
不要用 in + 子查询原创
你好,我是yes。
前两天我的 VIP 用户向我抛出了一个 SQL 问题,他的 MySQL 是 8.x版本:
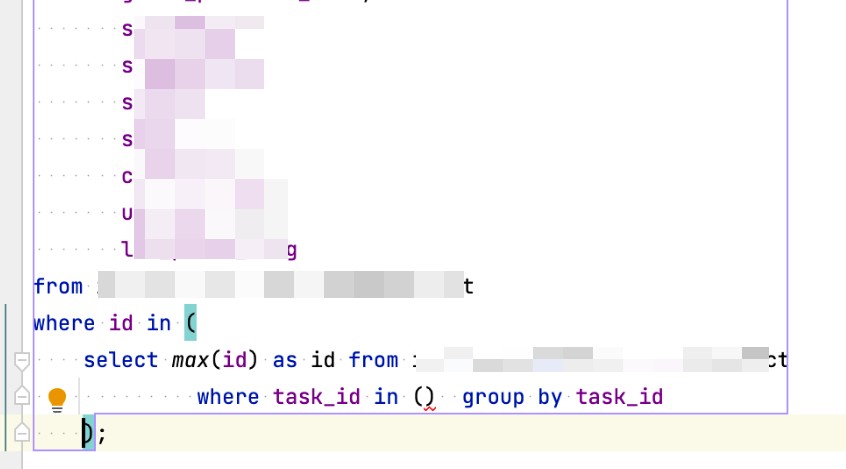
大概意思如下 sql :
select * from A where id in (
select max(id) as id from A
where task_id in(1,2,3)
group by task_id
);
这个 A 表中是有 task_id 这个索引的。
一眼看去这个查询没啥问题,子查询里会利用 task_id 这个索引,然后外面的这个查询会上 id 这个主键索引。
而事实是:

一看 explain ,果然走了全表扫描:

那么问题来了:明明有主键索引不用,mysql 为什么要选择全表?
我也不知道。

对将要执行的 SQL 而言,优化器会有成本模型,它会根据当前表的一些估算值结合当前的 SQL 语句进行打分,比如如果用了索引 A 需要多少 I/O 成本、CPU 成本,如果用索引 B 要多少I/O、CPU成本。
总而言之,它有自己的一套规则,会根据估计值预算成本,根据成本最终生成执行计划。
篇幅有限具体不多介绍,有兴趣的话看下官网:https://dev.mysql.com/doc/refman/8.0/en/cost-model.html
既然是预算,那就有可能不准,所以有时候就会产生该走索引却全表扫描的情况(因为算出的成本走全表扫描反而更低)。
所以针对上面这种情况,我让他加了强制用主键的操作 force index(PRIMARY),但是并没有生效,还是走了全表。
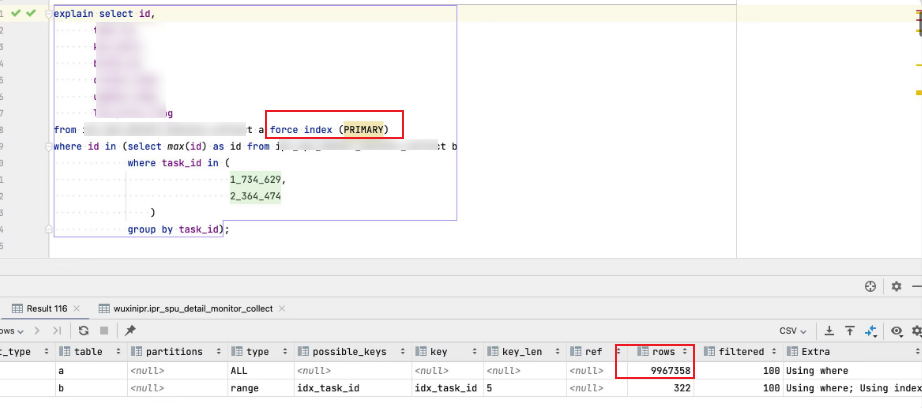
可以看到扫描了大约 996w 行数据(表数据有新增,所以从800w多变成了900多w)。
我自己估计:大致就是因为子查询的结果不确定,MySQL 不知道 in 的值到底有多大,所以保守型的选择了全表(我猜的,具体的逻辑估计得看源码,不过最终表现的事实确实如此)。
问题就在 in 的值大小不确定。
通过子查询,我们自己其实也无法保证 in 的值到底是多少。
所以最后的方案是抛弃 in 的方式,采用 inner join 的方式来改造 sql 实现。
改造 SQL 如下:
select * from A a inner join (
select max(id) as id from A
where task_id in(1,2,3) group by task_id
) b
on a.id = b.id;
这样改造以后,进行了一波 explain,结果如下:
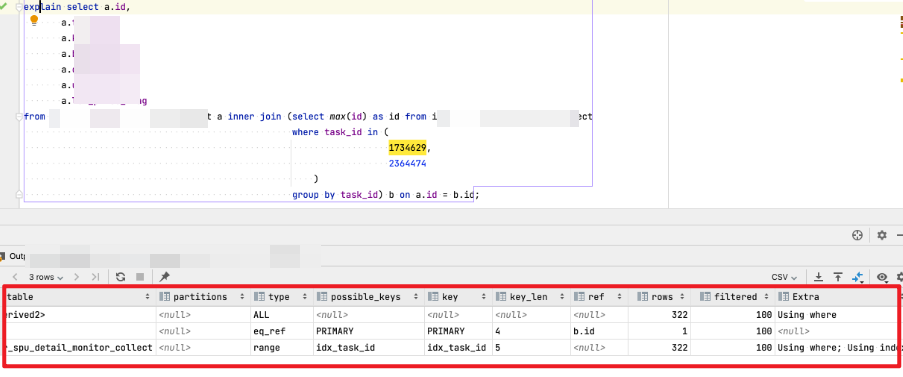
查询结果秒出,可以看下第二行,用上了主键索引,全部扫描的行数加起来也就 600 多。
所以我们换了一种方式来使得 MySQL 正常的用上索引且所要的结果是一致的。
这里也建议,如果 sql 是包含子查询的 in 查询,那么最好换成 join 的方式,因为我们不能保证 in 的查询一定会用上索引,万一来个全表扫描,在表数据量比较大的场景,很容易产生阻塞,多来几个这样的阻塞,数据库连接不可用,服务可能就挂了。
在测试环境看起来没问题,一到生产就 GG。
所以能不用 in + 子查询,就不要用,可以用 join 来替代实现。
我是yes,从一点点到亿点点我们下篇见~


