
【全网首发】聊聊C语言中的malloc申请内存的内部原理原创
大家好,我是飞哥!我们今天来深入地了解一下malloc函数的内部工作原理。
操作系统为应为应用层提供了 mmap、brk 等系统调用来申请内存。但是这些系统调用在很多的时候,我们并不会直接使用。原因有以下两个
-
系统调用管理的内存粒度太大。系统调用申请内存都是整页 4KB 起,但是我们平时编程的时候经常需要申请几十字节的小对象。如果使用 mmap 未免碎片率也太大了。 -
频繁的系统调用的开销比较大。和函数调用比起来,系统的调用的开销非常的大。如果每次申请内存都发起系统调用,那么我们的应用程序将慢如牛。
所以,现代编程语言的做法都是自己在应用层实现了一个内存分配器。其思想都和内核自己用的 SLAB 内存分配器类似。都是内存分配器预先向操作系统申请一些内存,然后自己构造一个内存池。当我们申请内存的时候,直接由分配器从预先申请好的内存池里申请。当我们释放内存的时候,分配器会将这些内存管理起来,并通过一些策略来判断是否将其回收给操作系统。
通过这种方式既灵活地管理了各种不同大小的小对象,也避免了用户频率地调用 mmap 系统调用所造成的开销。常见的内存分配器有 glibc 中的 ptmalloc、Google 的 tcmalloc、Facebook 的 jemalloc 等等。我们在学校里学习 C 语言时候使用的 malloc 函数的底层就是 glibc 的 ptmalloc 内存分配器实现的。
我们今天就以最经(古)典(老)的 ptmalloc 内存分配器讲起,带大家深入地了解 malloc 函数的内部工作原理。
本文中需要用到 glibc 源码,下载地址是 http://ftp.gnu.org/gnu/glibc/ 。本文使用的源码版本是 2.12.1。
一、ptmalloc 内存分配器定义
1.1 分配区 arena
在 ptmalloc 中,使用分配区 arena 管理从操作系统中批量申请来的内存。之所以要有多个分配区,原因是多线程在操作一个分配区的时候需要加锁。在线程比较多的时候,在锁上浪费的开销会比较多。为了降低锁开销,ptmalloc 支持多个分配区。这样在单个分配区上锁的竞争开销就会小很多。
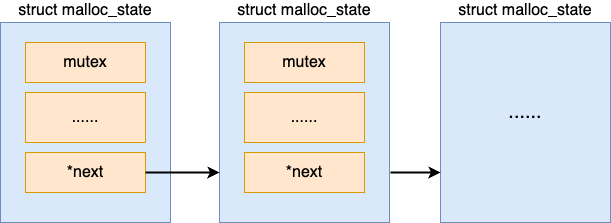
在 ptmalloc 中存在一个全局的主分配区,是用静态变量的方式定义的。
//file:malloc/malloc.c
static struct malloc_state main_arena;
分配区的数据类型是 struct malloc_state,其定义如下:
//file:malloc/malloc.c
struct malloc_state {
// 锁,用来解决在多线程分配时的竞争问题
mutex_t mutex;
// 分配区下管理内存的各种数据结构
...
/* Linked list */
struct malloc_state *next;
}
在分配区中,首先有一个锁。这是因为多个分配区只是能降低锁竞争的发生,但不能完全杜绝。所以还需要一个锁来应对多线程申请内存时的竞争问题。接下来就是分配区中内存管理的各种数据结构。这部分下个小节我们再详细看。
再看下 next 指针。通过这个指针,ptmalloc 把所有的分配区都以一个链表组织了起来,方便后面的遍历。
1.2 内存块 chunk
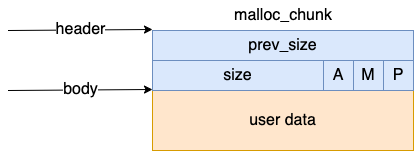
在每个 arena 中,最基本的内存分配的单位是 malloc_chunk,我们简称 chunk。它包含 header 和 body 两部分。这是 chunk 在 glibc 中的定义:
// file:malloc/malloc.c
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
我们在开发中每次调用 malloc 申请内存的时候,分配器都会给我们分配一个大小合适的 chunk 出来,把 body 部分的 user data 的地址返回给我们。这样我们就可以向该地址写入和读取数据了。强烈推荐关注本公众号「开发内功**」。
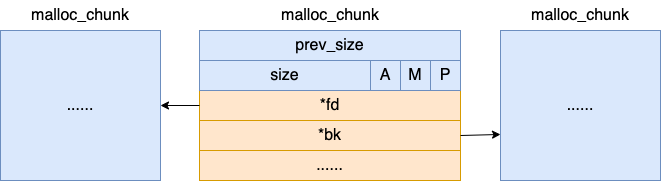
如果我们在开发中调用 free 释放内存的话,其对应的 chunk 对象其实并不会归还给内核。而是由 glibc 又组织管理了起来。其 body 部分的 fd、bk 字段分别是指向上一个和下一个空闲的 chunk( chunk 在使用的时候是没有这两个字段的,这块内存在不同场景下的用途不同),用来当双向链表指针来使用。
1.3 空闲内存块链表 bins
glibc 会将相似大小的空闲内存块 chunk 都串起来。这样等下次用户再来分配的时候,先找到链表,然后就可以从链表中取下一个元素快速分配。这样的一个链表被称为一个 bin。ptmalloc 中根据管理的内存块的大小,总共有 fastbins、**allbins、largebins 和 unsortedbins 四类。
这四类 bins 分别定义在 struct malloc_state 的不同成员里。
//file:malloc/malloc.c
struct malloc_state {
/* Fastbins */
mfastbinptr fastbins[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a **all request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
}
fastbins 是用来管理尺寸最小空闲内存块的链表。其管理的内存块的最大大小是 MAX_FAST_SIZE。
#define MAX_FAST_SIZE (80 * SIZE_SZ / 4)
SIZE_SZ 这个宏指的是指针的大小,在 32 位系统下,SIZE_SZ 等于 4 。在 64 位系统下,它等于 8。因为现在都是 64 位系统,所以本文中后面的例子中我们都是以 SIZE_SZ 为 8 来举例。所以在 64 位系统下,MAX_FAST_SIZE = 80 * 8 / 4 = 160 字节。
bins 是用来管理空闲内存块的主要链表数组。其链表总数为 2\ * NBINS 个,NBINS 的大小是 128,所以这里总共有 256 个空闲链表。
//file:malloc/malloc.c
#define NBINS 128
**allbins、largebins 和 unsortedbins 都使用的是这个数组。
另外top 成员是用来保存着特殊的 top chunk。当所有的空闲链表中都申请不到合适的大小的时候,会来这里申请。
1)fastbins
其中 fastbins 成员定义的是尺寸最小的元素的链表。它存在的原因是,用户的应用程序中绝大多数的内存分配是小内存,这组 bin 是用于提高小内存的分配效率的。
fastbin 中有多个链表,每个 bin 链表管理的都是固定大小的 chunk 内存块。在 64 位系统下,每个链表管理的 chunk 元素大小分别是 32 字节、48 字节、......、128 字节 等不同的大小。
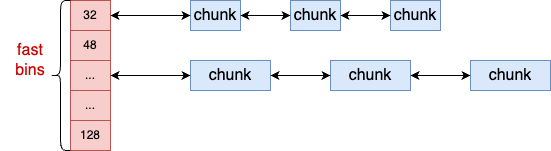
glibc 中提供了 fastbin_index 函数可以快速地根据要申请的内存大小找到 fastbins 下对应的数组下标。
//file:malloc/malloc.c
#define fastbin_index(sz) \
((((unsigned int)(sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
例如要申请的内存块大小是 32 字节,fastbin_index(32) 计算后可知应该到下标位 0 的空闲内存链表里去找。再比如要申请的内存块大小是 64 字节,fastbin_index(64) 计算后得知数组下标为 2。
2)**allbins
**allbins 是在 malloc_state 下的 bins 成员中管理的。
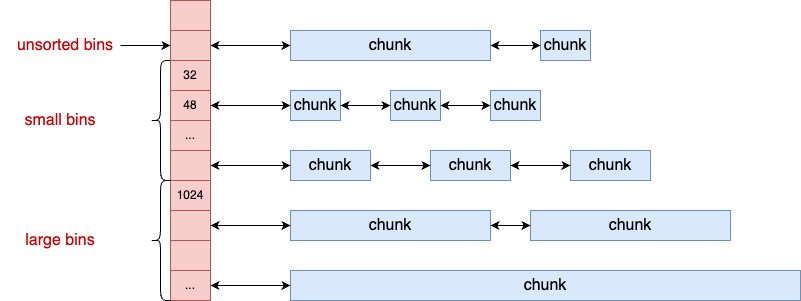
**allbins 数组总共有 64 个链表指针,是由 NSMALLBINS 来定义的。
//file:malloc/malloc.c
#define NSMALLBINS 64
和 fastbin 一样,同一个 **all bin 中的 chunk 具有相同的大小。**all bin 在 64 位系统上,两个相邻的 **all bin 中的 chunk 大小相差 16 字节(MALLOC_ALIGNMENT 是 2 个 SIZE_SZ,一个 SIZE_SZ 大小是 8)。
//file:malloc/malloc.c
#define MALLOC_ALIGNMENT (2 * SIZE_SZ)
#define SMALLBIN_WIDTH MALLOC_ALIGNMENT
管理的 chunk 大小范围定义在 in_**allbin_range 中能看到。只要小于 MIN_LARGE_SIZE 的都属于 **all bin 的管理范围。
#define MIN_LARGE_SIZE (NSMALLBINS * SMALLBIN_WIDTH)
#define in_**allbin_range(sz) \
((unsigned long)(sz) < (unsigned long)MIN_LARGE_SIZE)
通过上面的源码可以看出 MIN_LARGE_SIZE 的大小等于 64 * 16 = 1024。所以 **all bin 管理的内存块大小是从 32 字节、48 字节、......、1008 字节。(在 glibc 64位系统中没有管理 16 字节的空闲内存,是 32 字节起的)
另外 glibc 也提供了根据申请的字节大小快速算出其在 **all bin 中的下标的函数 **allbin_index。
//file:malloc/malloc.c
#define **allbin_index(sz) \
(SMALLBIN_WIDTH == 16 ? (((unsigned)(sz)) >> 4) : (((unsigned)(sz)) >> 3))
例如要申请的内存块大小是 32 **allbin_index(32) 计算后可知应该到下标位 2 的空闲内存链表里去找。再比如要申请的内存块大小是 64 **allbin_index(64) 计算后得知数组下标为 3。
2)largebins
largebins 和 **allbins 的区别是它管理的内存块比较大。其管理的内存是 1024 起的。
而且每两个相邻的 largebin 之间管理的内存块大小不再是固定的等差数列。这是为了用较少的链表数来更大块空闲内存的管理。
largebin_index_64 函数用来根据要申请的内存大小计算出其在 large bins 中的下标。
//file:malloc/malloc.c
#define largebin_index_64(sz) \
(((((unsigned long)(sz)) >> 6) <= 48)? 48 + (((unsigned long)(sz)) >> 6): \
((((unsigned long)(sz)) >> 9) <= 20)? 91 + (((unsigned long)(sz)) >> 9): \
((((unsigned long)(sz)) >> 12) <= 10)? 110 + (((unsigned long)(sz)) >> 12): \
((((unsigned long)(sz)) >> 15) <= 4)? 119 + (((unsigned long)(sz)) >> 15): \
((((unsigned long)(sz)) >> 18) <= 2)? 124 + (((unsigned long)(sz)) >> 18): \
126)
4)unsortedbins
unsortedbins 比较特殊,它管理的内存块不再是和 **allbins 或 largebins 中那样是相同或者相近大小的。而是不固定,是被当做缓存区来用的。
当用户释放一个堆块之后,会先进入 unsortedbin。再次分配堆块时,ptmalloc 会优先检查这个链表中是否存在合适的堆块,如果找到了,就直接返回给用户(这个过程可能会对 unsortedbin 中的堆块进行切割)。若没有找到合适的,系统也会顺带清空这个链表上的元素,把它放到合适的 **allbin 或者 large bin 中。
5)top chunk
另外还有有个独立于 fastbins、**allbins、largebins 和 unsortedbins 之外的一个特殊的 chunk 叫 top chunk。
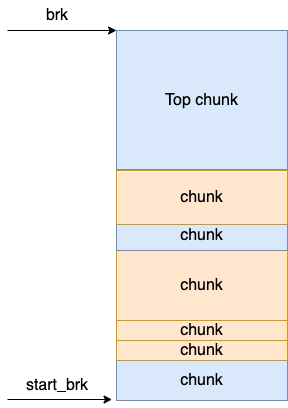
如果没有空闲的 chunk 可用的时候,或者需要分配的 chunk 足够大,当各种 bins 都不满足需求,会从top chunk 中尝试分配。
二、malloc 的工作过程
在前面的小节里我们看到,glibc 在分配区 arena 中分别用 fastbins、bins(保存着 **allbins、largebins 和 unsortedbins)以及 top chunk 来管理着当前已经申请到的所有空闲内存块。
有了这些组织手段后,当用户要分配内存的时候,malloc 函数就可以根据其大小,从合适的 bins 中查找合适的 chunk。
-
假如用户要申请 30 字节的内存,那就直接找到 32 字节这个 bin 链表,从链表头部摘下来一个 chunk 直接用。 -
假如用户要申请 500 字节的内存,那就找到 512 字节的 bin 链表,摘下来一个 chunk 使用 -
......
当用户用完需要释放的时候,glibc 再根据其内存块大小,放到合适的 bin 下管理起来。下次再给用户申请时备用。
另外还有就是为 ptmalloc 管理的 chunk 可能会发生拆分或者合并。当需要申请小内存块,但是没有大小合适的时候,会将大的 chunk 拆成多个小 chunk。如果申请大内存块的时候,而系统中又存在大量的小 chunk 的时候,又会发生合并,以降低碎片率。
这样不管如何申请和释放,都不会导致严重的碎片问题发生。这就是 glibc 内存分配器的主要管理。了解了主要原理后,我们再来看下 malloc 函数的实现中,具体是怎么样来分配处理内存分配的。
malloc 在 glibc 中的实现函数名是 public_mALLOc。
//file:malloc/malloc.c
Void_t*
public_mALLOc(size_t bytes)
{
// 选一个分配区 arena 出来,并为其加锁
arena_lookup(ar_ptr);
arena_lock(ar_ptr, bytes);
// 从分配区申请内存
victim = _int_malloc(ar_ptr, bytes);
// 如果选中的分配区没有申请成功,则换一个分配区申请
......
// 释放锁并返回
mutex_unlock(&ar_ptr->mutex);
return victim;
}
在 public_mALLOc 中主要的逻辑就是选择分配区和锁操作,这是为了避免多线程冲突。真正的内存申请核心逻辑都在 _int_malloc 函数中。这个函数非常的长。为了清晰可见,我们把它的骨干逻辑列出来。
//file:malloc/malloc.c
static Void_t*
_int_malloc(mstate av, size_t bytes)
{
// 对用户请求的字节数进行规范化
INTERNAL_SIZE_T nb; /* normalized request size */
checked_request2size(bytes, nb);
// 1.从 fastbins 中申请内存
if ((unsigned long)(nb) <= (unsigned long)(get_max_fast ())) {
...
}
// 2.从 **allbins 中申请内存
if (in_**allbin_range(nb)) {
...
}
for(;;) {
// 3.遍历搜索 unsorted bins
while ( (victim = unsorted_chunks****->bk) != unsorted_chunks****) {
// 判断是否对 chunk 进行切割
...
// 判断是否精准匹配,若匹配可以直接返回
...
// 若不精准匹配,则将 chunk 放到对应的 bins 中
// 如果属于 **allbins,则插入到 **allbins 中
// 如果属于 largebins,则插入到 largebins 中
...
// 避免遍历 unsorted bin 占用过多时间
if (++iters >= MAX_ITERS)
break;
}
// 4.如果属于 large 范围或者之前的 fastbins/**allbins/unsorted bins 请求都失败
// 则从 large bin 中寻找 chunk,可能会涉及到切割
...
// 5.尝试从 top chunk 中申请
// 可能会涉及对 fastbins 中 chunk 的合并
use_top:
victim = av->top;
size = chunksize(victim);
...
// 最后,分配区中没申请到,则向操作系统申请
void *p = sYSMALLOc(nb, av);
}
}
在一进入函数的时候,首先是调用 checked_request2size 对用户请求的字节数进行规范化。因为分配区中管理的都是 32、64 等对齐的字节数的内存。如果用户请求 30 字节,那么 ptmalloc 会对齐一下,然后按 32 字节为其申请。
接着是从分配区的各种 bins 中尝试为用户分配内存。总共包括以下几次的尝试。
-
1 如果申请字节数小于 fast bins 管理的内存块最大字节数,则尝试从 fastbins 中申请内存,申请成功就返回 -
2 如果申请字节数小于 **all bins 管理的内存,则尝试从 **allbins 中申请内存,申请成功就返回 -
3 尝试从 unsorted bins 中申请内存,申请成功就返回 -
4 尝试从 large bins 中申请内存,申请成功就返回 -
5 如果前面的步骤申请都没成功,尝试从 top chunk 中申请内存并返回 -
6 从操作系统中使用 mmap 等系统调用申请内存
在这些分配尝试中,一旦某一步申请成功了,就会返回。后面的步骤就不需要进行了。
最后在 top chunk 中也没有足够的内存的时候,就会调用 sYSMALLOc 来向操作系统发起内存申请。
//file:malloc/malloc.c
static Void_t* sYSMALLOc(INTERNAL_SIZE_T nb, mstate av)
{
...
mm = (char*)(MMAP(0, size, PROT_READ|PROT_WRITE, MAP_PRIVATE));
...
}
在 sYSMALLOc 中,是通过 mmap 等系统调用来申请内存的。
另外还有就是穿插在这些的尝试中间,可能会涉及到 chunk 的切分,将大块的 chunk 切分成较小的返回给用户。也可能涉及到多个小 chunk 的合并,用来降低内存碎片率。
以上就是 glibc 中的 ptmalloc 管理堆内存的基本原理。欢迎点赞、点再看!


