
一种探究 InnoDB 的存储格式的新方式原创
文件的存储结构包含了系统大量的实现细节,比如 java 的 class 文件结构,rocksdb 的存储结构。MySQL InnoDB 的存储格式比较复杂,但确实我们理解 MySQL 技术内幕不必可少的一环。传统的分析的方法有下面这两个
jeremycole 的 innodb_ruby
阿里开源的 Java 版本 innodb-java-reader
但这两个版本都不那么直观,我还是想原滋原味的通过分析 .ibd 文件来实现,以求达到两个目的:可视化、模板化。于是我想到了宇宙最强的二进制分析工具 010 Editor。
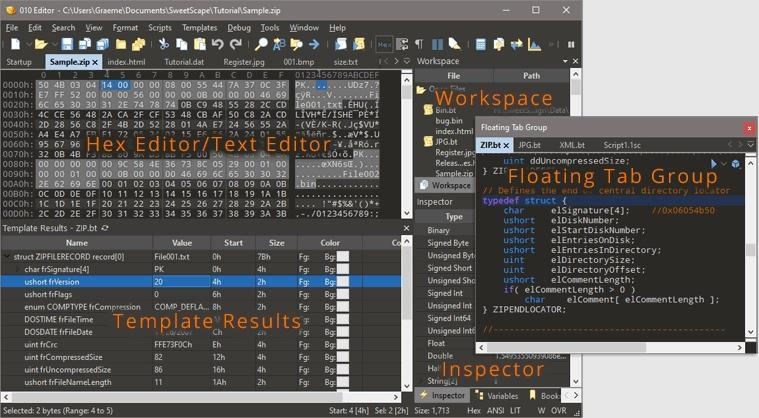
010 Editor 介绍
010 Editor 是一款商业软件,是二进制分析中十分强力的工具,能够解析多种文件格式并以可视化界面呈现。它有一个强大的内部引擎使得任何人都可以定制所需的解析脚本或解析模板。在 010 Editor的官网上已经有仓库存放了大量的脚本和模板库供大家学习和使用,比如 .zip、.exe、.class 等格式。但 MySQL 的 .ibd 文件官方仓库没有模板,只能自己撸一个了。
接下来介绍的大部分例子来源于小孩子大佬的掘金小册,算是作为一个补充吧。
万事开头难
010 模板的基本语法和 C 语言类似,本质就是把整个文件的二进制数据当作输入,将其映射到一个我们自己定义的结构体,在其中,我们可以自己来处理内部的逻辑。
我们知道 MySQL 以页为基本单位来管理存储空间,一个页的大小一般是 16KB,因此 ibd 文件大小除以 16KB 就可以知道有多少页了,也可以用循环读取 16KB 大小的方式直到文件末尾。
新建一个 test_01.bt 文件,内容如下。
#define PAGE_SIZE (16 * 1024)
// 定义一个 Page 结构体,表示一页的大小,暂时不解析里面的内容,先占个位
typedef struct Page {
byte content[PAGE_SIZE];
};
// 一直读取直到文件结束
while(!FEof()) {
Page page; // 读取 16KB 的内容映射到 Page 结构体中
}
也可以这么写
#define PAGE_SIZE (16 * 1024)
// 定义一个 Page 结构体,表示一页的大小,暂时不解析里面的内容,先占个位
typedef struct Page(int index) {
byte content[PAGE_SIZE];
};
local int file_size = FileSize();
local int i;
for (i = 0; i < file_size / PAGE_SIZE; ++i) {
Page page(i); // 读取 16KB 的内容映射到 Page 结构体中
}
导入这个模板文件,就可以在界面中这个 ibd 文件有 6 个 Page 页,具体里面是什么,我们稍后再解析。
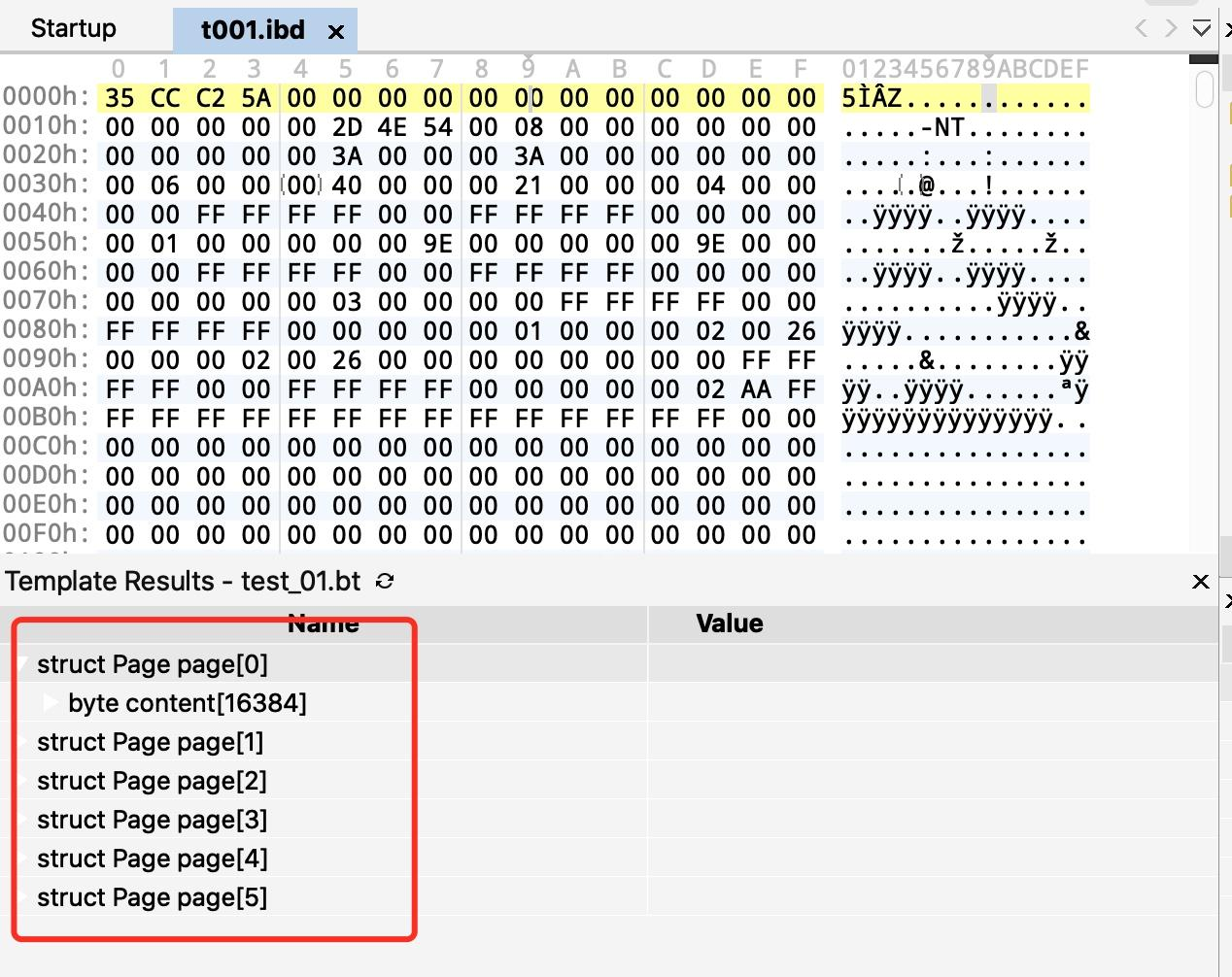
众所周不知,ibd 文件有很多种不同类型的 Page,但不同类型 Page 都以前 38 字节表示 File Header,描述了一些针对各种页都通用的一些信息,比如这个页的页面类型、页编号、它的上一个页、下一个页等。
它的组成结构如下。
这样在 010 中我们就可以定义一个结构体来表示 File Header。
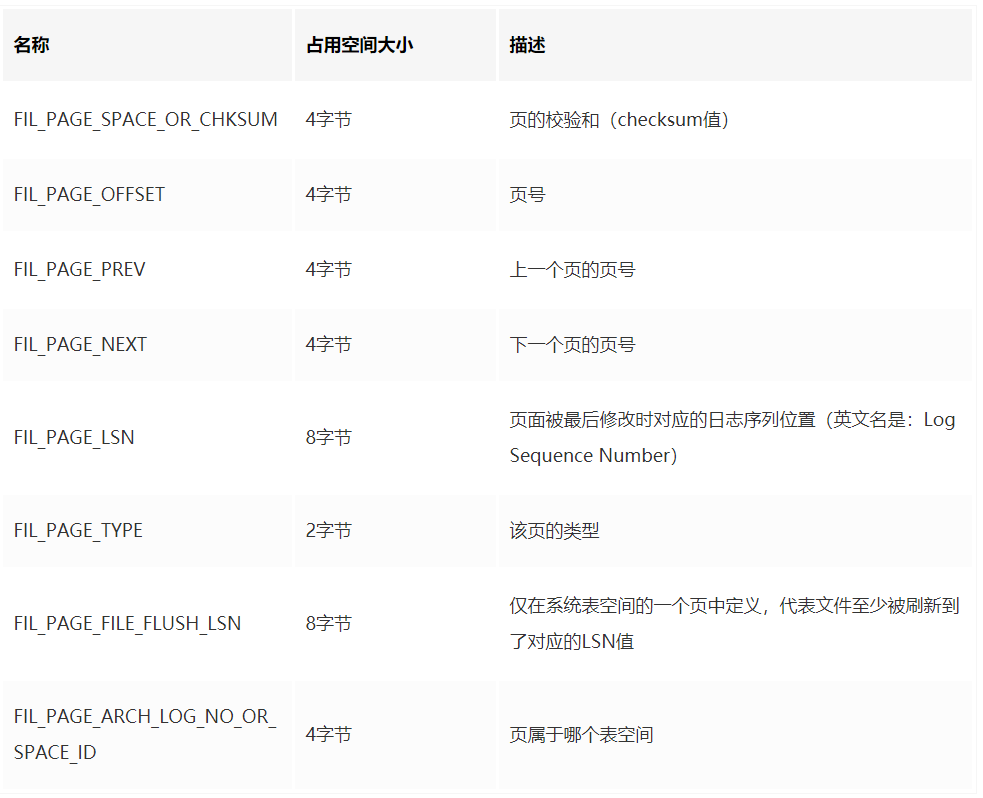
// 38 字节的 File Header,存储了页的一些通用信息
typedef struct FilHeader {
u4 FIL_PAGE_SPACE_OR_CHKSUM<format=hex,comment="页的校验和(checksum值)">;
u4 FIL_PAGE_OFFSET<fgcolor=0xFF0000,comment="页号">;
u4 FIL_PAGE_PREV<comment="上一个页的页号">;
u4 FIL_PAGE_NEXT<comment="下一个页的页号">;
u8 FIL_PAGE_LSN<comment="页面被最后修改时对应的日志序列位置(英文名是:Log Sequence Number)">;
PAGE_TYPE FIL_PAGE_TYPE;
u8 FIL_PAGE_FILE_FLUSH_LSN<comment="仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值">;
u4 FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID<comment="页属于哪个表空间">;
};
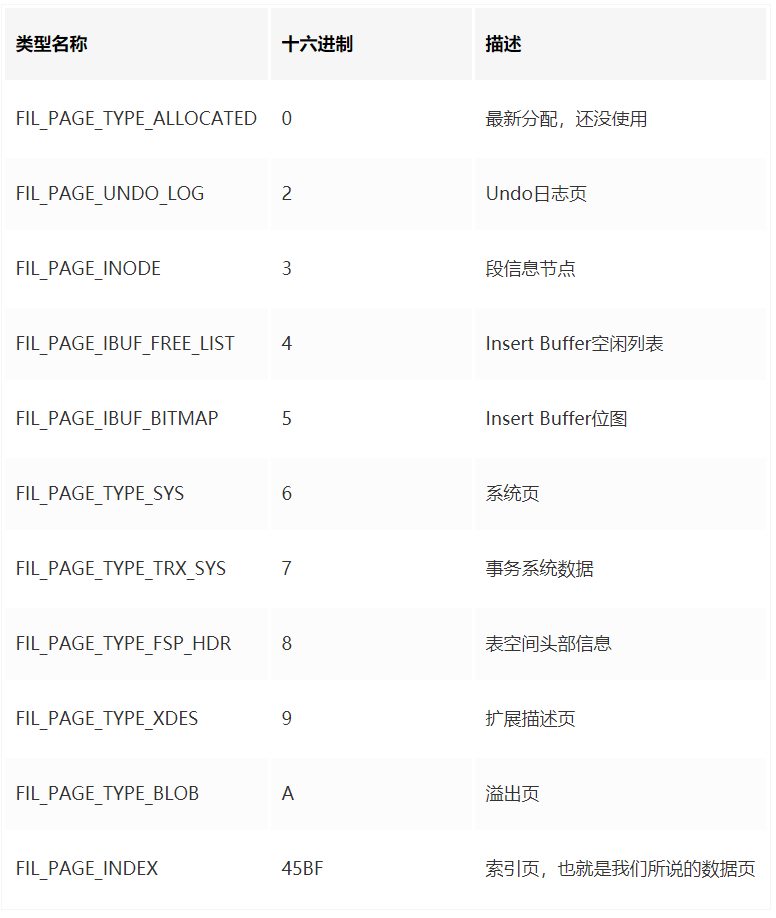
其中 PAGE_TYPE 是一个枚举类,表示页面的类型,常见的页面类型如下。
针对不同的页面类型,我们需要做不同的解析。综合上面的内容,我们就可以写出新一版的模板脚本。
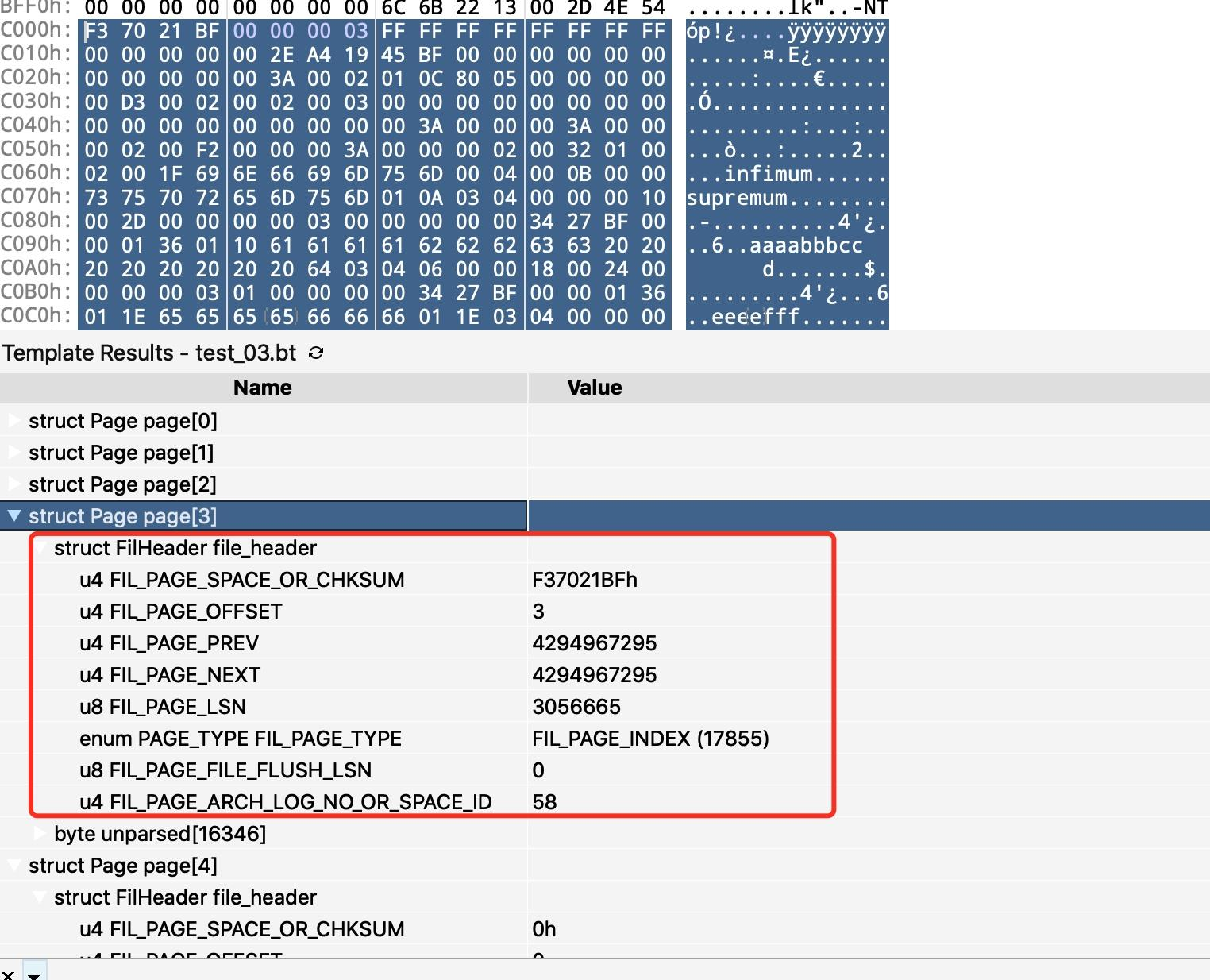
接下来我们重点解析 FIL_PAGE_INDEX 这种类型的页面,也就是我们所说的存数据的页。它的结构如下。
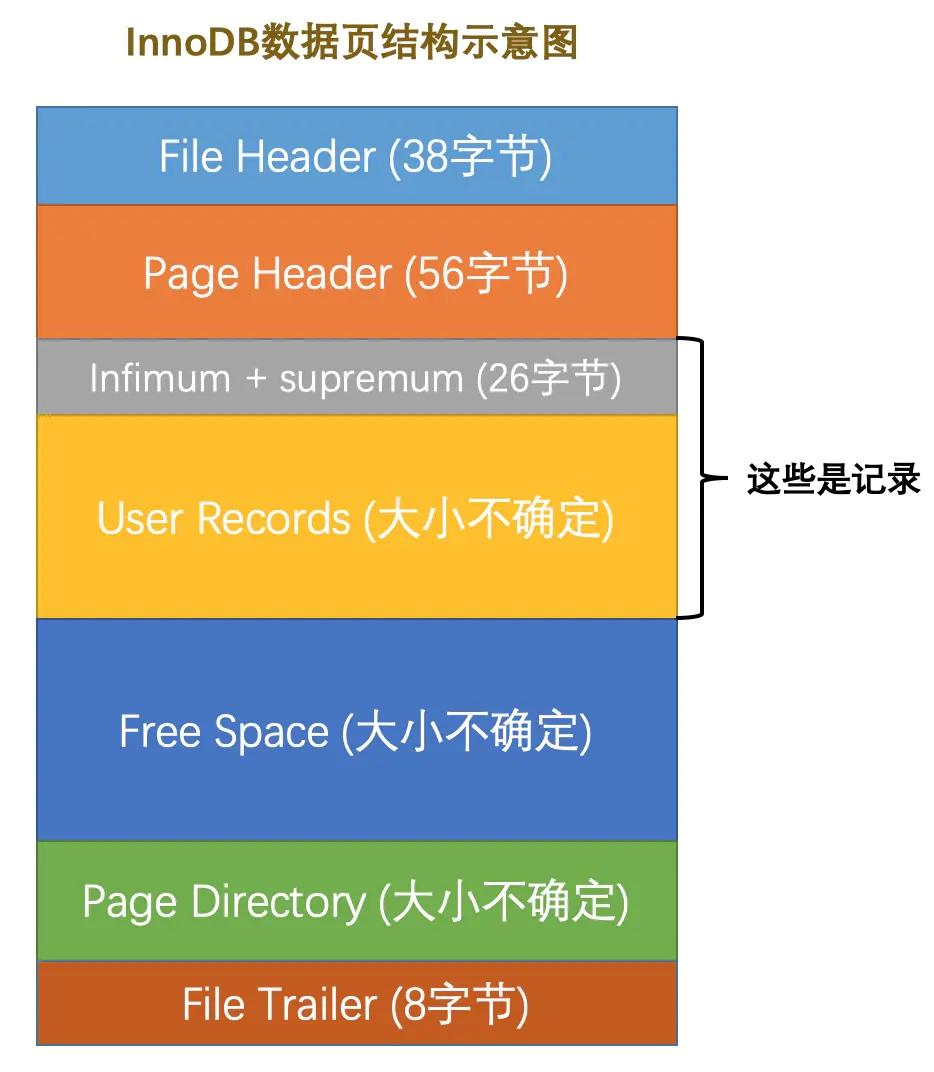
我们先来定义一个 PageHeader,如下所示。
// 56 字节的 Page Header
typedef struct PageHeader {
u2 PAGE_N_DIR_SLOTS<comment="在页目录中的槽数量">;
u2 PAGE_HEAP_TOP<comment="还未使用的空间最小地址,也就是说从该地址之后就是Free Space">;
PAGE_FORMAT_ENUM PAGE_FORMAT : 1 <comment="页面类型">;
u2 NUM_OF_HEAP_RECORDS : 15 <comment="本页中的记录的数量(包括最小和最大记录以及标记为删除的记录)">;
u2 PAGE_FREE<comment="next_record也会组成一个单链表,这个单链表中的记录可以被重新利用)">;
u2 PAGE_GARBAGE<comment="已删除记录占用的字节数">;
u2 PAGE_LAST_INSERT<comment="最后插入记录的位置">;
u2 PAGE_DIRECTION<comment="记录插入的方向">;
u2 PAGE_N_DIRECTION<comment="一个方向连续插入的记录数量">;
u2 PAGE_N_RECS<comment="该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录)">;
u8 PAGE_MAX_TRX_ID<comment="修改当前页的最大事务ID,该值仅在二级索引中定义">;
u2 PAGE_LEVEL<comment="当前页在B+树中所处的层级">;
u8 PAGE_INDEX_ID<comment="索引ID,表示当前页属于哪个索引">;
u1 PAGE_BTR_SEG_LEAF[10]<comment="B+树叶子段的头部信息,仅在B+树的Root页定义">;
u1 PAGE_BTR_SEG_TOP[10]<comment="B+树非叶子段的头部信息,仅在B+树的Root页定义">;
};
紧随 Page Header 之后的是两个特殊的记录 Infimum + Supremum,这是两个虚拟的行记录,表示了该页中的最小记录和最大记录。
Infimum 和 Supremum 由两部分组成,5 字节的记录头和 8 字节的字符串。
用脚本定义如下所示。
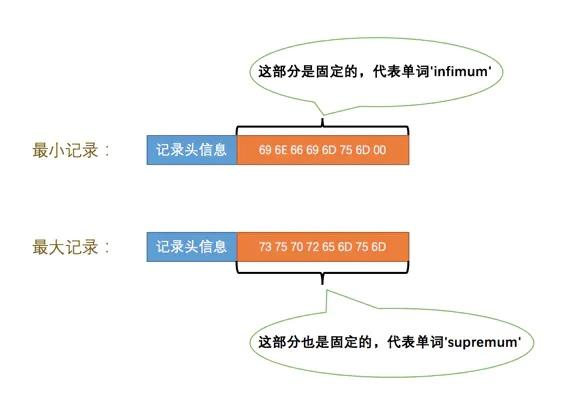
// 记录类型枚举类
enum <u1> RECORD_TYPE {
CONVENTIONAL = 0,
NODE_POINTER = 1,
INFIMUM = 2,
SUPREMUM = 3
};
// 5 字节记录头
typedef struct {
u1 : 2;
u1 delete_mask : 1;
u1 min_rec_mask : 1;
u1 n_owned : 4;
u2 heap_no : 13;
RECORD_TYPE record_type : 3;
short next_record : 16;
} RecordHeader<fgcolor=0xFF00FF>;
// 最大最小虚拟记录
typedef struct {
RecordHeader record_header; // 5 字节的记录头
char text[8]; // 8 字节的单词
} InfimumSupremumRecord;
运行脚本结果如下所示。
接下来我们就可以通过 infimum 和 supremum 遍历整个链表。
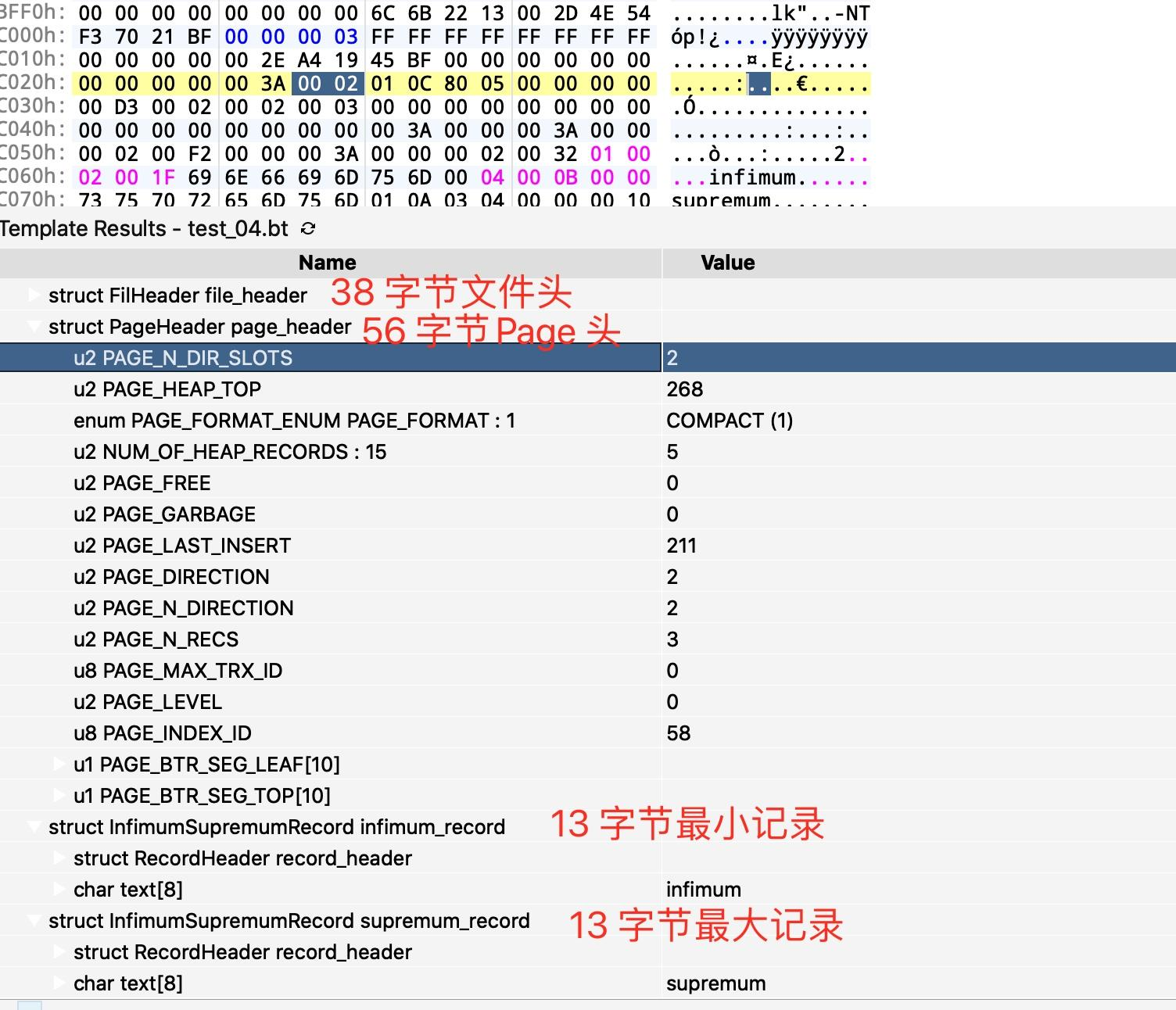
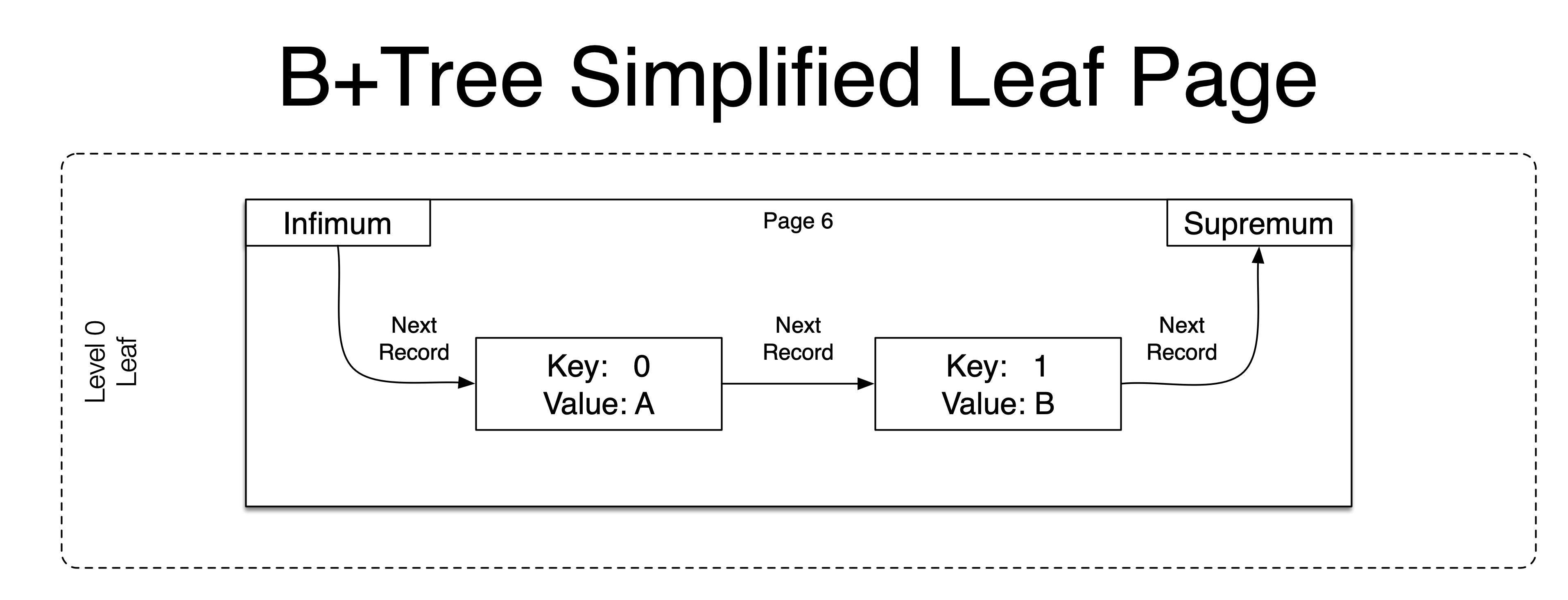
// 定义一个 Page 结构体
typedef struct Page(int index) {
FilHeader file_header; // 38 字节的 file header
if (file_header.FIL_PAGE_TYPE == FIL_PAGE_INDEX) {
PageHeader page_header; // 56 字节的 page header
InfimumSupremumRecord infimum_record; // 13 字节的虚拟最小记录
local int page_start_pos = index * PAGE_SIZE;
local int infimum_record_pos = FTell() - page_start_pos - 8; // 获取 infimum 记录的起始地址
InfimumSupremumRecord supremum_record; // 13 字节的虚拟最大记录
local int supremum_record_pos = FTell() - page_start_pos - 8; // 获取 supremum 记录的起始地址
// 第一条记录的相对位置
local int next_rec_rel_pos = infimum_record_pos + infimum_record.record_header.next_record;
// 遍历链表
while(next_rec_rel_pos != supremum_record_pos) {
FSeek(page_start_pos + next_rec_rel_pos - 5); // 往前走五个字节,读取记录头,便于获取下一条记录的相对位置
RecordHeader record_header;
next_rec_rel_pos += record_header.next_record;
}
}
// 跳到 Page 页的尾部
FSeek((index + 1) * PAGE_SIZE);
};
至此,我们已经完成了一个最简单的 ibd 文件解析逻辑。剩下的逻辑,就是根据不同的表结构和记录格式做解析。
重温 Compact/Dynamic 行格式
Dynamic 是 MySQL 默认的行格式,它与 Compact 基本类似,组成结构如下。
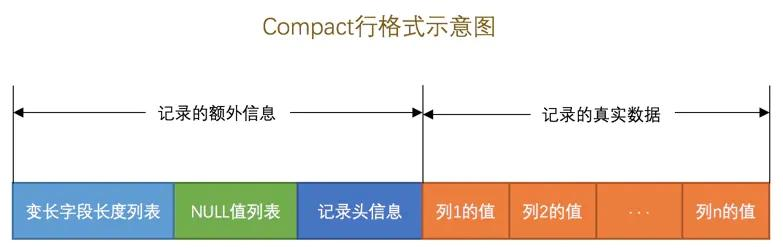
我们用小册子中的例子来做实验。
建表和初始化语句如下。
CREATE TABLE record_format_demo (
c1 VARCHAR(10),
c2 VARCHAR(10) NOT NULL,
c3 CHAR(10),
c4 VARCHAR(10)
) CHARSET=ascii ROW_FORMAT=COMPACT;
INSERT INTO record_format_demo(c1, c2, c3, c4) VALUES('aaaa', 'bbb', 'cc', 'd'), ('eeee', 'fff', NULL, NULL);
这个表没有定义主键,MySQL 会生成一个 6 字节的值作为主键。除此之外,还会增加 6 字节的 transaction_id 和 7 字节的 roll_pointer。因此我们可以在脚本中增加一个行记录的结构体。
typedef struct {
u8 row_id : 48; // 行ID,唯一标识一条记录
u8 trx_id : 48; // 事务ID
u8 roll_pointer : 56 <format=hex>; // 回滚指针
} Row;
然后在前面的 while 循环的 记录头后面增加记录的这个结构体。
// 遍历链表
while(next_rec_rel_pos != supremum_record_pos) {
FSeek(page_start_pos + next_rec_rel_pos - 5); // 往前走五个字节,读取记录头,便于获取下一条记录的相对位置
RecordHeader record_header;
if (record_header.record_type == CONVENTIONAL) {
Row row;
}
next_rec_rel_pos += record_header.next_record;
}
图片蓝色部分背景的就是一行记录的前三个部分,row_id + transaction_id + roll_pointer。
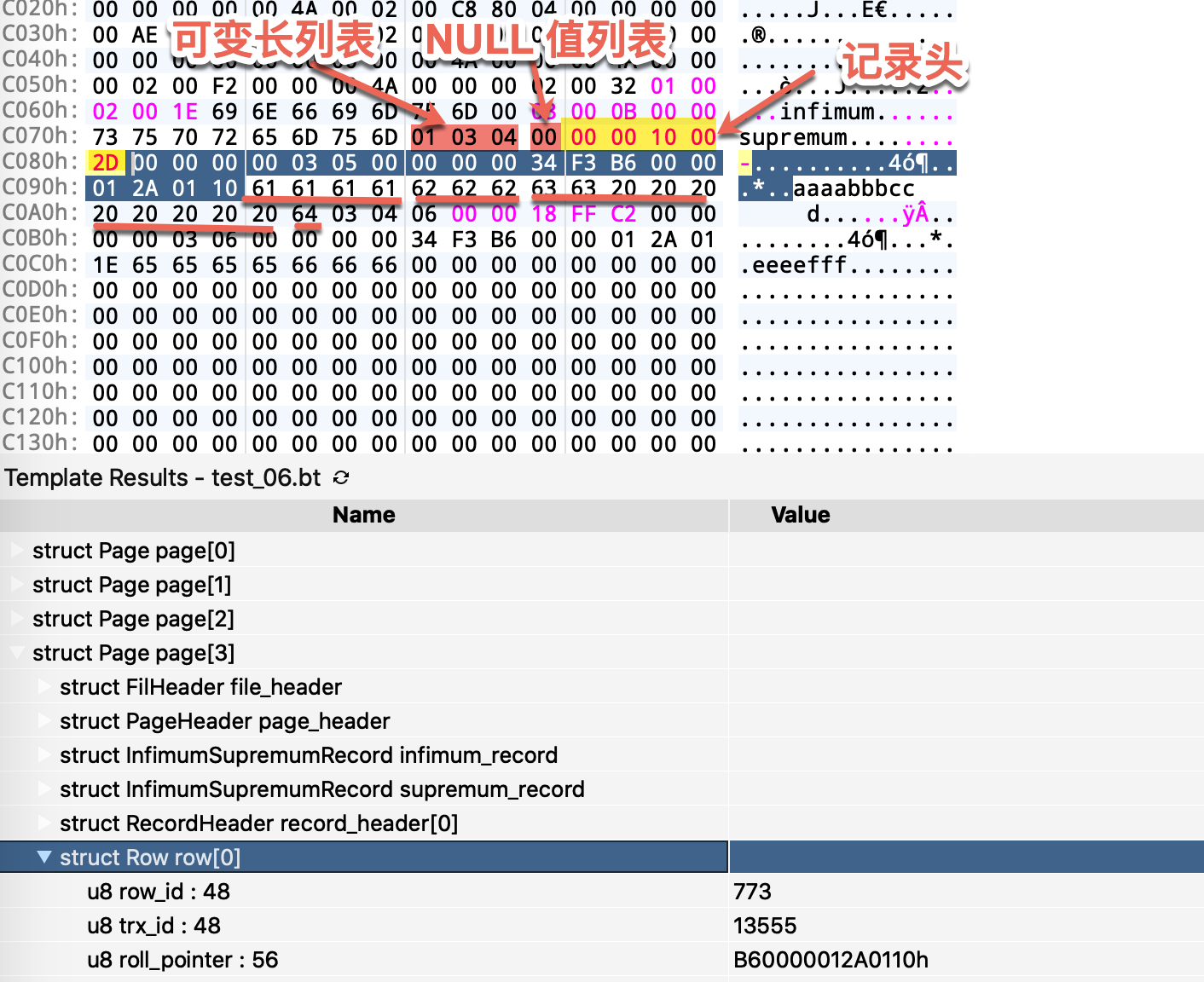
紧随其后的是第一行的 c1、c2、c3、c4 这四个字段真正的值,其中 c3 的类型是 char(10),实际长度小于 10 则后面补空格(0x20),这就是 char 类型的数据,末尾存不进空格的原因。
第一行的可变长字段长度列表为 01 03 04,分别对应 c4、c2、c1,它是根据表字段逆序排列的。c3 字段因为是 char 类型,且表编码是 ASCII,非变长,因此长度是确定的 10 字节,没有必要在变长字段长度列表里记录。然后我们来看 NULL 值列表,因为第一行的所有字段都不为 NULL,所以这个字段为 0。
接下来我们来看第二行数据,
对应的二进制列表如下。

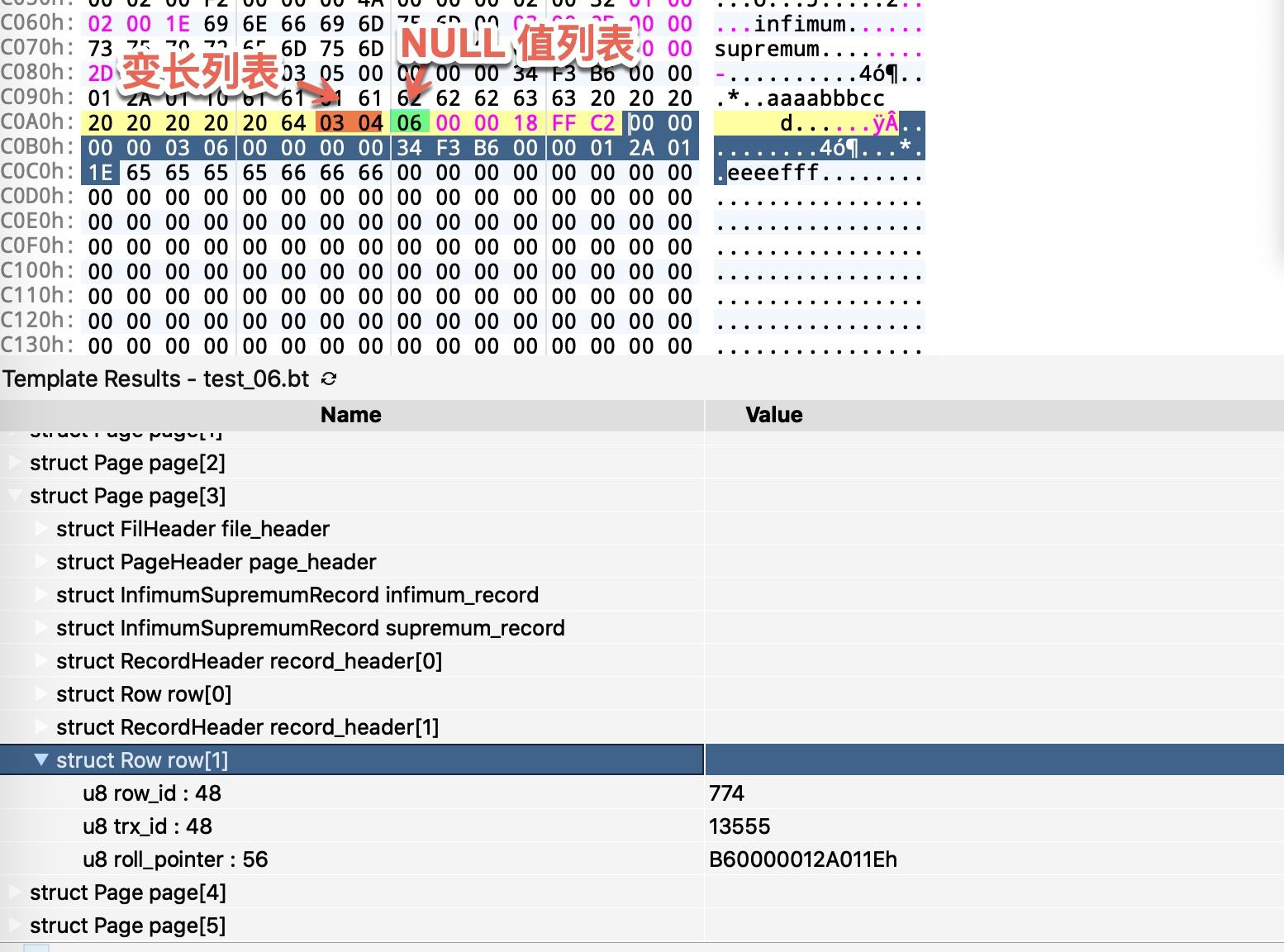
可以看到此时的 c4 字段因为为 NULL,没有必要在变长列表里记录,因此变长列表为 03 04。NULL 列表转为 0x06(00000110),NULL 值列表也是逆序排的,所以它的值为 0110,又因为 c2 定义不为 NULL,011 表示c1 字段不为 NULL,c3、c4 字段为 NULL。
这个例子是在表编码为 ASCII 的情况下产生的。关于 char 类型的数据,如果是在变长编码比如 UTF8 的情况下,在可变长列表中,是否需要记录 char 类型数据实际的长度呢?
我们来试一下,把表编码改为 utf8,插入"一二三四五六七八九十",
CREATE TABLE record_format_demo2 (
c1 VARCHAR(10),
c2 VARCHAR(10) NOT NULL,
c3 CHAR(10),
c4 VARCHAR(10)
) CHARSET=utf8 ROW_FORMAT=COMPACT;
INSERT INTO `record_format_demo2` (`c1`, `c2`, `c3`, `c4`) VALUES
('gggg','hhh','一二三四五六七八九十','j');
对应的文件信息如下。
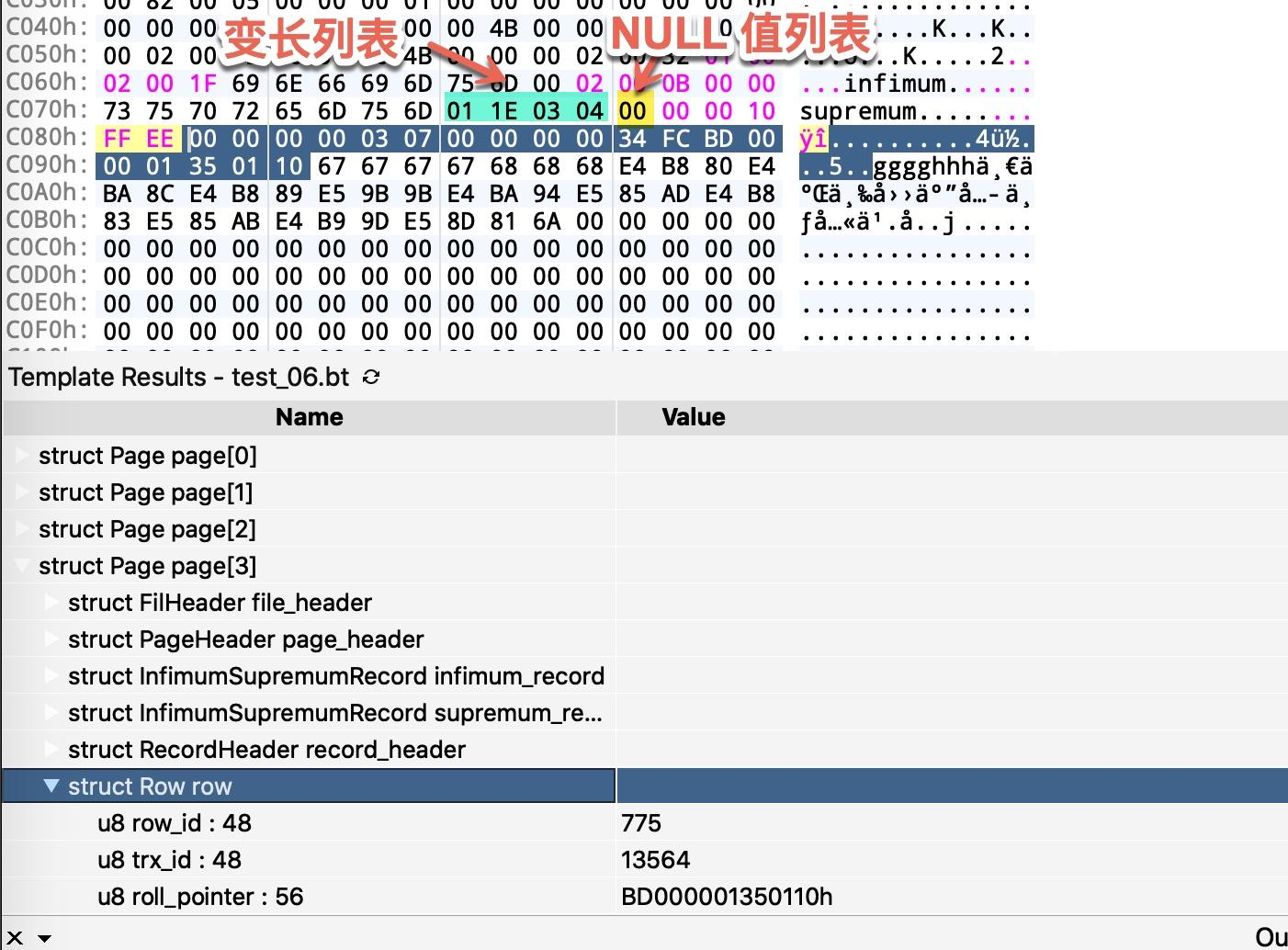
可以看到此时变长列表出现了 4 个,char 类型的 c3 字段也在其中,长度为 30(0x1E),这里的每个汉字都用三个字节来表示。
从存储结构看 varchar 超长行是如何处理的
这里继续沿用了小册中的例子
CREATE TABLE `varchar_size_demo_1` (
`c` varchar(65532) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=ascii ROW_FORMAT=COMPACT;
INSERT INTO varchar_size_demo_1(c) VALUES(REPEAT('a', 65532));
MySQL 一页大小为 16k,这里很显然需要至少 4 页才能存下所有的内容。那这部分数据是如何组织的呢?小册给出的图已经比较清晰的说明了 COMPACT 格式下的页面布局。
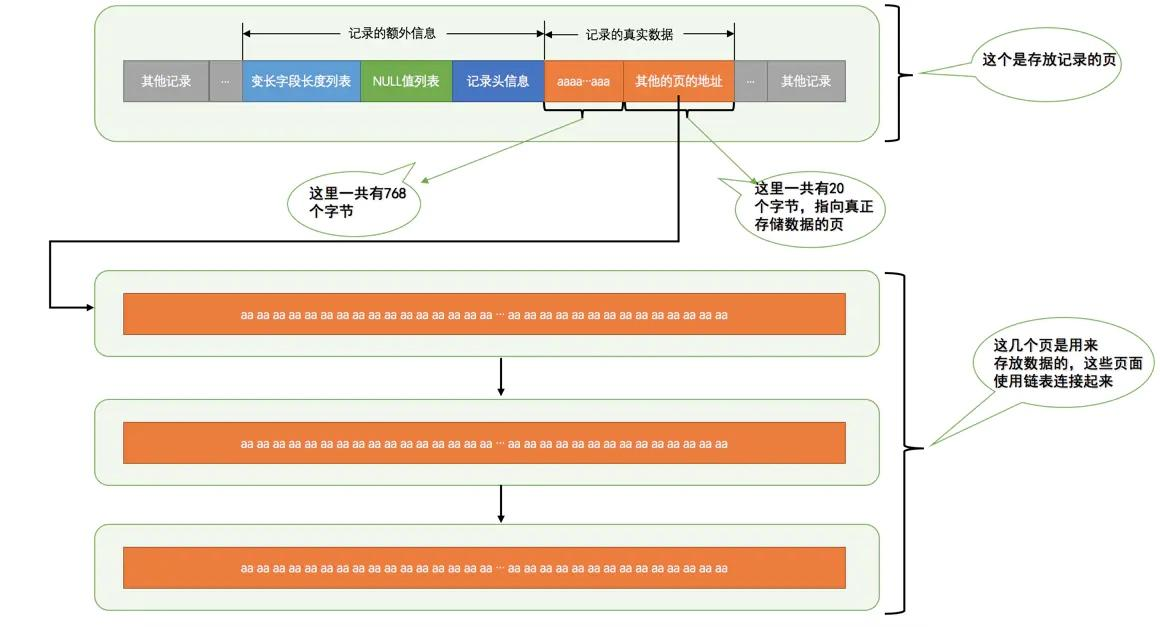
知道了这一结构,我们可以继续定制化针对于这个表的模板。
typedef struct OverflowPagePointer {
u4 space;
u4 page_no; // 页号
u4 page_offset; // 页内偏移量
u4 : 4 * 8; // 空
u4 length; // 剩余长度
};
typedef struct {
u8 row_id : 48; // 行ID,唯一标识一条记录
u8 trx_id : 48; // 事务ID
u8 roll_pointer : 56 <format=hex>; // 回滚指针
char data[768]; // 前 768 字节内容
OverflowPagePointer overflow_page_pointer; // 20 字节的溢出结构体
} Row;
这里没有说的是 20 字节的其它的页的地址,里面存的到底是什么。通过阅读源码,我提取除了这部分的结构,也就是上面的 OverflowPage。
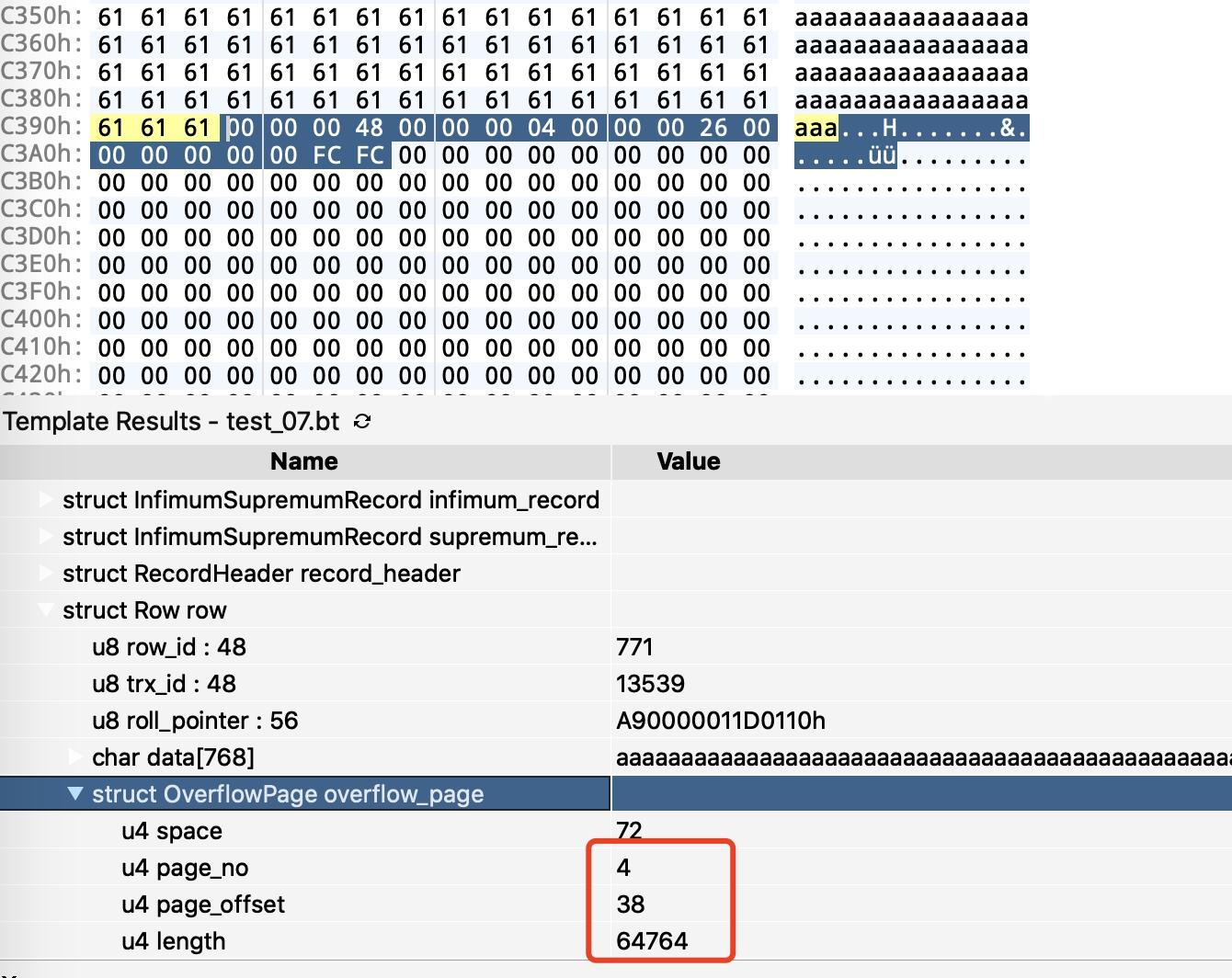
可以看到溢出记录指针指向了页号为 4,偏移量为 38 的 Page 页的内容。我们来看页号为 4 的内容区域
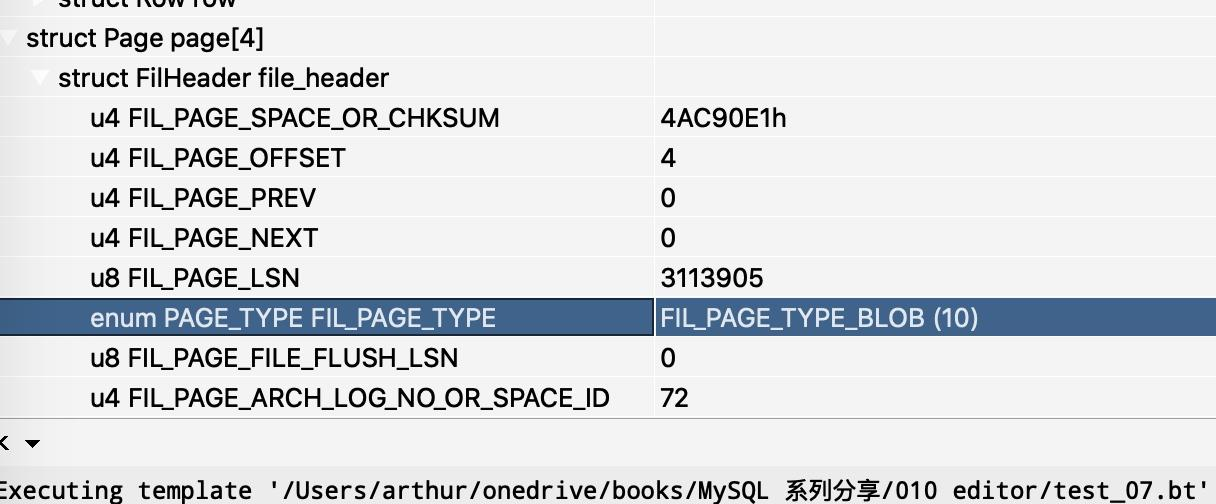
通过 File Header 可以知道,这个 Page 页面的类型为 BLOB 类型。紧随 File Header 之后的是 8 字节的类似于头的信息,前 4 个字节 length 表示当前页面中存储的溢出数据的长度,接下来的 4 字节表示存储溢出数据的下一个页号是什么。基于此,我们可以实现 BLOB 类型的页面的数据格式解析。
BLOB 类型的页面格式由 8 字节的头信息加实际的数据组成,头信息由 4 字节表示的长度信息加 4 字节的下一个 Page 页号组成。
因此我们可以写出来 BLOB 类型的结构体。
typedef struct {
u4 length;
u4 next_page_number;
char data[length];
} Blob;
修改我们的模板脚本,增加 BLOB 类型页面的判断。
if (file_header.FIL_PAGE_TYPE == FIL_PAGE_INDEX) {
PageHeader page_header; // 56 字节的 page header
InfimumSupremumRecord infimum_record; // 13 字节的虚拟最小记录
...
}
} else if (file_header.FIL_PAGE_TYPE == FIL_PAGE_TYPE_BLOB) {
Blob blob;
}
运行脚本得到的结果如下。
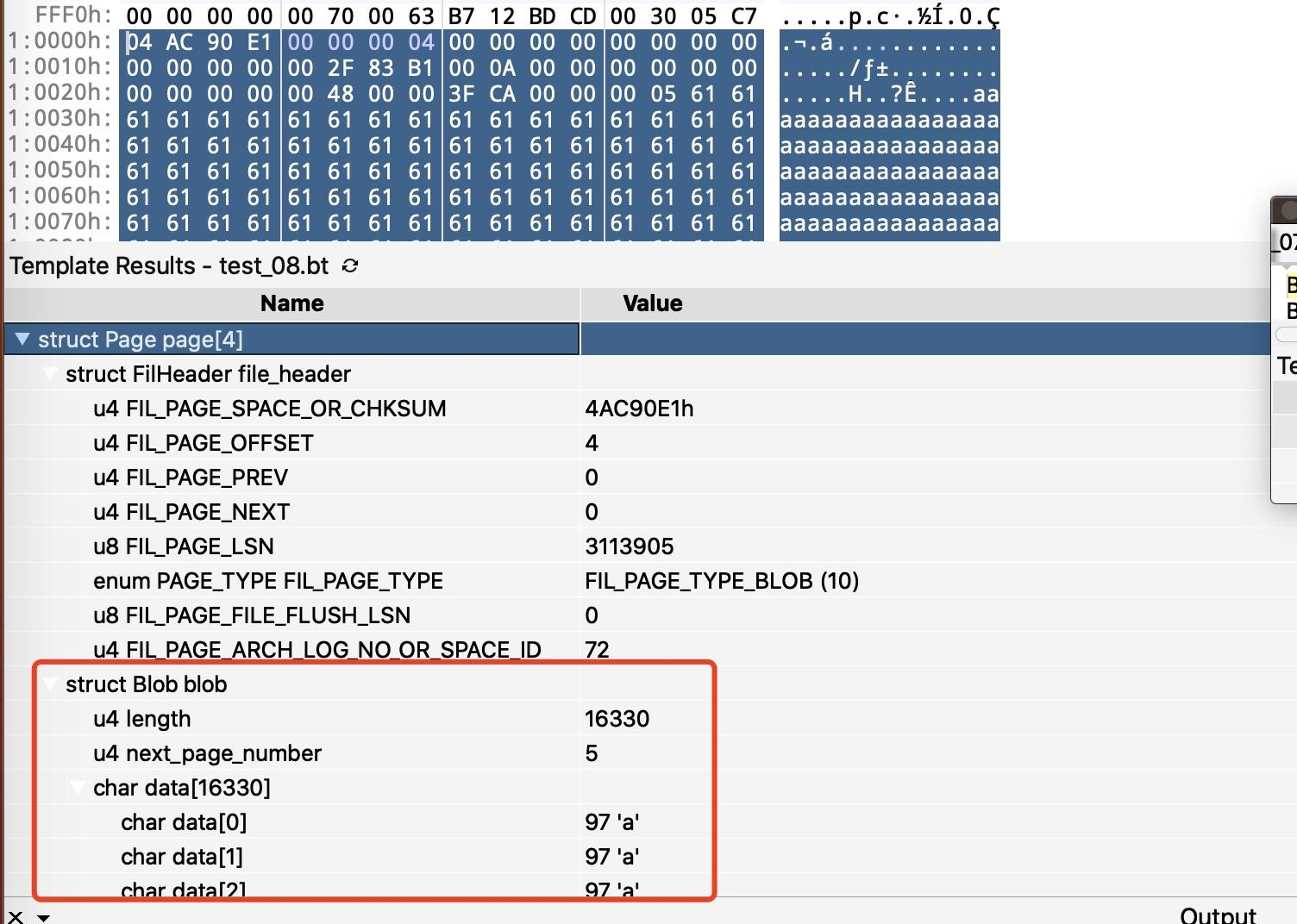
Dynamic 记录与 Compact 行格式类似,它把所有的真实记录都存储到了其它页面中,这里不展开。
从存储结构看看叶子节点与非叶子节点是如何表示的
这里我们创建一个 t2 表,写一个存储过程插入一千行数据。
CREATE TABLE `t2` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_a` (`a`)
) ENGINE=InnoDB;
drop procedure if exists gen_data;
delimiter ;;
create procedure gen_data()
begin
declare i int;
set i = 1;
while(i<=1000) do
insert into t2 values(i, i, i);
set i = i + 1;
end while;
end;;
delimiter ;
call gen_data();
这样表中就存在了从 1~1000 的 1000 行数据。
接下来我们来看这个表的存储结构,运行脚本,首先来看第 3 页(第 0、1、2 页都是系统页,先不管)。

可以看到第 3 页的记录类型为 1(NODE_POINTER),1 表示B+树非叶子节点记录,完整的记录类型如下。
- 0 表示普通记录
- 1 表示B+树非叶子节点记录
- 2 表示最小记录
- 3 表示最大记录
同时从第 3 页的 page_level 值可以看到值为 1,表示是非叶子节点(page_level 为 0)
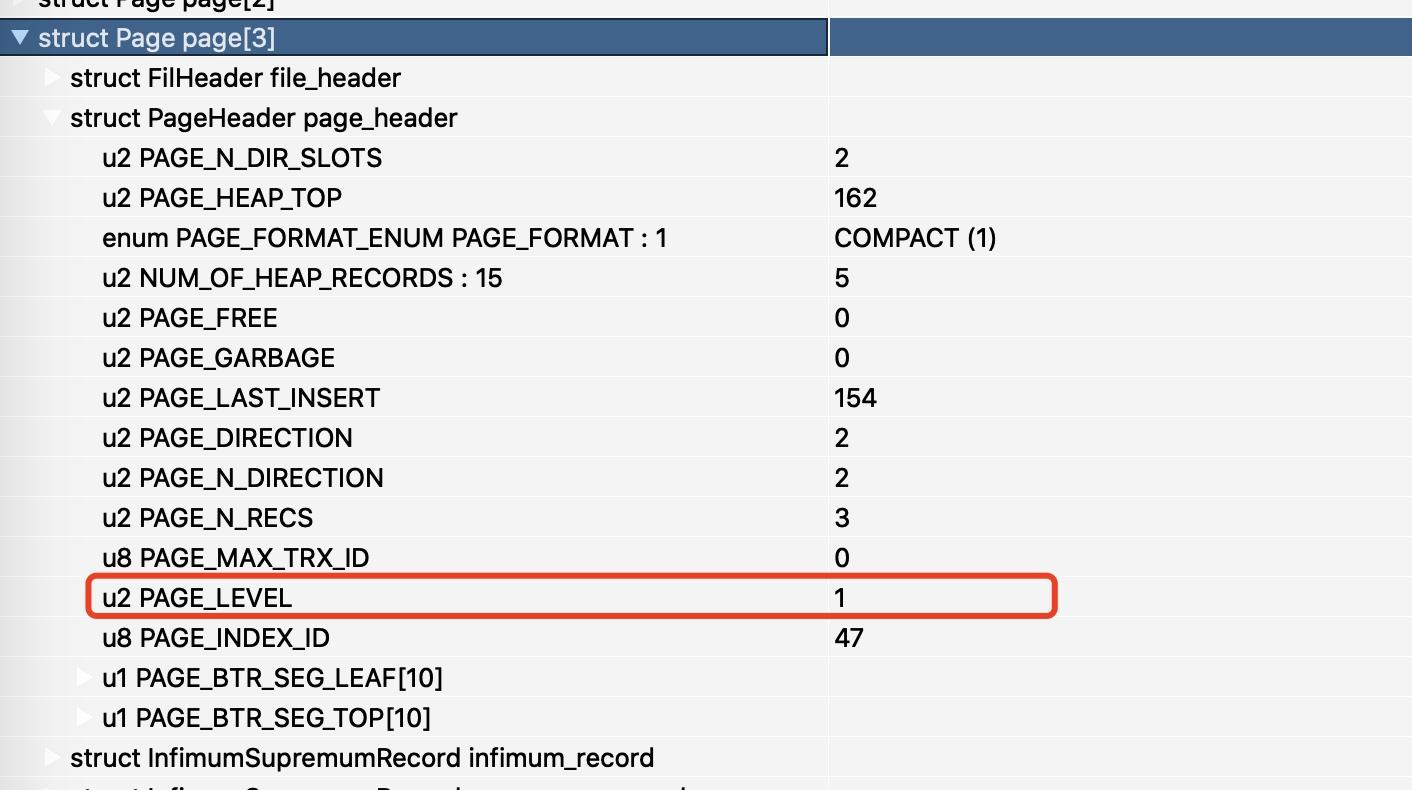
对于 NODE_POINTER 类型的记录,它其实存储的是指向的下一级 LEVEL 页面的最小主键 id 和 页面的 Page 号,定义它的类型如下所示。
typedef struct NonLeafRecord {
u4 min_key_on_child_page<read=read_int>;
u4 child_page_num;
};
// 处理最高位为 1 的情况
string read_int(u4 n) {
string ret;
SPrintf(ret, "%u", n & 0x7FFFFFFF);
return ret;
}
然后在代码里加入 NODE_POINTER 类型的处理逻辑。
while(next_rec_rel_pos != supremum_record_pos) {
FSeek(page_start_pos + next_rec_rel_pos - 5); // 往前走五个字节,读取记录头,便于获取下一条记录的相对位置
RecordHeader record_header;
if (record_header.record_type == CONVENTIONAL) {
Row row;
} else if (record_header.record_type == NODE_POINTER) { // 处理非叶子节点的数据
NonLeafRecord record;
}
next_rec_rel_pos += record_header.next_record;
}
运行后得到的结果如下。
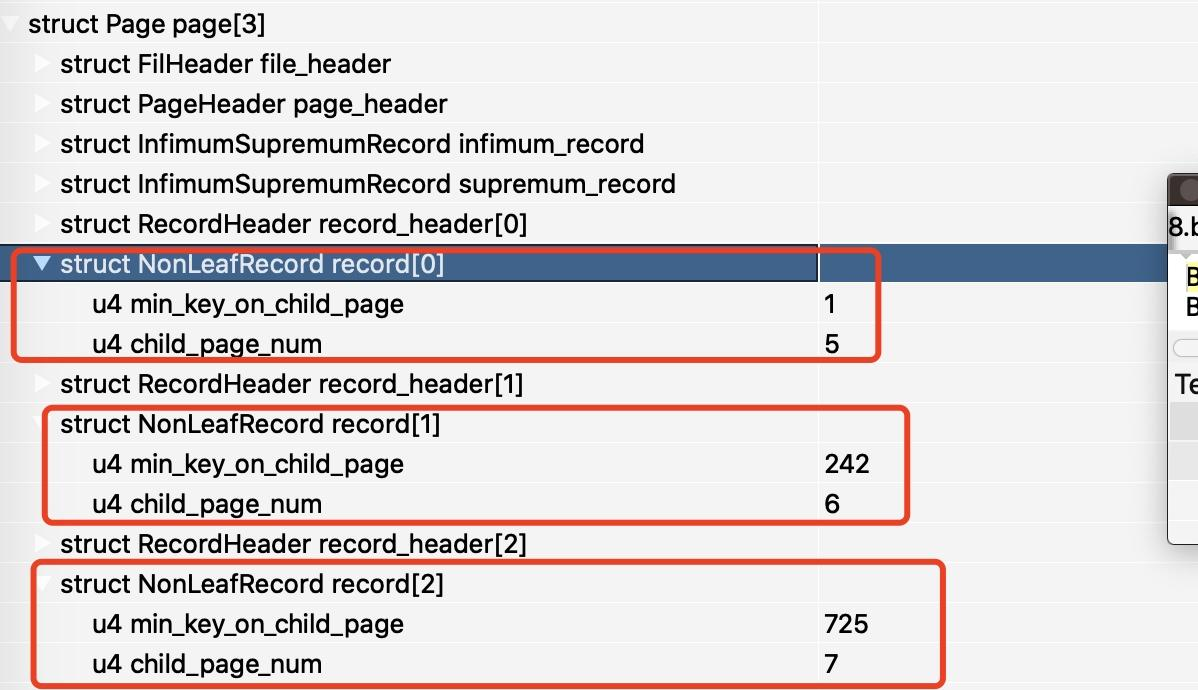
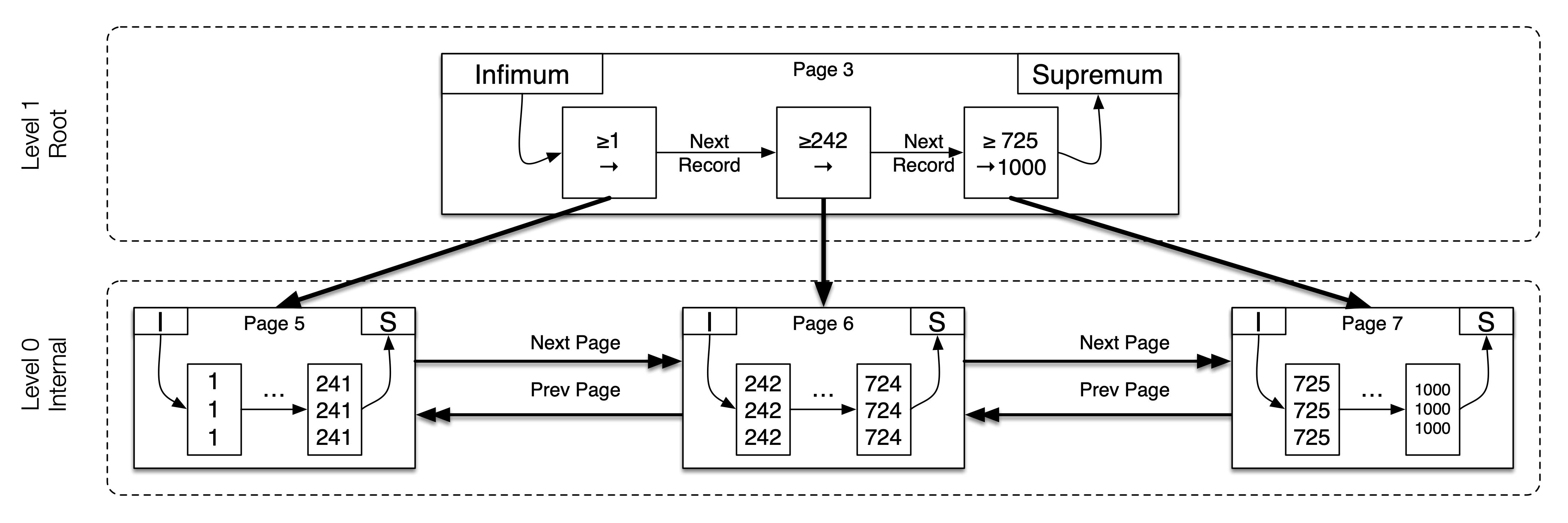
可以看到这里有三个非叶子节点,分别指向了第 5、6、7 页的叶子节点页面。这三个页面的最小主键值分别为 1、242、725。我们用一个图来表示。
其他
这里的模板文件还只是覆盖了 MySQL 文件格式很小的部分,可以作为一个最简单的模板,继续完善扩展支持。文章中用到的所有示例模板代码我已经放到了 github 上 github.com/arthur-zhan… ,有兴趣的同学可以继续完善。


