
别B+树了,out了原创
你好,我是yes。
最近了解了下 PolarDB MySQL,后续有机会分享下学习心得。
今天这篇先聊聊其内部引入 Blink Tree 来替换 B+Tree 的事情。
想必大伙都非常熟悉 B+Tree,面试常客,但是 Blink Tree 确实很少有人提到,它是 B+Tree 的升级版,据阿里云文档所述,通过对 B+Tree 的优化,可以将交易场景下 PolarDB 的读写性能提升20%。
B+Tree 的问题
那么 B+Tree 哪块表现的不好呢?
主要是并发场景下,写操作导致节点分裂(SMO,Split Merge Operation)的时候,刚好有并发读操作访问到错误的叶子节点,查错了节点,那么目标值肯定就搜索不到了,于是导致了错误查询。
举个例子,比如现有如下的一个 B+Tree:
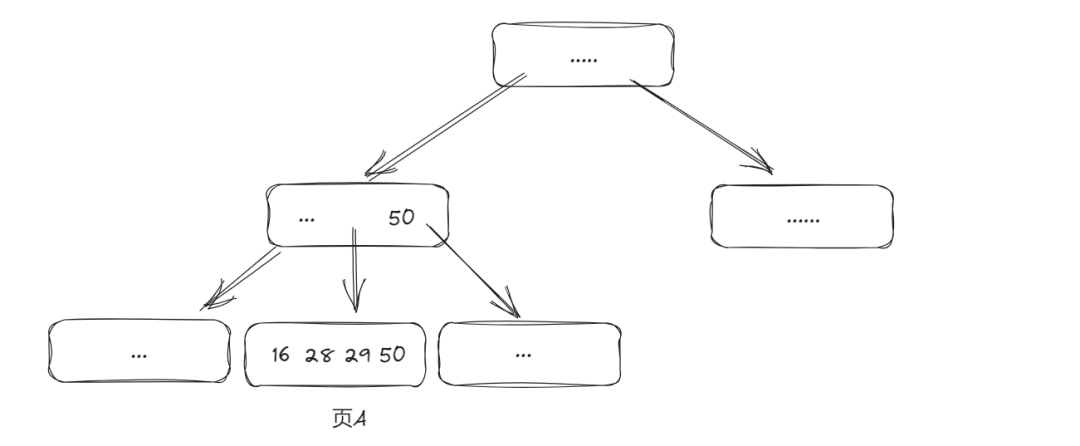
此时,插入一个数据 27,恰好页A满了,需要触发分裂,新增一个页B,且同时有个读取请求,想要访问数据 29。
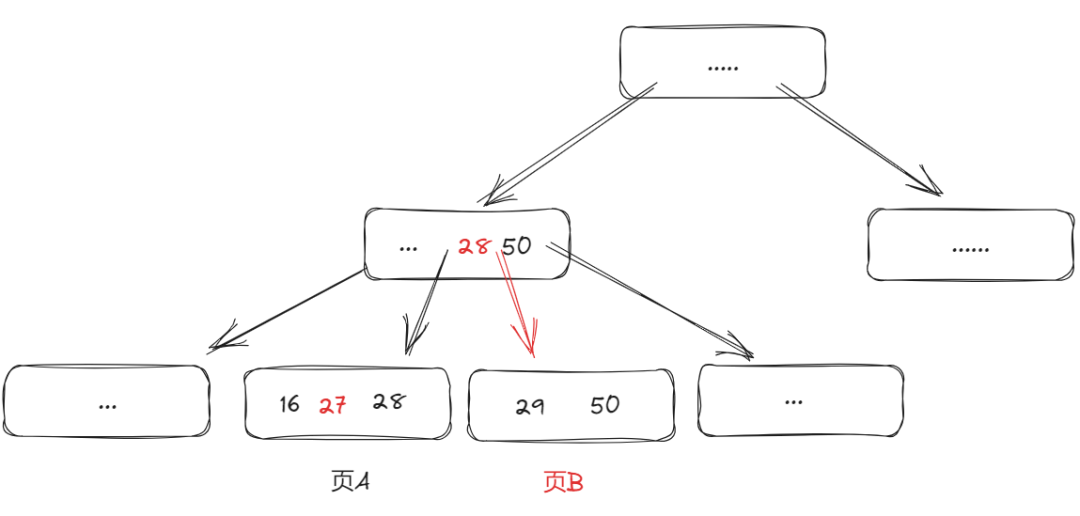
那么很有可能在分裂的时候,读请求访问到老的页面指针,指向了页 A,而页 A 内的 29 已经被分裂到新的页 B 中,这样一来读请求就发现没有 29 ,于是返回没数据,这就错乱了。
而且,叶子节点的分裂,可能会导致父节点的分裂,这种调整最长可能级联到根节点,并发场景下很容易导致错误,为了避免这种情况的发生,最简单的操作就是在发生节点分裂时,把整颗 B+Tree 都锁了。
这样一来数据的正确性得到了保证,但是性能就很低了,因为全局锁会影响了对所有页的访问。
后续 MySQL 对其在 5.7 版本后做了优化,但是整个 B+Tree 同时只能支持一个 SMO 操作的发生,高并发时大数据量插入导致多 SMO 的发生还是会被阻塞,影响性能。
Blink Tree
Blink Tree 主要引入了 high key 和 link 指针来解决并发读写中间态数据访问出错问题,能降低锁的粒度,提高性能。
high key 存储了每个节点的最大值,每个节点的 link 指针则指向了同层右侧的兄弟节点,在写入数据的时候,仅需对当前节点加锁,当前节点修改完毕后立马解锁,锁的粒度很细,并发度很高。
那具体是如何解决并发时候 SMO 中间态问题的呢?
我们直接来看来阿里云官网给的一个示意图:
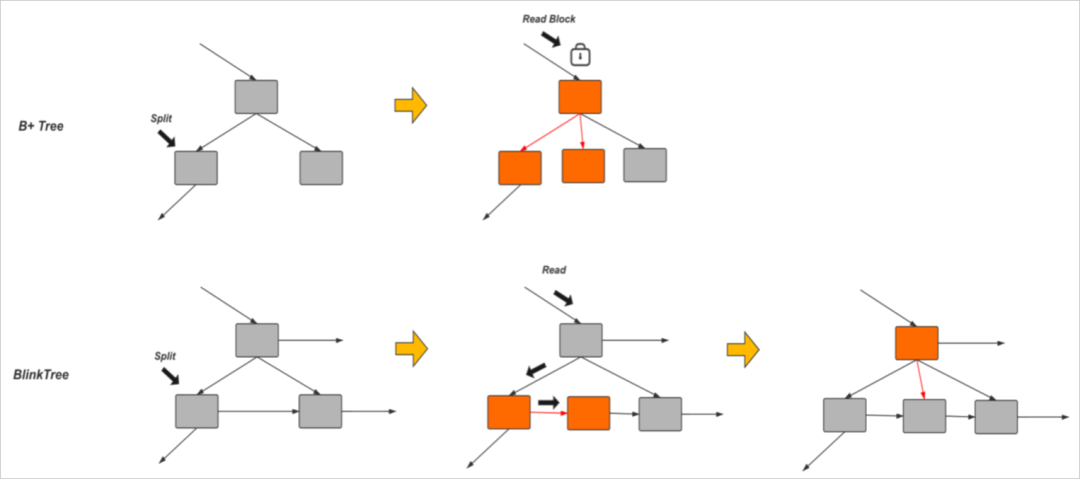
可以看到,相比于 B+Tree,Blink Tree的兄弟节点也进行了指针相连,当分裂在进行中还未完成,也就是父节点到新的子节点的链接还没有建立时,B+Tree 我们已经演示过了,并发读可能导致数据查询不到。
而 Blink Tree 就能解决这个问题,当读请求沿着老指针访问老页面的时候,对比下 high key,发现查询的值比当前页 high key 大,那么就沿着 link 指针找到旁边新分配的页面,此时就可以找到要查询的值了。
最后
这篇就简单介绍到这,对我们正常业务开发同学来说 Blink Tree 的理解到这也就差不多了,有兴趣的可以再看看 Blink Tree 的论文
-
https://www.csd.uoc.gr/~hy460/pdf/p650-lehman.pdf
还有这篇文章
-
https://zhuanlan.zhihu.com/p/374000358。
我是yes,从一点点到亿点点,我们下篇见~


