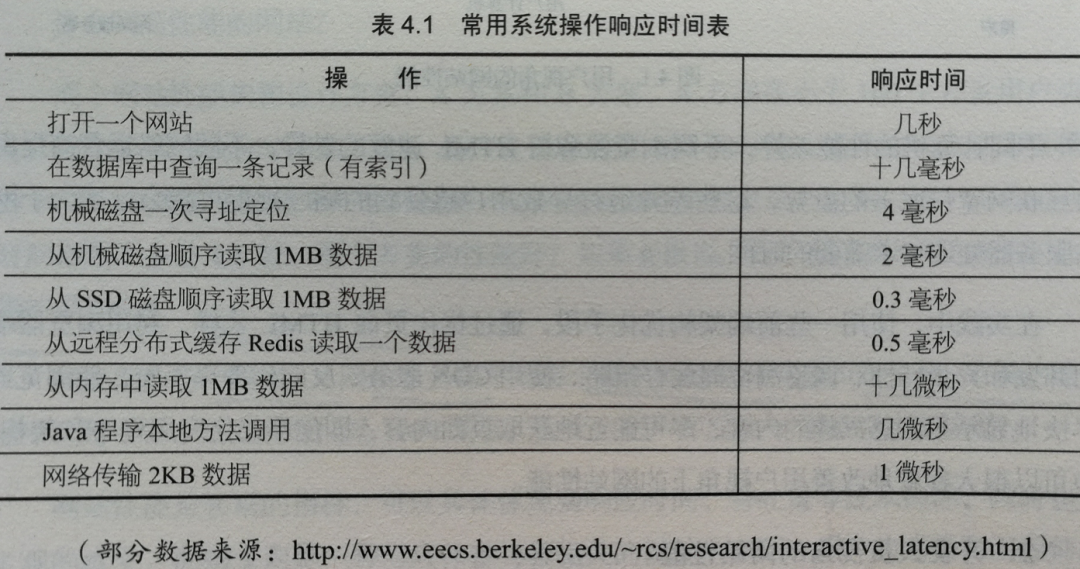
常用硬件性能参数

总结
读取1MB数据
-
从网络中顺序读取:10ms。1秒可以读取100次,或是1s最大读取100M(1000/10=100)。 -
从磁盘中顺序读取:30ms。1秒可以读取33次,或是1s最大读取33M(1000/30=33)。 -
从内存中顺序读取:0.25ms。1秒可以读取4000次,或是1s最大读取4G(1000/0.25=4000)。
访问时间数量级比较
-
访问CPU L1缓存:1ns; -
访问主存:100ns。约为访问CPU L1缓存时间的100倍; -
访问机械磁盘:10ms = 10,000,000ns。约为访问主存时间的10w倍; -
访问固态磁盘:100us = 100,000ns。约为访问机械磁盘时间的1/100倍,访问主存时间的1000倍;
参考
点赞收藏
分类:


