
分布式服务必问,Kafka分区Leader选举过程原创
上篇文章讲了Kafka Controller的选举过程,Controller的选举是为了保证整个Kafka集群的高可用。
今天讲一下Kafka Leader Replica(领导者副本)的选举过程, Leader Replica选举的目的是为了保证数据在分区副本之间的可靠传输和一致性。
1. Leader Replica简介
先温习一下Leader Replica的知识:
-
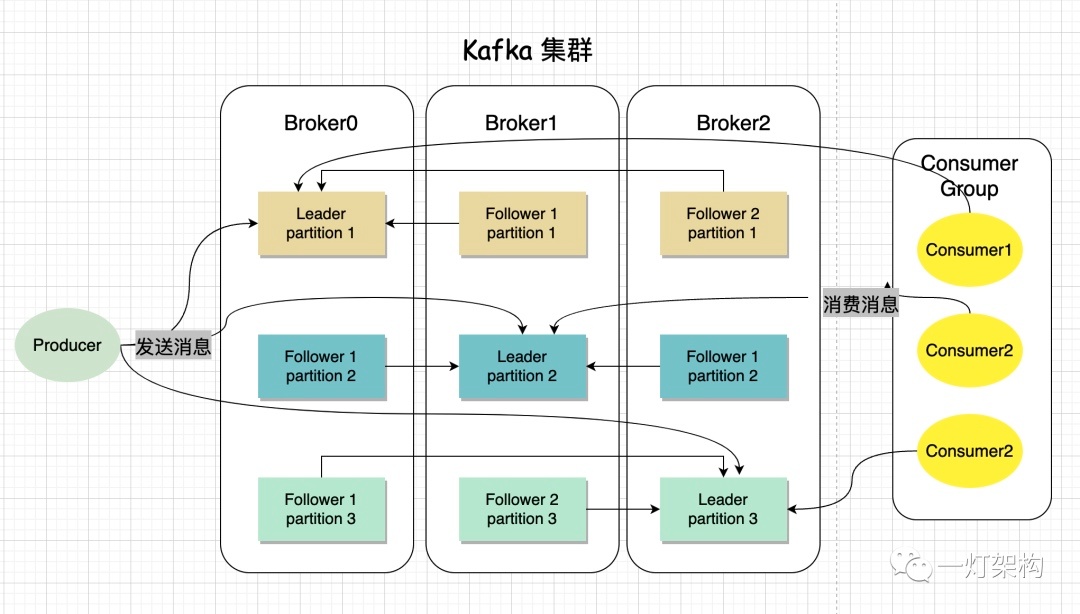
一个Kafka集群包含多个Broker节点,一个Broker节点相当于一台服务器。 -
一个 Topic(主题)包含多个 Partition(分区),Topic是逻辑概念,而Partition是物理分组。 -
一个Partition又包含多个 Replica(副本),Replica之间是一主多从的关系,有两种类型 Leader Replica(领导者副本)和 Follower Replica(跟随者副本),同一个Partition的Replica分布在不同的Broker节点上。 -
Leader Replica负责处理读写请求,Follower Replica只负责同步Leader Replica数据,不对外提供服务。 -
一个Partition的所有Replica集合统称为 AR(Assigned Replicas,已分配的副本),与Leader Replica保持同步的Replica集合称为 ISR(In-Sync Replicas,同步副本),与Leader Replica保持失去同步的Replica集合称为 OSR(Out-of-Sync Replicas,失去同步的副本), AR = ISR + OSR。 -
Leader Replica将消息写入磁盘前,需要等ISR中的所有副本同步完成。如果ISR中某个Follower Replica同步数据落后Leader Replica过多,会被转移到OSR中。如果OSR中的某个Follower Replica同步数据追上了Leader Replica,会被转移到ISR中。当Leader Replica发生故障的时候,只会从ISR中选举出新的Leader Replica。
了解了Leader Replica的基本概念之后,再讲一下什么情况下会触发Leader Replica选举。
2.Leader Replica选举触发时机
常见的有以下几种情况会触发Partition的Leader Replica选举:
-
Leader Replica 失效:当 Leader Replica 出现故障或者失去连接时,Kafka 会触发 Leader Replica 选举。 -
Broker 宕机:当 Leader Replica 所在的 Broker 节点发生故障或者宕机时,Kafka 也会触发 Leader Replica 选举。 -
新增 Broker:当集群中新增 Broker 节点时,Kafka 还会触发 Leader Replica 选举,以重新分配 Partition 的 Leader。 -
新建分区:当一个新的分区被创建时,需要选举一个 Leader Replica。 -
ISR 列表数量减少:当 Partition 的 ISR 列表数量减少时,可能会触发 Leader Replica 选举。当 ISR 列表中副本数量小于 Replication Factor(副本因子)时,为了保证数据的安全性,就会触发 Leader Replica 选举。 -
手动触发:通过 Kafka 管理工具(kafka-preferred-replica-election.sh),可以手动触发选举,以平衡负载或实现集群维护。
3. Leader Replica选举策略
在 Kafka 集群中,常见的 Leader Replica 选举策略有以下三种:
-
ISR 选举策略:默认情况下,Kafka 只会从 ISR 集合的副本中选举出新的 Leader Replica,OSR 集合中的副本不具备参选资格。
-
首选副本选举策略(Preferred Replica Election):首选副本选举策略也是 Kafka 默认的选举策略。在这种策略下,每个分区都有一个首选副本(Preferred Replica),通常是副本集合中的第一个副本。当触发选举时,控制器会优先选择该首选副本作为新的 Leader Replica,只有在首选副本不可用的情况下,才会考虑其他副本。
当然,也可以使用命令手动指定每个分区的首选副本:
bin/kafka-topics.sh --zookeeper localhost:2181 --topic my-topic-name --replica-assignment 0:1,1:2,2:0 --partitions 3意思是:my-topic-name有3个partition,partition0的首选副本是Broker1,partition1首选副本是Broker2,partition2的首选副本是Broker0。
-
不干净副本选举策略(Unclean Leader Election):在某些情况下,ISR 选举策略可能会失败,例如当所有 ISR 副本都不可用时。在这种情况下,可以使用 Unclean Leader 选举策略。Unclean Leader 选举策略会从所有副本中(包含OSR集合)选择一个副本作为新的 Leader 副本,即使这个副本与当前 Leader 副本不同步。这种选举策略可能会导致数据丢失,因此只应在紧急情况下使用。
修改下面的配置,可以开启 Unclean Leader 选举策略,默认关闭。
unclean.leader.election.enable=true
4. Leader Replica选举过程
当Leader Replica宕机或失效时,就会触发 Leader Replica 选举,分为两个阶段,第一个阶段是候选人的提名和投票阶段,第二个阶段是Leader的确认阶段。具体过程如下:
-
候选人提名和投票阶段
在Leader Replica失效时,ISR集合中所有Follower Replica都可以成为新的Leader Replica候选人。每个Follower Replica会在选举开始时向其他Follower Replica发送成为候选人的请求,并附带自己的元数据信息,包括自己的当前状态和Lag值。而Preferred replica优先成为候选人。
其他Follower Replica在收到候选人请求后,会根据请求中的元数据信息,计算每个候选人的Lag值,并将自己的选票投给Lag最小的候选人。如果多个候选人的Lag值相同,则随机选择一个候选人。
-
Leader确认阶段
在第一阶段结束后,所有的Follower Replica会重新计算每位候选人的Lag值,并投票给Lag值最小的候选人。此时,选举的结果并不一定出现对候选人的全局共识。为了避免出现这种情况,Kafka中使用了ZooKeeper来实现分布式锁,确保只有一个候选人能够成为新的Leader Replica。
当ZooKeeper确认有一个候选人已经获得了分布式锁时,该候选人就成为了新的Leader Replica,并向所有的Follower Replica发送一个LeaderAndIsrRequest请求,更新Partition的元数据信息。其他Follower Replica接收到请求后,会更新自己的Partition元数据信息,将新的Leader Replica的ID添加到ISR列表中。
5. 总结
本文介绍了Kafka Leader Replica(领导者副本)的选举过程,包括Leader Replica的基本概念、选举触发时机、选举策略和选举过程。Leader Replica选举的目的是为了保证数据在分区副本之间的可靠传输和一致性,常见的选举触发情况包括Leader Replica失效、Broker宕机、新增Broker、新建分区、ISR列表数量减少和手动触发。常见的选举策略包括ISR选举策略、首选副本选举策略和不干净副本选举策略。选举过程分为候选人提名和投票阶段和Leader确认阶段,其中使用ZooKeeper来实现分布式锁,确保只有一个候选人能够成为新的Leader Replica。

