
Meta AI 多语言阅读理解数据集 Belebele,涵盖 122 种语言变体
Meta AI 宣布推出一款涵盖 122 种语言变体的多语言阅读理解数据集,名为 Belebele。“我们希望这项工作能够引发围绕 LLM 多语言性的新讨论”。

BELEBELE 是首个跨语言并行数据集,可以直接比较所有语言的模型性能。该数据集涵盖了 29 种脚本和 27 个语系中不同类型的高、中、低资源语言。此外,还有 7 种语言包含在两种不同的脚本中,从而为印地语、乌尔都语、孟加拉语、尼泊尔语和僧伽罗语的罗马化变体制定了首个 NLP 基准。
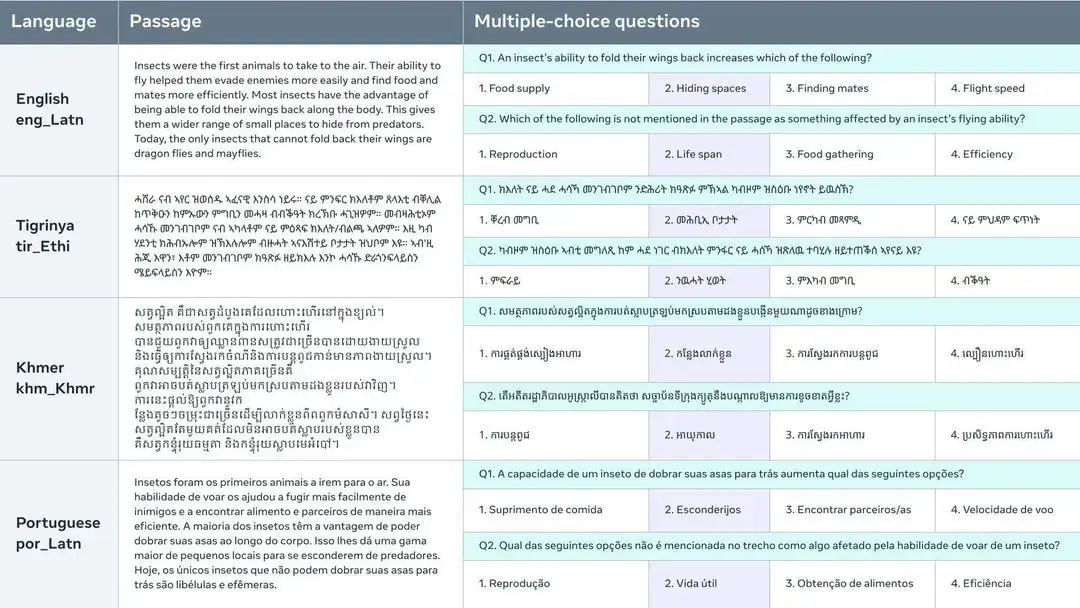
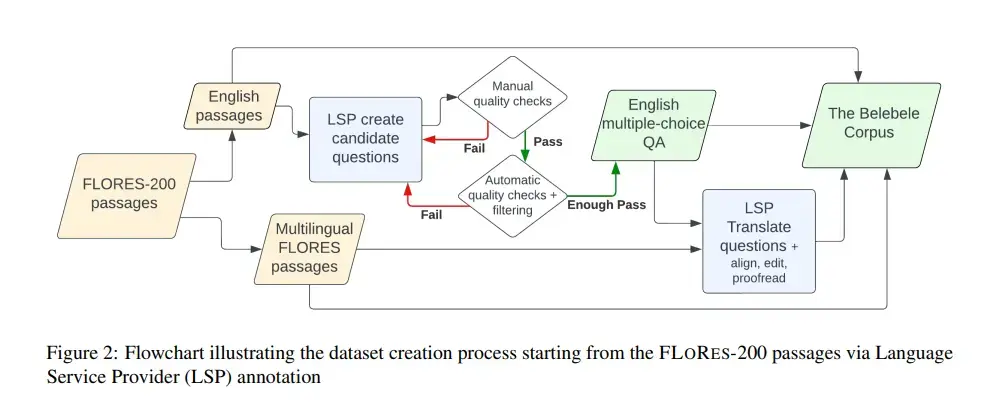
该数据集可对单语和多语模型进行评估,但其并行性也可在一些跨语言环境中对跨语言文本表征进行评估。通过从相关质量保证数据集中收集训练集,可以对任务进行全面微调评估。每个问题都基于 Flores-200 数据集中的一段短文,并有四个多项选择答案。这些问题经过精心设计,以区分具有不同一般语言理解水平的模型。
- 每种语言有 900 道题
- 488 个不同段落,每个段落有 1-2 道相关问题。
- 每道题有 4 个选择答案,其中只有一个是正确的。
- 122 种语言 / 语言变体(包括英语)。
- 900 x 122 = 109,800 个问题。
研究人员利用这个数据集评估了多语言屏蔽语言模型(MLM)和大语言模型(LLM)的能力。结果表明,尽管以英语为中心的 LLM 有显著的跨语言迁移能力,但在平衡的多语言数据上经过预训练的更小的 MLM 仍然能理解更多的语言。且词汇量越大、越有意识地构建词汇,在低资源语言上的表现就越好。
更多详情可查看完整论文。
0人觉得很赞
7223 阅读

