
深入理解Linux内核进程上下文切换原创
我们都知道操作系统的一个重要功能就是进行进程管理,而进程管理就是在合适的时机选择合适的进程来执行,在单个cpu运行队列上各个进程宏观并行微观串行执行,多个cpu运行队列上的各个进程之间完全的并行执行。进程管理是个复杂的过程,例如进程的描述、创建和销毁、生命周期管理、进程切换、进程抢占、调度策略、负载均衡等等。本文主要关注进程管理的一个切入点,那就是进程的上下文切换,来理解linux内核是如何进程进程上下文切换的,从而揭开上下文切换的神秘面纱。
(注意:本文以linux-5.0内核源码讲解,采用arm64架构)
本文目录:
1.进程上下文的概念
2.上下文切换详细过程
2.1 进程地址空间切换
2.2 处理器状态(硬件上下文)切换
3.ASID机制
4.普通用户进程、普通用户线程、内核线程切换的差别
5.进程切换全景视图
6.总结
1.进程上下文的概念
进程上下文是进程执行活动全过程的静态描述。我们把已执行过的进程指令和数据在相关寄存器与堆栈中的内容称为进程上文,把正在执行的指令和数据在寄存器与堆栈中的内容称为进程正文,把待执行的指令和数据在寄存器与堆栈中的内容称为进程下文。
实际上linux内核中,进程上下文包括进程的虚拟地址空间和硬件上下文。
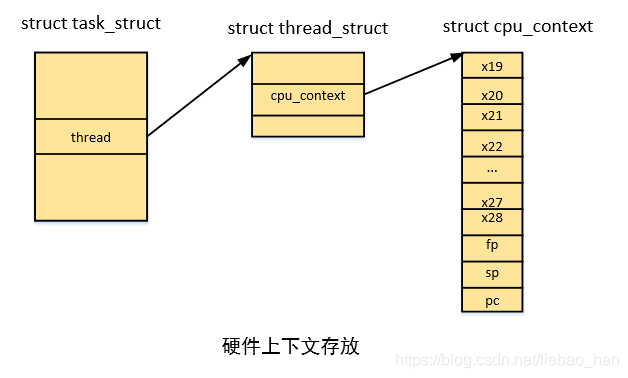
进程硬件上下文包含了当前cpu的一组寄存器的集合,arm64中使用task_struct结构的thread成员的cpu_context成员来描述,包括x19-x28,sp, pc等。
如下为硬件上下文存放示例图:
2.上下文切换详细过程
进程上下文切换主要涉及到两部分主要过程:进程地址空间切换和处理器状态切换。地址空间切换主要是针对用户进程而言,而处理器状态切换对应于所有的调度单位。下面我们分别看下这两个过程:
__schedule // kernel/sched/core.c
->context_switch
->switch_mm_irqs_off //进程地址空间切换
->switch_to //处理器状态切换
2.1 进程地址空间切换
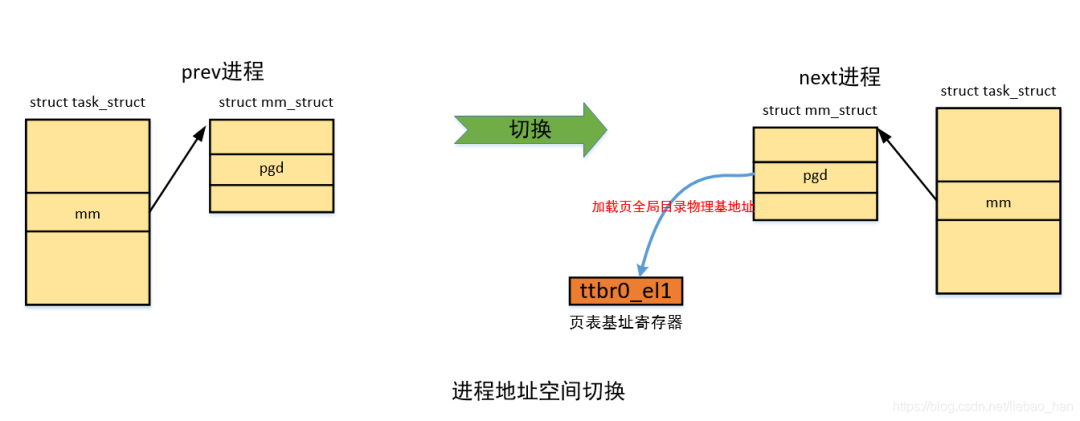
进程地址空间指的是进程所拥有的虚拟地址空间,而这个地址空间是假的,是linux内核通过数据结构来描述出来的,从而使得每一个进程都感觉到自己拥有整个内存的假象,cpu访问的指令和数据最终会落实到实际的物理地址,对用进程而言通过缺页异常来分配和建立页表映射。进程地址空间内有进程运行的指令和数据,因此到调度器从其他进程重新切换到我的时候,为了保证当前进程访问的虚拟地址是自己的必须切换地址空间。
实际上,进程地址空间使用mm_struct结构体来描述,这个结构体被嵌入到进程描述符(我们通常所说的进程控制块PCB)task_struct中,mm_struct结构体将各个vma组织起来进行管理,其中有一个成员pgd至关重要,地址空间切换中最重要的是pgd的设置。
pgd中保存的是进程的页全局目录的虚拟地址(本文会涉及到页表相关的一些概念,在此不是重点,不清楚的可以查阅相关资料,后期有机会会讲解进程页表),记住保存的是虚拟地址,那么pgd的值是何时被设置的呢?答案是fork的时候,如果是创建进程,需要分配设置mm_struct,其中会分配进程页全局目录所在的页,然后将首地址赋值给pgd。
我们来看看进程地址空间究竟是如何切换的,结果会让你大吃一惊(这里暂且不考虑asid机制,后面有机会会在其他文章中讲解):
代码路径如下:
context_switch // kernel/sched/core.c
->switch_mm_irqs_off
->switch_mm
->__switch_mm
->check_and_switch_context
->cpu_switch_mm
->cpu_do_switch_mm(virt_to_phys(pgd),mm) //arch/arm64/include/asm/mmu_context.h
arch/arm64/mm/proc.S
158 /*
159 * cpu_do_switch_mm(pgd_phys, tsk)
160 *
161 * Set the translation table base pointer to be pgd_phys.
162 *
163 * - pgd_phys - physical address of new TTB
164 */
165 ENTRY(cpu_do_switch_mm)
166 mrs x2, ttbr1_el1
167 mmid x1, x1 // get mm->context.id
168 phys_to_ttbr x3, x0
169
170 alternative_if ARM64_HAS_CNP
171 cbz x1, 1f // skip CNP for reserved ASID
172 orr x3, x3, #TTBR_CNP_BIT
173 1:
174 alternative_else_nop_endif
175 #ifdef CONFIG_ARM64_SW_TTBR0_PAN
176 bfi x3, x1, #48, #16 // set the ASID field in TTBR0
177 #endif
178 bfi x2, x1, #48, #16 // set the ASID
179 msr ttbr1_el1, x2 // in TTBR1 (since TCR.A1 is set)
180 isb
181 msr ttbr0_el1, x3 // now update TTBR0
182 isb
183 b post_ttbr_update_workaround // Back to C code...
184 ENDPROC(cpu_do_switch_mm)
代码中最核心的为181行,最终将进程的pgd虚拟地址转化为物理地址存放在ttbr0_el1中,这是用户空间的页表基址寄存器,当访问用户空间地址的时候mmu会通过这个寄存器来做遍历页表获得物理地址(ttbr1_el1是内核空间的页表基址寄存器,访问内核空间地址时使用,所有进程共享,不需要切换)。完成了这一步,也就完成了进程的地址空间切换,确切的说是进程的虚拟地址空间切换。
内核处理的是不是很简单,很优雅,别看只是设置了页表基址寄存器,也就是将即将执行的进程的页全局目录的物理地址设置到页表基址寄存器,他却完成了地址空间切换的壮举,有的小伙伴可能不明白为啥这就完成了地址空间切换?试想如果进程想要访问一个用户空间虚拟地址,cpu的mmu所做的工作,就是从页表基址寄存器拿到页全局目录的物理基地址,然后和虚拟地址配合来查查找页表,最终找到物理地址进行访问(当然如果tlb命中就不需要遍历页表),每次用户虚拟地址访问的时候(内核空间共享不考虑),由于页表基地址寄存器内存放的是当前执行进程的页全局目录的物理地址,所以访问自己的一套页表,拿到的是属于自己的物理地址(实际上,进程是访问虚拟地址空间的指令数据的时候不断发生缺页异常,然后缺页异常处理程序为进程分配实际的物理页,然后将页帧号和页表属性填入自己的页表条目中),就不会访问其他进程的指令和数据,这也是为何多个进程可以访问相同的虚拟地址而不会出现差错的原因,而且做到的各个地址空间的隔离互不影响(共享内存除外)。
其实,地址空间切换过程中,还会清空tlb,防止当前进程虚拟地址转化过程中命中上一个进程的tlb表项,一般会将所有的tlb无效,但是这会导致很大的性能损失,因为新进程被切换进来的时候面对的是全新的空的tlb,造成很大概率的tlb miss,需要重新遍历多级页表,所以arm64在tlb表项中增加了非全局(nG)位区分内核和进程的页表项,使用ASID区分不同进程的页表项,来保证可以在切换地址空间的时候可以不刷tlb,后面会主要讲解ASID技术。
还需要注意的是仅仅切换用户地址空间,内核地址空间由于是共享的不需要切换,也就是为何切换到内核线程不需要也没有地址空间的原因。
如下为进程地址空间切换示例图:
2.2 处理器状态(硬件上下文)切换
前面进行了地址空间切换,只是保证了进程访问指令数据时访问的是自己地址空间(当然上下文切换的时候处于内核空间,执行的是内核地址数据,当返回用户空间的时候才有机会执行用户空间指令数据**,地址空间切换为进程访问自己用户空间做好了准备**),但是进程执行的内核栈还是前一个进程的,当前执行流也还是前一个进程的,需要做切换。
arm64中切换代码如下:
switch_to
->__switch_to
... //浮点寄存器等的切换
->cpu_switch_to(prev, next)
arch/arm64/kernel/entry.S:
1032 /*
1033 * Register switch for AArch64. The callee-saved registers need to be saved
1034 * and restored. On entry:
1035 * x0 = previous task_struct (must be preserved across the switch)
1036 * x1 = next task_struct
1037 * Previous and next are guaranteed not to be the same.
1038 *
1039 */
1040 ENTRY(cpu_switch_to)
1041 mov x10, #THREAD_CPU_CONTEXT
1042 add x8, x0, x10
1043 mov x9, sp
1044 stp x19, x20, [x8], #16 // store callee-saved registers
1045 stp x21, x22, [x8], #16
1046 stp x23, x24, [x8], #16
1047 stp x25, x26, [x8], #16
1048 stp x27, x28, [x8], #16
1049 stp x29, x9, [x8], #16
1050 str lr, [x8]
1051 add x8, x1, x10
1052 ldp x19, x20, [x8], #16 // restore callee-saved registers
1053 ldp x21, x22, [x8], #16
1054 ldp x23, x24, [x8], #16
1055 ldp x25, x26, [x8], #16
1056 ldp x27, x28, [x8], #16
1057 ldp x29, x9, [x8], #16
1058 ldr lr, [x8]
1059 mov sp, x9
1060 msr sp_el0, x1
1061 ret
1062 ENDPROC(cpu_switch_to)
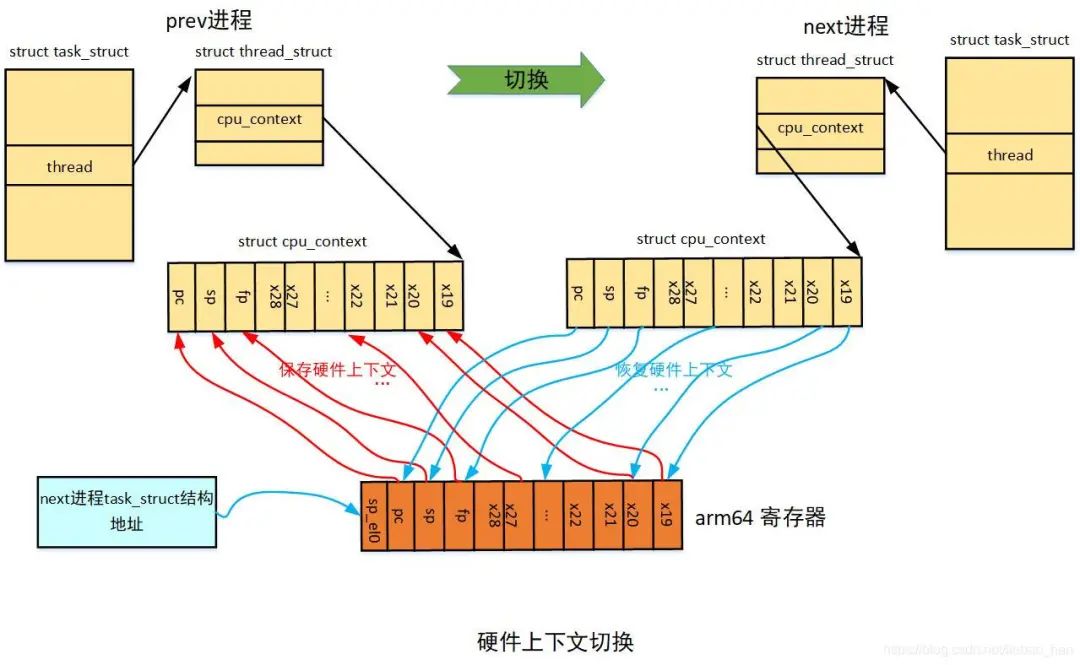
其中x19-x28是arm64 架构规定需要调用保存的寄存器,可以看到处理器状态切换的时候将前一个进程(prev)的x19-x28,fp,sp,pc保存到了进程描述符的cpu_contex中,然后将即将执行的进程(next)描述符的cpu_contex的x19-x28,fp,sp,pc恢复到相应寄存器中,而且将next进程的进程描述符task_struct地址存放在sp_el0中,用于通过current找到当前进程,这样就完成了处理器的状态切换。
实际上,处理器状态切换就是将前一个进程的sp,pc等寄存器的值保存到一块内存上,然后将即将执行的进程的sp,pc等寄存器的值从另一块内存中恢复到相应寄存器中,恢复sp完成了进程内核栈的切换,恢复pc完成了指令执行流的切换。其中保存/恢复所用到的那块内存需要被进程所标识,这块内存这就是cpu_contex这个结构的位置(进程切换都是在内核空间完成)。
由于用户空间通过异常/中断进入内核空间的时候都需要保存现场,也就是保存发生异常/中断时的所有通用寄存器的值,内核会把“现场”保存到每个进程特有的进程内核栈中,并用pt_regs结构来描述,当异常/中断处理完成之后会返回用户空间,返回之前会恢复之前保存的“现场”,用户程序继续执行。
所以当进程切换的时候,当前进程被时钟中断打断,将发生中断时的现场保存到进程内核栈(如:sp, lr等),然后会切换到下一个进程,当再次回切换回来的时候,返回用户空间的时候会恢复之前的现场,进程就可以继续执行(执行之前被中断打断的下一条指令,继续使用自己用户态sp),这对于用户进程来说是透明的。
如下为硬件上下文切换示例图:
3.ASID机制
前面讲过,进程切换的时候,由于tlb中存放的可能是其他进程的tlb表项,所有才需要在进程切换的时候进行tlb的清空工作(清空即是使得所有的tlb表项无效,地址转换需要遍历多级页表,找到页表项,然后重新加载页表项到tlb),有了ASID机制之后,命中tlb表项,由虚拟地址和ASID共同决定(当然还有nG位),可以减小进程切换中tlb被清空的机会。
下面我们讲解ASID机制,ASID(Address Space Identifer 地址空间标识符),用于区别不同进程的页表项,arm64中,可以选择两种ASID长度8位或者16位,这里以8位来讲解。
如果ASID长度为8位,那么ASID有256个值,但是由于0是保留的,所有可以分配的ASID范围就为1-255,那么可以标识255个进程,当超出255个进程的时候,会出现两个进程的ASID相同的情况,因此内核使用了ASID版本号。
内核中处理如下(参考arch/arm64/mm/context.c):
1)内核为每个进程分配一个64位的软件ASID,其中低8位为硬件ASID,高56位为ASID版本号,这个软件ASID存放放在进程的mm_struct结构的context结构的id中,进程创建的时候会初始化为0。
2)内核中有一个64位的全局变量asid_generation,同样它的高56位为ASID版本号,用于标识当前ASID分配的批次。
3)当进程调度,由prev进程切换到next进程的时候,如果不是内核线程则进行地址空间切换调用check_and_switch_context,此函数会判断next进程的ASID版本号是否和全局的ASID版本号相同(是否处于同一批次),如果相同则不需要为next进程分配ASID,不相同则需要分配ASID。
4)内核使用asid_map位图来管理硬件ASID的分配,asid_bits记录使用的ASID的长度,每处理器变量active_asids保存当前分配的硬件ASID,每处理器变量reserved_asids存放保留的ASID,tlb_flush_pending位图记录需要清空tlb的cpu集合。
硬件ASID分配策略如下:
(1)如果进程的ASID版本号和当前全局的ASID版本号相同(同批次情况),则不需要重新分配ASID。
(2)如果进程的ASID版本号和当前全局的ASID版本号不相同(不同批次情况),且进程原本的硬件ASID已经被分配,则重新分配新的硬件ASID,并将当前全局的ASID版本号组合新分配的硬件ASID写到进程的软件ASID中。
(3)如果进程的ASID版本号和当前全局的ASID版本号不相同(不同批次情况),且进程原本的硬件ASID还没有被分配,则不需要重新分配新的硬件ASID,只需要更新进程软件ASID版本号,并将当前全局的ASID版本号组合进程原来的硬件ASID写到进程的软件ASID中。
(4)如果进程的ASID版本号和当前全局的ASID版本号不相同(不同批次情况),需要分配硬件ASID时,发现硬件ASID已经被其他进程分配完(asid_map位图中查找,发现位图全1),则这个时候需要递增全局的ASID版本号, 清空所有cpu的tlb, 清空asid_map位图,然后分配硬件ASID,并将当前全局的ASID版本号组合新分配的硬件ASID写到进程的软件ASID中。
下面我们以实例来看ASID的分配过程:
如下图:
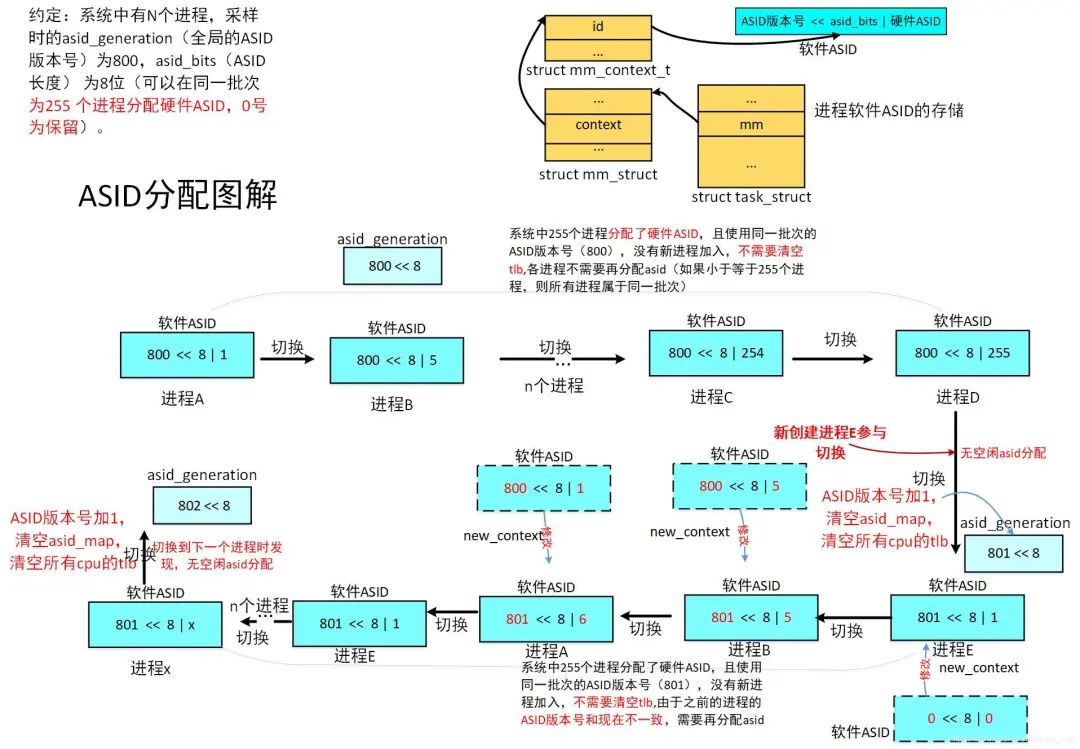
我们假设图中从A进程到D进程,有255个进程,刚好分配完了asid,从A到D的切换过程中使用的都是同一批次的asid版本号。
则这个过程中,有进程会创建的时候被切换到,假设不超出255个进程,在切换过程中会为新进程分配硬件的ASID,分配完后下次切换到他时由于他的ASID版本号和当前的全局的ASID版本号相同,所以不需要再次分配ASID,当然也不需要清空tlb。
注:这里说的ASID即为硬件ASID区别于ASID版本号。
情况1 -ASID版本号不变 属于策略(1):从C进程到D进程切换,内核判断D进程的ASID版本号和当前的全局的ASID版本号相同,所以不需要为他分配ASID(执行快速路径switch_mm_fastpath去设置ttbrx_el1))。
情况2 -硬件ASID全部分配完 属于策略(4):假设到达D进程时,asid已经全部分配完(系统中有255个进程都分配到了硬件asid号),这个时候新创建的进程E被调度器选中,切换到E,由于新创建的进程的软件ASID被初始化为0,所以和当前的全局的ASID版本号不同(不在同一批次),则这个时候会执行new_context为进程分配ASID,但是由于没有可以分配的ASID,所以会将全局的ASID版本号加1(发生ASID回绕),这个时候全局的ASID为801,然后清空asid_map,置位tlb_flush_pending所有bit用于清空所有cpu的tlb,然后再次去分配硬件ASID给E进程,这个时候分配到了1给他(将ASID版本号)。
情况3 -ASID版本号发生变化,进程的硬件ASID可以再次使用 属于策略(3):假设从E切换到了B进程,而B进程之前已经在全局的ASID版本号为800的批次上分配了编号为5的硬件ASID,但是B进程的ASID版本号800和现在全局的ASID版本号801不相同,所有需要new_context为进程分配ASID,分配的时候发现asid_map中编号为5没有被置位,也就是没有其他进程分配了5这个ASID,所有可以继续使用原来分配的硬件ASID 5。
情况4 - ASID版本号发生变化,有其他进程已经分配了相同的硬件ASID 属于策略(2): 假设从B进程切换到A进程,而B进程之前已经在全局的ASID版本号为800的批次上分配了编号为1的硬件ASID,但是B进程的ASID版本号800和现在全局的ASID版本号801不相同,所有需要new_context为进程分配ASID,分配的时候发现asid_map中编号为1已经被置位,也就是其他进程已经分配了1这个ASID,需要从asid_map寻找下一个空闲的ASID,则分配了新的ASID为6。
假设从A到E,由于E的ASID版本号和全局的ASID版本号(同一批次),和情况1相同,不需要分配ASID。但是之前原来处于800这个ASID版本号批次的进程都需要重新分配ASID,有的可以使用原来的硬件ASID,有的重新分配硬件ASID,但是都将ASID版本号修改为了现在全局的ASID版本号801。但是,随着硬件ASID的不断分配,最终处于801这一批次的硬件ASID也会分配完,这个时候就是上面的情况2,要情况所有cpu的tlb。
我可以看到有了ASID机制之后,由于只有当硬件ASID被分配完了(如被255个进程使用),发生回绕的时候才会清空所有cpu的tlb,大大提高了系统的性能(没有ASID机制的情况下每次进程切换需要地址空间切换的时候都需要清空tlb)。
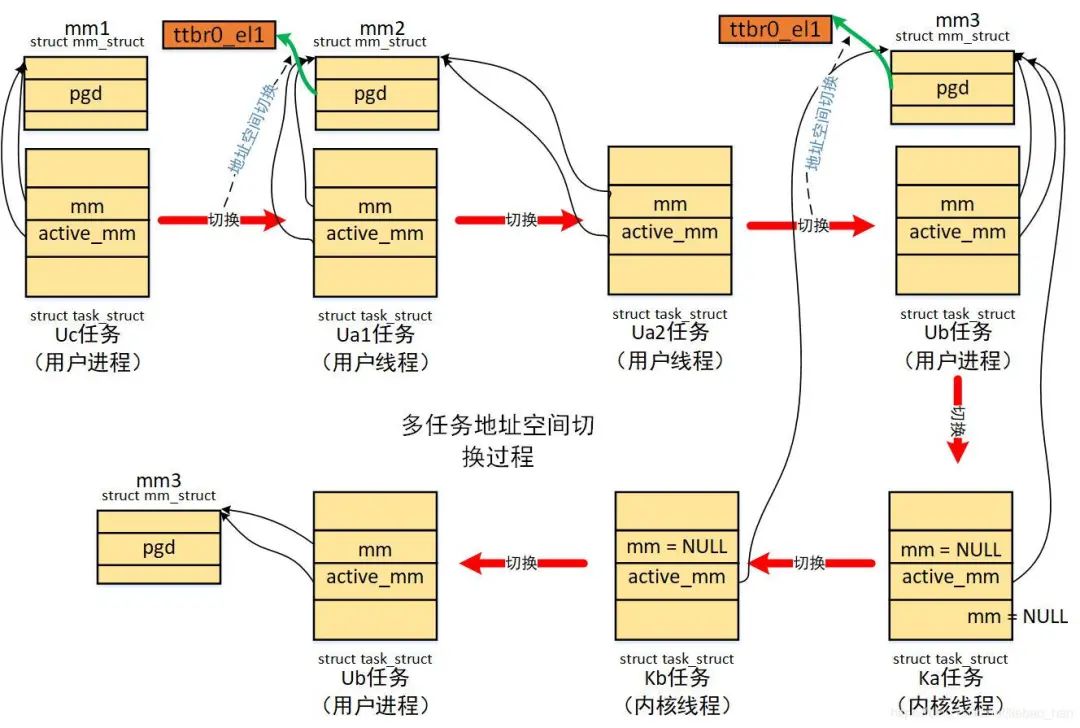
4. 普通用户进程、普通用户线程、内核线程切换的差别
内核地址空间切换的时候有一下原则:看的是进程描述符的mm_struct结构,即是成员mm:
1)如果mm为NULL,则表示即将切换的是内核线程,不需要切换地址空间(所有任务共享内核地址空间)。
2)内核线程会借用前一个用户进程的mm,赋值到自己的active_mm(本身的mm为空),进程切换的时候就会比较前一个进程的active_mm和当前进程的mm。
3)如果前一个任务的和即将切换的任务,具有相同的mm成员,也就是共享地址空间的线程则也不需要切换地址空间。
->所有的进程线程之间进行切换都需要切换处理器状态。
->对于普通的用户进程之间进行切换需要切换地址空间。
->同一个线程组中的线程之间切换不需要切换地址空间,因为他们共享相同的地址空间。
-> 内核线程在上下文切换的时候不需要切换地址空间,仅仅是借用上一个进程mm_struct结构。
有一下场景:
约定:我们将进程/线程统称为任务,其中U表示用户任务(进程/线程),K表示内核线程,带有数字表示同一个线程组中的线程。
有以下任务:Ua1 Ua2 Ub Uc Ka Kb (eg:Ua1为用户进程, Ua2为和Ua1在同一线程组的用户进程,Ub普通的用户进程,Ka普通的内核线程 )。
如果调度顺序如下:
Uc -> Ua1 -> Ua2 -> Ub -> Ka -> Kb -> Ub
从Uc -> Ua1 由于是不同的进程,需要切换地址空间。
从 Ua1 -> Ua2 由于是相同线程组中的不同线程,共享地址空间,在切换到Ua1的时候已经切换了地址空间,所有不需要切换地址空间。
从 Ua2 -> Ub 由于是不同的进程,需要切换地址空间。
从 Ub -> Ka 由于切换到内核线程,所以不需要切换地址空间。
从Ka -> Kb 俩内核线程之前切换,不需要切换地址空间。
从Kb -> Ub 从内核线程切换到用户进程,由于Ka和Kb都是借用Ub的active_mm,而Ub的active_mm 等于Ub的mm,所以这个时候 Kb的active_mm和 Ub的mm相同,所有也不会切换地址空间。
如下为多任务地址空间切换示例图:
5. 进程切换全景视图
我们以下场景为例:
A,B两个进程都是普通的用户进程,从进程A切换到进程B,简单起见我们在这里不考虑其他的抢占时机,我们假设A,B进程只是循环进行一些基本的运算操作,从来不调用任何系统调用,只考虑被时钟中断,返回用户空间之前被抢占的情况。
下面给出进程切换的全景视图:
视图中已经讲解很清楚,需要强调3个关键点:
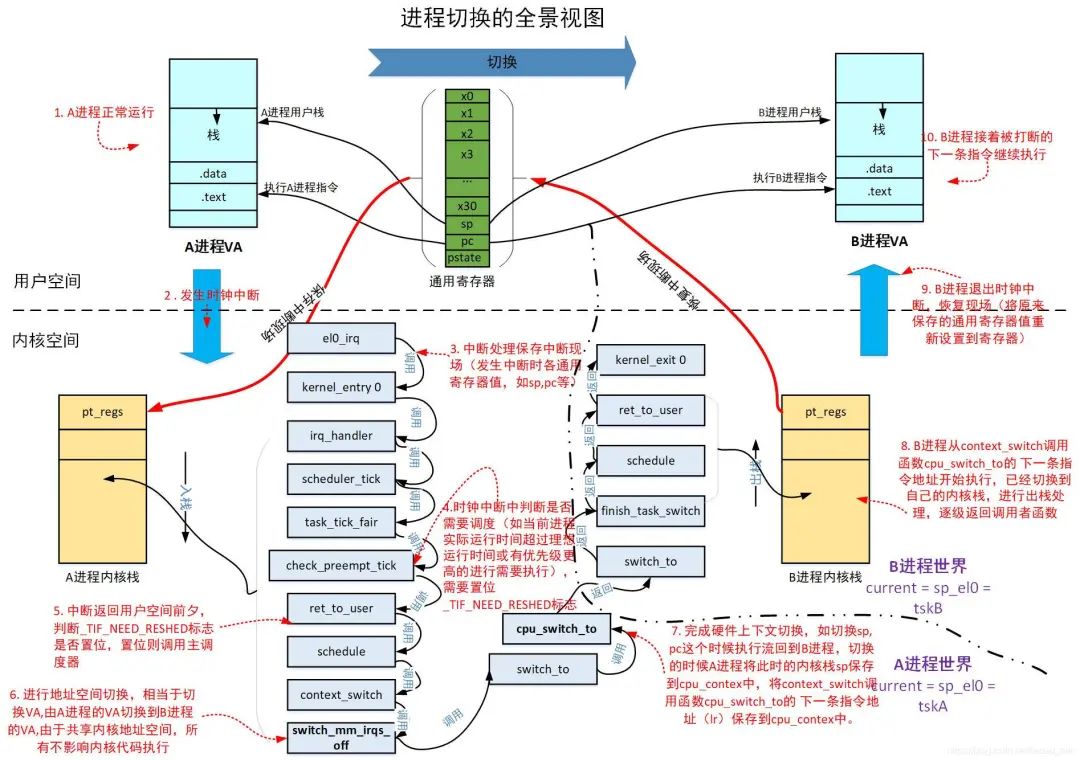
1.发生中断时的保存现场,将发生中断时的所有通用寄存器保存到进程的内核栈,使用struct pt_regs结构。
2.地址空间切换将进程自己的页全局目录的基地址pgd保存在ttbr0_le1中,用于mmu的页表遍历的起始点。
3.硬件上下文切换的时候,将此时的调用保存寄存器和pc, sp保存到struct cpu_context结构中。做好了这几个保存工作,当进程再次被调度回来的时候,通过cpu_context中保存的pc回到了cpu_switch_to的下一条指令继续执行,而由于cpu_context中保存的sp导致当前进程回到自己的内核栈,经过一系列的内核栈的出栈处理,最后将原来保存在pt_regs中的通用寄存器的值恢复到了通用寄存器,这样进程回到用户空间就可以继续沿着被中断打断的下一条指令开始执行,用户栈也回到了被打断之前的位置,而进程访问的指令数据做地址转化(VA到PA)也都是从自己的pgd开始进行,一切对用户来说就好像没有发生一样,简直天衣无缝。
6. 总结
进程管理中最重要的一步要进行进程上下文切换,其中主要有两大步骤:地址空间切换和处理器状态切换(硬件上下文切换),前者保证了进程回到用户空间之后能够访问到自己的指令和数据(其中包括减小tlb清空的ASID机制),后者保证了进程内核栈和执行流的切换,会将当前进程的硬件上下文保存在进程所管理的一块内存,然后将即将执行的进程的硬件上下文从内存中恢复到寄存器,有了这两步的切换过程保证了进程运行的有条不紊,当然切换的过程是在内核空间完成,这对于进程来说是透明的。



