
国产监控之光-夜莺监控(Nightingale)原创
夜莺是什么?
夜莺是一个服务端组件,类似 Grafana,可以对接不同的TSDB时序数据库作为数据源,支持的TSDB时序数据库如Prometheus、VictoriaMetrics、Thanos等等,只要数据进到这些库里了,夜莺就可以对数据源的数据进行分析、告警、可视化,以及后续的事件处理、告警自愈。
当然,夜莺也有端口接收监控数据,可以跟开源社区常见的各种监控采集器打通,比如Telegraf、Categraf、Grafana-agent、Datadog-agent、Prometheus生态的各类Exporter等等。这些agent采集了数据推给夜莺,夜莺适配了这些agent的数据传输协议,所以可以接收这些agent上报的监控数据,转存到后端对接的数据源,之后就可以对这些数据做告警分析、可视化。
夜莺部署架构
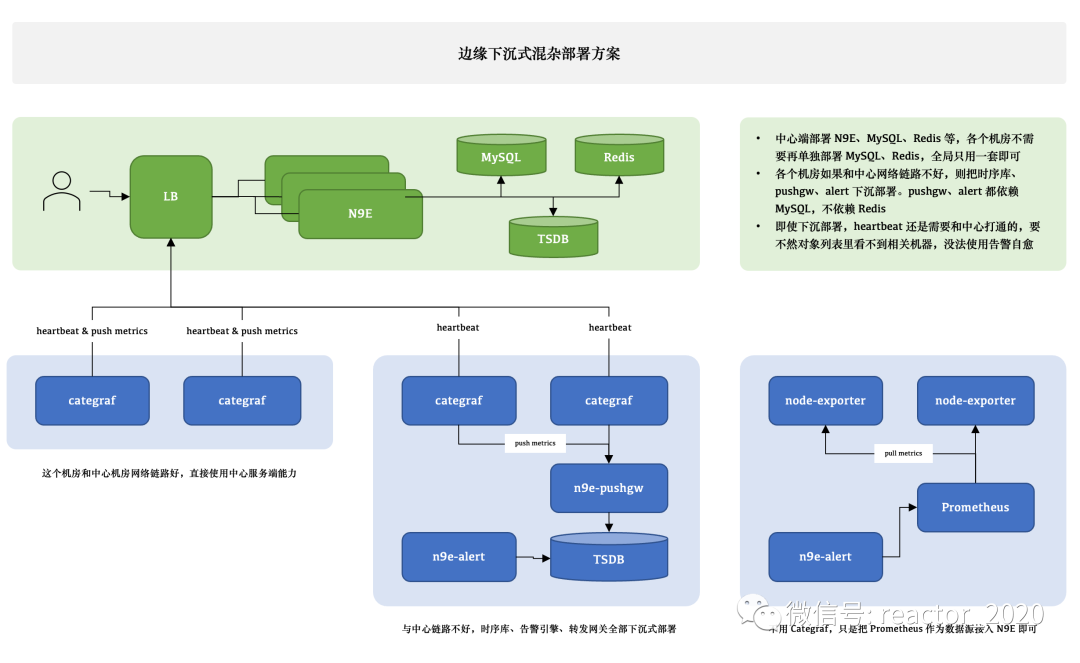
根据生产网络环境,夜莺可以实现「中心汇聚式部署方案」和「边缘下层式混杂部署方案」。
对于网络结构简单或小规模网络场景下,采用「中心汇聚式部署方案」实施比较简单,可以n9e核心组件采用单机或集群方式搭建,集群模式下前端需架设Nginx作为软负载或F5进行硬件设备负载,同时依赖MySQL和Redis中间件存储基础的元数据、用户信息等,不存在大数据量问题,因此,不用太考虑性能瓶颈。
Categraf是夜莺团队开发维护的监控采集侧核心组件,类似Telegraf、Grafana-Agent、Datadog-Agent,希望对所有常见监控对象提供监控数据采集能力,采用All-in-one的设计,不但支持指标采集,也希望支持日志和调用链路的数据采集。Categraf采集器采集了数据推送给夜莺,然后转存到后端数据源,如TSDB、ElasticSearch等。
❝注意:Categraf不属于夜莺监控系统组件,夜莺定位是服务端组件,不侧重监控数据采集侧。
❞
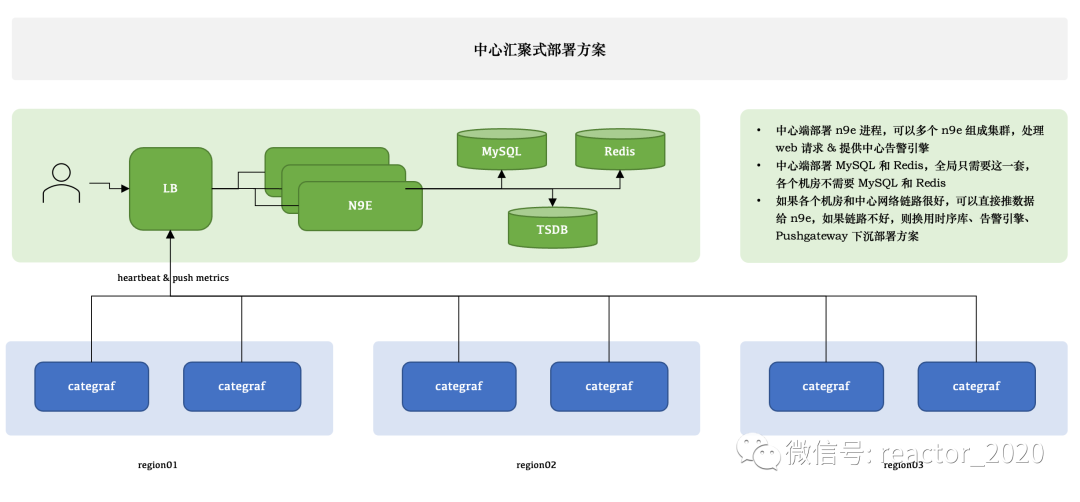
所有机房网络域下监控数据采集器都直接推数据给n9e,这个架构最为简单,维护成本最低。当然,前提是「要求机房网络域结构简单、规模不大场景,即不太关注跨网络域访问安全问题和大规模跨网络域传输数据网络带宽限制等」。
如果非上述场景,则要使用下面的「边缘下沉式混杂部署方案:」

这个图尝试解释 3 种不同的情形,比如 A 机房和中心网络链路很好,Categraf 可以直接汇报数据给中心n9e模块,另一个机房网络链路不好,就需要把时序库下沉部署,时序库下沉了,对应的告警引擎和转发网关也都要跟随下沉,这样数据不会跨机房传输,比较稳定。但是心跳还是需要往中心心跳,要不然在对象列表里看不到机器的 CPU、内存使用率。还有的时候,可能是接入的一个已有的Prometheus,数据采集没有走Categraf,那此时只需要把Prometheus作为数据源接入夜莺即可,可以在夜莺里看图、配告警规则,但是就是在对象列表里看不到,也不能使用告警自愈的功能,问题也不大,核心功能都不受影响。
「边缘下沉式混杂部署方案」中涉及到两个核心组件:「n9e-pushgw组件」和「n9e-alert组件」。
「n9e-pushgw组件」提供类似于remote_write和remote_read功能,categraf采集器将数据通过remote_write推送给n9e-pushgw组件,然后转存到tsdb时序数据,n9e服务端查询检索数据时通过remote_read讲求转发到对应机房下的n9e-pushgw组件。n9e-alert组件提供基于tsdb时序库中的指标数据告警功能。
一键部署
「笔者已经在公有云上搭建了一套临时环境,可以先登录体验下:」
http://124.222.45.207:17000/login
账号:root/root.2020
下面介绍下使用docker-compose快速一键部署。
1、代码在这里:💡 https://github.com/ccfos/nightingale 。如果有 docker 和 docker-compose 环境,我们就可以一键安装了:
git clone https://github.com/ccfos/nightingale.git
cd nightingale/docker
docker-compose up -d
2、安装完成之后,查看组件部署运行情况:
[root@VM-4-14-centos docker]# docker-compose ps
Name Command State Ports
--------------------------------------------------------------------------------------------------------
categraf /entrypoint.sh Up
ibex sh -c /wait && /app/ibex s ... Up 0.0.0.0:10090->10090/tcp, 0.0.0.0:20090->20090/tcp
mysql docker-entrypoint.sh mysqld Up 0.0.0.0:3406->3306/tcp, 33060/tcp
n9e sh -c /wait && /app/n9e Up 0.0.0.0:17000->17000/tcp
prometheus /bin/prometheus --config.f ... Up 0.0.0.0:9090->9090/tcp
redis docker-entrypoint.sh redis ... Up 0.0.0.0:6379->6379/tcp
❝注意,docker中不能有同名组件,比如我在安装过程中出现:ERROR: for prometheus Cannot create container for service prometheus: Conflict. The container name "/prometheus" is already in use by container xxx. You have to remove (or rename) that container to be able to reuse that name。
❞
3、浏览器访问n9e组件暴露的17000端口,即可看到页面,默认账号密码如下:
username = "root"
password = "root.2020"
4、访问prometheus组件暴露的9090端口,可以打开Prometheus WebUI:
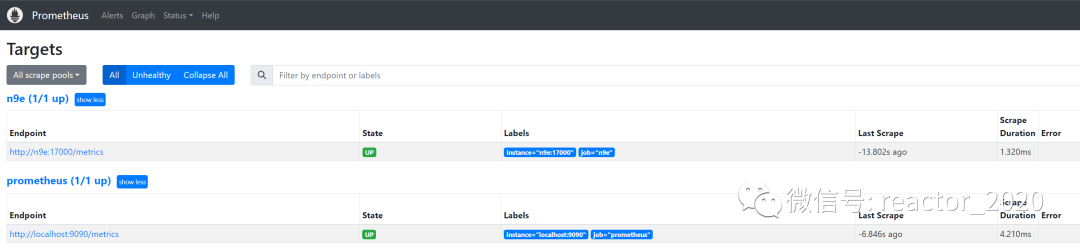
从Targets界面显示Prometheus接入2个目标采集点,从端口可以识别一个抓取n9e组件监控指标,另一个就是抓取prometheus组件自身指标。
基本使用
1、打开【基础设施】/【机器列表】菜单,该界面提供Categraf采集点机器管理,在【未归组对象】下就可以看到刚才部署的一个Categraf采集点:

❝Categraf 是一个监控采集 Agent,类似 Telegraf、Grafana-Agent、Datadog-Agent,希望对所有常见监控对象提供监控数据采集能力,采用 All-in-one 的设计,不但支持指标采集,也希望支持日志和调用链路的数据采集。
❞
Categraf通过Heartbeat心跳服务将节点的状态、内存、CPU、时间偏移、核数、OS等信息上报给n9e组件,进而Web上方便查看。
方便机器列表管理,可以进行分组,如下图我们对机器按照机房地域划分,并创建chengdu业务组:
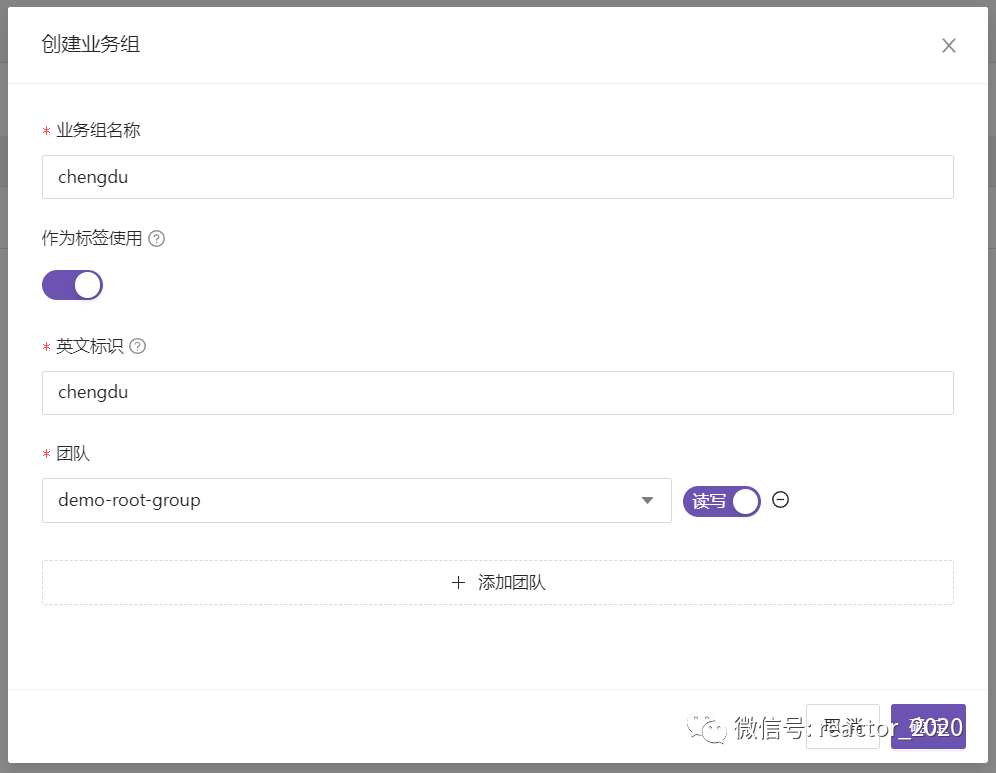
❝这里我打开【作为标签使用】开关,该业务组下机器采集数据推送TSDB库时会自动打上busigroup=[英文标识]标签,方便基于该维度进行数据聚合统计。
❞
【团队】这栏用于权限控制,比如控制哪个团队成员可以对该业务组下机器具有读写权限,或者只读权限等。【人员管理】/【团队管理】页面可以创建、管理团队。
选中机器,点击【批量操作】下【修改业务组】,将机器移入到新创建的业务组里:

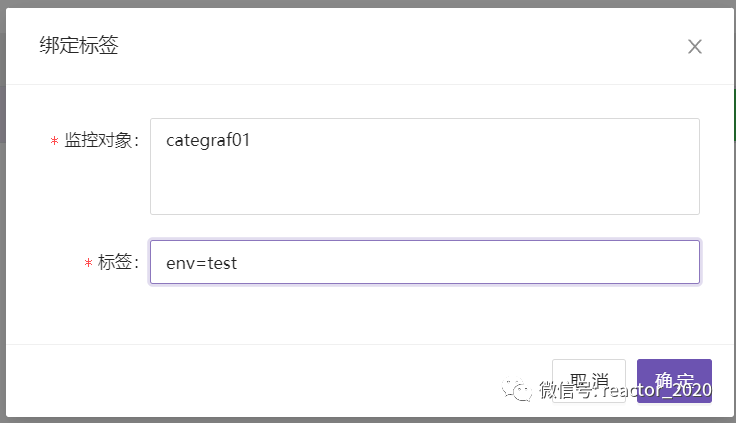
还可以选中机器,选择【批量操作】/【绑定标签】,手工为机器打上指定标签,则关联机器指标存储到TSDB时序数据库时会带上这些标签:
2、配置数据源
打开【系统配置】/【数据源】菜单,进入数据源管理界面,选择添加Prometheus数据源:
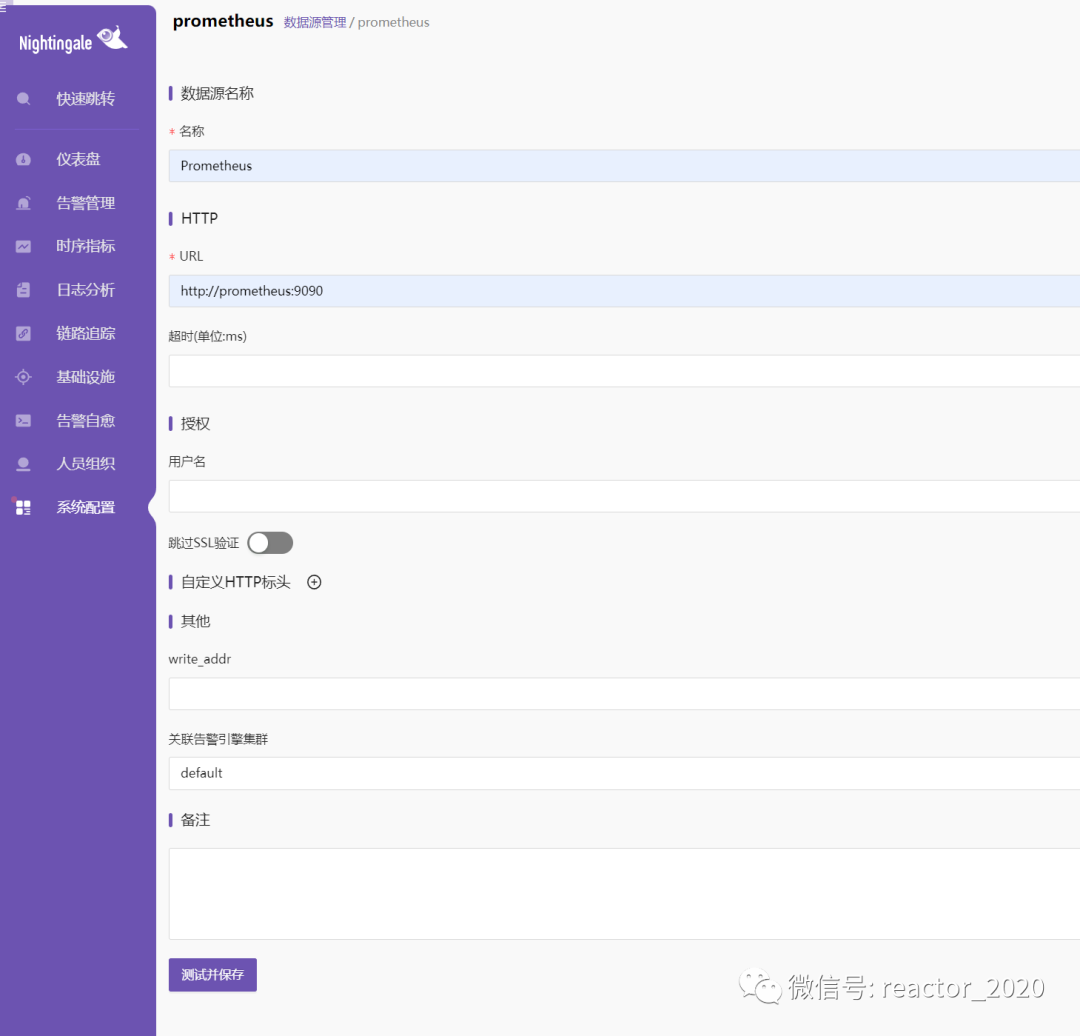
❝我这里采用docker compose一键部署,所以这里url可以填写http://prometheus:9090。
❞
2、添加好数据源,打开【时序指标】/【即时查询】菜单:
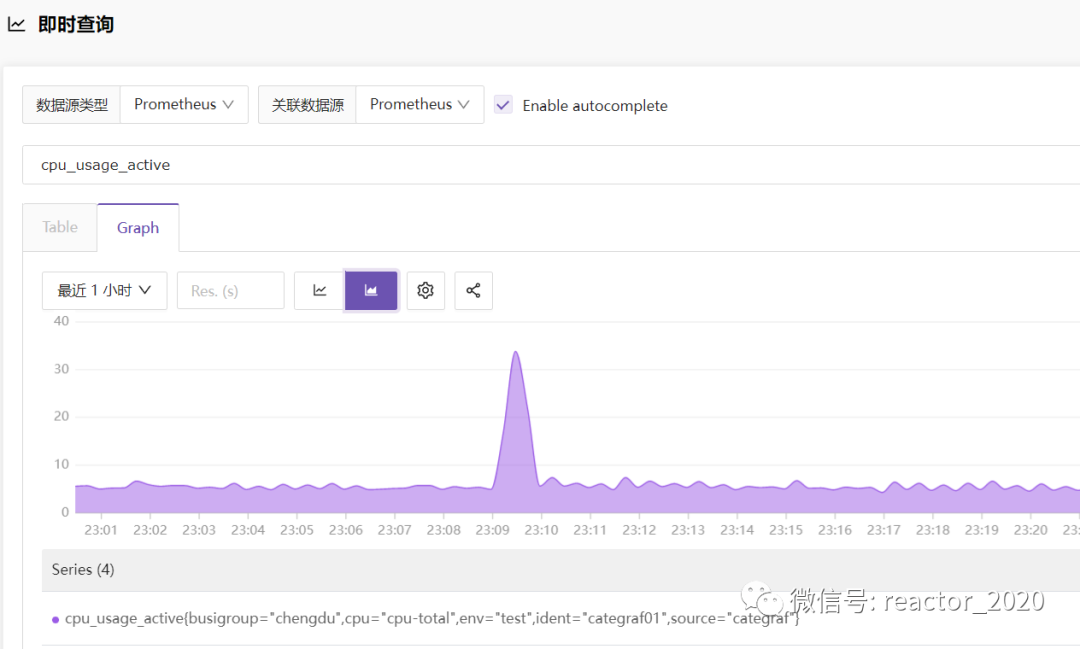
这个查询基本类似于Prometheus WebUI查询页面,关联数据源,输入PromQL即可查询指标数据,点击Graph还可以展示对应的区间趋势图。
指标cpu_usage_active{busigroup="chengdu",cpu="cpu-total",env="test",ident="categraf01",source="categraf"}标签说明:
1、busigroup="chengdu":这个就是刚才创建业务组时打开【作为标签使用】开关配置的标签;
2、cpu="cpu-total":组件暴露指标自身业务标签;
3、env="test":刚才在机器上手工绑定标签配置;
4、ident="categraf01":机器标识,即Categraf组件所属主机名;
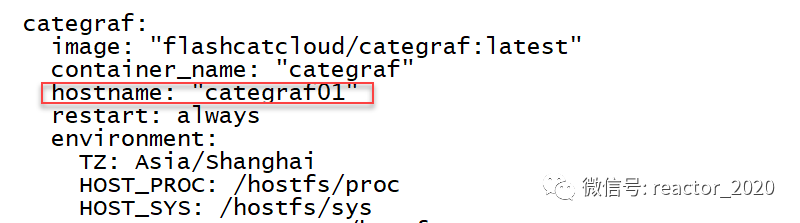
当然也可以在Categraf组件config.toml配置文件中指定hostname:

5、source="categraf":Categraf组件config.toml配置文件中global.labels配置信息:
[global.labels]
source="categraf"
# region = "shanghai"
# env = "localhost"
总结
夜莺监控系统部署架构简单,对于小规模监控场景下快速搭建一套监控系统来说是比较值得推荐的方式,整体体验也比较友好。但对于大规模监控场景,可能还不是那么的足够完善。
Categraf采集组件
1、categraf采集器采用推送模式(push),而不是Prometheus的拉(pull)模式,push模式导致采集器存在状态,即采集器要知道自己要推送给哪个服务后端的配置,少量categraf采集器来说无所谓,但是一旦成千上万采集点,甚至几百采集点,维护成本都是比较高的,特别是后端地址发生变更等。
2、push模式还存在接入权限问题,因为往往服务后端和采集器维护是两拨人,服务后端是运维人员,而采集器是项目组人员维护,比较难于控制接入,可能个别项目组大量接入采集点造成服务端压力过大奔溃,从而影响整个系统运行稳定。
3、push模式还存在推送频率问题,categraf组件可以配置推送频率,但是只能在采集器端控制,不同项目组运维人员可能配置不同推送频率,难以从全局控制,或者这么个场景:前期采集点少,数据量不大,推送频率5s,但是后面接入的越来越多,存储不够用,需要下调推送频率15s,没有统一修改调整方式。
部署架构优化
「边缘下沉式混杂部署方案」中categraf采集器还需要和夜莺后端n9e组件进行heartbeat心跳交互,这里可能会存在问题,对于大规模网络下,categraf会部署成千上万个实例,服务后端n9e组件维护这些心跳性能:
1、服务后端n9e组件维护这些心跳对服务性能和网络IO都存在损耗问题,一个心跳交互影响微乎其微,但是放到成千上万个节点心跳这个影响就会扩大;
2、「边缘下沉式混杂部署方案」往往就是由于网络环境复杂,为了heartbeat需要打通服务后端和那么多categraf组件网络连通性,可能影响是致命的;
3、n9e服务后端和categraf组件心跳传递数据主要:在线状态、CPU%、内存、CPU核数、CPU架构等,这个在线状态更多的是反映后端和categraf组件连通性,我觉得在线状态应该反映categraf有没有正常采集指标数据并推送到tsdb库可能更加合理,查看categraf采集组件历史一段区间内的在线状态、CPU、内存等,后端还需要考虑存储这些指标数据;
所以,categraf心跳交互这个逻辑应该移除,将心跳数据以指标方式暴露,并增加一个up指标反映在线状态,在categraf向n9e-pushgw组件推送数据时一并存储到tsdb时序库中。n9e后端在查询categraf当前状态或某历史区间在线情况时,都可以通过n9e-pushgw从tsdb时序库中拉取展示。
比如中心网络和边缘下沉网络可能有一段时间网络断开,这种只会影响后端过来的查询不能执行,categraf采集组件本身依然可以正常采集数据并推送到tsdb时序库,对于categraf采集器组件来说依然是正常在线的,因为网络域内部是正常的,待网络恢复后,n9e服务端就可以通过n9e-pushgw组件从tsdb时序库中查询出这段时间categraf是否正常采集、CPU使用率等等情况。
「边缘下沉式混杂部署方案」不同网络域下TSDB时序库是割裂的,全局聚合汇总数据暂未发现如何实现:


[更多云原生监控运维,请关注微信公众号:Reactor2020]

