
编译程序是一种翻译程序,编译程序是将一种语言形式翻译成另一种语言形式。它将高级语言所写的源程序翻译成等价的机器语言或汇编语言的目标程序。
整个编译过程一般可以划分为 5 个阶段:词法分析、语法分析、语义分析及中间代码生成、中间代码优化和目标代码生成。我们以一个简单的程序段为例,分别介绍这 5 个阶段所完成的任务。例如,计算圆柱体表面积的程序段如下:
float r,h,s;
s = 2 * 3.1416 * r * (h + r);
词法分析
词法分析阶段的任务是对构成源程序的字符串进行从左到右的扫描和分解,根据语言的词法规则,识别出一个一个具有独立意义的单词(也称单词符号,简称符号)。
语言的词法规则是单词符号的形成规则,它规定了哪些字符串构成一个单词符号。上述源程序通过词法分析,根据语言的词法规则识别出如下单词符号:
- 基本字(关键字) float
- 标识符 r,h,s
- 常数 3.1416,2
- 运算符 *,+
- 界符 () ; ,
单词符号的类型有:关键字、标识符、常数、运算符、界符。
语法分析
语法分析的任务是在词法分析的基础上,根据语言的语法规则,从单词符号串中识别出各种语法单位(如表达式、说明、 语句等)并进行语法检查,即检查各种语法单位在语法结构上的正确性。
语言的语法规则是语法单位的形成规则。它规定了如何从单词符号形成语法单位。上述源程序通过语法分析,根据语言的语法规则识别单词符号串 s = 2 * 3.1416 * r * (h + r),其中 s 是 <变量>,单词符号串 2 * 3.1416 * r * (h + r) 组合成 <表达式 > 这样的语法单位, 则由 <变量> = <表达式> 构成 <赋值语句> 这样的语法单位。在识别各类语法单位的同时进行语法检查,可以看到上述源程序是一个语法上正确的程序。
语义分析及中间代码生成
定义一种语言除了要求定义语法外,还要求定义其语义,即对语言的各种语法单位赋予具体的意义。
语义分析的任务是首先对每种语法单位进行静态的语义审查,然后分析其含义,并用另一种语言形式(比源语言更接近于目标语言的一种中间代码或直接用目标语言)来描述这种语义。例如,上述源程序中,赋值语句的语义为:计算赋值号右边表达式的值,并把它送到赋值号左边的变量所确定的内存单元中。语义分析时,先检查赋值号右边表达式和左边变量的类型是否一致,然后再根据赋值语句的语义,对它进行翻译可得到如下形式的四元式中间代码:
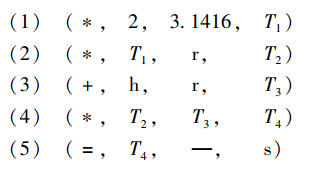
其中,T1、T2、T3、T4 是编译程序引进的临时变量,存放每条指令的运算结果。上述每一个四元式所表示的语义为:

这样,我们将源语言形式的赋值语句翻译为四元式表示的另一种语言形式,这两种语言在结构形式上是不同的,但在语义上是等价的。
中间代码优化
中间代码优化的任务是对前阶段产生的中间代码进行等价变换或改造,以期获得更为高效的,节省时间和空间的目标代码。优化主要包括局部优化和循环优化等,例如上述四元式经局部优化后得:
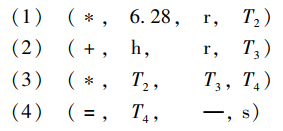
其中,2 和 3.1416 两个运算对象都是编译时的已知量,在编译时就可计算出它的值 6.28,而不必等到程序运行时再计算,即不必生成(*,2,3.1416,T1)的运算指令。
目标代码生成
目标代码生成的任务是将中间代码变换成特定机器上的绝对指令代码或可重定位的指令代码或汇编指令代码。
表格管理 & 错误处理
在编译程序的各个阶段中,都要涉及表格管理和错误处理。
编译程序的重要功能之一,是记录源程序中所使用的变量的名字,并且收集与名字属性相关的各种信息。名字属性包括一个名字的存储分配、类型、作用域等信息。如果名字是一个函数名,还会包括其参数数量、类型、参数的传递方式以及返回类型等信息。符号表数据结构可以为变量名字创建记录条目,来登记源程序中所提供的或在编译过程中所产生的这些信息,编译程序在工作过程的各个阶段需要构造、查找、修改或存取有关表格中的信息,因此在编译程序中必须有一组管理各种表格的程序。
如果编译程序只处理正确的程序,那么它的设计和实现将会大大简化。但是程序设计人员还期望编译程序能够帮助定位和跟踪错误。无论程序员如何努力,程序中难免总会有错误出现。虽然错误很常见,但很少有语言在设计的时候就考虑到错误处理问题。大部分程序设计语言的规范没有规定编译程序应该如何处理错误;错误处理方法由编译程序的设计者决定。 因此,从一开始就计划好如何进行错误处理,不仅可以简化编译程序的结构,还可以改进错误处理方法。一个好的编译程序在编译过程中, 应具有广泛的程序查错能力,并能准确地报告错误的种类及出错位置,以便用户查找和纠正,因此在编译程序中还必须有一个出错处理程序。
编译程序
编译过程的这 5 个阶段的任务分别由 5 个程序完成,这 5 个程序分别称为词法分析程序、语法分析程序、语义分析及中间
代码生成程序、中间代码优化程序和目标代码生成程序,另外再加上表格管理程序和出错处理程序。这些程序便是编译程
序的主要组成部分,一个典型编译程序的结构框图如图所示。
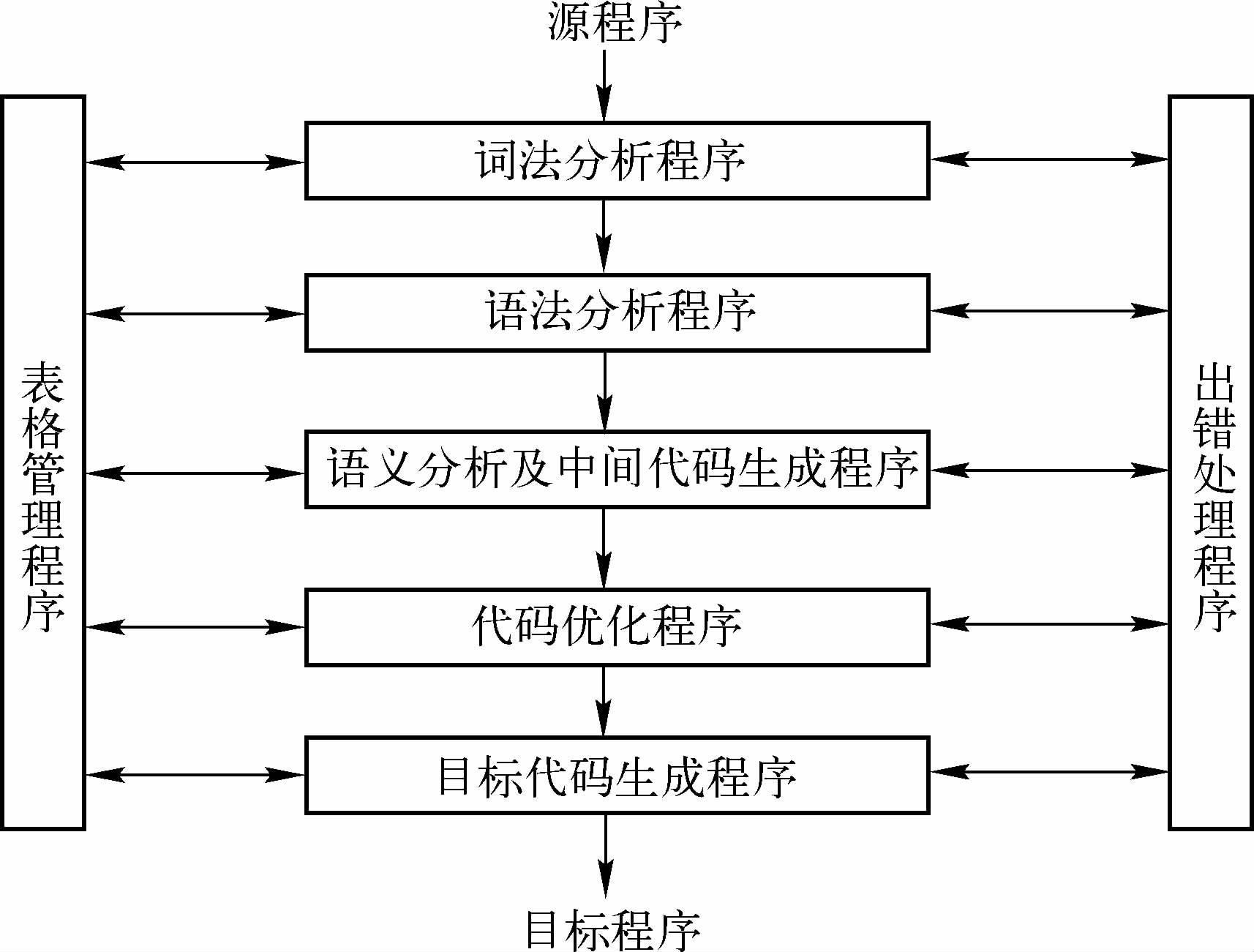
需要注意的是,图中所给出的各个阶段之间的关系是指它们之间的逻辑关系,不一定是执行时间上的先后关系。实际
上,可按不同的执行流程来组织上述各阶段的工作,这在很大程度上依赖于编译过程中对源程序扫描的遍数以及如何划分各遍扫描所进行的工作。
此处所说的 “遍”,是指对源程序或其等价的中间语言程序从头到尾扫描一遍,并完成规定加工处理工作的过程。例如,可以将前述 5 个阶段的工作结合在一起,对源程序从头到尾扫描一遍来完成编译的各项工作,这种编译程序称为一遍扫描的编译程序。对于某些程序设计语言,用一遍扫描的编译程序去实现比较困难,可采用多遍扫描的编译程序结构,每遍可完成上述某个阶段的一部分、全部或多个阶段的工作,且每一遍的工作是从前一遍获得的工作结果开始的,最后一遍的工作结果是目标语言程序,第一遍的输入则是用户书写的源程序。
多遍扫描的编译程序较一遍扫描的编译程序少占存储空间,遍数多一些,可使各遍所要完成的功能独立而单纯,其编译程序逻辑结构清晰,但遍数多势必增加输入输出开销,这将降低编译效率。一个编译程序究竟应分成几遍和它所面临的源语言的特征、机器规模、设计的目标等因素有关,很难统一划定。一般在主存可能的前提下,还是遍数少一点为好。
参考资料
《编译原理(第4版)》1.2 编译过程和编译程序的基本结构

