
MySQL事务特性ACID实现原理原创
前文回顾
MySQL使用B+Tree的数据结构,尽可能少的层级或IO读取量的情况下,能够缓存或存储更多数据量且达到快速查询的效果。
在进行索引存储的时候,索引的数据要放到磁盘里面,不可能将磁盘里面的所有文件一口气读到内存里面,因此要使用分块读取的方式,而操作系统本身进行内存和磁盘交互的时候是以页为单位的,按照页的整数倍作为某一个磁盘块来进行数据的读取。
在进行数据读取的时候,还要确认一个事情:索引是要有key-value值的,key是指定的索引列,value是具体的行数据。
索引系统在具体实现的时候,需要采用key-value格式的数据,那需要考虑使用什么样的数据结构?
支持key-value存储的数据结构有很多种:Hash表、二叉树、红黑树、AVL树、B树、B+树。
Hash表需要比较优良的Hash算法,但不支持范围查询,因为Hash表里面的数据都是均匀散列的,是无序的。
当进行某一个范围查询的时候,只能挨个对比,这样效率是比较低的。
MySQL Memory存储引擎支持Hash索引,但INNODB和MYISAM并不支持。
二叉树、AVL树、红黑树这几个树都是可以存储k-v格式数据的,共同的特点:最多有两个分支。
如果想存储更多数据的话,就会导致树的高度更高,树的高度更高会增加IO读取的次数,这样数据的访问效率是较低的。
因此基于这样的考虑把二叉树变成多叉树同时要具备有序和平衡的特点,因此B树应用而生。
在B树里面,每个数据节点可以存储更多的数据,同时数据和key值均匀的放在叶子节点和非叶子节点里面。
若存满三层B树的话,可以支持几千条或上万条的数据存储,这样是没有办法满足业务要求的,基于这样的场景再做一个延伸和考虑,将所有的data存储在叶子节点中,非叶子节点中不要存储数据,因此有了B+树,在B+树实际存储的时候,叶子节点存放了所有数据,而非叶子节点中并不存储实际的数据同时在叶子节点中有相应的指针可以连起来,可以通过头指针直接访问到当前叶子节点的最后一个数据,这样就完成了MySQL索引数据的存储。
3-4层的B+树足以支撑千万级数据量的存储。
一个原则是key所占用的存储空间要尽可能小,这样可以保证存储更多的数据。
MySQL事务
原子性、一致性、隔离性、持久性,
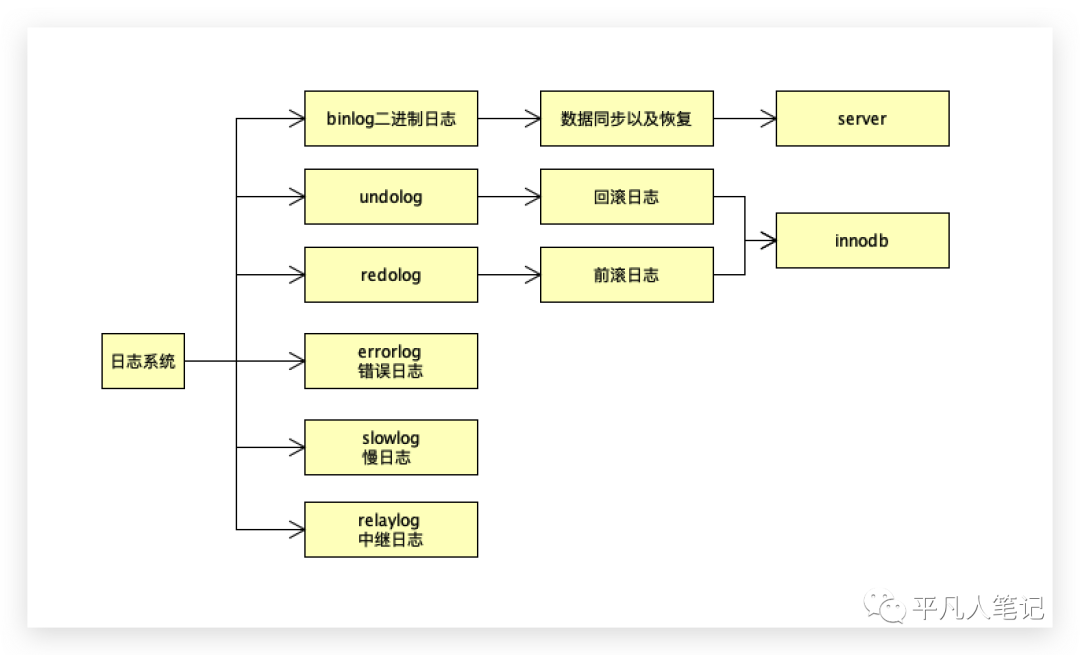
-
relaylog是中继日志,用于主从复制
-
slowlog 开启慢查询,记录哪条sql语句执行的慢
-
binlog 二进制日志文件,默认是不开启的,可以进行数据同步以及恢复,测试环境和生产环境最好开启
-
undolog 回滚日志
-
redolog 前滚日志
原子性的实现
原子性通过undolog,保留数据的历史状态,如果没有提交,历史状态依然保存,当需要回滚的时候,把历史数据拿过来,重新放入进去。
保存某一行记录的历史状态或历史版本,在提交失败之后,能恢复到上一个历史版本的状态。
在并行运行的各个事务之间相互独立,互不干扰。
一个事务在运行中,另一个事务不能去影响当前正在执行的事务。
这里会涉及到并发相关的基本操作:锁,但给数据加锁之后的效率低,所以通过MVCC多版本并发控制的方式来实现。
持久性的实现
通过redolog实现持久性,很多数据存储在磁盘,当更新某一条记录的时候,这个更新的操作执行效率很低。
这里涉及到对磁盘数据的一个寻址过程,每次在进行更新操作的时候,需要把数据从磁盘读取到内存里面去,
在内存里面先更新完成,更新完成之后,变成脏页,需要把内存里面的数据刷新到磁盘里面,来保证数据的一致性。
在进行寻址的过程中,MySQL突然挂了,这条数据没有来得及写磁盘,
重启之后,怎么保证把数据恢复出来?
通过redolog,redolog也是存在磁盘上的一个日志文件,每次往磁盘写入数据之前,先往日志文件里面写入一份,然后再往对应磁盘的数据文件中写。
既然真实数据在磁盘,redolog也在磁盘,为什么还要写一份redolog?
这里也涉及到了io的问题,在进行读写操作的时候,IO有两种方式,随机IO和顺序IO。
-
随机IO
一个庞大的文件,里面有10亿条记录,在这个文件的某一行或某一个位置进行修改,先找到这个位置,才能去写,而找的过程就会浪费很多时间,这就是随机IO。
-
顺序IO
顺序IO是不管当前文件存储了多少数据,所有新增的数据都直接往后面进行append操作,先顺序写到redolog,然后再慢慢进行读写,不需要实时性,不需要花费大量的时间去找数据来进行数据的更新。
redolog不会整理数据,有一个机制叫循环log,这是一个固定空间的文件,一直往里面追加,假如满了,会把之前的数据干掉,如果redolog没有写成功,数据丢了,就真的丢了。
先写redolog还是先写binlog?
记录了redolog之后,binlog中也会记录,同时记录会有什么问题么?
不管先写谁都有问题,这里会涉及到二阶段提交,这里不是分布式事务中的二阶段提交。
binlog和redolog要保证二阶段提交,即2个日志数据,要么都写,要么都不写。
如果一个写了一个没写,要判断下能否生效或者数据最终是否是一致。
什么是二阶段提交?如何保证宕机时数据的一致性?
redolog为了记录或为了阻止crash的存在,比如断电。
binlog是为了主从复制或数据恢复的。
在操作的时候,2个日志文件会同时写,在数据恢复的时候,要根据2个日志来判断。
数据更新的流程(看到底先写谁,后写谁?
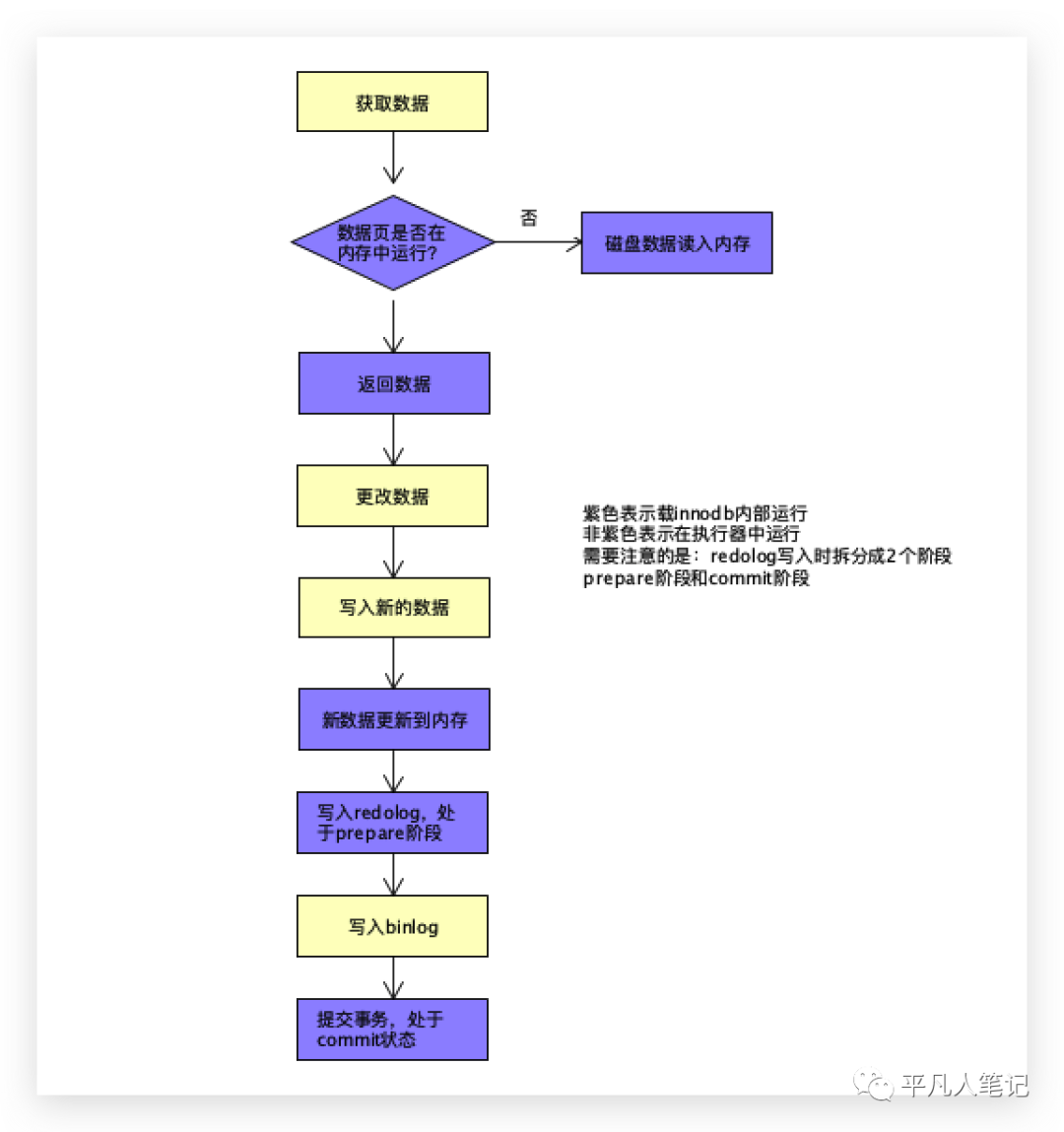
先获取数据,判断当前数据是否在内存中,如果没有的话,需要把磁盘中的数据加载到内存中。
然后修改数据,同时要写入新的数据,先写内存,写完内存之后,才会往磁盘中投放。
写这2个日志文件的时候,分为3个步骤:
-
先写redolog,处于prepare阶段;
-
再写binlog;
-
提交事务的时候,再把刚刚的prepare状态设置为commit状态。
为什么要这么设计?有什么好处?
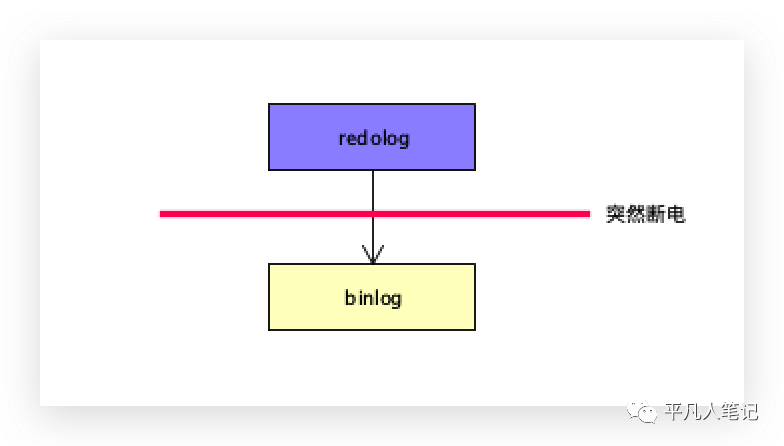
写完redolog,还没有来得及写binlog的时候,突然断电了,binlog是不具备对应信息的。
假设2台机器,操作A数据库,B数据是通过A数据库数据同步的。
A和B 2个数据库若不一致了,主从同步就失败了,反过来也是一样。
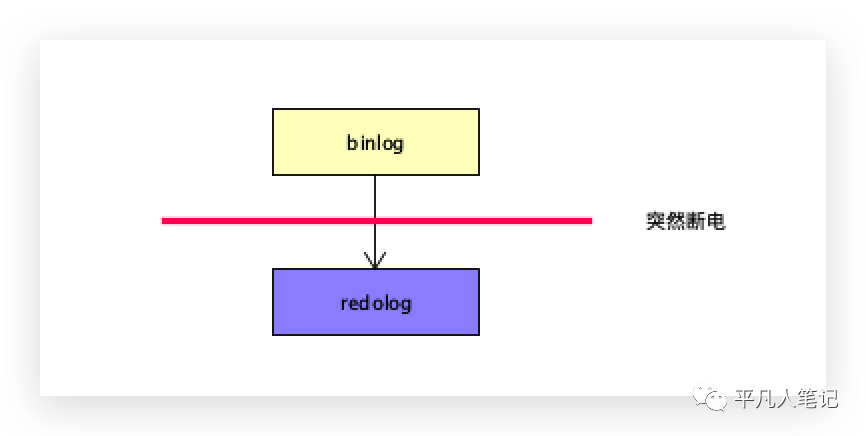
当写完binlog,还没有写完redolog的时候,突然断电。
A数据库中的binlog记录了对应的数据,B数据库已经将数据同步,但是A数据库的redolog中没有,出现断电之后,不能通过binlog把数据恢复回去,A机器少一条,B机器已经同步了,此时还是不一致性。
因此才诞生了诞生了二阶段提交,写redolog是prepare状态,当binlog写完之后,事务提交了,再把redolog设置为commit状态。
整个过程中,任何步骤都有可能出现断电情况。
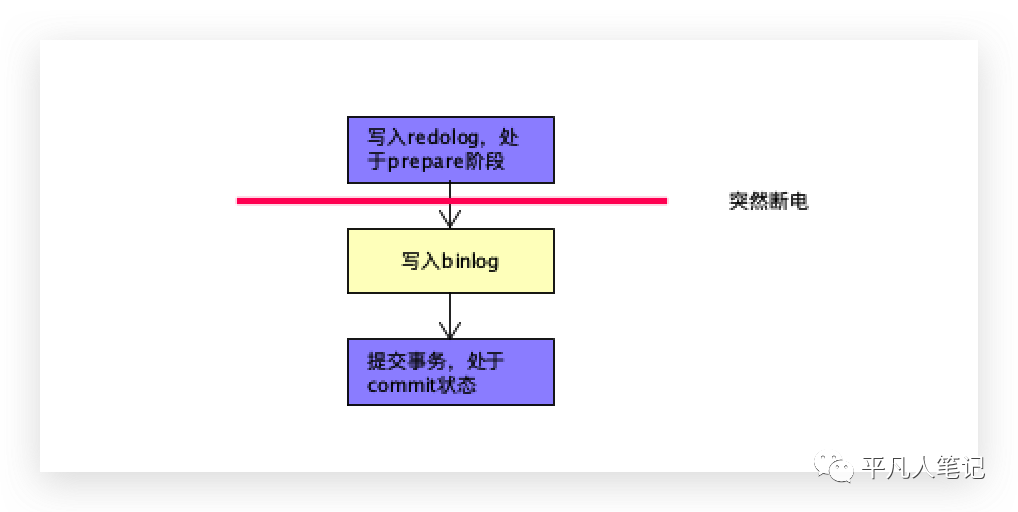
如果此处断电,再恢复的时候,先检查redolog,如果发现当前redolog是prepare状态,再去binlog中找对应的数据。
如果有,则把redolog的prepare状态修改成commit状态。
如果没有的话,就把prepare状态直接设置为失效。
这样2个文件可以保持一致。
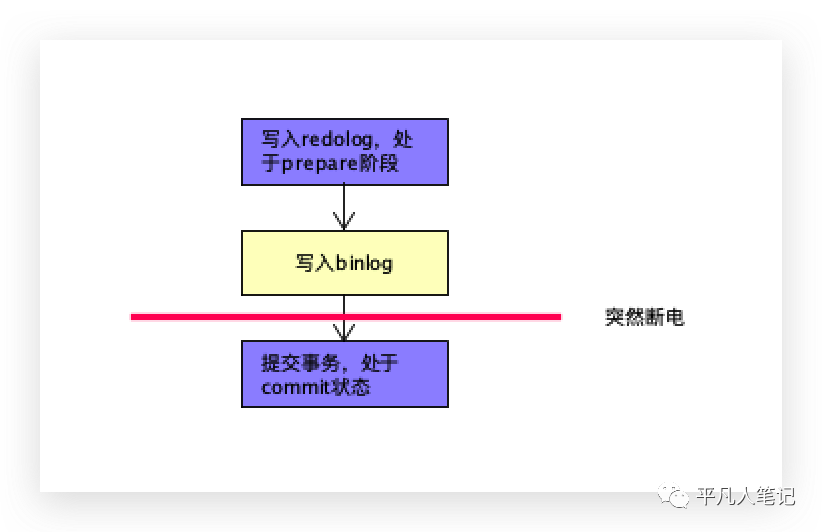
binlog没有parpare状态。
断电丢失只是丢失内存数据,磁盘中的数据是不会发生丢失的。
事务的一致性没有具体的实现,而是由其他3个特征共同保证了一致性问题。


