
Linux多线程应用性能分析原创
如今CPU的核心数越来越多, 在2019年你可以轻易买到超过50个核心的x86服务器CPU,一个中端台式机拥有8个执行线程也没什么好奇怪的。问题是我们怎样找到工作负载来“喂饱”那些相对饥饿的核。
到目前为止,我的博客中的大多数文章都还是聚焦在单核应用的性能上,完全忽略了多线程应用这一方面。所以,我决定写一篇面向初学者的文章,来叙述一下如何快速分析多线程应用的性能。当然了,一篇文章中不可能包含所有的细节,这里我只想简单介绍一下对多线程应用的性能分析应该如何落地,并提供测试清单和可以使用的工具集。我的博客上肯定还会有更多相关内容,敬请期待。
本文是一个系列文章的一部分,全系列包括:
-
多线程应用程序的性能分析 (本文).
-
如何在多线程应用程序中找到开销过大的锁.
-
使用Data Address Profiling检测伪共享.
我的文章通常喜欢提供一些案例,本文也不例外。首先介绍一下我们将要使用的benchmark。
Benchmark测试
为了更好地说明问题,我觉得在选择benchmark时应该添加一些约束:1
-
应该显式地使用
pthread/std::thread库来实现并行(而不是使用OpenMP隐式多线程库)。 -
性能不能随着线程数量的增加而同等地提高。任务不会被均匀地拆分到每个线程上执行。
-
自由,开源。
我选择了 h264dec benchmark (可以在Starbench parallel benchmark suite中获取),它可以解码原生H.264视频并且使用pthread库管理线程。
可以像这样运行 h264dec benchmark:
$ ./h264dec -i park_joy_2160p.h264 -t <number of threads> -o output.file
该benchmark有一个主线程(大部分情况处于空闲状态),一个用于读取输入的线程,可配置数量的工作线程(用于解码)以及一个用于写入输出的线程。
性能伸缩
在多线程应用程序中,首先需要评估的是,当我们添加核心/线程时,性能有着怎样的伸缩,这实际上是一个应用未来成功与否的重要指标。下图显示了 h264dec benchmark性能与线程数量之间的伸缩关系。我的CPU(Intel Core i5-8259U)是4核/8线程的,因此我将上限设为8线程。值得注意的是,大于 4个线程后,性能不再按线程增加的速度继续快速提高。
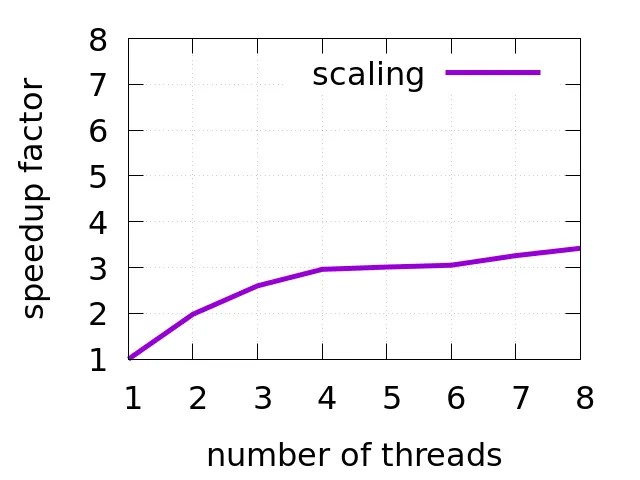
当你想要对工作负载的性能进行建模时,这就对你非常有用。例如,当你估算完成一个特定任务所需的硬件时,看看上面这张图片,我宁愿选择更少数量的核心,但每颗核心主频更高的配置方案。2
有时我们可能会被问到这样的问题:怎样的硬件配置刚好能够处理一个特定任务。当应用程序能够线性伸缩时(换句话说,每个线程处理独立的数据单元并且不需要同步),此时你可以大概估计一下:只需在单个线程中运行工作负载并测量其执行周期。然后,你可以选择特定核心数和频率的CPU来达到你的延迟/吞吐量的需求。但是,当应用程序的性能不能很好地伸缩时,事情就变得很麻烦。此时,你不能再依赖于IPC了(详见后文),因为一个线程可能表现得很忙,显得有很高的利用率,但实际上它仅仅是在锁上自旋。在Brendan Gregg 撰写的《性能之巅》中有更多关于容量规划的相关信息。
CPU 利用率
下一个重要指标是CPU利用率3,它可以告诉你在执行某个任务时平均有多少线程处于繁忙状态。注意,线程不一定是在做有用的工作,可能只是在自旋。下图可以看到 h264dec benchmark中线程数和CPU利用率之间的关系。
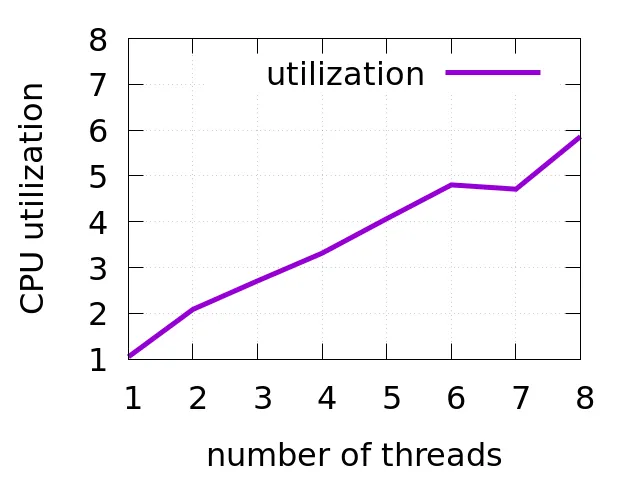
例如,当工作负载使用了5个线程时,平均只有4个线程处于繁忙状态。也就是说,通常有一个线程一直处于睡眠状态,这阻碍了性能的线性伸缩(性能没有随着线程数量增大而线性提高),表明线程之间存在一些同步。
同步开销
为了估量线程间通信的开销,我们可以通过统计时钟周期总数以及其期间执行的指令总数来计算:
# 1 个工作线程
$ perf stat ./h264dec -i park_joy_2160p.h264 -t 1 -o output.file -v
261,963,433,544 cycles # 3.766 GHz
485,932,999,948 instructions # 1.85 insn per cycle
66.236645032 seconds time elapsed
66.290561000 seconds user
3.324930000 seconds sys
# 4 个工作线程
$ perf stat ./h264dec -i park_joy_2160p.h264 -t 4 -o output.file -v
272,518,956,365 cycles # 3.479 GHz
523,079,251,733 instructions # 1.92 insn per cycle
23.643595782 seconds time elapsed
73.979057000 seconds user
4.402318000 seconds sys
# 8 个工作线程
$ perf stat ./h264dec -i park_joy_2160p.h264 -t 8 -o output.file -v
453,581,394,912 cycles # 3.410 GHz
661,715,307,682 instructions # 1.46 insn per cycle
22.700304401 seconds time elapsed
128.122821000 seconds user
4.883838000 seconds sys
这里有一些非常有趣的现象,可以看到8个线程时的计数结果可能与你的想象不同,先不要觉得奇怪,因为CPU时间是墙上时间的5倍以上,出现这种现象完全与CPU利用率有关。
再来查看8个线程运行结束时所执行的指令数量,8个工作线程执行的指令比单个线程多36%(661,715,307,682 / 485,932,999,948 ≈ 1.36),这些多出来的指令都可以视为开销,这可能是线程同步(自旋)引起的。
分析多线程应用
要想在源代码级别上进行分析,先看看在它上面运行profiler的记录:4
# 1 个工作线程
$ perf record -o perf1.data -- ./h264dec -i park_joy_2160p.h264 -t 1 -o output.file -v
[ perf record: Captured and wrote 10.790 MB perf1.data (282808 samples) ]
# 4 个工作线程
$ perf record -o perf4.data -- ./h264dec -i park_joy_2160p.h264 -t 4 -o output.file -v
[ perf record: Captured and wrote 12.592 MB perf4.data (330029 samples) ]
# 8 个工作线程
$ perf record -o perf8.data -- ./h264dec -i park_joy_2160p.h264 -t 8 -o output.file -v
[ perf record: Captured and wrote 21.239 MB perf8.data (556685 samples) ]
相关样本的数量与我们之前看到的user时间相关。也就是说,工作线程越多,profiler需要执行的中断就越多。如果我们仔细查看profiles,除了函数 ed_rec_thread以外,其他内容基本一致:
# 1 个工作线程
$ perf report -n -i perf1.data --stdio
# Overhead Samples Command Shared Object Symbol
# ........ ............ ....... ................ .....................................
0.18% 524 h264dec h264dec [.] ed_rec_thread
# 4 个工作线程
$ perf report -n -i perf4.data --stdio
# Overhead Samples Command Shared Object Symbol
# ........ ............ ....... ................ .....................................
3.62% 11417 h264dec h264dec [.] ed_rec_thread
# 8 个工作线程
$ perf report -n -i perf8.data --stdio
# Overhead Samples Command Shared Object Symbol
# ........ ............ ....... ................ .....................................
17.53% 95619 h264dec h264dec [.] ed_rec_thread
需要注意的问题是随着线程数量的增加, ed_rec_thread函数如何获取更多样本。这一问题很可能是阻碍我们通过添加更多线程来进一步扩展性能的瓶颈。
简单地比较和分析不同数量工作线程得到的profiles,也是我们在多线程应用中找到同步瓶颈所在的一个方法。
实际上, decode_slice_mb函数内联到 ed_rec_thread函数,而下面一行代码是 decode_slice_mb函数中的一段:
while (rle->mb_cnt >= rle->prev_line->mb_cnt -1);
这里的mb_cnt用关键字volatile修饰,所以自旋实际上发生在这里。
查看"每线程"
Linux的perf非常强大,perf可以收集到一个进程中主线程派生的每一个线程进行分析。如果你想查看单个线程执行的情况,可以使用perf的-s选项:
$ perf record -s ./h264dec -i park_joy_2160p.h264 -t 8 -o output.file -v
然后可以列出所有线程的ID以及每个线程收集的样本数量:
$ perf report -n -T
...
# PID TID cycles:ppp
6602 6607 52758679502
6602 6603 487183790
6602 6613 49670283608
6602 6608 51173619921
6602 6604 165362635
6602 6609 38662454026
6602 6610 31375722931
6602 6606 48270267494
6602 6611 53793234480
6602 6612 25640899076
6602 6605 14481176486
现在如果你只想分析程序某个特定线程所收集的样本,则可以使用perf的–tid选项:
$ perf report -T --tid 6607 -n
8.28% 25657 h264dec h264dec [.] decode_cabac_residual_nondc
7.12% 35880 h264dec h264dec [.] put_h264_qpel8_hv_lowpass
6.19% 31430 h264dec h264dec [.] put_h264_qpel8_v_lowpass
5.87% 28874 h264dec h264dec [.] h264_v_loop_filter_luma_c
2.82% 10105 h264dec h264dec [.] ff_h264_decode_mb_cabac
1.19% 4525 h264dec h264dec [.] get_cabac_noinline
如果你刚好有Intel Vtune Amplifier工具,可以用它的GUI对特定线程和热点进行及时的过滤和放大缩小。
当你已经确定了某个引起了问题的线程,并且不想再关注其他线程时,可以这样用perf分析一个线程:
perf record -t <TID>
使用strace工具
我经常使用的另外一个工具是 strace:
$ strace -tt -ff -T -o strace-dump -- ./h264dec -i park_joy_2160p.h264 -t 8 -o output.file
上述命令将为每个运行的线程都生成一个记录系统调用的转储文件,转储文件中每个系统调用都附带精确的时间戳和持续时间。我们可以进一步处理单个转储文件,并从中提取很多有趣的信息。例如:
# 线程等待mutex来解锁的总用时
$ grep futex strace-dump.3740 > futex.dump
$ sed -i 's/.*<//g' futex.dump
$ sed -i 's/>//g' futex.dump
$ paste -s -d+ futex.dump | bc
16.407458
# 线程从文件中读取输入的总用时
$ grep read strace-dump.3740 > read.dump
$ sed -i 's/.*<//g' read.dump
$ sed -i 's/>//g' read.dump
$ paste -s -d+ read.dump | bc
2.179850
这个线程总运行时间为21秒,而几乎80%的时间都被阻塞。然而此线程为所有工作线程提供输入,所以很可能是其他事情限制了benchmark的性能伸缩。
优化多线程应用
在处理单线程应用程序时,优化程序的一部分通常会提升整体性能5。但是,对于多线程应用程序就不一定了。实际上,这很难预测, 这种情况coz profiler能帮助分析。但由于我第一次使用,可能哪里出了问题,我没有获取到有效的信息。
如果你的应用程序能够很好地伸缩,或者线程在工作时不参与输入工作,那么进行优化后该程序性能可以成比例提高。在这种情况下,更容易对运行在单个线程上的应用程序进行性能分析,对于单线程起作用的优化很有可能扩展得很好。6
自顶向下法可以很好的帮助我们发现微体系结构问题,并对Intel下一代CPU有更好的解释。
本文由西邮陈莉君教授研一学生梁金荣、戴君毅、马明慧等翻译,陈莉君、宋宝华老师指导和审核。译者梁金荣、戴君毅、马明慧等同学热爱开源,践行开放、自由和分享。



