
Kafka是如何支持百万级TPS的?原创
承接上文RabbitMQ、RocketMQ、Kafka性能为何差距如此大?
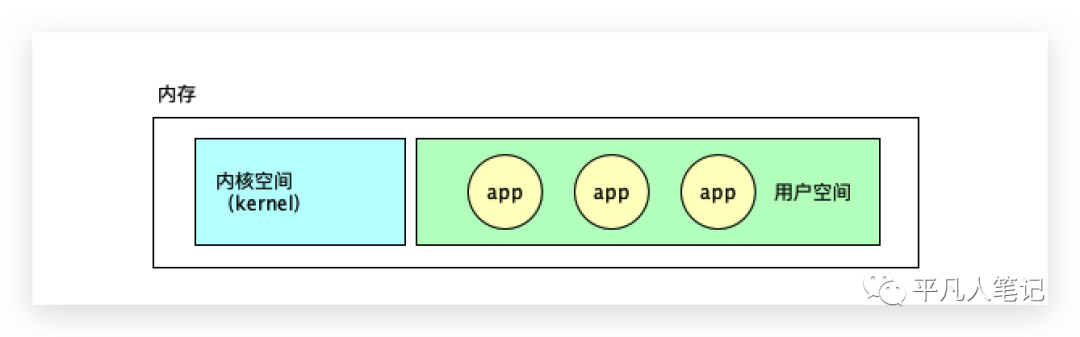
内存是线性地址空间,kernel程序先进入内存,一进入内存就开启保护模式,然后进行空间和权限的划分。
kernel占用的空间叫内核空间,也叫内核态;剩余的空间叫用户空间(用户态)。
应用程序在用户空间分配内存,应用程序与应用程序的地址空间是不能互相访问的,应用程序也不能直接访问内核的地址空间。
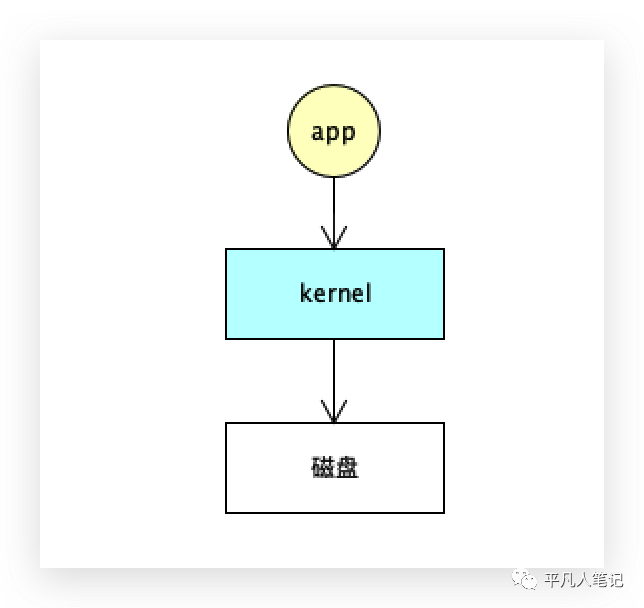
应用程序想使用硬件,比如磁盘、网卡等,都是需要和内核发生交互的,不能直接访问kernel的内核地址,但可以发生中断,通过调用系统内核中的方法间接的使用硬件资源。
直接内存映射MMAP
如果没有直接内存映射,程序想读写文件的话,怎么实现?
首先打开文件open(file)=fd 8得到一个文件描述符,然后读取文件描述符read(fd 8),文件描述符fd 8在内存中有一个映射,指向了硬盘中的文件,
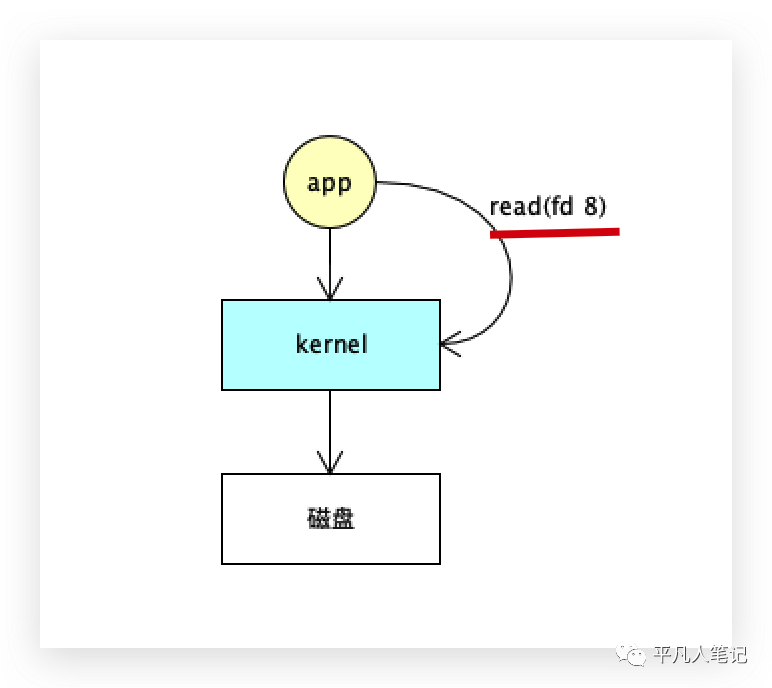
程序读取文件,调用内核的read(fd 8)方法,由内核替代程序读取文件描述符fd 8,程序就进入了所谓的io阻塞状态,即由用户态切换到内核态,由内核调用驱动再去读取这个文件,内核驱动将文件数据读取到内核空间,内核再拷贝到用户空间给程序使用。该过程可以用MMAP来加速。
系统调用MMAP
用户地址空间和内核地址空间都是逻辑地址,在物理的内存中开辟一块空间,内核可以访问这个空间,程序也可以访问,
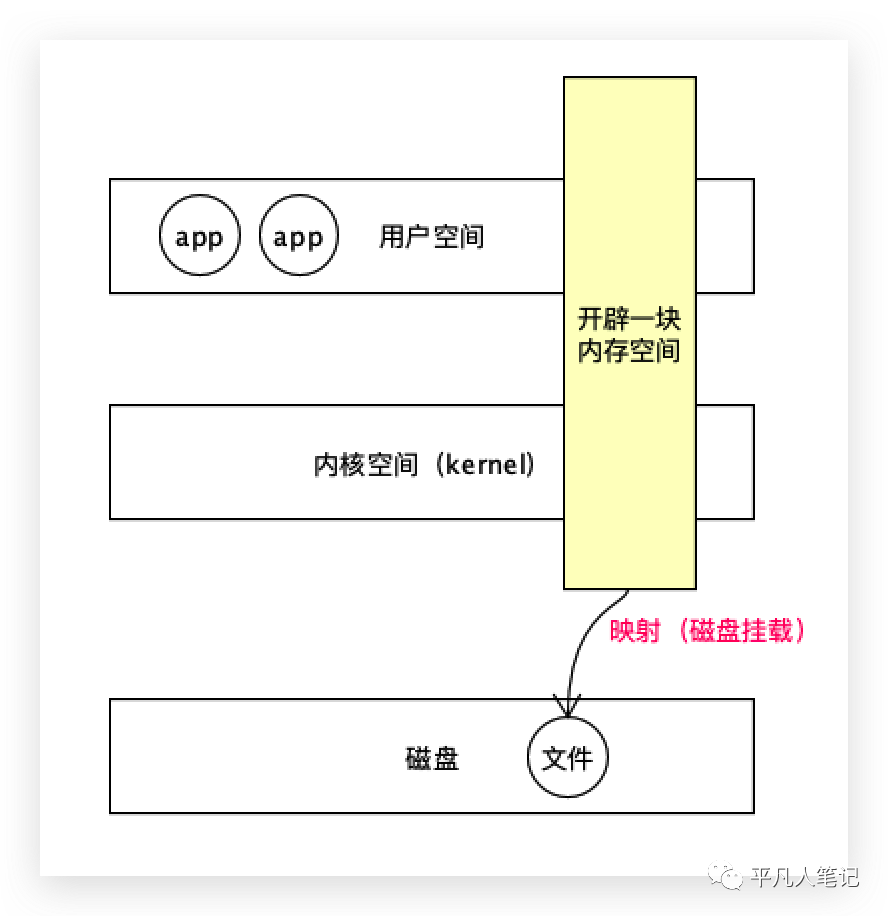
这个空间和磁盘文件做了MMAP映射,从这个空间中读取文件相当于从磁盘中读取文件,即文件的数据是直接放到这个共享区域里面的,程序可以不通过磁盘读取文件,而是直接从这个共享区域里面读取,减少了一次内核到进程之间数据拷贝的过程。
kafka生产消息的过程
kafka是由java或scama实现的,都属于JVM,它是用户空间的一个程序而已,kafka的数据可以持久化到磁盘,拿kafka当mq使用,其实就是间接的拿kafka当存储层使用,因为它的数据是持久化存储、不会丢失的。
当kafka启动的时候,先访问内核,再访问磁盘,
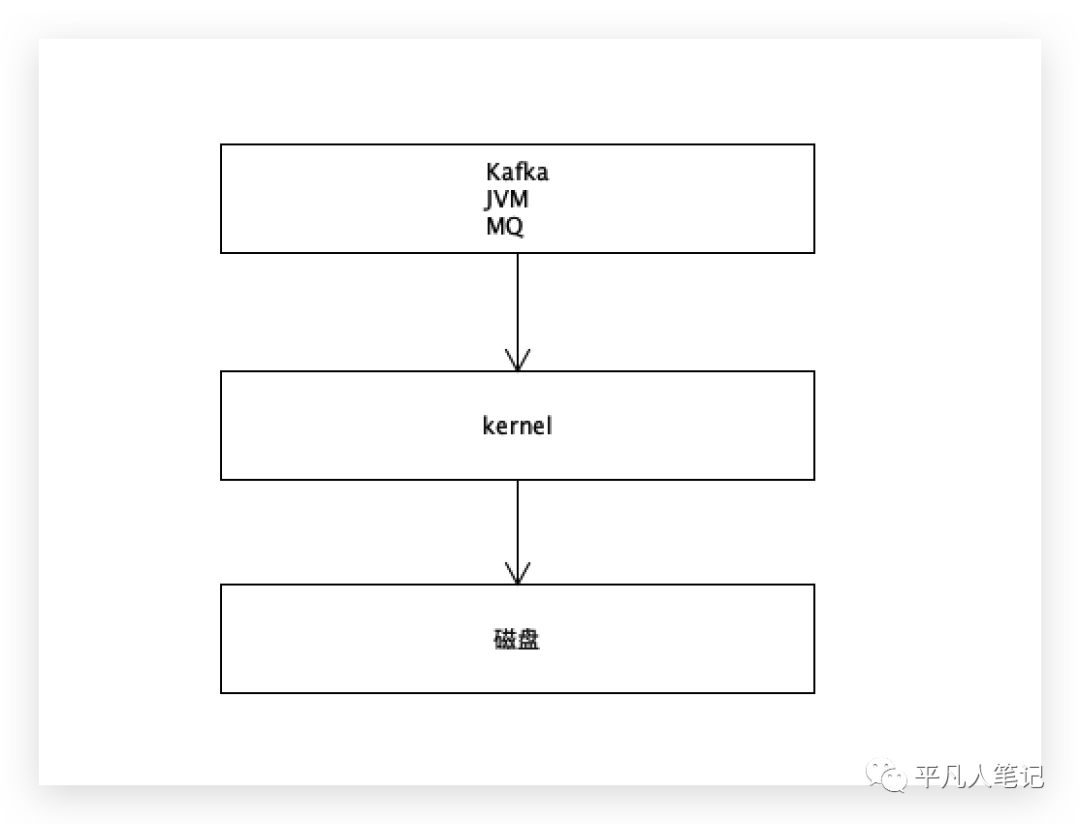
在用户空间和内核空间开辟一块共享区域,通过mmap技术与磁盘建立映射,
这样kafka就可以直接通过共享区域访问到文件了。
kafka的底层有一个段文件的概念,在kafka的生命周期里面,一段大小是1个G,像记录日志一样顺序写入磁盘。
kafka一启动,先在内存里面开1个G大小的空间,这个空间正好映射到磁盘中1G大小的文件,刚开始的时候,文件肯定是空的,但是在内存中开了一个空间,可以让用户空间进程和内核之间互通的一个区域。
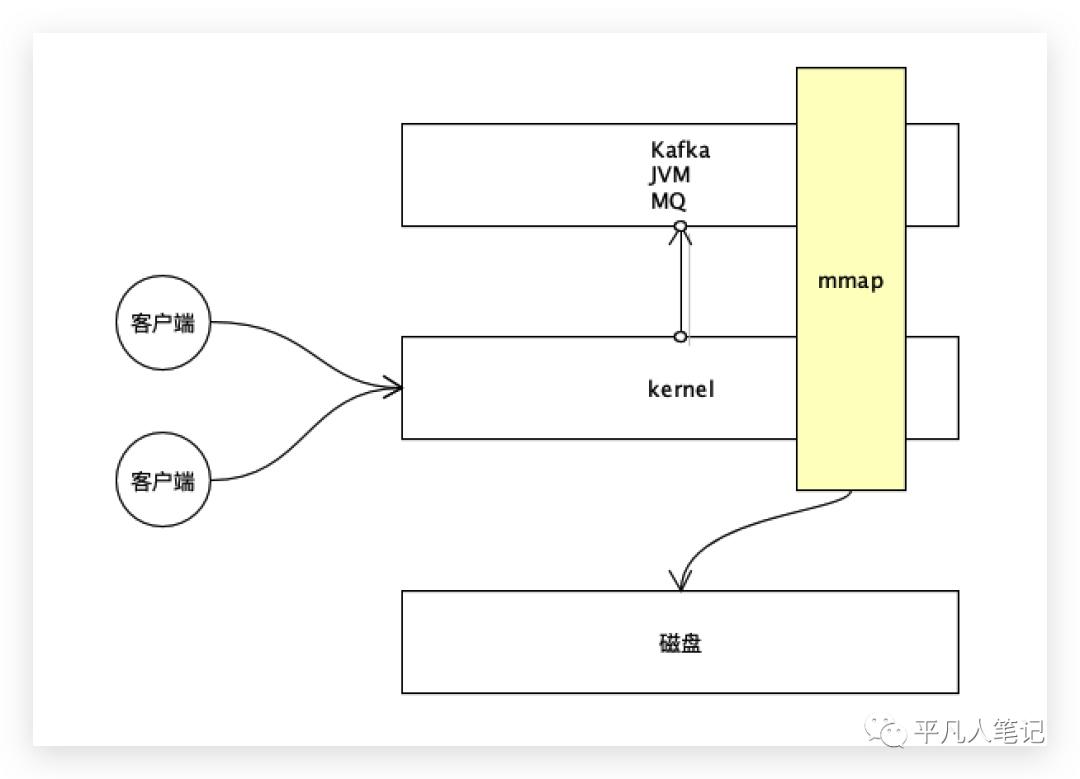
客户端通过网络连接到这台主机,先访问内核,客户端发送数据包过来,(即producer生产消息数据),数据从网卡进入这台主机,先到达到内核,由内核再拷贝给kafka。
数据进来的时候,是由内核态到用户态,kafka读取之后,会给这个数据加上消息段的头,比如加上id信息,再把它持久化到磁盘。
请求进来的数据不可避免的要从内核态到用户态,进入用户空间加工处理一下,最终要记录到文件里面。
如果没有MMAP技术怎么实现?
进程调用内核即应用程序调用write写,进程先把数据给到内核,再由内核拷贝到磁盘文件里面去。
MMAP是怎么实现的?
Kafka将共享区域看作一个buffer,直接把数据追加到buffer中去,追加buffer的时候,就会立马写入到文件里面去,这样就减少了一次数据拷贝的过程。
kafka通过mmap持久化数据,减少了一次由程序到内核拷贝数据的过程。
kafka消费消息的过程
消息数据存储在磁盘文件里面。
消费端通过socket网络连接过来的,这里会用到另外一个系统调用:零拷贝sendfile,这里跟mmap就没有关系了,mmap解决了数据进来的过程,进来的数据可以很快写入到磁盘中去。
如果没有零拷贝,那怎么读走文件中的数据?
一个请求进来,要读文件中的某个位置的数据,若要读取的数据在buffer(内核和用户进程共享的内存区域)中,即没有在历史文件里面的话,kafka把这个数据从buffer读取出来发送出去。
这时候需要从用户空间拷贝到内核,再通过socket(文件描述符、连接)发送出去。
kafka其实可以存储很长的数据,使用消费队列的时候,可以根据偏移量消费历史的记录。
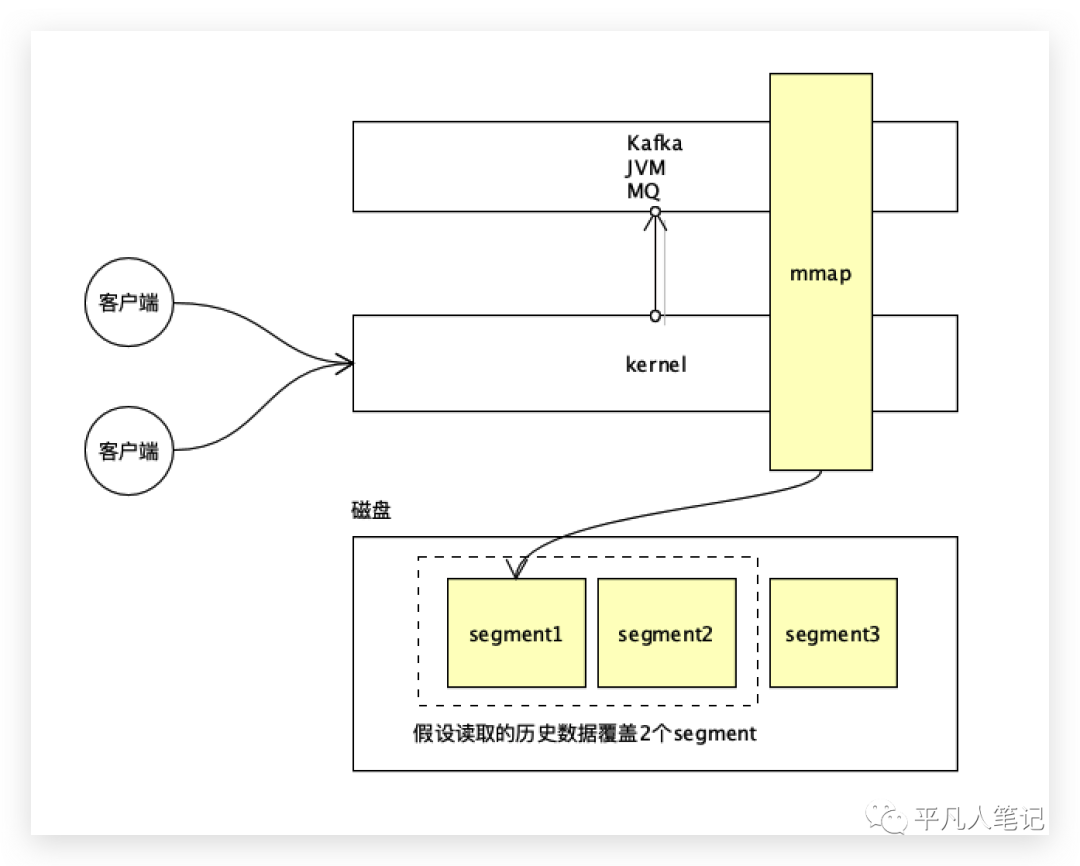
历史数据可以是占用segment1这1G的文件段,也可能是要读取的数据存放在2个不同的段中,而mmap映射了一个segment,其他的segment段是没有做mmap内存映射的。
再开一个mmap,就不太合适了,需要的内存空间会很大。
用户请求来到内核,再到kafka,kafka解析用户请求数据的偏移量,通过索引知道它的偏移量是在某个文件里面。
程序read读数据,读的是文件描述符,而真正的文件数据是由内核读取的,即并没有从内核拷贝到用户空间。
从磁盘读到内核,再拷贝给kafka进程,这是读磁盘的过程,这里拷贝是文件描述符,并不是文件数据。
进程调用socket write写,将文件描述符传入,即将文件描述符数据从kafka拷贝到内核,然后由内核读取真正的文件数据再经由网卡发送出去,
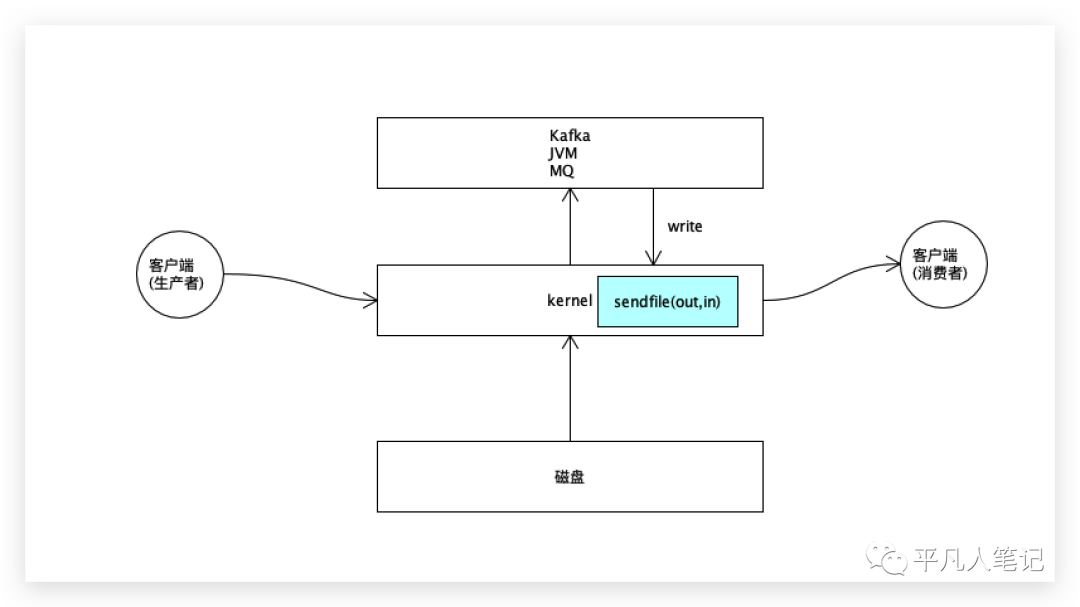
磁盘->内核->程序->内核->网卡(发送出去)。
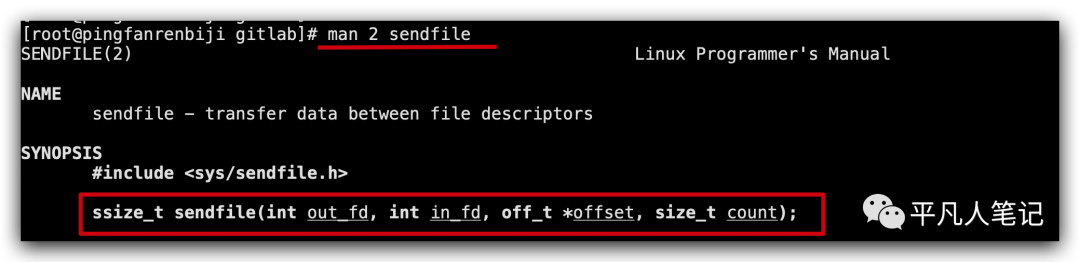
out_fd输出流,in_fd输入流,该方法是在内核中实现的。
程序只需要打开文件,拿到输入流的文件描述符;连接socket,拿到输出流的文件描述符;offset是偏移量;count发送的数据大小。
程序就调用了一下内核,内核读取数据得到输入流,再通过socket输出流经由网卡发送出去,这样减少了数据从内核到程序拷贝过去、再拷贝回来的过程,这叫sendfile零拷贝。
kafka用到了2个系统调用,一个是直接内存映射MMAP,一个是sendfile零拷贝。
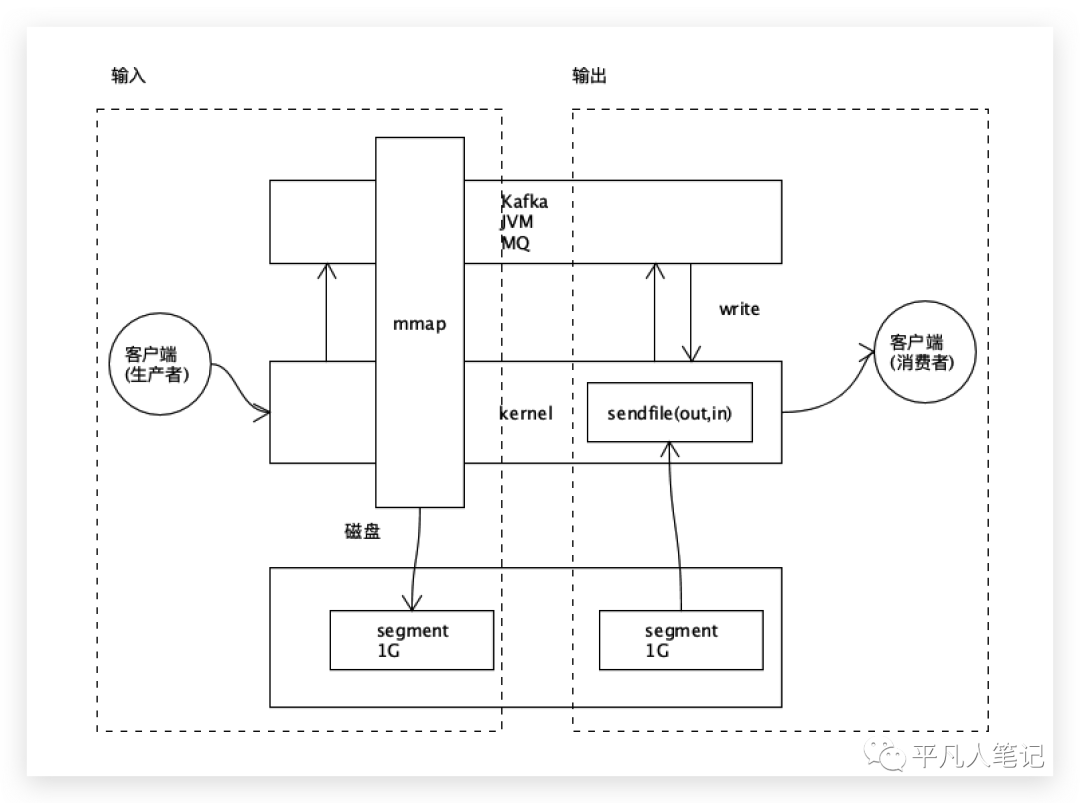
左边是输入,用到了mmap技术;右边是输出,用到了sendfile技术。
nginx是轻量级的web server,配置文件中有一个选项叫sendfile。
web server提供用户浏览图片或页面,这些文件都是放到磁盘上的,用户请求的资源是不需要由程序进行加工处理的,即磁盘上的文件是什么样就返回给用户什么样。
nginx开启sendfile后,nginx读取磁盘中的文件数据,nginx进程只是打开文件得到一个文件描述符,由内核读取该文件,再由内核将数据经过socket连接发送给客户端。

