
那些年你误会的Linux DMA(关于Linux DMA ZONE和API最透彻的一篇)原创
创作目的
互联网、Linux内核书籍上充满了各种关于Linux DMA ZONE和dma_alloc_coherent、dma_map_single等的各种讲解,由于很多童鞋缺乏自身独立的思考,人云亦云,对这些概念形成了很多错误的理解。本文的目的在于彻底澄清这些误解。
当你发现本文内容与baidu到的内容不一致的时候,以本文内容为准。
1.DMA ZONE的大小是16MB?
这个答案在32位X86计算机的条件下是成立的,但是在其他的绝大多数情况下都不成立。
首先我们要理解DMA ZONE产生的历史原因是什么。DMA可以直接在内存和外设之间进行数据搬移,对于内存的存取来讲,它和CPU一样,是一个访问master,可以直接访问内存。
DMA ZONE产生的本质原因是:不一定所有的DMA都可以访问到所有的内存,这本质上是硬件的设计限制。
在32位X86计算机的条件下,ISA实际只可以访问16MB以下的内存。那么ISA上面假设有个网卡,要DMA,超过16MB以上的内存,它根本就访问不到。所以Linux内核干脆简单一点,把16MB砍一刀,这一刀以下的内存单独管理。如果ISA的驱动要申请DMA buffer,你带一个GFP_DMA标记来表明你想从这个区域申请,我保证申请的内存你是可以访问的。
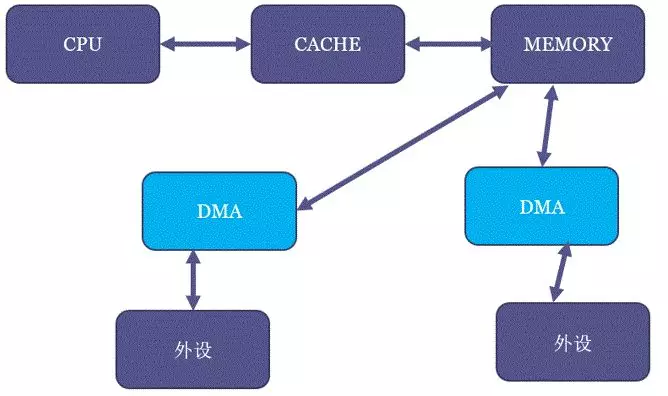
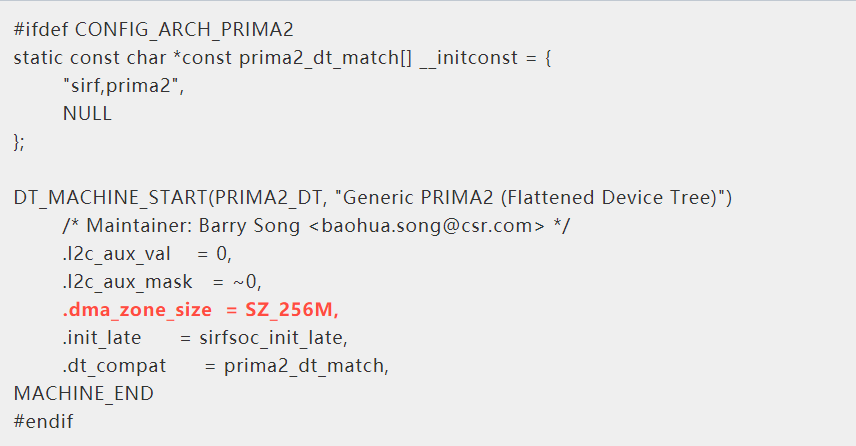
DMA ZONE的大小,以及DMA ZONE要不要存在,都取决于你实际的硬件是什么。比如我在CSR工作的时候,CSR的primaII芯片,尽管除SD MMC控制器以外的所有的DMA都可以访问整个4GB内存,但MMC控制器的DMA只能访问256MB,我们就把primaII对应Linux的DMA ZONE设为了256MB,详见内核:arch/arm/mach-prima2/common.c
不过CSR这个公司由于早前已经被Q记收购,已经不再存在,一起幻灭的,还有当年挂在汽车前窗上的导航仪。这不禁让我想起我们当年在ADI arch/blackfin里面写的代码,也渐渐快几乎没有人用了一样。
一代人的芳华已逝,面目全非,重逢虽然谈笑如故,可不难看出岁月给每个人带来的改变。原谅我不愿让你们看到我们老去的样子,就让代码,留住我们芬芳的年华吧…
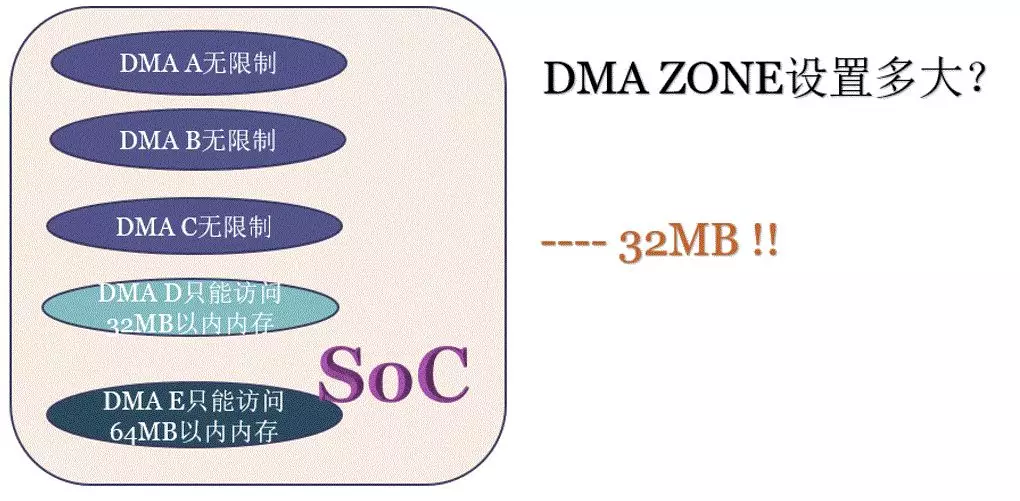
下面我们架空历史,假设有一个如下的芯片,里面有5个DMA,A、B、C都可以访问所有内存,D只能访问32MB,而E只能访问64MB,你觉得Linux的设计者会把DMA ZONE设置为多大?当然是32MB,因为如果设置为64MB,D从DMA ZONE申请的内存就可能位于32MB-64MB之间,申请了它也访问不了。
由于现如今绝大多少的SoC都很牛逼,似乎DMA都没有什么缺陷了,根本就不太可能给我们机会指定DMA ZONE大小装逼了,那个这个ZONE就不太需要存在了。反正任何DMA在任何地方申请的内存,这个DMA都可以存取到。
2.DMA ZONE的内存只能做DMA吗?
DMA ZONE的内存做什么都可以。DMA ZONE的作用是让有缺陷的DMA对应的外设驱动申请DMA buffer的时候从这个区域申请而已,但是它不是专有的。其他所有人的内存(包括应用程序和内核)也可以来自这个区域。
3.dma_alloc_coherent()申请的内存来自DMA ZONE?
dma_alloc_coherent()申请的内存来自于哪里,不是因为它的名字前面带了个dma_就来自DMA ZONE的,本质上取决于对应的DMA硬件是谁。看代码:
对于primaII而言,绝大多少的外设的dma_coherent_mask都设置为0XffffffffULL(4GB内存全覆盖),但是SD那个则设置为256MB-1对应的数字。这样当primaII的SD驱动调用dma_alloc_coherent()的时候,GFP_DMA标记被设置,以指挥内核从DMA ZONE申请内存。但是,其他的外设,mask覆盖了整个4GB,调用dma_alloc_coherent()获得的内存就不需要一定是来自DMA ZONE。

4.dma_alloc_coherent()申请的内存是非cache的吗?
要解答这个问题,首先要理解什么叫cache coherent。还是继续看这个DMA的图,我们假设MEM里面有一块红色的区域,并且CPU读过它,于是红色区域也进CACHE:
但是,假设现在DMA把外设的一个白色搬移到了内存原本红色的位置:
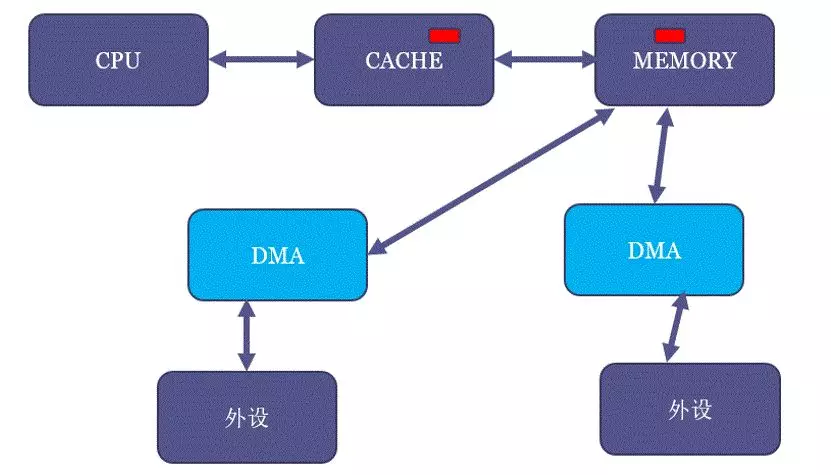
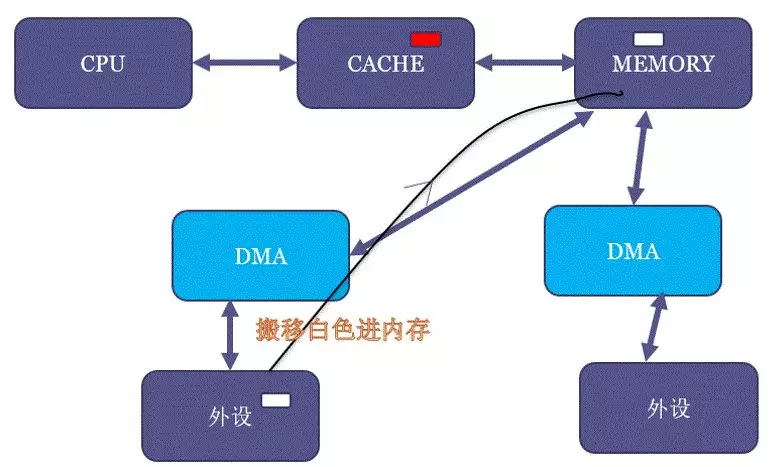
这个时候,内存虽然白了,CPU读到的却还是红色,因为CACHE命中了,这就出现了cache的不coherent。
当然,如果是CPU写数据到内存,它也只是先写进cache(不一定进了内存),这个时候如果做一个内存到外设的DMA操作,外设可能就得到错误的内存里面的老数据。
所以cache coherent的最简单方法,自然是让CPU访问DMA buffer的时候也不带cache。事实上,缺省情况下,dma_alloc_coherent()申请的内存缺省是进行uncache配置的。
但是,由于现代SoC特别强,这样有一些SoC里面可以用硬件做CPU和外设的cache coherence,如图中的cache coherent interconnect:
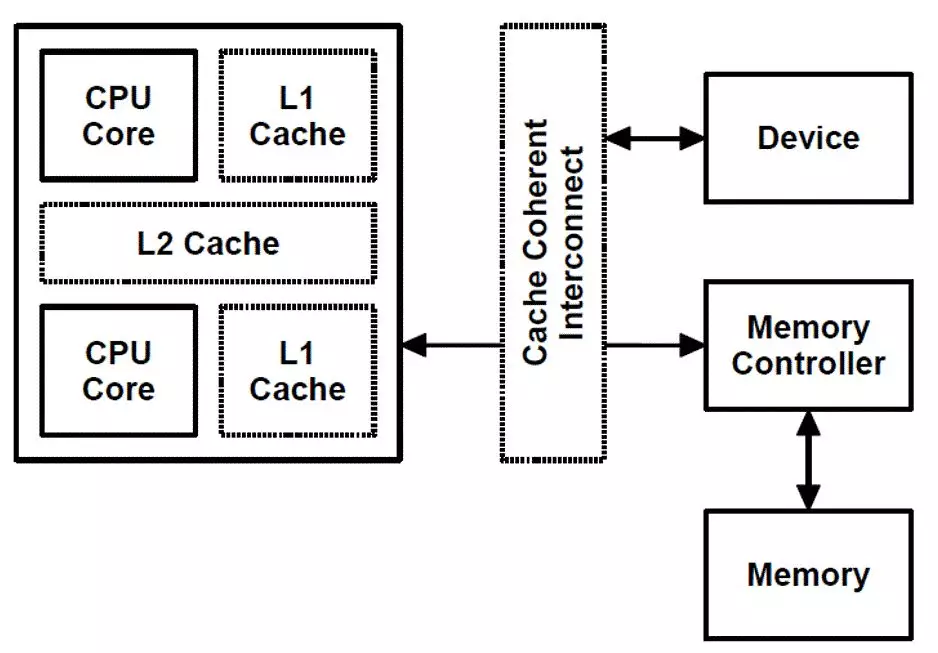
这些SoC的厂商就可以把内核的通用实现overwrite掉,变成dma_alloc_coherent()申请的内存也是可以带cache的。这部分还是让大牛Arnd Bergmann童鞋来解释:

当我grep内核源代码的时候,我发现部分SoC确实是这样实现的:

5.dma_alloc_coherent()申请的内存一定是物理连续的吗?
绝大多数的SoC目前都支持和使用CMA技术,并且多数情况下,DMA coherent APIs以CMA区域为申请的后端,这个时候,dma alloc coherent本质上用__alloc_from_contiguous()从CMA区域获取内存,申请出来的内存显然是物理连续的。这一点,在设备树dts里面就可以轻松配置,要么配置一个自己特定的cma区域,要么从“linux,cma-default”指定的缺省的CMA池子里面取内存:
reserved-memory {
#address-cells = <1>;
#size-cells = <1>;
ranges;
/* global autoconfigured region for contiguous allocations */
linux,cma {
compatible = "shared-dma-pool";
reusable;
size = <0x4000000>;
alignment = <0x2000>;
linux,cma-default;
};
display_reserved: framebuffer@78000000 {
reg = <0x78000000 0x800000>;
};
multimedia_reserved: multimedia@77000000 {
compatible = "acme,multimedia-memory";
reg = <0x77000000 0x4000000>;
};
};
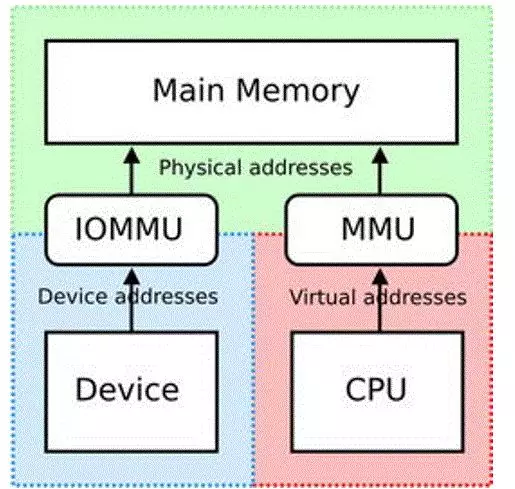
但是,如果IOMMU存在(ARM里面叫SMMU)的话,DMA完全可以访问非连续的内存,并且把物理上不连续的内存,用IOMMU进行重新映射为I/O virtual address (IOVA):
所以dma_alloc_coherent()这个API只是一个前端的界面,它的内存究竟从哪里来,究竟要不要连续,带不带cache,都完全是因人而异的。
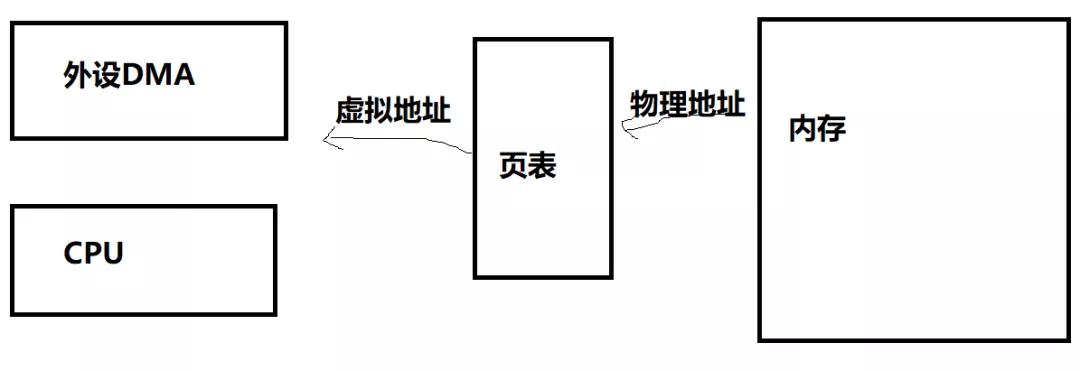
6.可以直接在进程的虚拟地址空间进行DMA操作吗?
在支持SVA(Shared Virtual Addressing)的场景下,外设可以和CPU共享相同的虚拟地址,这样外设就可以直接共享进程的地址空间:
相关文章:Shared Virtual Addressing for the IOMMU
https://lwn.net/Articles/747230/
当然,它要求硬件的三个支持(这里面每个要求都是必须的,我认为最最最重要的是IOMMU的page table和CPU MMU的page table格式是兼容的):

试想,你在用户空间的一片内存:
*void p = malloc(1MB);
当你要对这片内存进行压缩运算的时候,你的硬件里面有个压缩加速器,你直接把p这个地址告诉它,它就可以帮你进行压缩了,这样的生活是多么的惬意?
我觉得最最牛逼的是:外设共享了你写的app的进程的地址空间,外设直接融入你的应用成为它的一部分,帮应用完成部分功能(当然最主要是加速功能)。它甚至让前面的dma_alloc_coherent等待这样的专门申请一致性DMA缓冲区的API都那么的多余,你也不需要凡事设计到DMA操作的时候,都进行内核的大量操作。CPU和外设的绝对界线被打开。
同时我希望你不要把DMA狭义地理解为内存的拷贝,比如从内存里面往网卡里面搬移这样的事情。本文所述的DMA,更多地具备广义DMA的概念,就是外设可以直接访问内存。进而我也希望你不要把本文所说的外设想象成狭义的就是USB、网卡、I2C这种,本文所述CPU眼里的外设本身也可能是一个带运算能力的加速器、video处理器、GPU等。
如果外设是个加速器,利用SVA,它可以访问到进程虚拟地址空间的数据进行运算,减少了很多不必要的互动,可以极大地提升系统性能。
总结
最后总结一句,千万不要被教科书和各种网上的资料懵逼了双眼,你一定要真正自己探索和搞清楚事情的本源。
本文转自:Linux阅码场,作者:宋宝华



