
【全网首发】抽丝剥茧,记一次 Go 程序性能优化之旅原创
大家好,我是小楼。
在之前的文章《一言不合就重构》中介绍了我重构的一个服务健康检查系统,这个系统自上线开始就有一个问题:健康检查耗时有点高。但一直拖着没解决,究其原因只能拿出下面这张图。

背景介绍
在开始本文前,让大家快速进入状态,我们提取最简单的背景。
健康检查系统每隔一段时间会向目标服务器发送健康检查请求,当失败达到一定条件(例如连续3次失败),则将该目标从注册中心中摘除。
我们遇到一个问题:健康检查的耗时高。
虽然我们支持各种各样的健康检查请求,但这里主要还是 TCP 健康检查,也就是对目标服务发起 TCP 建连请求耗时比较高。多高呢?几毫秒到几十毫秒,甚至几百毫秒,平均下来40多毫秒。看着感觉还可以,但要知道 TCP 建连只需要三次握手,而且是内网,这样看来,确实离谱。
必要性
上面说了,慢就慢点,又不是不能用,为啥还要折腾呢?
这是因为有更多的服务要接入这个系统,比如原先是 Nginx 自带的主动健康检查也需要替换为这个系统。
但原先 Nginx 上配置的健康检查超时时间大多是 50 ~ 100ms,如果平迁到我这个系统,就可能出问题,由于检查耗时比较高,这些配置大概率会超时,导致服务被误摘。
如果把超时时间改大行不行呢?也不行,如果业务服务负载不均或单机有抖动导致耗时增高,原先的 Nginx 能发现并把不正常的节点摘除,但如果迁移到我的健康检查系统,就没法做到这点。
综上,还是很有必要查一下为什么建立一个 TCP 连接这么慢?
查监控
这次问题神奇之处是,监控上没有任何异常,包括 CPU、内存、磁盘、网络等一系列指标均无异常,甚至还表现的非常优秀,就只有健康检查耗时高。
找不同
首先,对比我们的程序和 Nginx 的主动健康检查,有什么区别,总结了几点:
-
Nginx 是 C 语言编写,我们的程序是 Go 编写; -
Nginx 部署在物理机上,我们的程序部署在 Docker 上; -
Nginx 上健康的服务量级比较少,我们的程序单机需要检查上万台目标服务;
做试验
基于这些不同点,我做了2个小实验:
-
在物理机上部署这个健康检查系统,对一个服务进行健康检查,对比 Docker 容器上相同目标检查耗时发现,物理机耗时只有几毫秒; -
在另一个 Docker 上部署,也只对这个服务进行检查,发现耗时也只有几毫秒;
大胆猜测,检查耗时可能和检查的量级有关,并且我们的程序是有潜力达到和 Nginx 相当的水平的,大不了堆机器嘛。

怀疑协程调度
检查一个目标地址,需要开一个协程,量级大小就代表了 Go 协程数量级,于是猜测是不是 Go 协程调度导致耗时高?
所以怎么看 Go 协程调度花费了多少时间?查找资料,发现 Go Trace 工具可以看到调度耗时,前提是 Go 版本 >= 1.5,且开启 pprof,刚好我们都达到了。
采集数据:
curl -o trace.dump 'http://127.0.0.1:8600/debug/pprof/trace?seconds=30'
查看:
go tool trace trace.dump
具体介绍和简单使用可以参考这篇文章:《深入浅出 Go trace》。
比如我这里拿到了这样的结果:
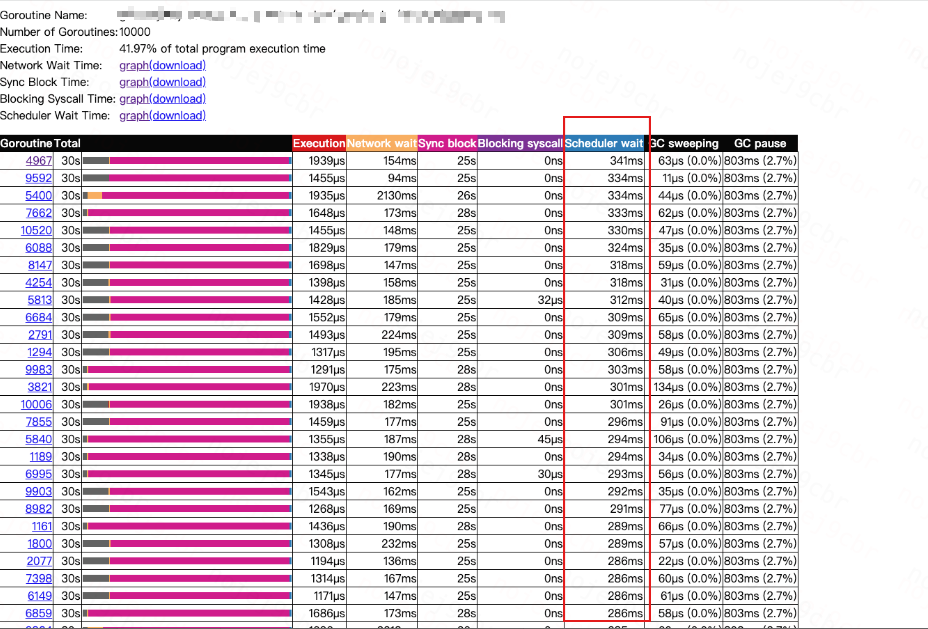
采集了30s,单个协程在 30s 的运行中调度花费了300ms,感觉很多。
于是我又搜索,Go 协程调度什么情况下会慢,还真就让我找到了这篇文章:
《Go gomaxprocs 调高引起调度性能损耗》 https://cloud.tencent.com/developer/article/1848155
摘出重点:
在微服务体系下服务的部署通常是放在 docker 里的。一个宿主机里跑着大量的不同服务的容器。为了避免资源冲突,通常会合理地对每个容器做 cpu 资源控制。比如给一个 golang 服务的容器限定了 2 cpu core 的资源,容器内的服务不管怎么折腾,也确实只能用到大约 2 个 cpu core 的资源。
但 golang 初始化 processor 数量是依赖 /proc/cpuinfo 信息的,容器内的 cpuinfo 是跟宿主机一致的,这样导致容器只能用到 2 个 cpu core,但 golang 初始化了跟物理 cpu core 相同数量的 processor。
...
runtime processor 多了会出现什么问题?
一个是 runtime findrunnable 时产生的损耗,另一个是线程引起的上下文切换。
看到这里想到当年做 Java 上云时也遇到类似的问题,上云后 Java GC 线程数开了和物理机核数相同的数量,导致 GC 时上下文切换严重。
于是写个简单的 Go 程序,在容器上输出 GOMAXPROCS,发现果然是物理机的核数。怎么解决?我又查了一些资料,发现了这个库:
https://github.com/uber-go/automaxprocs
只要引入这个库,就能自动设置正确的 GOMAXPROCS,兼容各种环境。这就好办了,改好代码上线,一顿操作下来,发现耗时并没有肉眼可见的变化。

怀疑 GC
检查量级的不同必然带来内存分配和 GC 的压力,而且 Nginx 是 c 写的,手动释放内存,比高级语言自动 GC 要强很多,所以这里有必要怀疑一下。
这次还是用 trace 的看一下,专门挑了建立连接的 goroutine:

不看不知道,一看吓一跳,GC 暂停时间普遍占比很高,最高达到了100%,离谱!
于是点进去看看 GC 到底花在哪里?
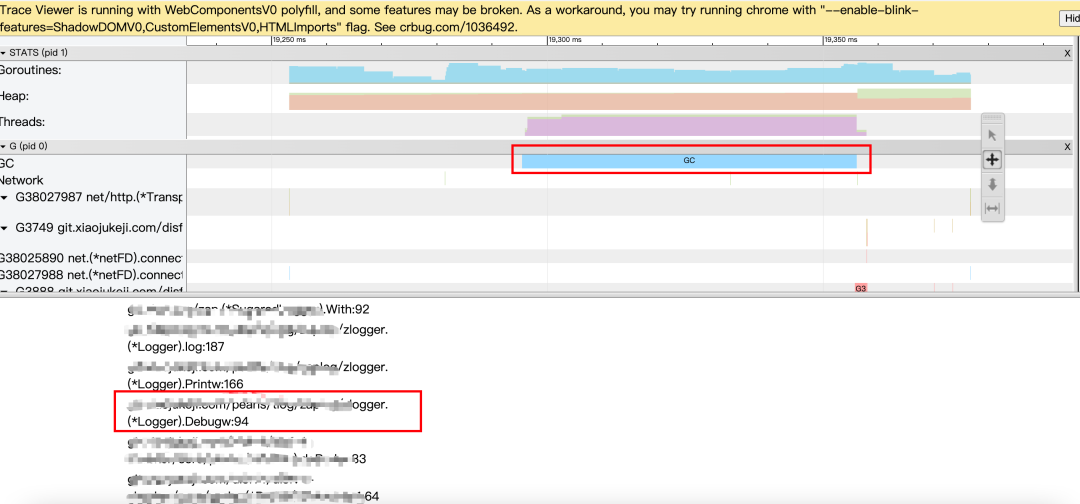
随手点了几个,发现主要是2个点:
-
Debug 日志 -
Metric 上报
Debug 日志是用于定位线上问题的,直接关掉即可,有问题时再打开,由于这是我们自己实现的一个日志库,没有动态调整日志级别的能力,于是我给它加了一个动态调整日志级别的功能,平时关闭,需要时再打开。
关掉 Debug 日志平均耗时由40ms下降到了30ms。

再次 dump trace,发现耗时高的基本就是 metric 上报了,日志这部分 GC 不再出现,通过 heap dump 也能发现内存使用最多的是 metric 了,但这部分优化空间很小,因为这个库不是我们维护,只能去掉一些不必要的 metric,再就是扩容了。
原先我们是10台 8C16G 的 Docker,扩容到 20 台,发现平均耗时一下从 30ms 下降到 10ms:
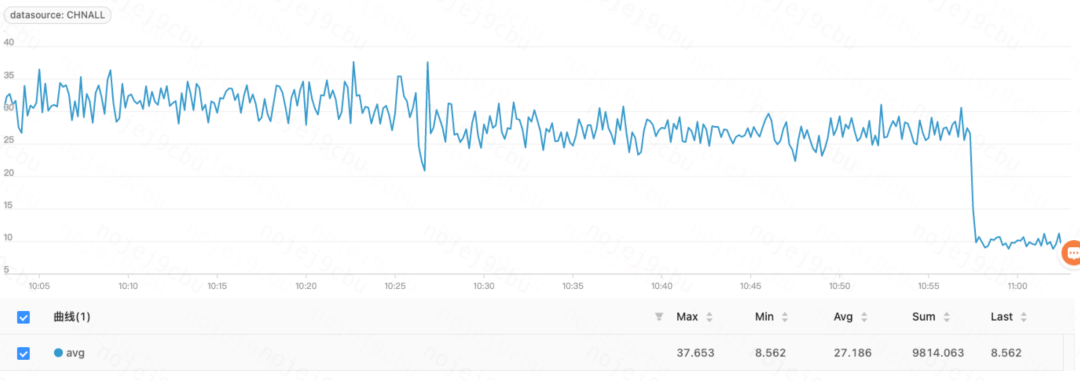
虽然这样扩容能解决问题,但成本也不少,仔细观察内存使用情况,其实并没有使用多少内存,CPU 也是,资源其实还是极大地浪费了,于是我尝试把容器配置由 8C16G 换成 4C8G,结果发现效果一样,也就是说用相同的资源,耗时只有之前的 1/4。
GC 参数调整
到这里,我在想,Go 的 GC 能不能调整参数呢?于是我又查了一些资料,发现只有一个参数 GOGC 可以调整,这个参数代表了内存涨百分之多少进行一次 GC,例如200表示内存翻倍时进行一次 GC,越高则 GC 频率越低。于是我测试了100~1000,发现500时表现较好,平均耗时由10ms下降至8ms,效果有但没那么明显。
至于这里面的理论支撑依据,由于篇(我)幅(也)有(不)限(懂),可以在以后的文章中细说。
最后
优化到这里,基本能满足需求,没必要再优化,实在不行,还可以扩容。最终的成绩是在资源不变的情况下平均耗时由40ms下降到8ms,某个服务的耗时由120ms下降到10ms,效果非常明显。
整个过程其实不需要太多理论知识,只要善于使用工具,先猜测再实践论证,一层一层抽丝剥茧,终会搞定。
搜索关注微信公众号"捉虫大师",后端技术分享,架构设计、性能优化、源码阅读、问题排查、踩坑实践 进技术交流群加微信 MrRoshi


