
线程与栈那些事原创
这篇文章是介绍一下线程与栈相关的话题,文章比较长,主要会聊聊下面这些话题:
- 进程与线程的本质区别,线程与内存共享
- Linux pthread 与 Guard 区域
- Hotspot 线程栈的 Guard 区域实现原理
- 你可能没有怎么听说过的 Yellow-Zone、Red-Zone
- Java StackOverflowError 的实现原理
为了讲清楚线程与栈的关系,我们要从进程和线程之间的关系讲起,接下来开始第一部分。
第一部分:老生常谈之进程线程
网上很多文章都说,线程比较轻量级 lightweight,进程比较重量级,首先我们来看看这两者到底的区别和联系在哪里。
clone 系统调用
在上层看来,进程和线程的区别确实有天壤之别,两者的创建、管理方式都非常不一样。在 linux 内核中,不管是进程还是线程都是使用同一个系统调用 clone,接下来我们先来看看 clone 的使用。为了表述的方便,接下来暂时用进程来表示进程和线程的概念。
clone 函数的函数签名如下。
int clone(int (*fn)(void *),
void *child_stack,
int flags,
void *arg, ...
/* pid_t *ptid, struct user_desc *tls, pid_t *ctid */ );
参数释义如下:
- 第一个参数 fn 表示 clone 生成的子进程会调用 fn 指定的函数,参数由第四个参数 arg 指定
- child_stack 表示生成的子进程的栈空间
- flags 参数非常关键,正是这个参数区分了生成的子进程与父进程如何共享资源(内存、打开文件描述符等)
- 剩下的参数,ptid、tls、ctid 与线程实现有关,这里先不展开
接下来我们来看一个实际的例子,看看 flag 对新生成的「进程」行为的影响。
clone 参数的影响
接下来演示 CLONE_VM 参数对父子进程行为的影响,这段代码当运行时的命令行参数包含 “clone_vm” 时,给 clone 函数的 flags 会增加 CLONE_VM。代码如下:
static int child_func(void *arg) {
char *buf = (char *)arg;
// 修改 buf 内容
strcpy(buf, "hello from child");
return 0;
}
const int STACK_SIZE = 256 * 1024;
int main(int argc, char **argv) {
char *stack = malloc(STACK_SIZE);
int clone_flags = 0;
// 如果第一个参数是 clone_vm,则给 clone_flags 增加 CLONE_VM 标记
if (argc > 1 && !strcmp(argv[1], "clone_vm")) {
clone_flags |= CLONE_VM;
}
char buf[] = "msg from parent";
if (clone(child_func, stack + STACK_SIZE, clone_flags, buf) == -1) {
exit(1);
}
sleep(1);
printf("in parent, buf:\"%s\"\n", buf);
return 0;
}
上面的代码在 clone 调用时,将父进程的 buf 指针传递到 child 进程中,当不带任何参数时,CLONE_VM 标记没有被设置,表示不共享虚拟内存,父子进程的内存完全独立,子进程的内存是父进程内存的拷贝,子进程对 buf 内存的写入只是修改自己的内存副本,父进程看不到这一修改。
编译运行结果如下。
$ ./clone_test
in parent, buf:"msg from parent"
可以看到 child 进程对 buf 的修改,父进程并没有生效。
再来看看运行时增加 clone_vm 参数时结果:
$ ./clone_test clone_vm
in parent, buf:"hello from child"
可以看到这次 child 进程对 buf 修改,父进程生效了。当设置了 CLONE_VM 标记时,父子进程会共享内存,子进程对 buf 内存的修改也会直接影响到父进程。
讲这个例子是为后面介绍进程和线程的区别打下基础,接下来我们来看看进程和线程的本质区别是什么。
进程与 clone
以下面的代码为例。
pid_t gettid() {
return syscall(__NR_gettid);
}
int main() {
pid_t pid;
pid = fork();
if (pid == 0) {
printf("in child, pid: %d, tid:%d\n", getpid(), gettid());
} else {
printf("in parent, pid: %d, tid:%d\n", getpid(), gettid());
}
return 0;
}
使用 strace 运行输出结果如下:
clone(child_stack=NULL,
flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD,
child_tidptr=0x7f75b83b4a10) = 16274
可以看到 fork 创建进程对应 clone 使用的 flags 中唯一需要值得注意的 flag 是 SIGCHLD,当设置这个 flag 以后,子进程退出时,系统会给父进程发送 SIGCHLD 信号,让父进程使用 wait 等函数获取到子进程退出的原因。
可以看到 fork 调用时,父子进程没有共享内存、打开文件等资源,这样契合进程是资源的封装单位这个说法,资源独立是进程的显著特征。接下来我们来看看线程与 clone 的关系。
线程与 clone
这里以一段最简单的 C 代码来看看创建一个线程时,底层到底发生了什么,代码如下。
#include <pthread.h>
#include <unistd.h>
#include <stdio.h>
void *run(void *args) {
sleep(10000);
}
int main() {
pthread_t t1;
pthread_create(&t1, NULL, run, NULL);
pthread_join(t1, NULL);
return 0;
}
使用 gcc 编译上面的代码
gcc -o thread_test thread_test.c -lpthread
然后使用 strace 执行 thread_test,系统调用如下所示。
mmap(NULL, 8392704, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0) = 0x7fefb3986000
clone(child_stack=0x7fefb4185fb0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tidptr=0x7fefb41869d0, tls=0x7fefb4186700, child_tidptr=0x7fefb41869d0) = 12629
mprotect(0x7fefb3986000, 4096, PROT_NONE) = 0
比较重要的是下面这些 flags 参数:
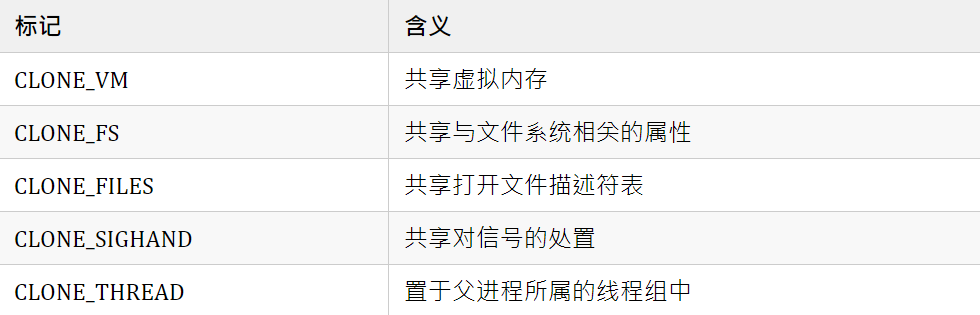
可以看到,线程创建的本质是共享进程的虚拟内存、文件系统属性、打开的文件列表、信号处理,以及将生成的线程加入父进程所属的线程组中。
值得注意的是 mmap 申请的内存大小不是 8M 而是 8M + 4K
8392704 = 8 * 1024 * 1024 + 4096
为什么会多这 4K,我们接下来的第二部分线程与栈中会详细阐述。
第二部分:线程与栈
前面内容中,我们看到通过 strace 查看线程创建过程中的 8M 的栈大小,实际上会分配多 4k 的空间,这是一个很有意思的问题,我们来详细看看。
线程与 Guard 区域
线程的栈是一个比较“奇怪”的产物,一方面线程的栈是线程独有,里面保存了线程运行状态、局部变量、函数调用等信息。另外一方面,从资源管理的角度而言,所有线程的栈都属于进程的内存资源,线程和父进程共享资源,进程中其它线程自然可以修改任意线程的栈内存。
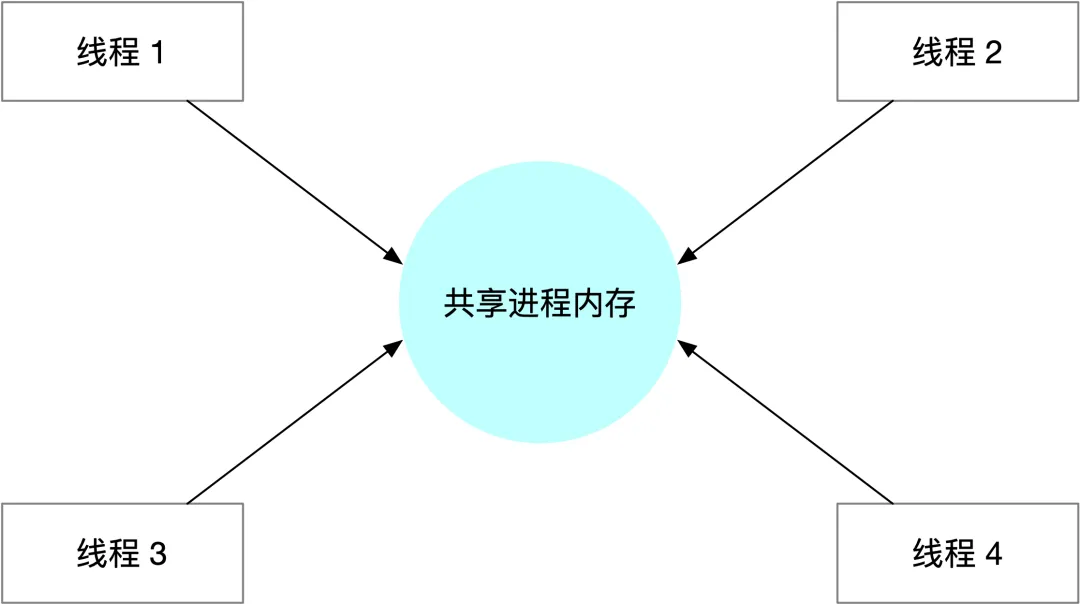
以下面的代码为例,这段代码创建了两个线程 t1、t2,对应的运行函数是 runnable1 和 runnable2。t1 线程将 buf 数组的地址复制给全局指针 p,t1 线程每隔 1s 打印一次 buf 数组的内容,t2 线程每隔 3s 修改一次 p 指针指向地址的内容。
#include <pthread.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
static char *p;
void *runnable1(void *args) {
char buf[10] = {0};
p = buf;
while (1) {
printf("buffer: %s\n", buf);
sleep(1);
}
}
void *runnable2(void *args) {
int index = 0;
while (1) {
if (p) {
strcpy(p, index++ % 2 == 0 ? "say hello" : "say world");
}
sleep(3);
}
}
int main() {
pthread_t t1, t2;
pthread_create(&t1, NULL, runnable1, NULL);
pthread_create(&t2, NULL, runnable2, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
return 0;
}
编译运行上面的代码,结果输出如下
$ ./thread_stack_test
buf:
buf:
buf:
buf: say hello
buf: say hello
buf: say hello
buf: say world
buf: say world
buf: say world
buf: say hello
buf: say hello
可以看到线程 2 直接修改了线程 1 栈中数组的内容。这种行为是 linux 中完全合法,不会报任何错误。如果可以这么随意的访问到其它线程的内容是一个非常危险的事情,比如栈越界,将会造成其它线程的数据错乱。
为了能减缓栈越界带来的影响,操作系统引入了 stack guard 的概念,就是给每个线程栈多分配一页(4k)或多页内存,这片内存不可读、不可写、不可执行,只要访问就会造成段错误。
我们以一个实际的例子来看栈越界,代码如下所示。
static void *thread_illegal_access(void *arg) {
sleep(1);
char p[1];
int i;
for (i = 0; i < 1024; ++i) {
printf("[%d] access address: %p\n", i, &p[i * 1024]);
p[i * 1024] = 'a';
}
}
static void *thread_nothing(void *arg) {
sleep(1000);
return NULL;
}
int main() {
pthread_t t1;
pthread_t t2;
pthread_create(&t1, NULL, thread_nothing, NULL);
pthread_create(&t2, NULL, thread_illegal_access, NULL);
char str[100];
sprintf(str, "cat /proc/%d/maps > proc_map.txt", getpid());
system(str);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
return 0;
}
编译上面的 c 文件,使用 strace 执行,部分系统调用如下所示。
// thread 1
mmap(NULL, 8392704,
PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK,
-1, 0) = 0x7f228d615000
mprotect(0x7f228d615000, 4096, PROT_NONE) = 0
clone(child_stack=0x7f228de14fb0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tidptr=0x7f228de159d0, tls=0x7f228de15700, child_tidptr=0x7f228de159d0) = 9696
// thread 2
mmap(NULL, 8392704,
PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0) = 0x7f228ce14000
mprotect(0x7f228ce14000, 4096, PROT_NONE) = 0
clone(child_stack=0x7f228d613fb0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tidptr=0x7f228d6149d0, tls=0x7f228d614700, child_tidptr=0x7f228d6149d0) = 9697
在 linux 中,一个线程栈的默认大小是 8M(8388608),但是这里 mmap 分配的内存块大小却是 8392704(8M+4k),这里多出来的 4k 就是 stack guard 大小。
分配了 8M+4k 的内存以后,随即使用 mprotect 将刚分配的内存块的 4k 地址的权限改为了 PROT_NONE, PROT_NONE 表示拒绝所有访问,不可读、不可写、不可执行。第二个线程创建的过程一模一样,这里不再赘述,两个线程的内存布局如下所示。

$ ./thread_test
[0] access address: 0x7ffff6feef0b
[1] access address: 0x7ffff6fef30b
[2] access address: 0x7ffff6fef70b
[3] access address: 0x7ffff6fefb0b
[4] access address: 0x7ffff6feff0b
[5] access address: 0x7ffff6ff030b
[1] 18133 segmentation fault ./thread_test
我们可以看到最后 access 导致段错误的地址是 0x7ffff6ff030b,这个地址正好位于线程 1 的 guard 区域内。最后一个合法的范围还处于 t2 的线程栈的合法区域中,如下所示。

Java 线程栈溢出是如何处理的
前面介绍过,Linux 的线程通过 4k 的 Guard 区域实现了栈溢出的简单预防,只要读写 Guard 区域就会出现段错误。那有没有想过 Java 是如何处理栈溢出的呢?
Java 线程的栈溢出时,进程不会退出,StackOverflowError 异常还可以被捕获,程序可以继续运行,以下面的代码为例。
public class ThreadStackTest0 {
private static void foo(int i) {
foo(i + 1);
}
public static void main(String[] args) throws IOException {
System.out.println("in main");
new Thread(new Runnable() {
@Override
public void run() {
foo(0);
}
}).start();
System.in.read();
}
}
编译运行上面的代码,可以看到
$ javac ThreadStackTest0.java; java -cp . ThreadStackTest0
in main
Exception in thread "Thread-0" java.lang.StackOverflowError
at ThreadStackTest0.foo(ThreadStackTest0.java:8)
at ThreadStackTest0.foo(ThreadStackTest0.java:8)
// ...
首先解决第一个疑惑,Java 的普通线程有没有 Linux 原生线程的那种 4k 的 Guard 区域呢?
首先来说答案,答案是没有的。Hotspot 源码中创建线程的代码在 os_linux.cpp 中,
bool os::create_thread(Thread* thread, ThreadType thr_type, size_t stack_size) {
// ...
// glibc guard page
pthread_attr_setguardsize(&attr, os::Linux::default_guard_size(thr_type));
// ...
}
guard 区域的大小是由 os::Linux::default_guard_size 这个方法确定的,这个方法的内部实现比较简单,判断线程的类型是不是普通的 Java 线程,如果是的话,guard 的大小设置为 0,如果不是则设置为 4k。
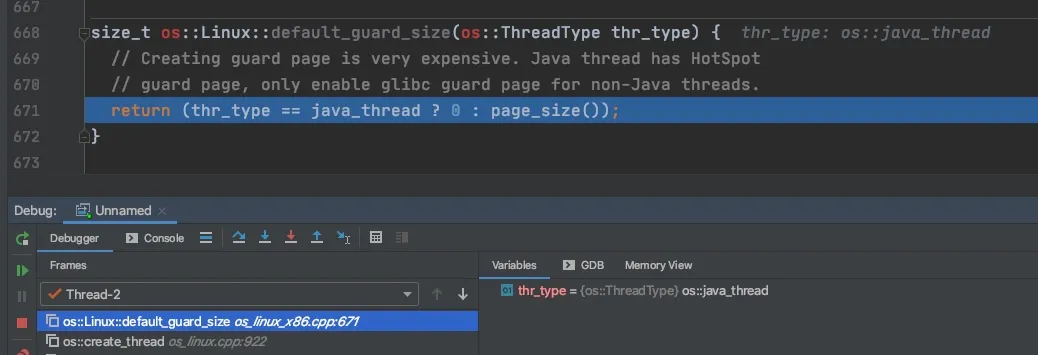
什么是 Java 的普通线程呢?除了用户手动 new Thread() 方式创建的 java 线程,其实还有不少 JVM 运行需要的额外的辅助线程,比如 GC 线程、编译线程、watcher 线程等。从源码调试的结果可以看到,对于 Java 线程,guard 区域大小被设置为 0,其他类型的线程都被设置为默认的 4k。
不要高兴的太早,没有 Linux 原生线程标准的 guard 区域,不代表 Java 线程没有自己实现。实际上 Hotspot 不光自己接管了 Guard 区域,它还实现了两个,一个叫 Yellow Zone,一个叫 Red Zone,如下所示。
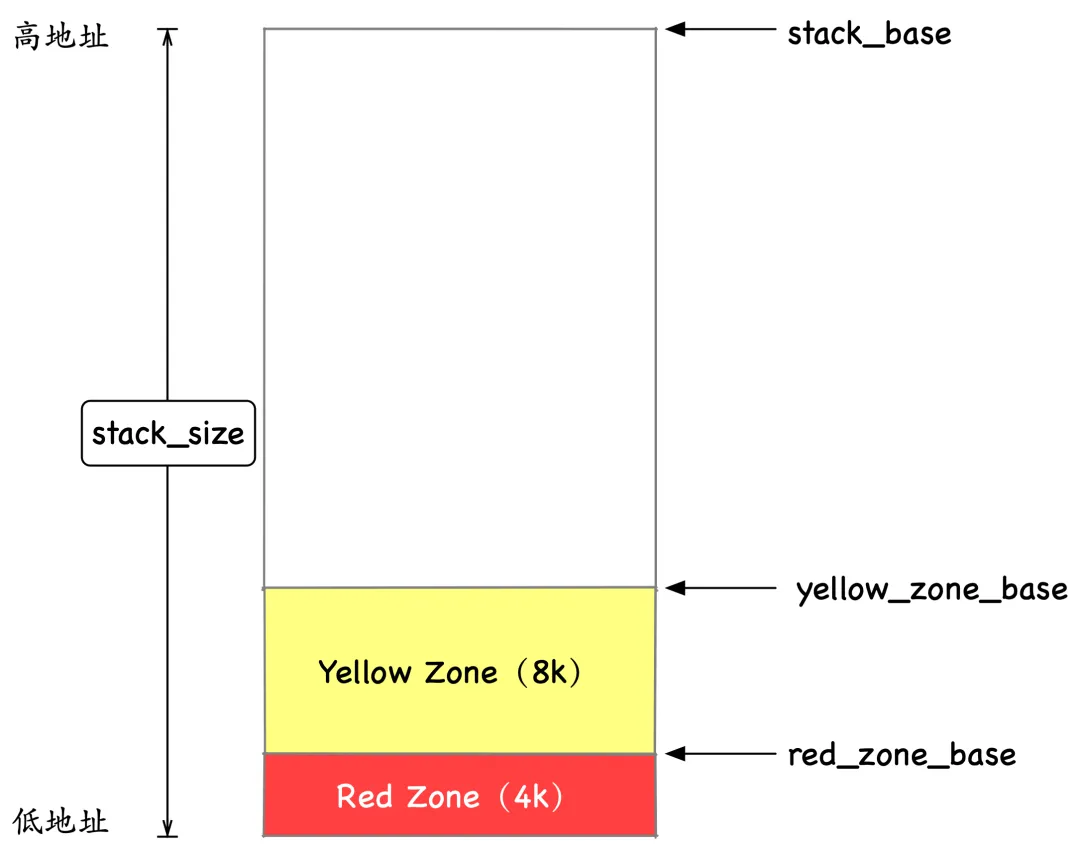
其中 Yellow Zone 的默认大小为 8k,可以通过 -XX:StackRedPages 来指定,Red Zone 的默认大小为 4k,可以通过 -XX:StackRedPages 来指定。这 12k 的权限都是 PROT_NONE,也就是不可读不可写不可执行,读写这一块区域都会触发 Segmentation Fault(SIGSEGV),JVM 为了能自己处理栈溢出异常,它处理了 SIGSEGV 这个信号。
接下来介绍一下这两块区域:
- Yellow zone:这一块区域是用来处理可恢复的栈溢出的,当栈溢出发生在这一块区域时,会把这 8k 的内存区域的权限改为可读可写,随后 JVM 会抛出 StackOverflowError 异常,StackOverflowError 这个异常应用层可以被捕获进行处理。当异常抛出处理完以后,这 8k 内存区域的权限又会恢复为不可读、不可写、不可执行的状态。
- Red zone:这一块的区域是用来处理不可恢复的栈溢出的,算是线程栈最后的防线了。这个区域的栈溢出,JVM 会视为致命错误,进程会退出并生成 hs_err_pid.log 文件。当栈溢出在这个区域时,会首先把这 4k 的权限改为可读可写,以便留一些栈空间生成 hs_err_pid.log 文件。
完整的代码见 os_linux_x86.cpp,如下所示。
extern "C" JNIEXPORT int
JVM_handle_linux_signal(int sig, siginfo_t* info, void* ucVoid, int abort_if_unrecognized) {
// Handle ALL stack overflow variations here
if (sig == SIGSEGV) {
address addr = (address) info->si_addr;
// 检查发生段错误的地址是不是在栈内存的有效范围内 [stack_base-stack_size, stack_base]
if (addr < thread->stack_base() &&
addr >= thread->stack_base() - thread->stack_size()) {
// stack overflow
// 发生段错误的地址处于 yellow 区域
if (thread->in_stack_yellow_zone(addr)) {
// 先把 yellow zone 的 8k 权限改为可读可写,以便调用抛出 STACK_OVERFLOW 异常
thread->disable_stack_yellow_zone();
if (thread->thread_state() == _thread_in_Java) {
// Throw a stack overflow exception. Guard pages will be reenabled
// while unwinding the stack.
stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::STACK_OVERFLOW);
} else {
// Thread was in the vm or native code. Return and try to finish.
return 1;
}
} else if (thread->in_stack_red_zone(addr)) { // 如果地址在 red zone
// Fatal red zone violation. Disable the guard pages and fall through
// to handle_unexpected_exception way down below.
// 先 disable 掉 red zone,把权限改为可读可写,方便留出 4k 的栈给生成 hs_err_pid.log 文件的代码使用
thread->disable_stack_red_zone();
tty->print_raw_cr("An irrecoverable stack overflow has occurred.");
// This is a likely cause, but hard to verify. Let's just print
// it as a hint.
tty->print_raw_cr("Please check if any of your loaded .so files has "
"enabled executable stack (see man page execstack(8))");
} else {
}
}
}
Java 线程栈的大小最小是多少?
这是一个比较有意思的问题,之前也没有怎么多想过,只知道默认的栈大小为 1M,那我们随便试一下:

可以看到在我的 64 位 Centos7 系统上,这个值为栈大小最小要指定 228k,这个值怎么来的呢?我们来看看源码。
os::Linux::min_stack_allowed = MAX2(os::Linux::min_stack_allowed,
(size_t)(StackYellowPages+StackRedPages+StackShadowPages) * Linux::page_size() +
(2*BytesPerWord COMPILER2_PRESENT(+1)) * Linux::vm_default_page_size());
其中 MAX2 函数表示取两个入参的最大值,os::Linux::min_stack_allowed 的值为 64k,StackYellowPages=2,StackRedPages=1,StackShadowPages=20,Linux::page_size() 的值为 4k,BytesPerWord=8,Linux::vm_default_page_size() 的值为 8k。
min_stack_allowed = max(64k, (2 + 1 + 20) * 4k + (2 * 8 + 1) * 8k)
= max(64k, 228k) = 228k
在 Mac 上 Xss 的最小值为 160k,它的计算规则有一点不太一样,源码如下:
os::Bsd::min_stack_allowed = MAX2(os::Bsd::min_stack_allowed,
(size_t)(StackYellowPages+StackRedPages+StackShadowPages+
2*BytesPerWord COMPILER2_PRESENT(+1)) * Bsd::page_size());
计算的过程也就是:
min_stack_allowed = (2 + 1 + 20 + 16 + 1) * 4k = 160k
小结
这篇文章希望你能够了解到下面这些知识:
- 进程与线程的生成,底层都是由 clone 系统调用生成
- 进程与线程的一大区别在于进程拥有各自独立的进程资源,线程则是共享进程的资源
- linux 线程栈的默认大小为 8M,除了线程栈的内存,每个线程还会额外多 4k 的 guard 区域防止栈溢出
- JHotspot 的普通线程的 guard 区域大小为 0,不过自己接管了 Guard 区域的实现
- Hotspot 通过 Yellow-Zone、Red-Zone 这两个区域和自定义 SIGSEGV 信号的处理实现了栈溢出的处理
- JVM 的 XSS 最小值与平台相关,具体的算法可以参考上面的内容

