
prometheus 服务发现原理原创
服务发现
概述
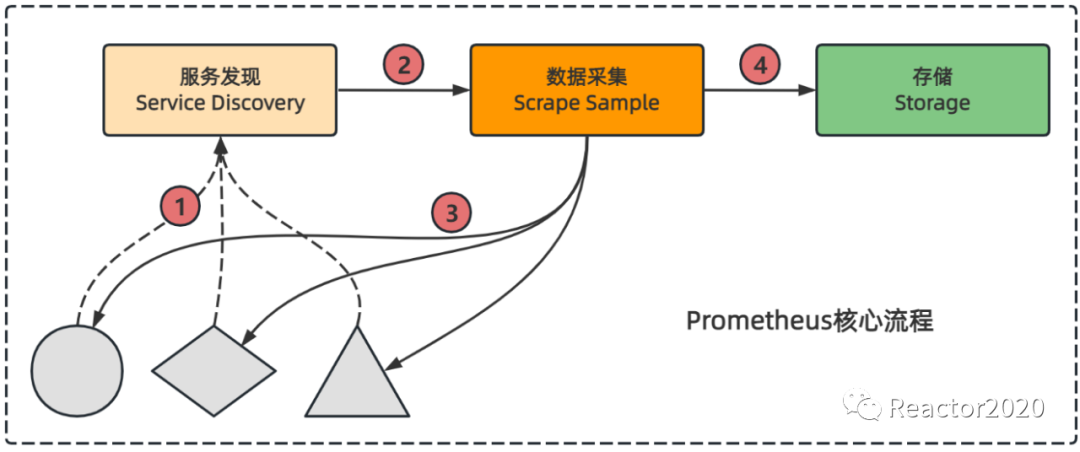
如上图,Prometheus核心功能包括服务发现、数据采集和数据存储。服务发现模块专门负责发现需要监控的目标采集点(target)信息,数据采集模块从服务发现模块订阅该信息,获取到target信息后,其中就包含协议(scheme)、主机地址:端口(instance)、请求路径(metrics_path)、请求参数(params)等;然后数据采集模块就可以基于这些信息构建出一个完整的Http Request请求,定时通过pull http协议不断的去目标采集点(target)拉取监控样本数据(sample);最后,将采集到监控样本数据交由TSDB模块进行数据存储。
为什么需要服务发现模块
类似于微服务通过引入注册中心组件解决众多微服务间错综复杂的依赖调用。无论是服务主动停止,意外挂掉,还是因为流量增加对服务实现进行扩容,这些服务数据或状态上的动态变化,通过注册中心屏蔽服务状态变更造成的影响,简化了调用方处理逻辑。
同理,Prometheus最开始设计是一个面向云原生应用程序的,云原生、容器场景下按需的资源使用方式对于监控系统而言就意味着没有了一个固定的监控目标,所有的监控对象(基础设施、应用、服务)都在动态的变化。Prometheus解决方案就是引入一个中间的代理人,这个代理人掌握着当前所有监控目标的访问信息,Prometheus只需要向这个代理人询问有哪些监控目标即可,这种模式被称为服务发现(service discovery)。
目前,Prometheus支持的服务发现协议是非常丰富的,最新版本(2.41)已支持接近三十种服务发现协议:
<azure_sd_config>
<consul_sd_config>
<digitalocean_sd_config>
<docker_sd_config>
<dockerswarm_sd_config>
<dns_sd_config>
<ec2_sd_config>
<openstack_sd_config>
<ovhcloud_sd_config>
<puppetdb_sd_config>
<file_sd_config>
<gce_sd_config>
<hetzner_sd_config>
<http_sd_config>
<ionos_sd_config>
<kubernetes_sd_config>
<kuma_sd_config>
<lightsail_sd_config>
<linode_sd_config>
<marathon_sd_config>
<nerve_sd_config>
<nomad_sd_config>
<serverset_sd_config>
<triton_sd_config>
<eureka_sd_config>
<scaleway_sd_config>
<uyuni_sd_config>
<vultr_sd_config>
<static_config>
服务发现配置解析
1、Prometheus服务启动加载prometheus.yml配置文件会被解析Config结构体:
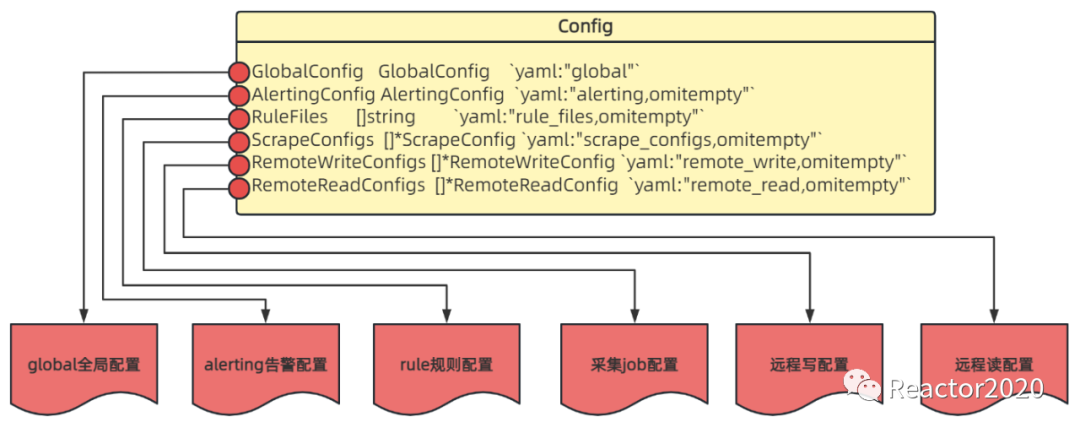
❝
Config结构体是配置类的最顶层结构,内部包含6个字段分别对应prometheus配置的6大组成部分。
2、其中数据采集配置部分ScrapeConfigs对应的是一个*ScrapeConfig类型切片,一个ScrapeConfig对应的是scrape_configs配置下的一个job抓取任务,服务发现协议配置对应其中ServiceDiscoveryConfigs字段:

3、discovery.Configs对应的是Config切片:
type Configs []Config
所以,一个job抓取任务下可以配置多个服务发现协议,如:
- job_name: 'prometheus'
metrics_path: /metrics
static_configs:
- targets: ['124.222.45.207:9090']
file_sd_configs:
- files:
- targets/t1.json
- targets/t2.json
refresh_interval: 5m
4、Config是一个接口:

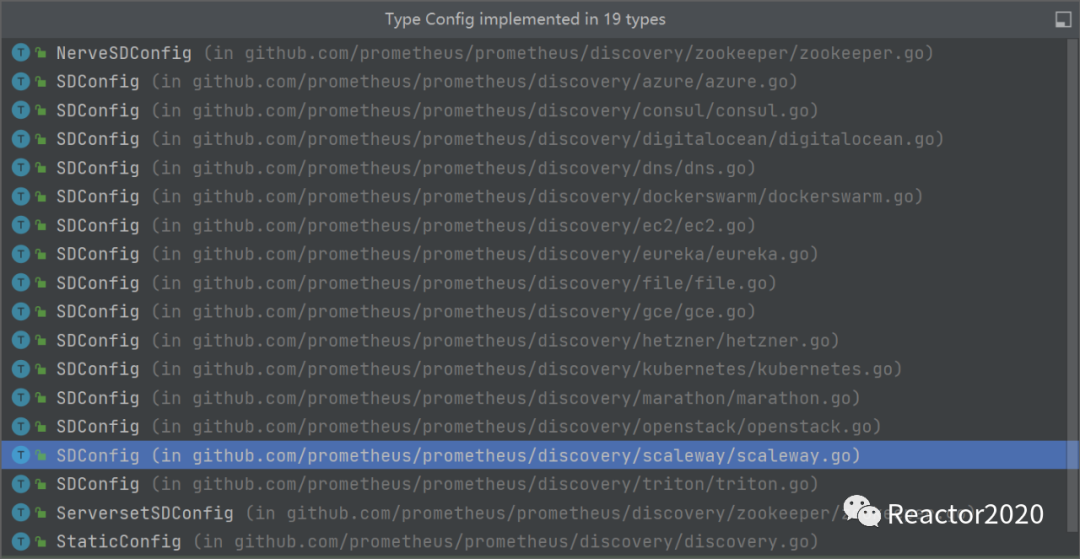
Config是一个接口的定义,每种服务发现协议都会存在一个对应Config接口的实现(见下图)。该接口主要定义两个方法:
1、Name() string:定义服务发现协议类型,如eureka、kubernetes等等;
2、NewDiscoverer(DiscovererOptions) (Discoverer, error):返回一个Discoverer类型变量,该类型也是一个接口,其只定义了一个方法Run方法,即Discoverer是对应的服务发现协议具体运行逻辑封装,通过Run方法提供统一的运行入口。
服务发现核心原理
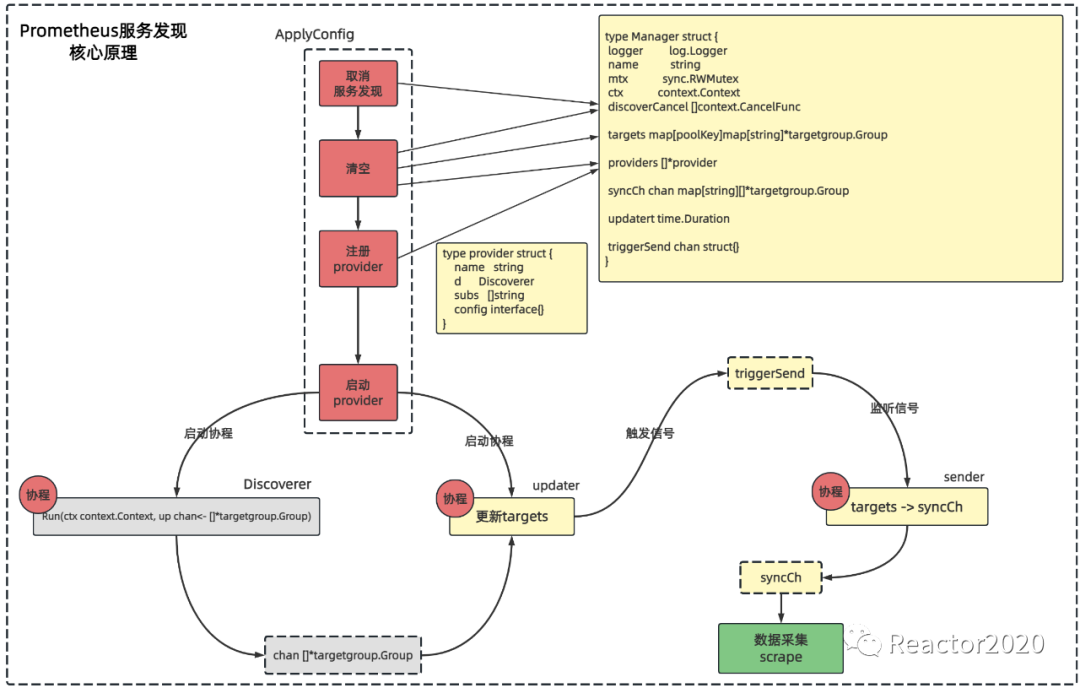
说明:
-
Prometheus服务发现核心逻辑的入口主要关注Manager结构体的ApplyConfig方法:基于服务发现的配置使其生效; -
ApplyConfig方法包括四个主要步骤:type provider struct {
name string
d Discoverer
subs []string
config interface{}
}❝
一个job下一个服务发现协议对应一个Discoverer。
❞provider还有额外三个字段:1、
name:provider名称,格式:fmt.Sprintf("%s/%d", typ, len(m.providers));2、
subs:string切片,存放job名称,因为可能不同job下存在一致的服务发现配置,就只会生成一个provider,然后subs存放job列表;3、
config:服务发现配置 -
启动 Discoverer接口Run方法,让服务发现逻辑运行; -
协程中运行 updater方法; -
Discoverer接口Run方法主要基于具体服务发现协议发现target,然后通过通道传递给updater处理逻辑,将其解析处理放入到Manager结构体中targets字段中,并向triggerSend通道发送信号,表示当前targets发生变更; -
Manager结构体sender方法每5秒监听triggerSend通道信号,并将Manager结构体中targets字段处理后放入到syncCh通道中; -
数据采集模块( scrape)监听syncCh通道,就可以获取到服务发现生成的targets信息,然后reload将target纳入监控开始抓取监控指标。 -
启动
provider:遍历Manager结构体中providers切片,启动每个provider,该步骤主要是启动两个协程:❝
❞Manager结构体sender方法是在Prometheus启动时discoveryManagerScrape.Run()方法中启动。 -
取消服务发现:配置变更也会调用 ApplyConfig方法,这时就要把基于之前配置运行的服务发现服务取消,然后基于当前配置重新生成; -
清空:主要清空 discoverCancel、targets和providers几个容器元素,因为要基于当前配置重新生成; -
注册 provider:provider是对Discoverer的封装,不同服务发现协议都会实现Config接口,其中NewDiscoverer方法就是创建Discoverer
「Prometheus服务发现核心就是三个协程之间协作:」
-
「协程1:」负责运行 Discoverer接口Run方法,基于协议发现采集点; -
「协程2:」负责将协程1发现的采集点信息更新到 Manager结构体中targets字段的map中; -
「协程3:」负责将 Manager结构体中targets字段的数据通过通道发送给scrape模块;
scrape模块获取到采集点如何进行数据采集后续scrape模块分析。
监控指标
Prometheus服务发现通用指标主要有如下5个,都定义在discovery/manager.go中:
prometheus_sd_discovered_targets
prometheus_sd_failed_configs
prometheus_sd_received_updates_total
prometheus_sd_updates_delayed_total
prometheus_sd_updates_total
「1、采集点数量指标」
服务发现主要基于协议发现采集目标,prometheus_sd_discovered_targets指标反馈各个job发现的采集目标数:
prometheus_sd_discovered_targets:gauge类型,当前发现的目标数
config:job名称
name:取值scrape和notify,区分指标抓取服务发现还是告警通知服务发现
示例:prometheus_sd_discovered_targets{config="auth_es1", name="scrape"} 12
❝这里基于协议发现的目标数,还未进入采集模块,并不能区分是在线还是离线。
❞
「2、服务发现协议异常错误指标」
服务发现会给每个发现配置项生成一个provider,并为每个provider使用协程运行,如果基于配置项生成provider错误就可以通过prometheus_sd_failed_configs指标反馈:
prometheus_sd_failed_configs:gauge类型,当前无法加载的服务发现配置数
配置数:一个job可能存在多个服务发现协议配置,对应配置项则是多个
示例:
prometheus_sd_failed_configs{name="scrape"} 10
prometheus_sd_failed_configs{name="notify"} 5
一个job可能对应多个服务发现配置项,如下:这个job下配置了static_configs和file_sd_configs两个服务发现协议配置,则对应两个服务发现配置项,注册两个provider,每个provider在独立协程中运行:
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'test'
static_configs:
- targets: ['localhost:9090']
file_sd_configs:
- refresh_interval: 5m
files:
- targets/manual.*.json
「3、协程交互指标」
服务发现主要涉及3类协程:
-
Discoverer协程(多个):封装provider,基于协议发现采集点,这里可能会存在多个,一个provider对应一个Discoverer协程; -
updater协程(1个):Discoverer协程发现采集点,通过channel通道通知到updater协程,updater协程将采集点更新到Manager结构体中targets字段中,然后向Manager结构体中triggerSend通道写入数据,告诉sender协程targets有更新; -
sender协程(1个):sender协程每5秒检测triggerSend通道数据,检测到更新则将Manager结构体targets数据处理封装写入到Manager结构体syncCh通道中,scrape模块监测该通道,即完成将服务发现模块和scrape模块交互。
这其中涉及三个指标:
prometheus_sd_received_updates_total
prometheus_sd_updates_delayed_total
prometheus_sd_updates_total




