
分布式ID|源码解析美团Leaf双Buffer优化方案原创
-
分布式ID的使用场景
-
基于MySql的初步方案
-
第一次优化:Leaf-segment数据库方案
-
第二次优化:Leaf-segment 双buffer优化
-
源码解析双buffer优化方案

背景

此时一个能够生成全局唯一ID的系统是非常必要的。
概括下来,那业务系统对ID号的要求有哪些呢?
平均延迟和TP999延迟都要尽可能低;
可用性5个9;
高QPS。
数据库生成
1 begin;
2 REPLACE INTO Tickets64 (stub) VALUES ('a');
3 SELECT LAST_INSERT_ID();
4 commit;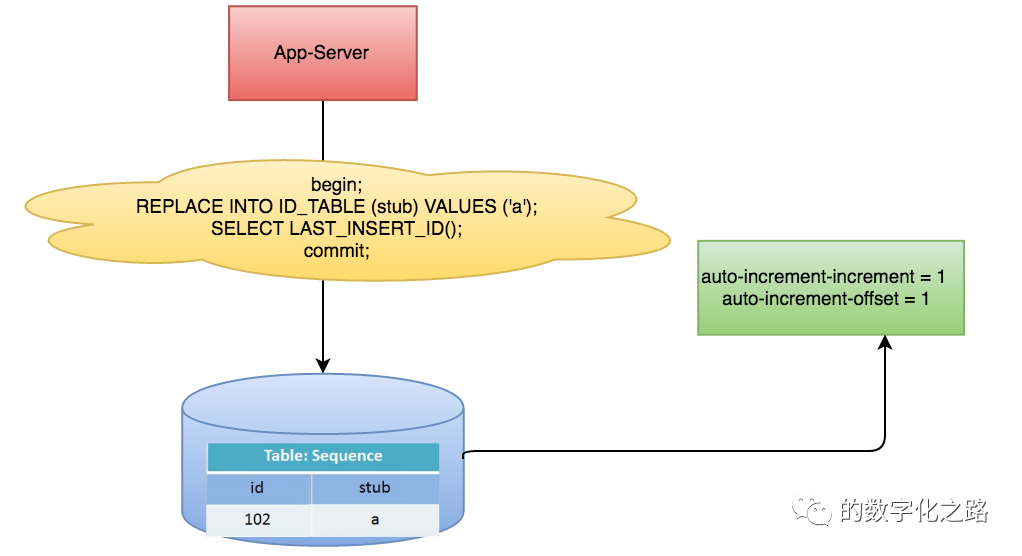
ID号单调自增,可以实现一些对ID有特殊要求的业务。
1 TicketServer1:
2 auto-increment-increment = 2
3 auto-increment-offset = 1
4
5 TicketServer2:
6 auto-increment-increment = 2
7 auto-increment-offset = 2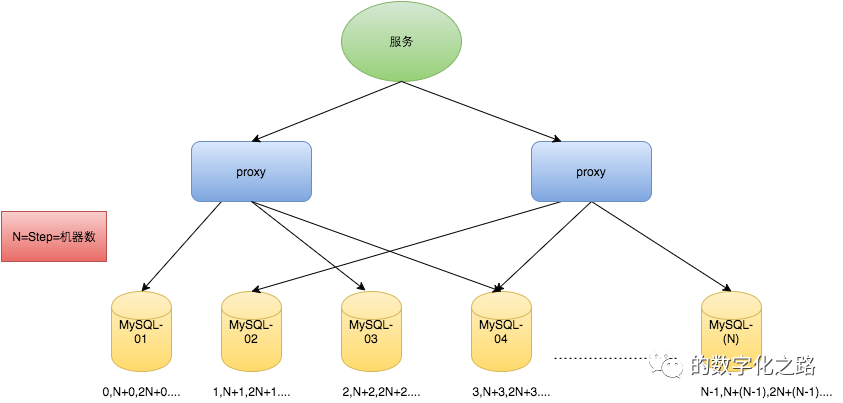
Leaf方案实现
There are no two identical leaves in the world
德国哲学家、数学家莱布尼茨

1 CREATE TABLE `leaf_alloc` (
2 `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
3 `biz_tag` varchar(128) NOT NULL DEFAULT '' COMMENT '标签名',
4 `max_id` bigint(20) NOT NULL DEFAULT '1' COMMENT '目前Segment的id',
5 `step` int(11) NOT NULL COMMENT '步长',
6 `desc` varchar(256) NOT NULL DEFAULT '' COMMENT '描述',
7 `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
8 `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
9 PRIMARY KEY (`id`) USING BTREE,
10 UNIQUE KEY `uk_biz_tag` (`biz_tag`) USING BTREE
11) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4biz_tag用来区分业务,
max_id表示该biz_tag目前所被分配的ID号段的最大值,
step表示每次分配的号段长度。
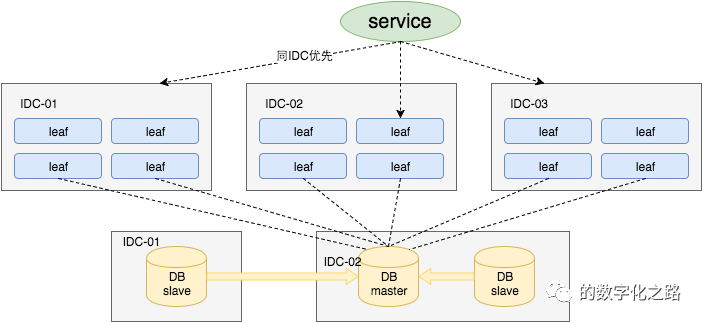
原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step,大致架构如下图所示:
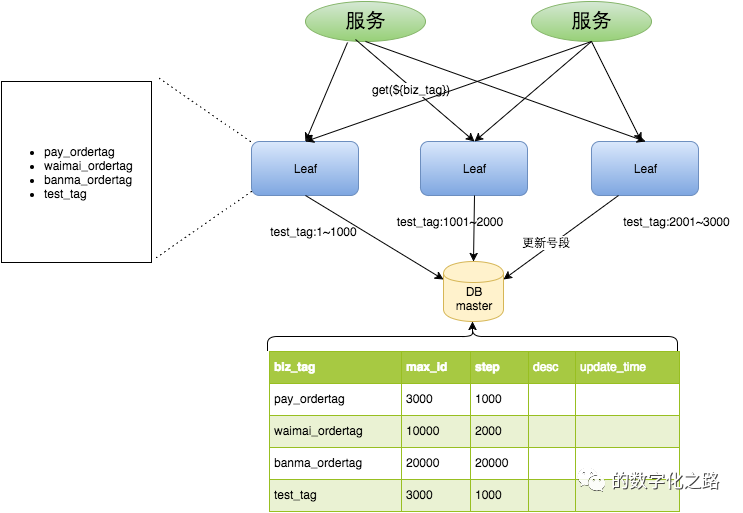
begin
UPDATE leaf_alloc SET max_id=max_id+step WHERE biz_tag=xxx
SELECT tag, max_id, step FROM leaf_alloc WHERE biz_tag=xxx
commit这种模式有以下优缺点:
优点:
Leaf服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景。
ID号码是趋势递增的8byte的64位数字,满足上述数据库存储的主键要求。
容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内Leaf仍能正常对外提供服务。
可以自定义max_id的大小,非常方便业务从原有的ID方式上迁移过来。
缺点:
ID号码不够随机,会泄露发号量信息,不太安全。
TP999数据波动大,当号段使用完之后还是会hang在更新数据库的I/O上,TP999数据会出现偶尔的尖刺。
DB宕机会造成整个系统不可用。
双buffer优化
详细实现如下图所示:
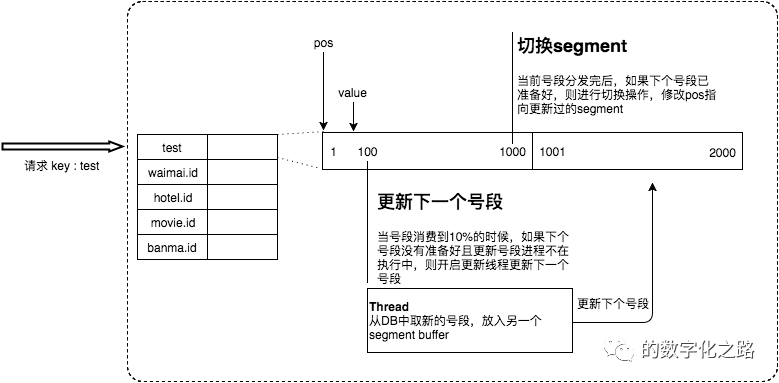

Leaf高可用容灾
当然这种方案在一些情况会退化成异步模式,甚至在非常极端情况下仍然会造成数据不一致的情况,但是出现的概率非常小。
如果你的系统要保证100%的数据强一致,可以选择使用“类Paxos算法”实现的强一致MySQL方案,如MySQL 5.7前段时间刚刚GA的MySQL Group Replication。
双buffer优化方案的源码解析
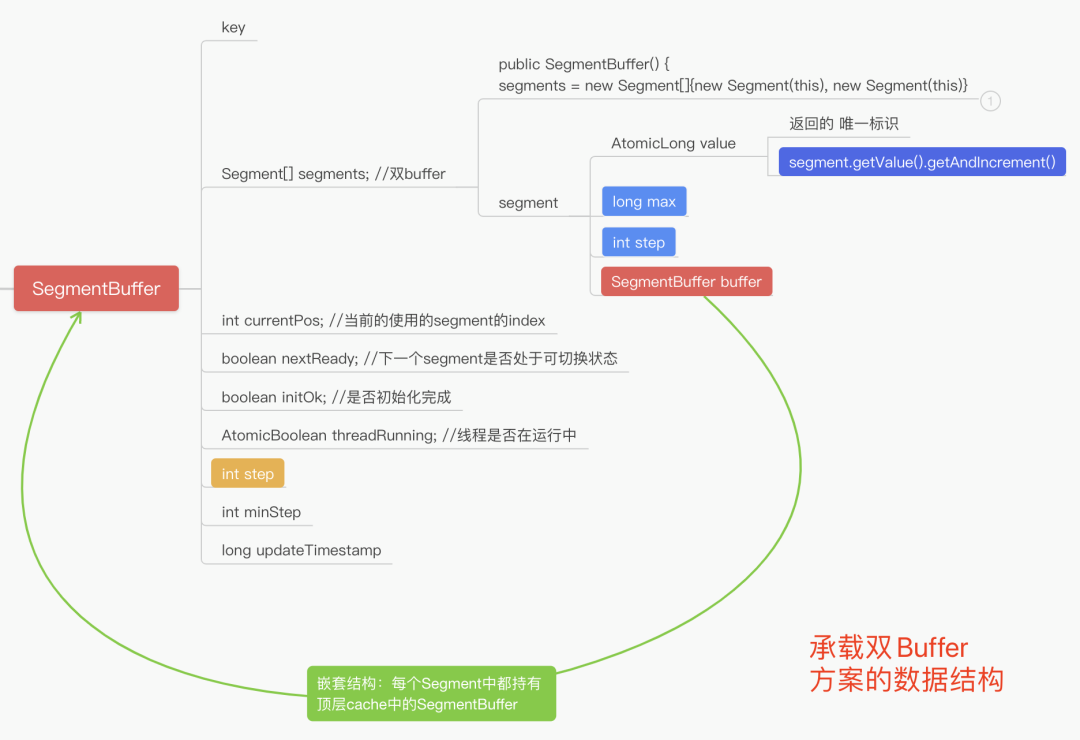
(1)Leaf服务启动时进行数据初始化:
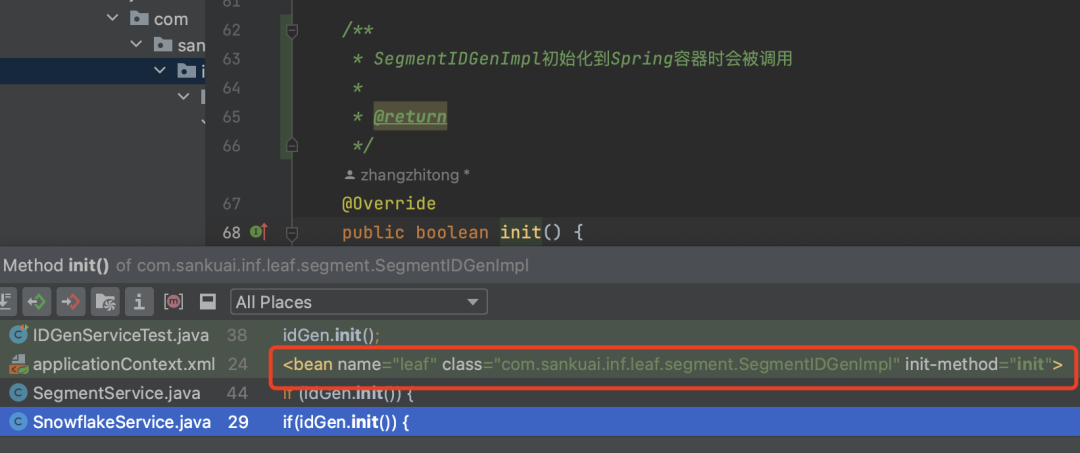
/**
* SegmentIDGenImpl初始化到Spring容器时会被调用
*
* @return
*/
@Override
public boolean init() {
logger.info("Init ...");
// 确保加载到kv后才初始化成功
/**
* 把DB中的biz_tag【key】、max_id、step
* 初始化到jvm中的 Map<String, SegmentBuffer> cache 中
*/
updateCacheFromDb();
/**
* 更新标识initOK
* 说明:
* 使用volatile解决变量initOK对多线程的可见性问题
* private volatile boolean initOK = false;
*/
initOK = true;
/**
* 把DB中新insert的biz_tag【key】、max_id、step
* 加入到Map<String, SegmentBuffer> cache
*/
updateCacheFromDbAtEveryMinute();
return initOK;
}(2)提供分布式ID服务的API
com.sankuai.inf.leaf.server.controller.LeafController#getSegmentId
/**
* 双buffer优化方案API
* 根据key【业务标识(biz_tag)】来生成分布式ID
*
* @param key
* @return 新的ID
*/
@RequestMapping(value = "/api/segment/get/{key}")
public String getSegmentId(@PathVariable("key") String key) {
return get(key, segmentService.getId(key));
}com.sankuai.inf.leaf.segment.SegmentIDGenImpl#get
/**
* 双buffer架构获取分布式ID
*
* @param key 业务标识
* @return 新的分布式ID:业务ID+最大的数字
*/
@Override
public Result get(final String key) {
/**
* 检查数据库里的业务标识biz_tag、步长step、max_id都加载到内存中了
*/
if (!initOK) {
/**
* 没有加载完成,后面没有check的逻辑,得到的分布式ID很大可能性是不对的。
* 要确保服务的确定性,此时抛出异常是合适的
*/
return new Result(EXCEPTION_ID_IDCACHE_INIT_FALSE, Status.EXCEPTION);
}
if (cache.containsKey(key)) {
/**
* 如果业务标识存在,则要使用步长step和max_id来生成分布式ID
*/
SegmentBuffer buffer = cache.get(key);
if (!buffer.isInitOk()) {
/**
* 如果max_id数据没有准备好,则
*/
synchronized (buffer) {
/**
* 不同的Jvm是不同的号段。
* 只需要在jvm范围内确保线程安全即可
*/
if (!buffer.isInitOk()) {
try {
/**
* 更新号段
*/
updateSegmentFromDb(key, buffer.getCurrent());
logger.info("Init buffer. Update leafkey {} {} from db", key, buffer.getCurrent());
buffer.setInitOk(true);
} catch (Exception e) {
logger.warn("Init buffer {} exception", buffer.getCurrent(), e);
}
}
}
}
/**
* 如果数据库里的数据初始化到jvm内存完成,直接getAndIncrement获取自增的id
*/
return getIdFromSegmentBuffer(cache.get(key));
}
/**
* 如果业务标识key在jvm中不存在,则无法继续后续处理,抛异常
*/
return new Result(EXCEPTION_ID_KEY_NOT_EXISTS, Status.EXCEPTION);
}com.sankuai.inf.leaf.segment.SegmentIDGenImpl#updateSegmentFromDb
/**
* 更新号段
* (1)设置号段的起始值:maxId-step
* (2)设置jvm当前号段的maxId
* (3)设置步长step
*
* @param key 指定的业务标识biz_tag
* @param segment 存放了新的号段范围的Segment
*/
public void updateSegmentFromDb(String key, Segment segment) {
StopWatch sw = new Slf4JStopWatch();
SegmentBuffer buffer = segment.getBuffer();
LeafAlloc leafAlloc;
if (!buffer.isInitOk()) {
/**
* 如果jvm中的号段信息没有完成db到jvm的初始化
* 则:
* (1)获取下一个号段的值
* maxId=maxId+step
* (2)更新jvm中的step,有可能step被更新过了
*
* updateMaxIdAndGetLeafAlloc的说明:
* (1)更新maxId
* (2)查询最新maxId,step的操作要在一个事务中。
* 这个地方展开讲一下:此处是使用数据库更新行锁来达到一个全局互斥锁的效果
*
*/
leafAlloc = dao.updateMaxIdAndGetLeafAlloc(key);
buffer.setStep(leafAlloc.getStep());
buffer.setMinStep(leafAlloc.getStep());//leafAlloc中的step为DB中的step
} else if (buffer.getUpdateTimestamp() == 0) {
/**
* 第一次更新号段信息:
* (1)获取下一个号段的值 maxId=maxId+step
* (2)更新jvm中的step,有可能step被更新过了
* (3)更新updateTimestamp
*
* updateMaxIdAndGetLeafAlloc的说明:
* (1)更新maxId
* (2)查询最新maxId,step的操作要在一个事务中。
* 这个地方展开讲一下:此处是使用数据库更新行锁来达到一个全局互斥锁的效果
*
*/
leafAlloc = dao.updateMaxIdAndGetLeafAlloc(key);
buffer.setUpdateTimestamp(System.currentTimeMillis());
buffer.setStep(leafAlloc.getStep());
buffer.setMinStep(leafAlloc.getStep());//leafAlloc中的step为DB中的step
} else {
/**
* 如果号段消费超过预期,且step小于最大步长不超过100,0000
* 则按下面的规则加大step
*/
long duration = System.currentTimeMillis() - buffer.getUpdateTimestamp();
int nextStep = buffer.getStep();
if (duration < SEGMENT_DURATION) {
if (nextStep * 2 > MAX_STEP) {
//do nothing
} else {
nextStep = nextStep * 2;
}
} else if (duration < SEGMENT_DURATION * 2) {
//do nothing with nextStep
} else {
nextStep = nextStep / 2 >= buffer.getMinStep() ? nextStep / 2 : nextStep;
}
logger.info("leafKey[{}], step[{}], duration[{}mins], nextStep[{}]", key, buffer.getStep(), String.format("%.2f", ((double) duration / (1000 * 60))), nextStep);
LeafAlloc temp = new LeafAlloc();
temp.setKey(key);
temp.setStep(nextStep);
/**
*
* updateMaxIdByCustomStepAndGetLeafAlloc说明:
* (1)更新maxId、step
* (2)查询最新maxId,step的操作要在一个事务中。
* 这个地方展开讲一下:此处是使用数据库更新行锁来达到一个全局互斥锁的效果
* 与updateMaxIdAndGetLeafAlloc相比,多更新了step
*/
leafAlloc = dao.updateMaxIdByCustomStepAndGetLeafAlloc(temp);
buffer.setUpdateTimestamp(System.currentTimeMillis());
buffer.setStep(nextStep);
buffer.setMinStep(leafAlloc.getStep());//leafAlloc的step为DB中的step
}
// must set value before set max
/**
* (1)设置号段的起始值:maxId-step
* (2)设置jvm当前号段的maxId
* (3)设置步长step
*/
long value = leafAlloc.getMaxId() - buffer.getStep();
segment.getValue().set(value);
segment.setMax(leafAlloc.getMaxId());
segment.setStep(buffer.getStep());
sw.stop("updateSegmentFromDb", key + " " + segment);
}假设服务QPS为Q,号段长度为L,号段更新周期为T,那么Q * T = L。
最开始L长度是固定的,导致随着Q的增长,T会越来越小。
但是Leaf本质的需求是希望T是固定的。
那么如果L可以和Q正相关的话,T就可以趋近一个定值了。
所以Leaf每次更新号段的时候,根据上一次更新号段的周期T和号段长度step,来决定下一次的号段长度nextStep:
T < 15min,nextStep = step * 2
15min < T < 30min,nextStep = step
T > 30min,nextStep = step / 2至此,满足了号段消耗稳定趋于某个时间区间的需求。当然,面对瞬时流量几十、几百倍的暴增,该种方案仍不能满足可以容忍数据库在一段时间不可用、系统仍能稳定运行的需求。因为本质上来讲,Leaf虽然在DB层做了些容错方案,但是号段方式的ID下发,最终还是需要强依赖DB。
com.sankuai.inf.leaf.segment.SegmentIDGenImpl#getIdFromSegmentBuffer
/**
* 从SegmentBuffer中获取biz_tag对应号段在内存中的最大值
* 最大值超出当前号段的最大值后,要更新jvm中的号段,然后再获取最大值
*
* @param buffer
* @return 当前jvm中biz_tag对应号段在内存中的最大值
*/
public Result getIdFromSegmentBuffer(final SegmentBuffer buffer) {
/**
* 为解决超出jvm已经申领号段范围的问题,增加while(true)
* 1. 如果超过jvm中的号段范围,更新下一个号段
* 2. 将最新的max_id更新到数据库,
* 3、将最新的数据加载到jvm,
* 4、然后再获取当前号段的getAndIncrement
*/
while (true) {
/**
* 使用ReadWriteLock解决getAndIncrement获取最新id时的线程安全问题
*/
buffer.rLock().lock();
try {
final Segment segment = buffer.getCurrent();
if (!buffer.isNextReady() && (segment.getIdle() < 0.9 * segment.getStep()) && buffer.getThreadRunning().compareAndSet(false, true)) {
/**
* 如果(1)下一个号段没有ready
* 且(2)当前号段已下发10%时,如果下一个号段未更新,
* 且(3)更新下一个号段的线程
* 则另启一个更新线程去更新下一个号段
*/
service.execute(new Runnable() {
@Override
public void run() {
/**
* 开始准备下一个号段的号段范围
*/
Segment next = buffer.getSegments()[buffer.nextPos()];
/**
* 一个标识,用来标识下一个号段范围是否更新完成
*/
boolean updateOk = false;
try {
/**
* 执行 更新下一个号段 的操作
*/
updateSegmentFromDb(buffer.getKey(), next);
/**
* 号段范围更新完成,更新标识
*/
updateOk = true;
logger.info("update segment {} from db {}", buffer.getKey(), next);
} catch (Exception e) {
logger.warn(buffer.getKey() + " updateSegmentFromDb exception", e);
} finally {
if (updateOk) {
/**
* 更新状态时,打开写锁。获取id的过程都卡住
*/
buffer.wLock().lock();
/**
* 下一个号段已更新完成
*/
buffer.setNextReady(true);
/**
* 更新号段的线程的状态设置为非运行中
*/
buffer.getThreadRunning().set(false);
/**
* 更新下一个号段的所有状态更新完成,释放写锁,当前jvm可以正常生成指定biz_tag的分布式id
*/
buffer.wLock().unlock();
} else {
/**
* 下一个号段没有更新成功,则将更新线程退出前将线程状态置为false
*/
buffer.getThreadRunning().set(false);
}
}
}
});
}
/**
* getAndIncrement来获取下一个id
*/
long value = segment.getValue().getAndIncrement();
if (value < segment.getMax()) {
/**
* 如果新的id在号段范围内,则获取成功
*/
return new Result(value, Status.SUCCESS);
}
} finally {
/**
* 第一轮获取id,unlock。
* 因为readLock与writeLock是互斥,此处不释放readLock则会阻塞 更新线程去更新下一个号段
*/
buffer.rLock().unlock();
}
/**
* 自旋等待更新号段线程执行完成
*/
waitAndSleep(buffer);
/**
* 因为当前并不能100%确定更新线程已经成功执行完成
* 加写锁。本方法入口处的 buffer.rLock().lock();也会被阻塞
*/
buffer.wLock().lock();
try {
final Segment segment = buffer.getCurrent();
/**
* getAndIncrement获取id
*/
long value = segment.getValue().getAndIncrement();
if (value < segment.getMax()) {
return new Result(value, Status.SUCCESS);
}
/**
* 走到此处,说明更新线程还没有执行完成
*/
if (buffer.isNextReady()) {
/**
* 更新线程操作完成。
* 则切换SegmentBuffer
*/
buffer.switchPos();
/**
* 如果新SegmentBuffer用完了,然后再启动更新线程
* 更新线程的运行状态置为false。
*/
buffer.setNextReady(false);
} else {
/**
* 到此处,说明两个SegmentBuffer都没有ready,是出问题了
*/
logger.error("Both two segments in {} are not ready!", buffer);
return new Result(EXCEPTION_ID_TWO_SEGMENTS_ARE_NULL, Status.EXCEPTION);
}
} finally {
/**
* 释放wLock,不然这个整个方法就会被阻塞了
*/
buffer.wLock().unlock();
}
}
}
com.sankuai.inf.leaf.segment.SegmentIDGenImpl#waitAndSleep
/**
* 自旋等待号段更新线程更新完成
* 最多等待100s
*
* @param buffer
*/
private void waitAndSleep(SegmentBuffer buffer) {
int roll = 0;
while (buffer.getThreadRunning().get()) {
roll += 1;
if (roll > 10000) {
try {
TimeUnit.MILLISECONDS.sleep(10);
break;
} catch (InterruptedException e) {
logger.warn("Thread {} Interrupted", Thread.currentThread().getName());
break;
}
}
}
}详见:https://github.com/helloworldtang/Leaf.git
相关信息汇总
1、可用性5个9

2、什么是聚集索引
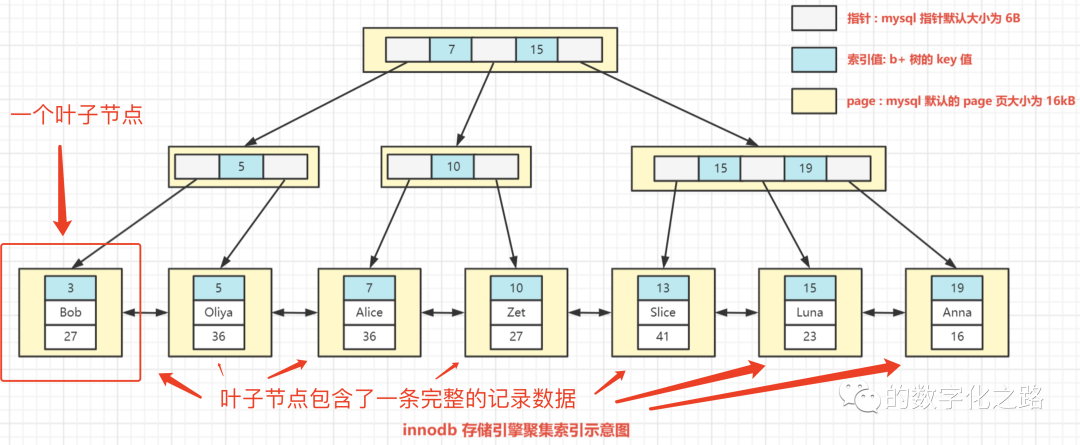
将索引列字段和行记录数据维护在了一起,通过聚集索引能直接获取到整行数据。也就是说,索引的叶子节点包含了完整的一条数据记录。
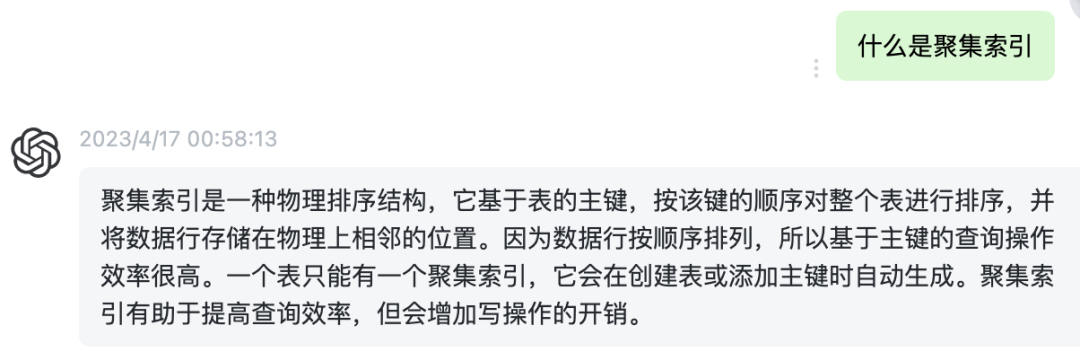
例如数据库中有一张 user 表,id 为主键
那么基于这张表的主键 id 建立的聚集索引,如下图所示
3、非聚集索引

Innodb 以 age 建立的非聚集索引如下图
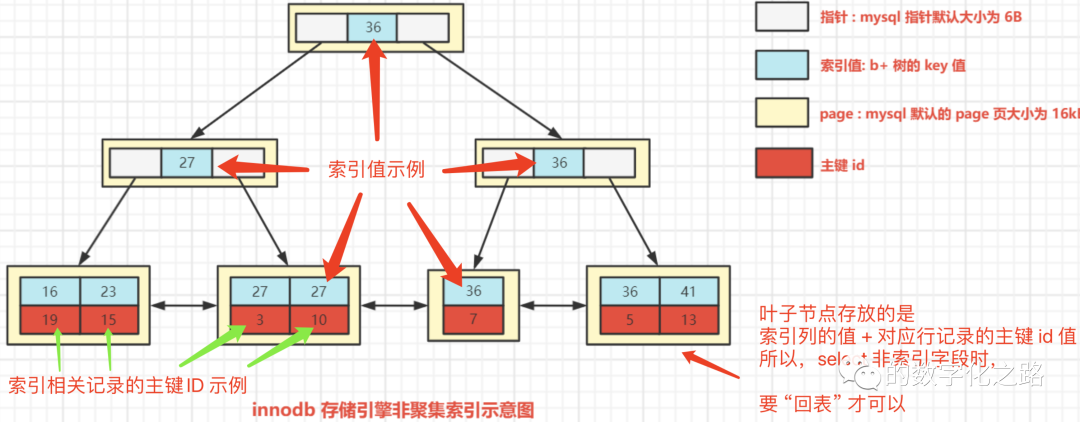

是为了节省磁盘空间 和 保证数据的一致性。


[K2,K5]
/ \
[K0,K1] [K3,K4,K6,K7]
/ | | | \
[--,K0] [K0,K1] [K1,K2] [K2,K3] [K3,K4,K5] [K5,K6] [K6,K7] [K7,--]
| | | | | | | |
[5,6,9] [2,7,12] [1,8,16] [3,4,10] [13,15,19] [11,14,20] [17,18,21] [22,28,30]参考
https://www.cnblogs.com/xiaomaomao/p/16196006.html
https://tech.meituan.com/2017/04/21/mt-leaf.html
https://dev.mysql.com/doc/refman/5.7/en/group-replication.html
https://blog.csdn.net/LO_YUN/article/details/126795183
https://www.processon.com/view/link/643c3d7bec0f2b0724eb208e

