
Topic太多!RocketMQ炸了!原创
网上博客常说,kafka的topic数量过多会影响kafka,而RocketMQ不会受到topic数量影响。
但是,果真如此吗?
最近排查一个问题,发现RocketMQ稳定性同样受到topic数量影响!!
好了,一起来回顾下这次问题排查吧,最佳实践和引申思考放在最后,千万不要错过。
1、问题描述
我们的RocketMQ集群为4.6.0版本,按照3个nameserver,2个broker,每个broker为主从双节点部署。
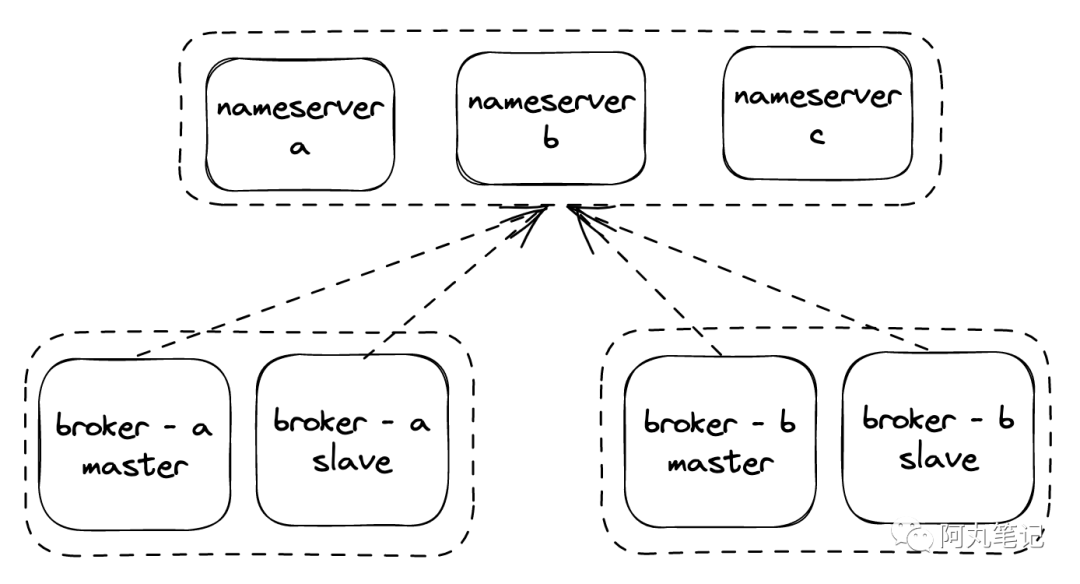
某天收到警报,broker-b突然从nameserver掉线,且主从双节点都无法重新注册。
2、初步排查
2.1 检查进程存活&网络
因为控制台上显示broker-a正常,因此可以认为 nameserver、broker-a都是正常的,问题出在broker-b上。
当时第一反应是broker-b进程挂了,或者网络不通了。
登陆broker节点,看到进程依然存活。
然后通过telnet检查和nameserver的联通性,显示正常,网络没有问题。
2.2 检查日志
检查broker日志,马上发现了异常。
2023-01-09 14:07:37 WARN brokerOutApi_thread_3 - registerBroker Exception, mqnameserver3:xxxx
org.apache.rocketmq.remoting.exception.RemotingSendRequestException: send request to <qnameserver3/xx.xx.xx.xxx:xxxx> failed
at org.apache.rocketmq.remoting.netty.NettyRemotingAbstract.invokeSyncImpl(NettyRemotingAbstract.java:429) ~[rocketmq-remoting-4.6.0.jar:4.6.0]
at org.apache.rocketmq.remoting.netty.NettyRemotingClient.invokeSync(NettyRemotingClient.java:373)
......
异常比较明确,broker请求nameserver失败,所以导致无法注册到集群中。
那为什么会注册失败呢?没有非常明确的提示,因此去看下nameserver上的日志信息。
2023-01-09 14:09:26 ERROR NettyServerCodecThread_1 - decode exception, xx.xxx.xx.xxx:40093
io.netty.handler.codec.TooLongFrameException: Adjusted frame length exceeds 16777216: 16777295 - discarded
at io.netty.handler.codec.LengthFieldBasedFrameDecoder.fail(LengthFieldBasedFrameDecoder.java:499) [netty-all-4.0.42.Final.jar:4.0.42.Final]
......
这个异常看起来是nameserver上的netty抛出的,请求过大抛出了异常。
根据日志关键字,直接定位到了源码,确实有默认的大小限制,并且可以通过com.rocketmq.remoting.frameMaxLength进行控制。
2.3 源码分析
虽然找到了异常的直接原因,但是为什么broker突然会有这么大的请求?是什么带来的?
从broker的warning日志中,并没有办法看到更多有效信息。
因此,还是得深入分析下broker上的源码。根据日志关键字,很快找到broker中的异常位置
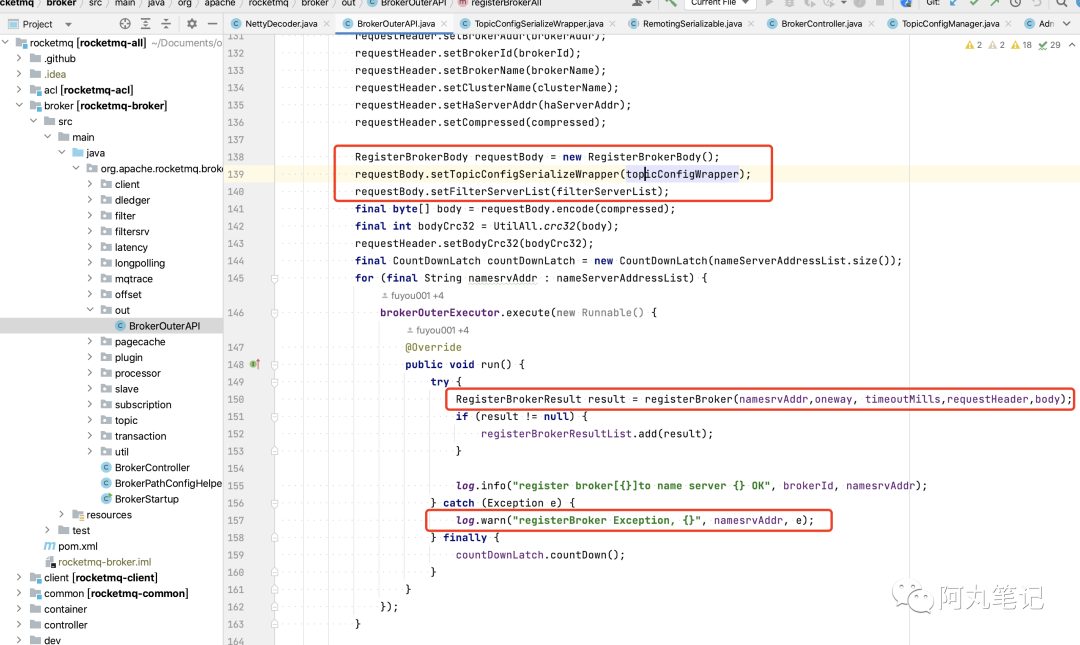
注意!这里通过遍历nameserverlist,在线程池中异步注册,跟后面的一个小知识点有关。
从源码中可以分析出,如果有过大的请求的话,应该就是这个requestBody引起,它携带了大量topic信息topicConfigWrapper。
但是我们在控制台上看到当前集群中,只有300+topic(这里其实是一个误区,最后会解释),理论上来说是非常小的,为什么会超出容量限制呢?
看了下源码上下文,并没有对reqeustBody或者topicConfigWrapper有相关日志的记录,因此,还是需要arthas来看看了。
2.4 arthas定位
直接通过arthas定位实际内存值
watch org.apache.rocketmq.broker.out.BrokerOuterAPI registerBrokerAll {params,returnObj} -x 3
查看结果
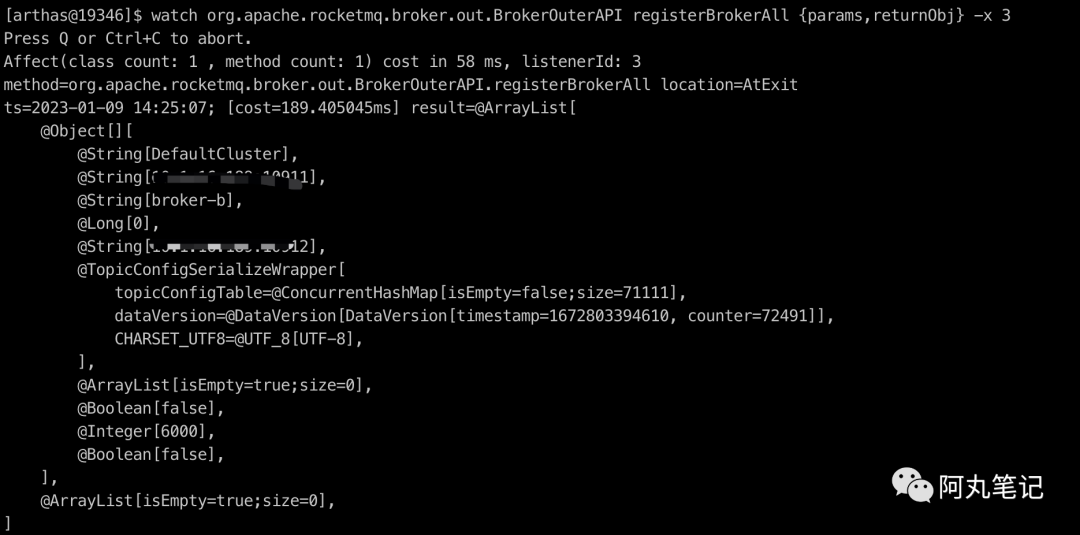
啥玩意?!
topicConfigTable的map大小为size=71111?!!
进一步看看这些topic里面都是些啥?我们调整下arthas的参数-x为4,改变watch变量的深度。
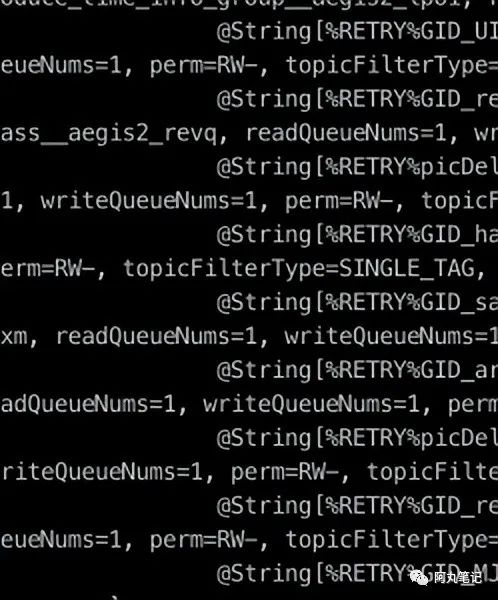
发现问题了!
我们看到了大量%RETRY%开头的topic。
3、根本原因
至此,根本原因就能明确了。
RETRY topic过多,导致 broker 向 nameserver 发送心跳(定时发送注册请求)时,心跳请求中携带的 body 上的 topic 信息过大,超过了 nameserver 上使用的 NettyDecoder.java 限制的 16M (默认值),心跳请求失败,所以broker掉线。
4、恢复
既然问题基本确定了,那么先尝试恢复吧。
前面已经看到了对最大请求体的配置,因此,我们在bin/runserver.sh中添加一个JAVA_OPTION对com.rocketmq.remoting.frameMaxLength进行配置。然后重启nameserver。
重新观察broker,果然重启成功了。
2023-01-09 16:03:55 INFO brokerOutApi_thread_3 - register broker[0]to name server mqnameserver4:9876 OK
2023-01-09 16:03:55 INFO brokerOutApi_thread_4 - register broker[0]to name server mqnameserver2:9876 OK
当然,这只是临时恢复措施,后面重点要思考以下问题并进行优化:
-
RETRY topic数量这么多是否正常?是否可以清理无效topic?
-
如何做好后续的topic数量监控告警?
5、最佳实践
5.1 定时删除无效RETRY topic
考虑使用定时任务扫描所有业务topic下的消费组,再根据消费组状态(状态为not_online的消费组),拼出对应RETRY topic进行删除。以上步骤均有开源MQ sdk 的 api 可以调用。
即使后续消费组重新使用,RETRY topic 也会重新创建,不影响消费。
5.2 topic总数监控
前面说到在控制台上看到当前集群中只有300+topic,这里其实是一个误区,只勾选了NORMAL类型的topic,并没有注意RETRY、DLQ、SYSTEM类型的topic。
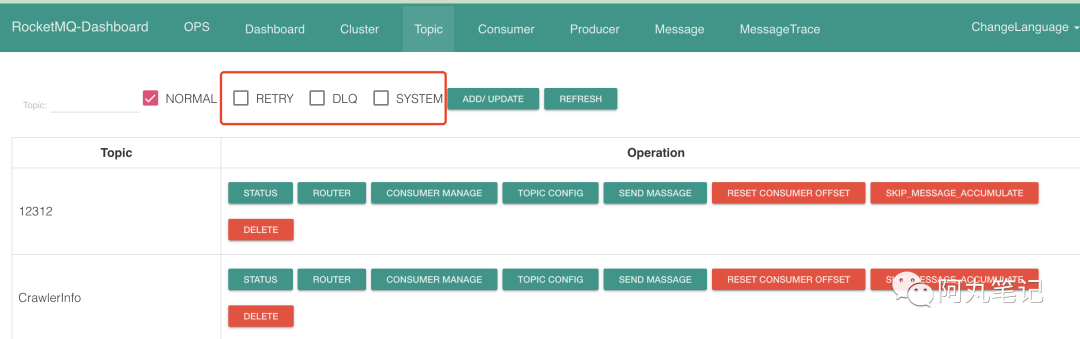
而这次几万个topic基本都是RETRY类型的。
后续需要添加topic数量监控(包括RETRY类型),防止由于topic数量过多,导致broker注册失败。
6、引申思考
6.1 RETRY topic是什么?为什么有这么多?
这需要从RocketMQ的重试机制与死信机制说起。
RocketMQ 提供了自带的重试机制,消息消费失败或超时,会被投递到 RETRY topic。RETRY topic 里的消息会按照延时队列的延时时间进行消费,这样也避免了有问题的消息阻塞正常消费。
RETRY topic 里保存的是消费状态为 consumer_later 的消息,在重试达到 16 次(默认值)以后,消息会进入死信队列(本质上也是一个新的topic类型,DLS topic)。
DLQ topic在使用时才会创建,因此不会像RETRY topic 这样大量膨胀。
但是,RETRY topic不一样。它是由RocketMQ服务端自动创建,创建的时机有两个:
-
消费失败的时候,将消息发送回 broker,这时候会在服务端创建RETRY topic

-
consumer client 和服务端保持心跳时创建RETRY topic

线下环境的消费组存在大量的临时测试group,而 RocketMQ会给每个实际存在的消费组创建RETRY topic,导致 RETRY topic 大量膨胀。
6.2 如果所有消息自动重试,顺序消息会乱序吗?
我们知道,RocketMQ中包含三种消息类型:普通消息、普通有序消息、严格有序消息。
三种消息的类型介绍如下:
-
普通消息:消息是无序的,任意发送发送哪一个队列都可以。
-
普通有序消息:同一类消息(例如某个用户的消息)总是发送到同一个队列,在异常情况下,也可以发送到其他队列。
-
严格有序消息:消息必须被发送到同一个队列,即使在异常情况下,也不允许发送到其他队列。
对于这三种类型的消息,RocketMQ对应的提供了对应的方法来分别消息:
//发送普通消息,异常时默认重试
public SendResult send(Message msg)
//发送普通有序消息,通过selector动态决定发送哪个队列,异常默认不重试,可以用户自己重试,并发送到其他队列
public SendResult send(Message msg, MessageQueueSelector selector, Object arg)
//发送严格有序消息,通过指定队列,保证严格有序,异常默认不重试
public SendResult send(Message msg, MessageQueue mq)
所以RocketMQ客户端的生产者默认重试机制,只对普通消息有作用。对于普通有序消息、严格有序消息是没有作用。
6.3 nameserver数据一致性问题
在通过修改启动参数com.rocketmq.remoting.frameMaxLength进行临时恢复的时候,发现一个问题:日志恢复了,但是控制台上却仍然没有显示broker-b。
排查了下发现,由于nameserver有4台,只重启了一台,而控制台连接访问的nameserver是另一台,所以显示不正确。
通过切换控制台nameserver地址,就能看到broker-b了。
为什么不同nameserver允许数据不一致呢?
前面在排查的过程中也发现了,broker源码中通过遍历nameserverlist,在线程池中异步注册topic信息到nameserver。

而这也体现了RocketM中对nameserver的设计思想。
nameserver是一个AP组件,而不是CP组件!
在 RocketMQ 中 Nameserver 集群中的节点相互之间不通信,各节点相互独立,实现非常简单。但同样会带来一个问题:
Topic 的路由信息在各个节点上会出现不一致。
那 Nameserver 如何解决这个问题呢?RocketMQ 的设计者采取的方案是不解决,即为了保证 Nameserver 的高性能,允许存在这些缺陷。
NameServer之间不通信,消息发送端通过PULL方式更新topic信息,无法及时感知路由信息的变化,因此引入了消息发送重试(只针对普通消息)与故障规避机制来保证消息的发送高可用。
事实上,在RocketMQ的早期版本,即MetaQ 1.x和MetaQ 2.x阶段,也是依赖Zookeeper的(CP型组件)。但MetaQ 3.x(即RocketMQ)却去掉了ZooKeeper依赖,转而采用自己的NameServer。
NameServer数据不一致,比较大的影响就是topic的队列会存在负载不均衡的问题,以及消费端的重复消费问题,这些问题对消息队列来说都是可以忍受的,只要最终能保持一致,恢复平衡即可。
更多好文分享尽在阿丸笔记(微信公众号:aone_note),欢迎关注!


