
答读者问:唯一索引冲突,为什么主键的 supremum 记录会加 next-key 锁?原创
本文缘起于一位读者的提问:插入一条记录,导致唯一索引冲突,为什么会对主键的 supremum 记录加 next-key 排他锁?
我在 MySQL 8.0.32 复现了问题,并调试了加锁流程,写下来和大家分享。
了解完整的加锁流程,有助于我们更深入的理解 InnoDB 的记录锁,希望大家有收获。
本文基于 MySQL 8.0.32 源码,存储引擎为 InnoDB。
目录
-
1. 准备工作
-
2. 问题复现
-
3. 前置知识点:隐式锁
-
4. 流程分析
-
4.1 插入记录到主键、唯一索引
-
4.2 唯一索引记录加锁
-
4.3 回滚语句
-
4.4 主键索引记录的隐式锁转换
-
4.5 主键索引记录的锁转移
-
5. 总结
正文
1. 准备工作
创建测试表:
CREATE TABLE `t6` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`i1` int unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_i1` (`i1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
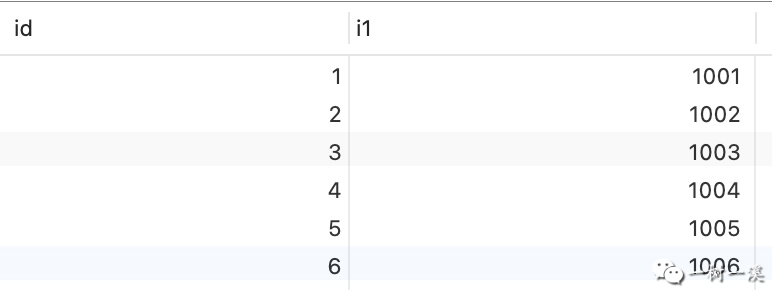
插入测试数据:
INSERT INTO `t6`(i1) VALUES
(1001), (1002), (1003),
(1004), (1005), (1006);
设置事务隔离级别:
在 my.cnf 中,把系统变量 transaction_isolation 设置为 REPEATABLE-READ。
2. 问题复现
插入一条会导致唯一索引冲突的记录:
BEGIN;
INSERT INTO `t6`(i1) VALUES(1001);
通过 BEGIN 显式开启事务,INSERT 执行完成之后,我们可以通过以下 SQL 查看加锁情况:
SELECT
OBJECT_NAME, INDEX_NAME, LOCK_TYPE,
LOCK_MODE, LOCK_STATUS, LOCK_DATA
FROM `performance_schema`.`data_locks`;
结果如下:

唯一索引(uniq_i1):id = 1,i1 = 1001 的记录,加 next-key 共享锁。
主键索引(PRIMARY):supremum 记录,加 next-key 排他锁。
3. 前置知识点:隐式锁
插入记录时,隐式锁是个比较重要的概念,它存在的目的是:减少插入记录时不必要的加锁,提升 MySQL 的并发能力。
我们先来看一下隐式锁的定义:
事务 T 要插入一条记录 R,只要即将插入记录的目标位置没有被其它事务上锁,事务 T 就不需要申请对目标位置加锁,可以直接插入记录。
事务 T 提交之前,如果其它事务出现以下 2 种情况,都必须帮助事务 T 给记录 R 加上排他锁:
-
其它事务执行 UPDATE、DELETE 语句时扫描到了记录 R。 -
其它事务插入的记录和 R 存在主键或唯一索引冲突。
未提交事务 T 插入的记录上,这种隐性的、由其它事务在需要时帮忙创建的锁,就是隐式锁。
隐式锁,就像神话电视剧里的结界。没有触碰到它时,看不见,就像不存在一样,一旦触碰到,它就显现出来了。
隐式锁可能出现于多种场景,我们来看看主键索引的 2 种隐式锁场景:
前提条件:
事务 T1 插入一条记录 R1,即将插入 R1 的目标位置没有被其它事务上锁,事务 T1 可以直接插入 R1。
场景 1:
事务 T1 插入 R1 之后,提交事务之前,事务 T2 试图插入一条记录 R2(主键字段值和 R1 相同)。
事务 T2 给 R2 寻找插入位置的过程中,就会发现 R2 和 R1 冲突,并且插入 R1 的事务 T1 还没有提交,这就触发了 R1 的隐式锁逻辑。
事务 T2 会帮助 T1 给 R1 加上排他锁,然后,它自己会申请对 R1 加共享锁,并等待事务 T1 释放 R1 上的排他锁。
事务 T1 释放 R1 的锁之后,如果事务 T2 没有锁等待超时,它获取到 R1 上的锁之后,就可以继续进行主键冲突的后续处理逻辑了。
场景 2:
事务 T1 插入 R1 之后,提交事务之前,事务 T3 执行 UPDATE 或 DELETE 语句时扫描到了 R1,发现插入 R1 的事务 T1 还没有提交,同样触发了 R1 的隐式锁逻辑。
事务 T3 会帮助 T1 给 R1 加上排他锁,然后,它自己会申请对 R1 加排他锁,并等待事务 T1 释放 R1 上的排他锁。
事务 T1 提交并释放 R1 的锁之后,如果事务 T3 没有锁等待超时,它获取到 R1 上的锁之后,就可以继续对 R1 进行修改或删除操作了。
对隐式锁有了大概了解之后,接下来,我们回到本文主题,来看看 INSERT 执行过程中的加锁流程。
4. 流程分析
我们先来看一下主要堆栈,接下来的流程分析围绕这个堆栈进行:
| > row_insert_for_mysql_using_ins_graph() storage/innobase/row/row0mysql.cc:1585
| + > row_ins_step(que_thr_t*) storage/innobase/row/row0ins.cc:3677
| + - > row_ins(ins_node_t*, que_thr_t*) storage/innobase/row/row0ins.cc:3559
| + - x > row_ins_index_entry_step(ins_node_t*, que_thr_t*) storage/innobase/row/row0ins.cc:3435
| + - x = > row_ins_index_entry() storage/innobase/row/row0ins.cc:3303
| + - x = | > row_ins_sec_index_entry() storage/innobase/row/row0ins.cc:3203
| + - x = | + > row_ins_sec_index_entry_low() storage/innobase/row/row0ins.cc:2926
| + - x = | + - > row_ins_scan_sec_index_for_duplicate() storage/innobase/row/row0ins.cc:1894
| + > row_mysql_handle_errors() storage/innobase/row/row0mysql.cc:701
这个堆栈的关键步骤有 2 个:
-
row_ins_step(),插入记录到主键、唯一索引。 -
row_mysql_handle_errors(),插入失败之后,进行错误处理。
4.1 插入记录到主键、唯一索引
// storage/innobase/row/row0mysql.cc
static dberr_t row_insert_for_mysql_using_ins_graph(...) {
...
// 主要构造用于执行插入操作的 2 个对象:
// 1. ins_node_t 对象,保存在 prebuilt->ins_node 中
// 2. que_fork_t 对象,保存在 prebuilt->ins_graph 中
row_get_prebuilt_insert_row(prebuilt);
node = prebuilt->ins_node;
// 把 server 层的记录格式转换为 InnoDB 的记录格式
row_mysql_convert_row_to_innobase(node->row, prebuilt, mysql_rec, &temp_heap);
...
// 执行插入操作
row_ins_step(thr);
...
if (err != DB_SUCCESS) {
error_exit:
que_thr_stop_for_mysql(thr);
...
// 错误处理
auto was_lock_wait = row_mysql_handle_errors(&err, trx, thr, &savept);
...
return (err);
}
...
}
这个方法的主要逻辑:
-
调用 row_get_prebuilt_insert_row(),构造包含插入数据的 ins_node_t 对象、查询执行图 que_fork_t 对象,分别保存到 prebuilt 的 ins_node、ins_graph 属性中。 -
把 server 层的记录格式转换为 InnoDB 的记录格式。 -
调用 row_ins_step(),插入记录到主键索引、二级索引(包含唯一索引、非唯一索引)。
// storage/innobase/row/row0ins.cc
que_thr_t *row_ins_step(que_thr_t *thr)
{
...
// 重置 node->trx_id_buf 指针指向的内存区域
memset(node->trx_id_buf, 0, DATA_TRX_ID_LEN);
// 把当前事务 ID 拷贝到 node->trx_id_buf 指针指向的内存区域
trx_write_trx_id(node->trx_id_buf, trx->id);
if (node->state == INS_NODE_SET_IX_LOCK) {
...
// 给表加上意向锁
err = lock_table(0, node->table, LOCK_IX, thr);
...
}
...
err = row_ins(node, thr);
...
return (thr);
}
row_ins_step() 调用 row_ins() 插入记录到主键索引、二级索引。
// storage/innobase/row/row0ins.cc
[[nodiscard]] static dberr_t row_ins(...)
{
...
// 迭代表中的索引,插入记录到索引中
while (node->index != nullptr) {
// 只要不是全文索引
if (node->index->type != DICT_FTS) {
// 调用 row_ins_index_entry_step()
// 插入记录到当前迭代的索引中
err = row_ins_index_entry_step(node, thr);
switch (err) {
// 执行成功,跳出 switch
// 会接着进行下一轮迭代
case DB_SUCCESS:
break;
// 存在主键索引或唯一索引冲突
case DB_DUPLICATE_KEY:
thr_get_trx(thr)->error_state = DB_DUPLICATE_KEY;
thr_get_trx(thr)->error_index = node->index;
// 贯穿到 default 分支
[[fallthrough]];
default:
// 返回错误码 DB_DUPLICATE_KEY
return err;
}
}
// 插入记录到主键索引或二级索引成功
// node->index、entry 指向表中的下一个索引
node->index = node->index->next();
node->entry = UT_LIST_GET_NEXT(tuple_list, node->entry);
...
}
...
}
row_ins() 的主要逻辑是个 while 循环,逐个迭代表中的索引,每迭代一个索引,都把构造好的记录插入到索引中。迭代完全部索引之后,插入一条记录到表中的操作就完成了。
接下来,我们通过示例 SQL 来看看 row_ins() 的具体执行流程。
-- 为了方便,这里再展示下测试表和示例 SQL
CREATE TABLE `t6` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`i1` int unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_i1` (`i1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
INSERT INTO `t6`(i1) VALUES(1001);
测试表 t6 有两个索引:主键索引、uniq_i1(唯一索引),对于示例 SQL,上面代码中的 while 会进行 2 轮迭代:
第 1 轮,调用 row_ins_index_entry_step(),插入记录到主键索引。示例 SQL 没有指定主键字段值,主键字段会使用自增值,不会和表中原有记录冲突,插入操作能执行成功。
第 2 轮,调用 row_ins_index_entry_step(),插入记录到 uniq_i1。新插入记录的 i1 字段值为 1001,和表中原有记录(id = 1)的 i1 字段值相同,会导致唯一索引冲突。
row_ins_index_entry_step() 插入记录到 uniq_i1,导致唯一索引冲突,它会返回错误码 DB_DUPLICATE_KEY 给 row_ins()。
row_ins() 拿到错误码之后,它的执行流程到此结束,把错误码返回给调用者。
当执行流程带着错误码(DB_DUPLICATE_KEY)一路返回到 row_insert_for_mysql_using_ins_graph(),接下来会调用 row_mysql_handle_errors() 处理唯一索引冲突的善后逻辑(这部分留到 4.3 回滚语句再聊)。
介绍唯一索引冲突的善后逻辑之前,我们以 row_ins_sec_index_entry_low() 为入口,一路跟随执行流程进入 row_ins_sec_index_entry_low(),来看看给唯一索引中冲突记录加 next-key 共享锁的流程。
这里的 next-key 共享锁,就是下图中 LOCK_DATA = 1001,1 对应的锁。

4.2 唯一索引记录加锁
// storage/innobase/row/row0ins.cc
dberr_t row_ins_sec_index_entry_low(...) {
...
if (dict_index_is_spatial(index)) {
// 处理空间索引的逻辑
...
} else {
if (index->table->is_intrinsic()) {
// MySQL 内部临时表
...
} else {
// 找到记录将要插入到哪个位置
btr_cur_search_to_nth_level(index, 0, entry, PAGE_CUR_LE, search_mode,
&cursor, 0, __FILE__, __LINE__, &mtr);
}
}
...
// 索引中需要用几个(n_unique)字段
// 才能唯一标识一条记录
n_unique = dict_index_get_n_unique(index);
// 如果是主键索引或唯一索引
if (dict_index_is_unique(index) &&
// 并且即将插入的记录
// 和索引中的记录相同
(cursor.low_match >= n_unique || cursor.up_match >= n_unique)) {
...
// 判断新插入记录是否会导致冲突
// 如果会导致冲突,会对冲突记录加锁
err = row_ins_scan_sec_index_for_duplicate(flags, index, entry, thr, check,
&mtr, offsets_heap);
...
}
...
}
row_ins_sec_index_entry_low() 找到插入记录的目标位置之后,如果发现这个位置已经有一条相同的记录了,说明有可能导致唯一索引冲突,调用 row_ins_scan_sec_index_for_duplicate() 确认是否冲突,并根据情况进行加锁处理。
// storage/innobase/row/row0ins.cc
[[nodiscard]] static dberr_t row_ins_scan_sec_index_for_duplicate(...)
{
...
// SQL 语句是否包含解决主键、唯一索引冲突的逻辑
allow_duplicates = row_allow_duplicates(thr);
...
do {
...
if (flags & BTR_NO_LOCKING_FLAG) {
/* Set no locks when applying log in online table rebuild. */
} else if (allow_duplicates) {
...
// 如果 SQL 语句包含解决主键、唯一索引冲突的逻辑
// 给冲突记录加排他锁(LOCK_X)
err = row_ins_set_rec_lock(LOCK_X, lock_type, block, rec, index, offsets,
thr);
} else /* else_1 */ {
if (skip_gap_locks) {
// 如果是数据字典表、SDI 表
// 决定加什么锁,忽略
...
} else if (is_supremum) {
/* We use next key lock to possibly combine the locks in bitmap.
Equivalent to LOCK_GAP. */
// next-key 锁
lock_type = LOCK_ORDINARY;
} else if (is_next) {
/* Only gap lock is required on next record. */
// gap 锁
lock_type = LOCK_GAP;
} else /* else_2 */ {
/* Next key lock for all equal keys. */
// next-key 锁
lock_type = LOCK_ORDINARY;
}
...
// SQL 语句【不包含】解决主键、唯一索引冲突的逻辑
// 给冲突记录加共享锁(LOCK_S)
err = row_ins_set_rec_lock(LOCK_S, lock_type, block, rec, index, offsets,
thr);
}
...
if (is_supremum) {
continue;
}
// !index->allow_duplicates = true
// 即 index->allow_duplicates = false
// 表示不允许索引中存在重复记录
// 调用 row_ins_dupl_error_with_rec()
// 确定新插入记录是否会导致索引冲突
if (!is_next && !index->allow_duplicates) {
if (row_ins_dupl_error_with_rec(rec, entry, index, offsets)) {
// 返回 true,说明会导致索引冲突
// 把错误码赋值给 err 变量
// 作为方法的返回值
err = DB_DUPLICATE_KEY;
...
goto end_scan;
}
} else /* else_3 */ {
ut_a(is_next || index->allow_duplicates);
goto end_scan;
}
} while (pcur.move_to_next(mtr));
end_scan:
/* Restore old value */
dtuple_set_n_fields_cmp(entry, n_fields_cmp);
return err;
}
以下 3 种 SQL,allow_duplicates = true,表示 SQL 包含解决主键、唯一索引冲突的逻辑:
-
load datafile replace -
replace into -
insert ... on duplicate key update
解决冲突的方式:
-
load datafile replace、replace into,删除表中的冲突记录,插入新记录。 -
insert ... on duplicate key update,用 update 后面的各字段值更新表中冲突记录对应的字段。
如果 SQL 包含解决主键、唯一索引冲突的逻辑,会更新或删除冲突记录,所以需要加排他锁(LOCK_X)。
对于示例 SQL,allow_duplicates = false,执行流程会进入 else_1 分支。
因为示例 SQL 不包含解决主键、唯一索引冲突的逻辑,不会更新、删除冲突记录,所以,只需要对冲突记录加共享锁(LOCK_S),加锁的精确模式为 next-key 锁(对应 else_2 分支)。
和变量 allow_duplicates 的含义不同,if (!is_next && !index->allow_duplicates) 中的 index->allow_duplicates 表示唯一索引是否允许存在重复记录:
-
对于 MySQL 内部临时表的二级索引,index->allow_duplicates = true。 -
对于其它表,index->allow_duplicates = false。
对于示例 SQL,if (!is_next && !index->allow_duplicates) 条件成立,调用 row_ins_dupl_error_with_rec() 得到返回值 true,说明新插入记录和唯一索引中的原有记录冲突。
执行流程进入 if (row_ins_dupl_error_with_rec(rec, entry, index, offsets)) 分支,设置变量 err 的值为 DB_DUPLICATE_KEY。
那么,问题来了:插入记录到唯一索引时,发现插入目标位置已经有一条相同的记录了,这不能说明新插入记录和唯一索引中原有记录冲突吗?
还真不能,因为唯一索引有个特殊场景要处理,那就是 NULL 值。
InnoDB 认为 NULL 表示未知,NULL 和 NULL 也是不相等的,所以,唯一索引中可以包含多条字段值为 NULL 的记录。
本文中,唯一索引都是指的二级索引。InnoDB 主键的字段值是不允许为 NULL 的。
举个例子:对于测试表 t6,假设某条记录的 i1 字段值为 NULL,新记录的 i1 字段值也为 NULL,就可以插入成功,而不会报 Duplicate key 错误。
4.3 回滚语句
row_ins_step() 执行结束之后,row_insert_for_mysql_using_ins_graph() 从 trx->error_state 中得到错误码 DB_DUPLICATE_KEY,说明新插入记录导致唯一索引冲突,调用 row_mysql_handle_errors() 处理冲突的善后逻辑,堆栈如下:
| > row_mysql_handle_errors(...) storage/innobase/row/row0mysql.cc:701
| + > // 插入记录导致唯一索引冲突,需要回滚
| + > trx_rollback_to_savepoint(trx_t*, trx_savept_t*) storage/innobase/trx/trx0roll.cc:151
| + - > trx_rollback_to_savepoint_low(trx_t*, trx_savept_t*) storage/innobase/trx/trx0roll.cc:114
| + - x > que_run_threads(que_thr_t*) storage/innobase/que/que0que.cc:1001
| + - x = > que_run_threads_low(que_thr_t*) storage/innobase/que/que0que.cc:966
| + - x = | > que_thr_step(que_thr_t*) storage/innobase/que/que0que.cc:913
| + - x = | + > row_undo_step(que_thr_t*) storage/innobase/row/row0undo.cc:362
| + - x = | + - > row_undo(undo_node_t*, que_thr_t*) storage/innobase/row/row0undo.cc:296
| + - x = | + - x > row_undo_ins(undo_node_t*, que_thr_t*) storage/innobase/row/row0uins.cc:500
| + - x = | + - x = > row_undo_ins_remove_clust_rec(undo_node_t*) storage/innobase/row/row0uins.cc:118
| + - x = | + - x = | > row_convert_impl_to_expl_if_needed(btr_cur_t*, undo_node_t*) storage/innobase/row/row0undo.cc:338
| + - x = | + - x = | + > // 把主键索引记录上的隐式锁转换为显式锁
| + - x = | + - x = | + > lock_rec_convert_impl_to_expl(...) storage/innobase/lock/lock0lock.cc:5544
| + - x = | + - x = | + - > lock_rec_convert_impl_to_expl_for_trx(...) storage/innobase/lock/lock0lock.cc:5496
| + - x = | + - x = | + - x > lock_rec_add_to_queue(...) storage/innobase/lock/lock0lock.cc:1613
| + - x = | + - x = | + - x = > lock_rec_other_has_expl_req(...) storage/innobase/lock/lock0lock.cc:900
| + - x = | + - x = | + - x = > // 创建锁结构
| + - x = | + - x = | + - x = > RecLock::create(trx_t*, lock_prdt const*) storage/innobase/lock/lock0lock.cc:1356
| + - x = | + - x = | > // 先进行乐观删除,如果乐观删除失败,后面会进行悲观删除
| + - x = | + - x = | > btr_cur_optimistic_delete(...) storage/innobase/include/btr0cur.h:466
| + - x = | + - x = | + > btr_cur_optimistic_delete_func(...) storage/innobase/btr/btr0cur.cc:4562
| + - x = | + - x = | + - > lock_update_delete(...) storage/innobase/lock/lock0lock.cc:3350
| + - x = | + - x = | + - x > // 刚刚插入的记录,因为唯一索引冲突需要删除,让它的下一条记录继承 GAP 锁
| + - x = | + - x = | + - x > lock_rec_inherit_to_gap(...) storage/innobase/lock/lock0lock.cc:2588
| + - x = | + - x = | + - x = > lock_rec_add_to_queue(...) storage/innobase/lock/lock0lock.cc:1681
| + - x = | + - x = | + - x = | > // 为被删除的主键记录的下一条记录创建锁结构
| + - x = | + - x = | + - x = | > RecLock::create(trx_t*, lock_prdt const*) storage/innobase/lock/lock0lock.cc:1356
row_mysql_handle_errors() 的核心逻辑是个 switch,根据不同的错误码进行相应的处理。
// storage/innobase/row/row0mysql.cc
bool row_mysql_handle_errors(...)
{
...
switch (err) {
...
case DB_DUPLICATE_KEY:
...
if (savept) {
/* Roll back the latest, possibly incomplete insertion
or update */
trx_rollback_to_savepoint(trx, savept);
}
/* MySQL will roll back the latest SQL statement */
break;
...
}
...
}
对于错误码 DB_DUPLICATE_KEY,row_mysql_handle_errors() 会调用 trx_rollback_to_savepoint() 回滚示例 SQL 对于主键索引所做的插入记录操作。
savept 是调用 row_ins_step() 插入记录到主键、唯一索引之前的保存点,trx_rollback_to_savepoint() 可以利用 savept 中的保存点,删除 row_ins_step() 刚刚插入到主键索引中的记录,让主键索引回到 row_ins_step() 执行之前的状态。
对于示例 SQL,trx_rollback_to_savepoint() 经过多级之后,调用 row_undo_ins_remove_clust_rec() 删除已插入到主键索引的记录。
// storage/innobase/row/row0uins.cc
[[nodiscard]] static dberr_t row_undo_ins_remove_clust_rec(
undo_node_t *node) /*!< in: undo node */
{
...
// 把新插入到主键索引中的记录上的隐式锁
// 转换为显式锁
row_convert_impl_to_expl_if_needed(btr_cur, node);
// 先进行乐观删除
if (btr_cur_optimistic_delete(btr_cur, 0, &mtr)) {
err = DB_SUCCESS;
goto func_exit;
}
...
// 如果乐观删除失败,再进行悲观删除
btr_cur_pessimistic_delete(&err, false, btr_cur, 0, true, node->trx->id,
node->undo_no, node->rec_type, &mtr, &node->pcur,
nullptr);
}
删除主键索引记录之前,需要给它加锁。因为插入操作包含隐式锁的逻辑,所以这里的加锁操作是把即将被删除记录上的隐式锁转换为显式锁。
当然,需要满足一定的条件,row_convert_impl_to_expl_if_needed() 才会把主键索引中即将被删除记录上的隐式锁转换为显式锁。
// storage/innobase/row/row0undo.cc
void row_convert_impl_to_expl_if_needed(btr_cur_t *cursor, undo_node_t *node) {
...
// 满足以下 3 种条件之一,不需要把隐式锁转换为显式锁:
// 1. !node->partial = true,即 node->partial = false
// 表示整个事务回滚
// 2. node->trx == nullptr
// 3. node->trx->isolation_level < trx_t::REPEATABLE_READ
// 事务隔离级别为:读未提交(RU)、读已提交(RC)
if (!node->partial || (node->trx == nullptr) ||
node->trx->isolation_level < trx_t::REPEATABLE_READ) {
return;
}
...
// 满足以下 4 种条件,需要把隐式锁转换显式锁:
// 1. heap_no 对应的记录不是 supremum
// 2. 当前索引不是空间索引
// 3. 不是用户临时表
// 4. 不是 MySQL 内部临时表
if (/* 1 */ heap_no != PAGE_HEAP_NO_SUPREMUM &&
/* 2 */ !dict_index_is_spatial(index) &&
/* 3 */ !index->table->is_temporary() &&
/* 4 */ !index->table->is_intrinsic()) {
lock_rec_convert_impl_to_expl(block, rec, index,
Rec_offsets().compute(rec, index));
}
}
对于示例 SQL,第 1 个 if 条件不成立,所以不会执行 return,而是会继续判断第 2 个 if 条件。
第 2 个 if 条件成立,执行流程进入 if 分支,调用 lock_rec_convert_impl_to_expl() 把隐式锁转换为显式锁。
执行流程回到 row_undo_ins_remove_clust_rec(),调用 row_convert_impl_to_expl_if_needed() 把主键索引中即将被删除记录上的隐式锁转换为显式锁之后,接下就是删除记录了。
先调用 btr_cur_optimistic_delete() 进行乐观删除。
乐观删除指的是删除数据页中的记录之后,不会因为数据页中的记录数量过少而触发相邻的数据页合并。
如果乐观删除成功,直接返回 DB_SUCCESS。
如果乐观删除失败,再调用 btr_cur_pessimistic_delete() 进行悲观删除。
悲观删除指的是删除数据页中的记录之后,因为数据页中的记录数量过少,会触相邻的数据页合并。
4.4 主键索引记录的隐式锁转换
上一小节中,我们没有深入介绍主键索引中即将被删除记录上的隐式锁转换为显式锁的逻辑,接下来,我们来看看这个逻辑。
// storage/innobase/lock/lock0lock.cc
void lock_rec_convert_impl_to_expl(...) {
trx_t *trx;
...
// 主键索引
if (index->is_clustered()) {
trx_id_t trx_id;
// 获取 rec 记录中 DB_TRX_ID 字段的值
// 拿到插入 rec 记录的事务 ID
trx_id = lock_clust_rec_some_has_impl(rec, index, offsets);
// 判断事务是否处于活跃状态
// 如果事务是活跃状态,返回事务的 trx_t 对象
// 如果事务已提交,返回 nullptr
trx = trx_rw_is_active(trx_id, true);
} else { // 二级索引
...
}
if (trx != nullptr) {
ulint heap_no = page_rec_get_heap_no(rec);
...
// 如果事务是活跃状态
// 把 rec 记录上的隐式锁转换为显式锁
lock_rec_convert_impl_to_expl_for_trx(block, rec, index, offsets, trx,
heap_no);
}
}
InnoDB 主键索引的记录中,都有一个隐藏字段 DB_TRX_ID。
lock_rec_convert_impl_to_expl() 先调用 lock_clust_rec_some_has_impl() 读取主键索引中即将被删除记录的 DB_TRX_ID 字段。
然后调用 trx_rw_is_active() 判断 DB_TRX_ID 对应的事务是否处于活跃状态(事务未提交)。
如果事务处于活跃状态,调用 lock_rec_convert_impl_to_expl_for_trx() 把 rec 记录上的隐式锁转换为显式锁。
// storage/innobase/lock/lock0lock.cc
static void lock_rec_convert_impl_to_expl_for_trx(...)
{
...
{
locksys::Shard_latch_guard guard{UT_LOCATION_HERE, block->get_page_id()};
...
trx_mutex_enter(trx);
...
// 判断事务的状态不是 TRX_STATE_COMMITTED_IN_MEMORY
if (!trx_state_eq(trx, TRX_STATE_COMMITTED_IN_MEMORY) &&
// heap_no 对应记录上没有显式的排他锁
!lock_rec_has_expl(LOCK_X | LOCK_REC_NOT_GAP, block, heap_no, trx)) {
ulint type_mode;
// 加锁粒度:记录(LOCK_REC)
// 加锁模式:写锁(LOCK_X)
// 加锁的精确模式:记录(LOCK_REC_NOT_GAP)
type_mode = (LOCK_REC | LOCK_X | LOCK_REC_NOT_GAP);
lock_rec_add_to_queue(type_mode, block, heap_no, index, trx, true);
}
trx_mutex_exit(trx);
}
trx_release_reference(trx);
...
}
lock_rec_convert_impl_to_expl_for_trx() 也不会照单全收,它还会进一步判断:
-
事务状态不是 TRX_STATE_COMMITTED_IN_MEMORY,因为处于这个状态的事务就算是已经提交成功了,已提交成功的事务修改的记录不包含隐藏式锁逻辑,也就不需要把隐式锁转换为显式锁了。 -
记录上没有显式的排他锁。
满足上面 2 个条件之后,才会调用 lock_rec_add_to_queue() 创建锁对象(RecLock)并加入到全局锁对象的 hash 表中,这就最终完成了把主键索引中即将被删除记录上的隐式锁转换为显式锁。
4.5 主键索引记录的锁转移
主键索引中即将被删除记录上的显式锁,只是个过渡,它是用来为锁转移做准备的。
不管是乐观删除,还是悲观删除,删除刚插入到主键索引的记录之前,需要把该记录上的锁转移到它的下一条记录上,转移操作由 lock_update_delete() 完成。
// storage/innobase/lock/lock0lock.cc
void lock_update_delete(const buf_block_t *block, const rec_t *rec) {
...
if (page_is_comp(page)) {
// 获取即将被删除的记录的编号
heap_no = rec_get_heap_no_new(rec);
// 获取即将被删除记录的下一条记录的编号
next_heap_no = rec_get_heap_no_new(page + rec_get_next_offs(rec, true));
} else {
...
}
...
/* Let the next record inherit the locks from rec, in gap mode */
// 把即将被删除记录上的锁转移到它的下一条记录上
lock_rec_inherit_to_gap(block, block, next_heap_no, heap_no);
...
}
lock_update_delete() 调用 rec_get_heap_no_new() 获取即将被删除记录的下一条记录的编号,然后调用 lock_rec_inherit_to_gap() 把即将被删除记录上的锁转移到它的下一条记录上。
// storage/innobase/lock/lock0lock.cc
static void lock_rec_inherit_to_gap(...)
{
lock_t *lock;
...
// heap_no 是主键索引中即将被删除的记录编号
for (lock = lock_rec_get_first(lock_sys->rec_hash, block, heap_no);
lock != nullptr; lock = lock_rec_get_next(heap_no, lock)) {
/* Skip inheriting lock if set */
if (lock->trx->skip_lock_inheritance) {
continue;
}
if (!lock_rec_get_insert_intention(lock) &&
!lock->index->table->skip_gap_locks() &&
(!lock->trx->skip_gap_locks() || lock->trx->lock.inherit_all.load())) {
lock_rec_add_to_queue(LOCK_REC | LOCK_GAP | lock_get_mode(lock),
heir_block, heir_heap_no, lock->index, lock->trx);
}
}
}
for 循环中,lock_rec_get_first() 获取主键索引中即将被删除记录上的锁。
能否获取到锁,取决于前面的 row_convert_impl_to_expl_if_needed() 是否已经把记录上的隐式锁转换为显式锁。
row_convert_impl_to_expl_if_needed() 会对多个条件进行判断,以决定是否把记录上的隐式锁转换为显式锁。其中,比较重要的判断条件是事务隔离级别:
-
如果事务隔离级别是 READ-COMMITTED,隐式锁不转换为显式锁。 -
如果事务隔离级别是 REPEATABLE-READ,再结合其它判断条件,决定是否把隐式锁转换为显式锁。
我们以测试表和示例 SQL 为例,来看看 lock_rec_inherit_to_gap() 的执行流程。
示例 SQL 执行于 REPEATABLE-READ 隔离级别之下,并且满足其它判断条件,row_convert_impl_to_expl_if_needed() 会把记录上的隐式锁转换为显式锁。
所以,lock_rec_get_first() 会获取到主键索引中即将被删除记录上的锁,并且 for 循环中的第 2 个 if 条件成立,执行流程进入 if 分支。
对于示例 SQL,即将被删除记录的下一条记录是 supremum,调用 lock_rec_add_to_queue() 把即将被删除记录上的锁转移到 supremum 记录上。
接下来,介绍 lock_rec_add_to_queue() 代码之前,我们先看一下传给该方法的第 1 个参数的值。
lock_get_mode() 会返回即将被删除记录上的锁:LOCK_REC_NOT_GAP | LOCK_REC | LOCK_X。
第 1 个参数的值为:LOCK_REC | LOCK_GAP | lock_get_mode(lock)。
把 lock_get_mode() 的返回值代入其中,得到:LOCK_REC | LOCK_GAP | LOCK_REC_NOT_GAP | LOCK_REC | LOCK_X。
去重之后,得到传给 lock_rec_add_to_queue() 的第 1 个参数(type_mode)的值:LOCK_REC | LOCK_GAP | LOCK_REC_NOT_GAP | LOCK_X。
// storage/innobase/lock/lock0lock.cc
static void lock_rec_add_to_queue(ulint type_mode, ...) {
...
// 对 supremum 伪记录进行特殊处理
if (heap_no == PAGE_HEAP_NO_SUPREMUM) {
...
// 去掉 LOCK_GAP、LOCK_REC_NOT_GAP
type_mode &= ~(LOCK_GAP | LOCK_REC_NOT_GAP);
}
...
// 实例化锁对象
RecLock rec_lock(index, block, heap_no, type_mode);
...
// 把锁对象加入全局锁对象 hash 表
rec_lock.create(trx);
...
}
type_mode 就是 lock_rec_inherit_to_gap() 函数中传过来的第 1 个参数,它的值为:LOCK_REC | LOCK_GAP | LOCK_REC_NOT_GAP | LOCK_X。
对于示例 SQL,即将被删除记录的下一条记录是 supremum,执行流程会命中 if (heap_no == PAGE_HEAP_NO_SUPREMUM) 分支,执行代码:type_mode &= ~(LOCK_GAP | LOCK_REC_NOT_GAP)。
从 type_mode 中去掉 LOCK_GAP、LOCK_REC_NOT_GAP,得到 LOCK_REC | LOCK_X,表示给 supremum 加 next-key 排他锁。
5. 总结
REPEATABLE-READ 隔离级别下,如果插入一条记录,导致唯一索引冲突,执行流程如下:
-
插入记录到主键索引,成功。 -
插入记录到唯一索引,冲突,插入失败。 -
给唯一索引中冲突的记录加锁。
对于 load datafile replace、replace into、insert ... on duplicate key update 语句,加排他锁(LOCK_X)。
对于其它语句,加共享锁(LOCK_S)。 -
把主键索引中对应记录上的隐式锁转换为显式锁 [Not RC]。 -
把主键索引记录上的显式锁转移到它的下一条记录上 [Not RC]。 -
删除主键索引记录。
顺便说一下,对于 READ-COMMITTED 隔离级别,大体流程相同,不同之处在于,它没有上面流程中打了 [Not RC] 标记的两个步骤。
对于示例 SQL,READ-COMMITTED 隔离级别下,不会给主键索引的 supremum 记录加锁,加锁情况如下:

最后,把示例 SQL 在 REPEATABLE-READ 隔离级别下的加锁情况放在这里,作个对比:

有想了解的 MySQL 知识点或想交流的问题可以关注我公众号:一树一溪


