
eBPF: 从 BPF2BPF 调用到尾调用转载
1. 引言
这篇文章首先介绍尾调用的一般限制和用法,并与 BPF2BPF 调用做对比,最后给出一个我对内核中尾部调用样例做的一个修改版本(应用 CO-RE)。(我在学习尾调用的时候苦于没有一个能跑起来的简单易懂的例子,所以最后自己撸了一个,这个版本我认为是目前能找到的所有例子里对初学者最友好,逻辑最清晰的一个)。
2. Tail Call(尾调用)
BPF 提供了一种在内核事件和用户程序事件发生时安全注入代码的能力,这就让非内核开发人员也可以对内核进行控制,但是因为 11 个 64 位寄存器和 32 位子寄存器、一个程序计数器和一个 512 字节的 BPF 堆栈空间以及 100 万条指令(5.1+),递归深度 33 的固有限制,使得可以实现的逻辑是有限的(非图灵完备)。
内核栈是很宝贵的,一般 BPF 到 BPF 的会使用额外的栈帧,尾调用最大的优势就是其复用了当前的栈帧并跳转至另外一个 eBPF 程序,可以在 [5] 中看到如下描述:
The important detail that it’s not a normal call, but a tail call. The kernel stack is precious, so this helper reuses the current stack frame and jumps into another BPF program without adding extra call frame.
重要的细节这不是一个正常的调用,而是一个尾部调用。内核栈很珍贵,所以这个辅助方式重用了当前的栈框架,并跳转到另一个 BPF 程序,而没有增加额外的调用帧。
eBPF 程序都是独立验证的(调用者的堆栈和寄存器中的值被调用者不可访问),所以状态的传递一般可以使用 per-CPU map 传递,TC 还可以使用 skb_buff->cb 这样的特殊数据项去传递数据 [8];其次类型相同的 BPF 程序才可以尾调用,而且还要与 JIT 编译器相匹配, 因此一个给定的 BPF 程序 要么是 JIT 编译执行,要么是解释器执行(invoke interpreted programs)
尾调用的步骤需要用户态和内核态配合,主要由两个部分组成:
-
用户态:
BPF_MAP_TYPE_PROG_ARRAY类型的特殊 map,存储自定义 index 到 bpf_program_fd 的到映射 -
内核态:
bpf_tail_call辅助函数,其负责跳转到另一个 eBPF 程序,其函数定义是这样的static long (*bpf_tail_call)(void *ctx, void *prog_array_map, __u32 index),ctx 是上下文,prog_array_map 是前面说的BPF_MAP_TYPE_PROG_ARRAY类型的 map,用于用户态设置跳转程序和用户自定义 index 的映射,index 就是用户自定义索引了。
bpf_tail_call 如果运行成功,内核立即运行新 eBPF 程序的第一条指令(永远不会返回到之前的程序)。如果跳转的目标程序不存在(即 index 在 prog_array_map 中不存在),或者此程序链已达到最大尾调用数,则调用可能会失败,如果调用失败,调用者继续执行后续指令。
[5] 中我们可以看到如下文字:
The chain of tail calls can form unpredictable dynamic loops therefore tail_call_cnt is used to limit the number of calls and currently is set to 32.
尾部调用链可以形成不可预测的动态循环,因此 tail_call_cnt 用于限制调用的数量,目前设置为 32。
这个限制在内核中由宏 MAX_TAIL_CALL_CNT (用户空间不可访问)定义,当前设置为 32(我并不知道这个所谓的 unpredictable dynamic loops 是什么)。
上面提到了尾调用可以省内核栈空间,除了这一点以外我认为其最大的优势如下:
-
用于增加可执行的 eBPF 程序指令的最大执行数 -
eBPF 程序编排
上面两个优势不是在我在想当然的胡诌,举个两个例子分别解释上面两个观点:
-
[10] 在 BMC 中有一个 eBPF 程序中有一个大循环,虽然 eBPF 程序只有 142 行,但是字节码已经到了七十多万行,如果不做逻辑拆分会在 verify 阶段被拒绝。
-
[9] 中提出了一种通过配置文件任意组合 eBPF 程序的 eBPF 编排策略,给我的感觉是他们像做一个三方存储,然后可以通过配置自动拉去需要的 eBPF 程序,然后自动编排,载入,执行,这里编排的过程是用尾调用实现的,基本的流程如下:
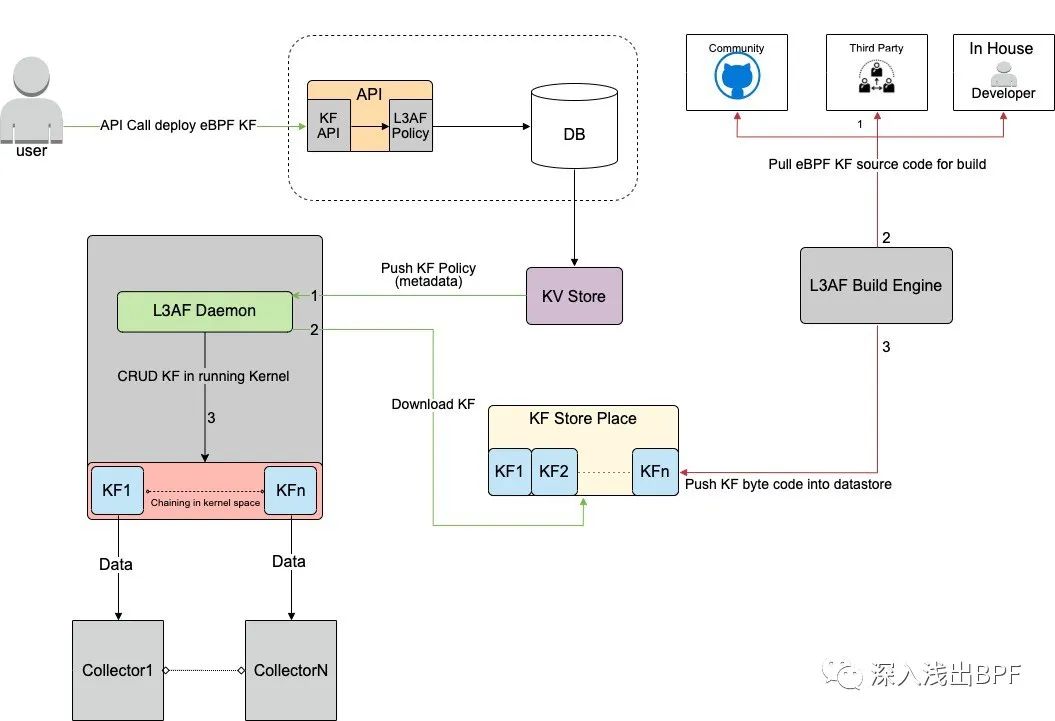
3. BPF to BPF Calls
从 Linux 4.16 和 LLVM 6.0 开始,这个限制得到了解决,加载器、校验器、解释器和 JIT 中都开始支持函数调用。
最大的优势是减小了生成的 BPF 代码大小,因此对 CPU instruction cache 更友好。BPF 辅助函数的调用约定也适用于 BPF 函数间调用,即 r1 - r5 用于传递参数,返回 结果放到 r0。r1 - r5 是 scratch registers,r6 - r9 像往常一样是保留寄存器。最大嵌套调用深度是 8。调用方可以传递指针(例如,指向调用方的栈帧的指针) 给被调用方。
尾调用的缺点是生成的程序镜像大,但是省内存;BPF to BPF Calls 的优点是镜像小,但是内存消耗大。内核 5.9 以前不允许 tail Call 和 BPF to BPF Call 调用协同工作,在 5.10 以后的 X86 架构上,允许同时使用这两种调用类型。
在 [7] 中提到同时使用两种类型有一定限制,否则会导致内核栈溢出:

我们以上图的调用链举例,这里所说的限制就是每一个子程序的栈空间( stack size)不能超过 256 字节(如果校验器检测到 bpf to bpf 调用,那主程序也会被当做子程序),这个限制使得 BPF 程序调用链最多能使用 8KB 的栈空间,计算方式:256 byte/stack 乘以尾调用数量上限 33。如果没有这个限制,BPF 程序将使用 512 字节栈空间,最终消耗最多 16KB 的总栈空间,在某些架构上会导致栈溢出。
这里需要提的一点是两种类型在同时使用时到底是如何省内存的,举个例子,subfunc1 执行 Tail Call 调用 func2,此时 subfunc 的栈帧已经被 func2 复用了,然后 func2 执行 BPF to BPF Calls 调用 subfunc2,此时第三个栈帧被创建,然后执行 Tail Call 调用 func3,五个逻辑过程使用了三个栈,这就节省了内存。
然后因为开始时调用 subfunc1,所以最终的程序执行权仍然会回到 func1。
4. CO-RE Sample
我们可以在 [11][12] 中看到 kernel 中对于 Tail Call 的官方实例,我使用 libbpf CO-RE 特性修改了 [11],使得 User 程序更容易理解 libbpf 使用 Tail Call。其次虽然挂载 ebpf 程序可以使用其他命令辅助挂载,比如 tc,prctl,但是示例程序我认为可能老老实实调接口挂容易理解些,我们使用 [11] 作为例子。
例子中用到了 seccomp filter,这个过滤器用于减少内核中系统调用暴露于应用程序的范围,说人话就是限制每个进程使用的系统调用(参数修改是 task_struct 级别的),支持 SECCOMP_SET_MODE_STRICT 和 SECCOMP_SET_MODE_FILTER 两种过滤模式,用于限定子集 (read,write, _exit,sigreturn) 的过滤和 eBPF 形式的过滤。[3] 中提到可以避免 TOCTTOU,因为 open 被限制了,自然也就没有 TOCTTOU 错误的风险了 [6]。
[3] 中对 seccomp filter 的解释是这样的:
System call filtering isn’t a sandbox. It provides a clearly defined mechanism for minimizing the exposed kernel surface. It is meant to be a tool for sandbox developers to use.
[2] 中提到:
Designed to sandbox compute-bound programs that deal with untrusted byte code.
tracex5_kern.bpf.c
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#include "bpf_helpers.h"
char LICENSE[] SEC("license") = "Dual BSD/GPL";
struct {
__uint(type, BPF_MAP_TYPE_PROG_ARRAY);
__uint(max_entries, 1024);
__type(key, u32);
__type(value, u32);
} progs SEC(".maps");
SEC("kprobe/__seccomp_filter")
int BPF_KPROBE(__seccomp_filter, int this_syscall, const struct seccomp_data *sd, const bool recheck_after_trace)
{
// 这里注意 ebpf 程序栈空间只有 512 字节,太大这里会报错的,可以自己调大一点看看
char comm_name[30];
bpf_get_current_comm(comm_name, sizeof(comm_name));
// 调用失败以后会直接 fall through
bpf_tail_call(ctx, &progs, this_syscall);
char fmt[] = "syscall=%d common=%s\n";
bpf_trace_printk(fmt, sizeof(fmt), this_syscall, comm_name);
return 0;
}
/* we jump here when syscall number == __NR_write */
SEC("kprobe/SYS__NR_write")
int bpf_func_SYS__NR_write(struct pt_regs *ctx)
{
struct seccomp_data sd;
bpf_probe_read(&sd, sizeof(sd), (void *)PT_REGS_PARM2(ctx));
if (sd.args[2] > 0) {
char fmt[] = "write(fd=%d, buf=%p, size=%d)\n";
bpf_trace_printk(fmt, sizeof(fmt),
sd.args[0], sd.args[1], sd.args[2]);
}
return 0;
}
SEC("kprobe/SYS__NR_read")
int bpf_func_SYS__NR_read(struct pt_regs *ctx)
{
struct seccomp_data sd;
bpf_probe_read(&sd, sizeof(sd), (void *)PT_REGS_PARM2(ctx));
if (sd.args[2] > 0 && sd.args[2] <= 1024) {
char fmt[] = "read(fd=%d, buf=%p, size=%d)\n";
bpf_trace_printk(fmt, sizeof(fmt),
sd.args[0], sd.args[1], sd.args[2]);
}
return 0;
}
SEC("kprobe/SYS__NR_open")
int bpf_func_SYS__NR_open(struct pt_regs *ctx)
{
struct seccomp_data sd;
bpf_probe_read(&sd, sizeof(sd), (void *)PT_REGS_PARM2(ctx));
char fmt[] = "open(fd=%d, path=%p)\n";
bpf_trace_printk(fmt, sizeof(fmt), sd.args[0], sd.args[1]);
return 0;
}
tracex5_user.c
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <signal.h>
#include <time.h>
#include <assert.h>
#include <errno.h>
#include <sys/resource.h>
#include <linux/if_link.h>
#include <linux/limits.h>
#include <bpf/libbpf.h>
#include "trace.skel.h"
#define BPF_SYSFS_ROOT "/sys/fs/bpf"
enum {
SYS__NR_read = 3,
SYS__NR_write = 4,
SYS__NR_open = 5,
};
struct bpf_progs_desc {
char name[256];
enum bpf_prog_type type;
int map_prog_idx;
struct bpf_program *prog;
};
static struct bpf_progs_desc progs[] = {
{"kprobe/__seccomp_filter", BPF_PROG_TYPE_KPROBE, -1, NULL},
{"kprobe/SYS__NR_read", BPF_PROG_TYPE_KPROBE, SYS__NR_read, NULL},
{"kprobe/SYS__NR_write", BPF_PROG_TYPE_KPROBE, SYS__NR_write, NULL},
{"kprobe/SYS__NR_open", BPF_PROG_TYPE_KPROBE, SYS__NR_open, NULL},
};
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
static volatile bool exiting = false;
static void sig_handler(int sig)
{
exiting = true;
}
int main(int argc, char **argv)
{
struct trace_bpf *skel;
int map_progs_fd, main_prog_fd, prog_count;
int err;
// 设置一些 debug 信息的回调
libbpf_set_print(libbpf_print_fn);
signal(SIGINT, sig_handler);
signal(SIGTERM, sig_handler);
// Load and verify BPF application
skel = trace_bpf__open();
if (!skel) {
fprintf(stderr, "Failed to open and load BPF skeleton\n");
return 1;
}
// Load and verify BPF programs
err = trace_bpf__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
map_progs_fd = bpf_object__find_map_fd_by_name(skel->obj, "progs");
prog_count = sizeof(progs) / sizeof(progs[0]);
for (int i = 0; i < prog_count; i++) {
progs[i].prog = bpf_object__find_program_by_title(skel->obj, progs[i].name);
if (!progs[i].prog) {
fprintf(stderr, "Error: bpf_object__find_program_by_title failed\n");
return 1;
}
bpf_program__set_type(progs[i].prog, progs[i].type);
}
for (int i = 0; i < prog_count; i++) {
int prog_fd = bpf_program__fd(progs[i].prog);
if (prog_fd < 0) {
fprintf(stderr, "Error: Couldn't get file descriptor for program %s\n", progs[i].name);
return 1;
}
// -1 指的是主程序
if (progs[i].map_prog_idx != -1) {
unsigned int map_prog_idx = progs[i].map_prog_idx;
if (map_prog_idx < 0) {
fprintf(stderr, "Error: Cannot get prog fd for bpf program %s\n", progs[i].name);
return 1;
}
// 给 progs map 的 map_prog_idx 插入 prog_fd
err = bpf_map_update_elem(map_progs_fd, &map_prog_idx, &prog_fd, 0);
if (err) {
fprintf(stderr, "Error: bpf_map_update_elem failed for prog array map\n");
return 1;
}
}
}
// 只载入主程序,尾调用不载入,所以不可以调用 trace_bpf__attach
struct bpf_link* link = bpf_program__attach(skel->progs.__seccomp_filter);
if (link == NULL) {
fprintf(stderr, "Error: bpf_program__attach failed\n");
return 1;
}
while(exiting){
// 写个裸循环会吃巨多 CPU 的
sleep(1);
}
cleanup:
// Clean up
trace_bpf__destroy(skel);
return err < 0 ? -err : 0;
}
执行如下指令:
-
clang -g -O2 -target bpf -D__TARGET_ARCH_x86 -I/usr/src/kernels/5.4.119-19-0009.1(改成自己的)/include/ -idirafter /usr/local/include -idirafter /usr/include -c trace.bpf.c -o trace.bpf.o
-
gen skeleton trace.bpf.o > trace.skel.h
-
clang -g -O2 -Wall -I . -c trace.c -o trace.o
-
clang -Wall -O2 -g trace.o -lelf -lz -o trace
-
cat /sys/kernel/debug/tracing/trace_pipe
-
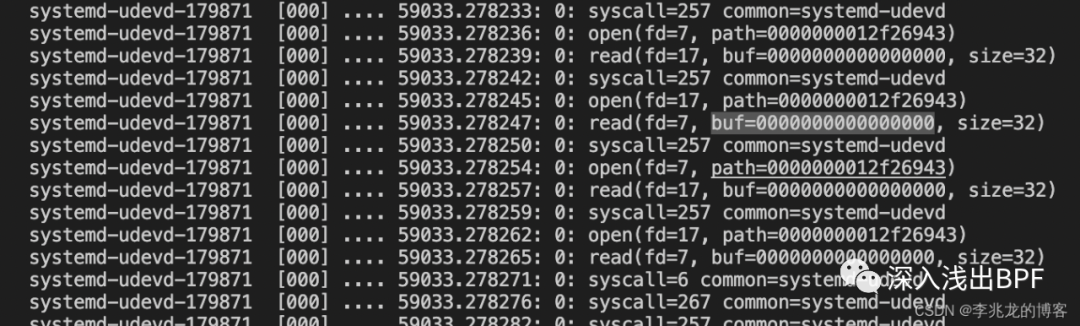
可以看到预期输出。
5. tail call costs in eBPF
[13] 评估了为缓解 Spectre 缺陷而引入的一些优化给 eBPF 的尾调用性能带来了多少性能损耗(Spectre 是指大多数 CPU(英特尔、AMD、ARM)上存在的一系列利用硬件漏洞的漏洞)。
这篇文章还没看,有精力了拜读一下,先插个眼。
6. 总结
eBPF 环境现在我还是很头疼,开始在 VMware Fusion 上跑虚拟机,但是 m1 不支持 VMware Tools,导致使用极其不便,而且镜像也需要特殊的修改才能用到 m1 上,用高版本的内核没那么容易;其次买的云服务器版本只到 5.4.119,一些 eBPF 的特性也没法用;至于 MAC m1 双系统,我不太有精力去吃这个螃蟹了,一是资料少,其次 Tail Calls 和 BPF to BPF Calls 同时调用目前也只支持 X86,收益也不大。
好吧,我承认,归根结底,还是不想花钱去买 Parallels Desktop。
7. 参考
-
linux 安全之 seccomp [1] -
Using seccomp to limit the kernel attack surface [2] -
SECure COMPuting with filters [3] -
seccomp(2) — Linux manual page [4] -
bpf: introduce bpf_tail_call() helper [5] -
Time-of-check to time-of-use wiki [6] -
cilium document [7] -
eBPF: Traffic Control Subsystem [8] -
Introducing Walmart’s L3AF Project: Control plane, chaining eBPF programs, and open-source plans [9] -
BMC: Accelerating Memcached using Safe In-kernel Caching and Pre-stack Processing [10] -
kernel tracex5_kern.c [11] -
kernel sockex3_kern.c [12] -
Evaluation of tail call costs in eBPF [13]
参考资料
linux 安全之 seccomp: https://blog.csdn.net/u013250169/article/details/115669655
2Using seccomp to limit the kernel attack surface: https://man7.org/conf/lpc2015/limiting_kernel_attack_surface_with_seccomp-LPC_2015-Kerrisk.pdf
3SECure COMPuting with filters: https://www.kernel.org/doc/Documentation/prctl/seccomp_filter.txt
4seccomp(2) — Linux manual page: https://www.man7.org/linux/man-pages/man2/seccomp.2.html
5bpf: introduce bpf_tail_call() helper: https://lwn.net/Articles/645169/
6Time-of-check to time-of-use wiki: https://en.wikipedia.org/wiki/Time-of-check_to_time-of-use
7cilium document: https://docs.cilium.io/en/stable/bpf/#tail-calls
8eBPF: Traffic Control Subsystem: https://blog.csdn.net/weixin_43705457/article/details/123388130
9Introducing Walmart’s L3AF Project: Control plane, chaining eBPF programs, and open-source plans: https://medium.com/walmartglobaltech/introducing-walmarts-l3af-project-control-plane-chaining-ebpf-programs-and-open-source-plans-b96c54823ada
0BMC: Accelerating Memcached using Safe In-kernel Caching and Pre-stack Processing: https://www.usenix.org/system/files/nsdi21-ghigoff.pdf
1kernel tracex5_kern.c: https://elixir.bootlin.com/linux/v5.4.119/source/samples/bpf/tracex5_kern.c
2kernel sockex3_kern.c: https://elixir.bootlin.com/linux/v5.4.119/source/samples/bpf/sockex3_kern.c
3Evaluation of tail call costs in eBPF: https://elixir.bootlin.com/linux/v5.4.119/source/samples/bpf/sockex3_kern.c

