
RabbitMQ、RocketMQ、Kafka性能为何差距如此大?原创
MQ的作用解耦、异步、削峰填谷。
-
未使用MQ的情况
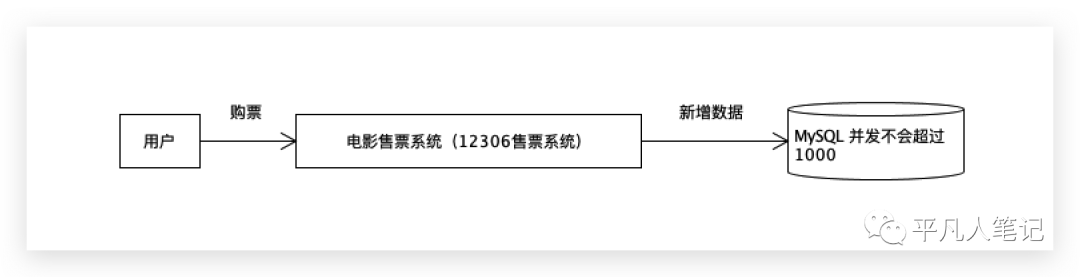
mysql并发写大部分情况下维持在600-800之间,并发读1200-1500之间,所以消费端在消费消息的时候需控制在并发小于1000,从而达到限流的效果。
-
使用MQ的情况
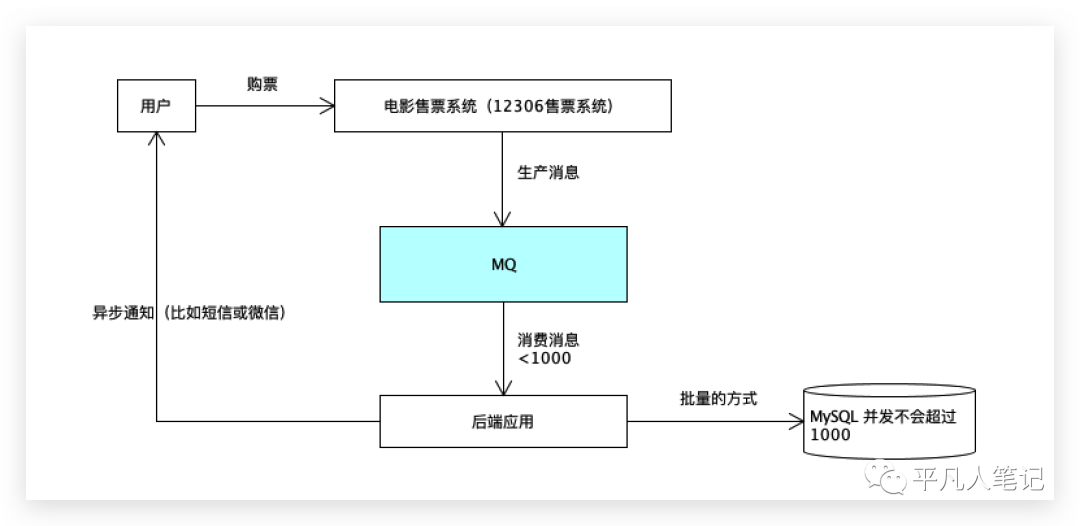
mq做个缓冲,消息放到磁盘,几个G或上t都可以存储,消息丢失的可能性比较小。
使用MQ需要面临的问题
可用性降低
多了MQ,对外部依赖增加,但通过try-catch兜底,mq消息发送失败,则插入数据库。
提高复杂度
需要搭建高可用的Kafka集群或RocketMQ集群。
消息重复
通过消费端的幂等性实现。
中间生产消息的时候,有可能会发生网络的波动,业务程序认为消息没有发送成功,其实消息已经写入了一条,应用端超时timeout,此时会进行消息的重发即2个id为1的都会写入到mq中,后端应用消费的时候,就会消费到2条消息。
消息顺序
比如下单、支付、发送物流通知,这3个业务消息并发的产生且后端多线程消费的情况下,需要考虑消息消费顺序的问题。
解决的方式是单个消费者、单个生产者、单个队列可以保证消息有序的消费。
一个主题,多个队列的情况下需要通过负载均衡的方式路由到不同的队列中来。
有多个消费者不能确保消息消费的顺序。
一致性问题
A、B、C三个系统,A和B两个写入数据库成功了,C系统写库失败,这种情况可以用分布式事务解决,可以使用RocketMQ提供的分布式事务或阿里开源的Seta。
对比下常用的MQ
RabbitMQ
支持并发1.2W。
RabbitMQ集群很弱,主要确保高可用,不能拓展性能。
想性能更高,得搭建多主多从,比如3主3从、4主4从,第一个可以确保高可用,第二个可以提高整个的性能,但RabbitMQ集群不可以这样拓展性能。
Kafka
支持并发100W。
RocketMQ
支持并发10W。
Kafka、RocketMQ天生支持分布式,支持动态扩展、动态扩缩容。
RocketMQ相对来说功能也比较丰富,支持死信消息、延迟(基于死信消息可以实现延迟消息)消息、消息的回溯、消息的过滤。
Kafka不支持死信消息。
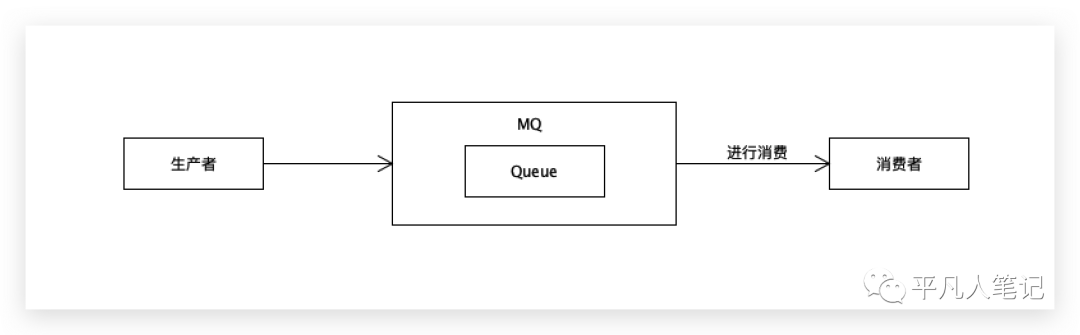
消息端消费成功,发起ACK确认,作为RabbitMQ来说,可以直接把这个消息删掉。
Kafka或RocketMQ会记录消息者的偏移量,保证下一次消费的时候不会消费同一条消息。
死信消息
如果消费很多次还没有成功,比如10次、20次都不能消费成功,mq中的这个消息就不能被确认 ,这个时候就引入了死信消息,进入一个单独的死信队列进行保存,后续进行手工处理或额外处理,比如用消息补偿机制,实在消费不了的则异步通知生产者。
RabbitMQ在ack确认很多次都没有成功返回的时候,则会设置一个标识,就会认为这个消息是死信消息,就会把这个消息写入DCL队列中。
RocketMQ也有这样的死信消息,如果消息重试的次数超过16次,作为RocketMQ也会把这个消息写入专门的死信队列中去。
补偿机制要根据业务来,比如微信冲电话费,在微信应用里面,通过异步的方式来通知成功或失败,如果说失败了,失败的补偿机制就是退费;如果这条消息反正也消费不了,不知道出于什么原因,也有可能加入了失信名单 或超过了消费的额度,这个时候就消费不了,多次尝试之后,在微信的后端就认为是死信消息,而退费就是一种补偿机制。
延迟消息
一般情况下,消息只要发到mq,消费者就会里立马消费掉,但是有的业务场景需要在这个消息上加一个延迟的时间,比如延迟10分钟再被消费。
应用场景比如买电影票-线上电影票的购票流程:
1、选座位,对这个座位进行锁定,防止再被其他人锁定
2、必须在10分钟之内支付
异常情况:选了座位,不支付。
对于后端系统来说,只要锁定过期且没有支付,就需要把座位释放掉。
这种情况可以采用定时任务来处理,不断的去轮循数据库,但会出现新的问题,1要查询数据库,2每个人选定的时间不一样,若定时10分钟跑一次,就会出现释放座位不及时的情况,若定时1秒跑一次,系统性能开销比较大。
最优的方案是采用延时消息,每一次选座位的时候,就写一个延时10分钟的消息,在消费的时候,必须等10分钟之后,消费者再处理,不需要轮询数据库。
不同MQ为什么性能差别这么大?
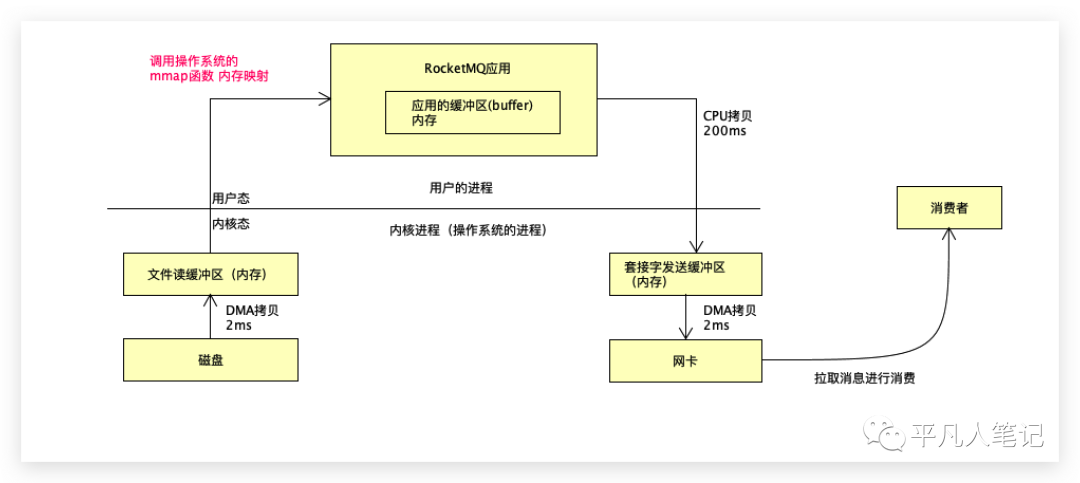
主要依赖于Rabbitmq、Kafka持久化的底层机制:将消息写入磁盘的零拷贝技术。
Netty、Nginx都有用到该技术。
零拷贝包括MMAP的零拷贝、Sendfile的零拷贝。
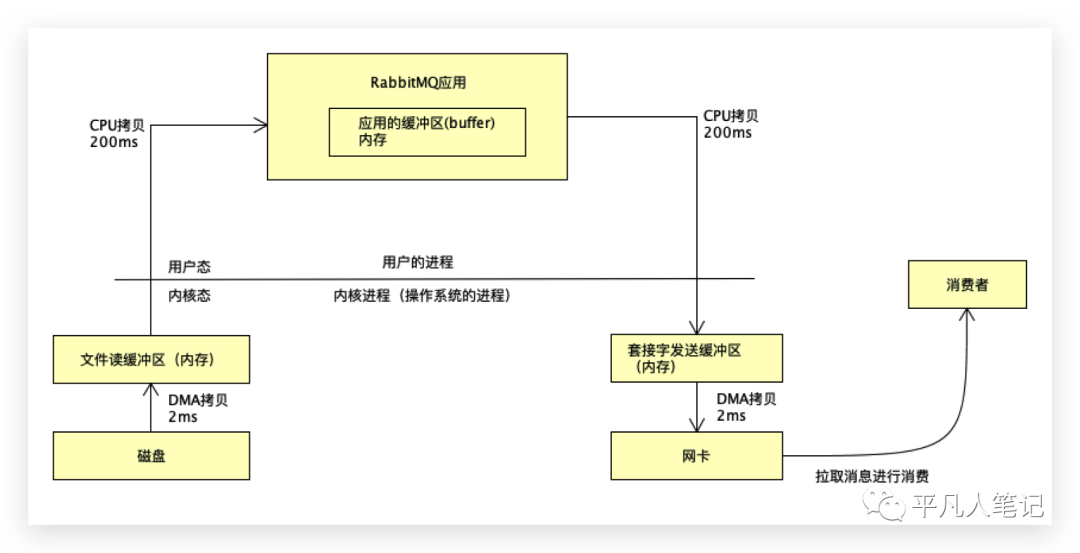
RabbitMQ传统方式的拷贝
作为消费者要拉取消息进行消费,站在IO的角度去看,为了确保消息的高可用,往往把消息放到磁盘,一旦数据没有写入磁盘就会有丢失数据的可能性,所以消息会先写入磁盘。
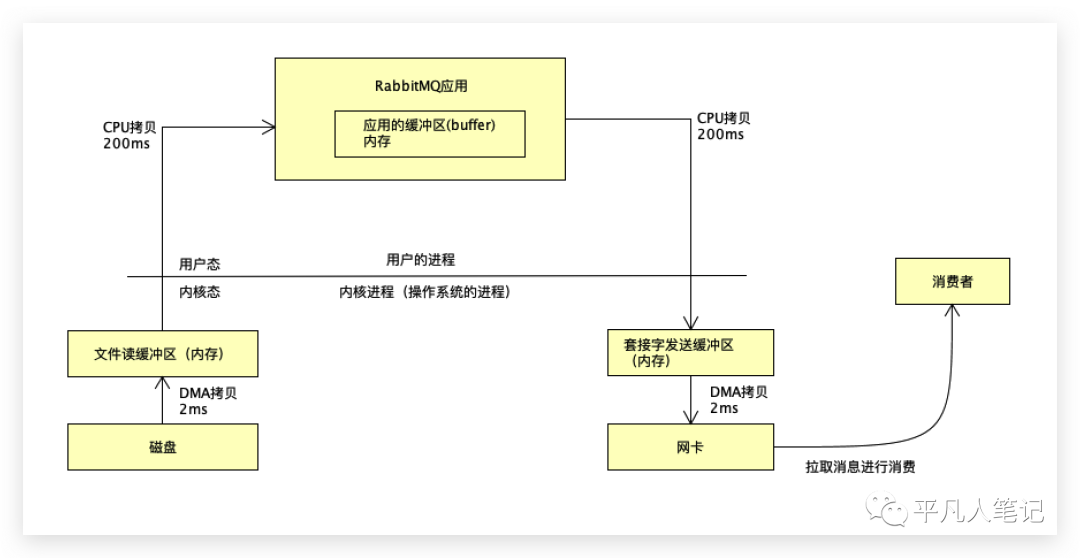
把数据从磁盘读出,再通过网络发送给消费者。
应用发送数据要先发送给操作系统的网卡,最终通过网卡发送数据给消费者。
站在磁盘的角度来看,数据首先要经过第一个拷贝,这里叫DMA拷贝到文件读取缓冲区,伪代码为buffer=file.read ,写完之后,发给消费者,创建一个socket即建立一个TCP网络通信,通过socket调用send方法,把读到的buffer进行发送。
站在io的角度来看,经过了几次拷贝?
第一次:数据从磁盘拷贝到内核的文件读取缓冲区,这个过程称为DMA拷贝,
然后数据经过第二次拷贝:CPU拷贝,拷贝的数据放入应用缓冲区即就是刚才定义的buffer字节流。
应用程序并不能直接操作网卡,底层调用socket,通过socket调用操作系统的网卡,但是操作系统网卡会有一个问题 :不能直接读到应用的内存,所以又需要经过一次CPU拷贝到套接字发送缓冲区,最后再经过一次DMA拷贝(直接内存读取 Direct Memory Access)。
内核或操作系统的驱动允许不同速度的硬件进行沟通的时候才会有DMA拷贝。
如果没有DMA,就需要通过CPU的大量中断来进行负载。
什么叫中断?
在计算机里面,启动一个线程,让CPU来跑,CPU在跑的时候,你给我发了一个消息,我的电脑怎么知道我的网卡里面进来一条消息呢?这个就需要网卡在硬件级别叫下CPU:cpu等一等,现在我要打断你一下。
如果通过CPU负载的话,效率很低,因为CPU干很多事情,CPU做大量中断负载的话,比如200M的数据,如果通过CPU拷贝,大概需要200ms,而通过DMA拷贝,速度只需要2毫秒。
计算机里面,越底层的东西就越快,通过CPU拷贝到话,效率往往很低,因为这个时候还需要向CPU请求负载, 这里会涉及到很多的中断负载的切换。
在不考虑MQ应用程序运转多少时间的情况下,传统的拷贝大概需要404毫秒。
RocketMQ MMAP零拷贝技术
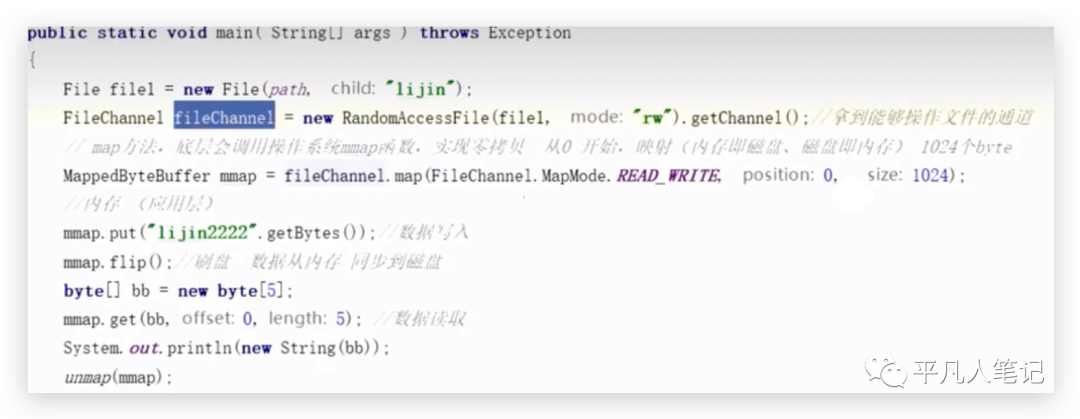
在RocketMQ中采用一种MMAP的零拷贝技术,本身是做内存映射,当内存的应用缓冲区调用操作系统的mmap函数,可以做一个内存映射。
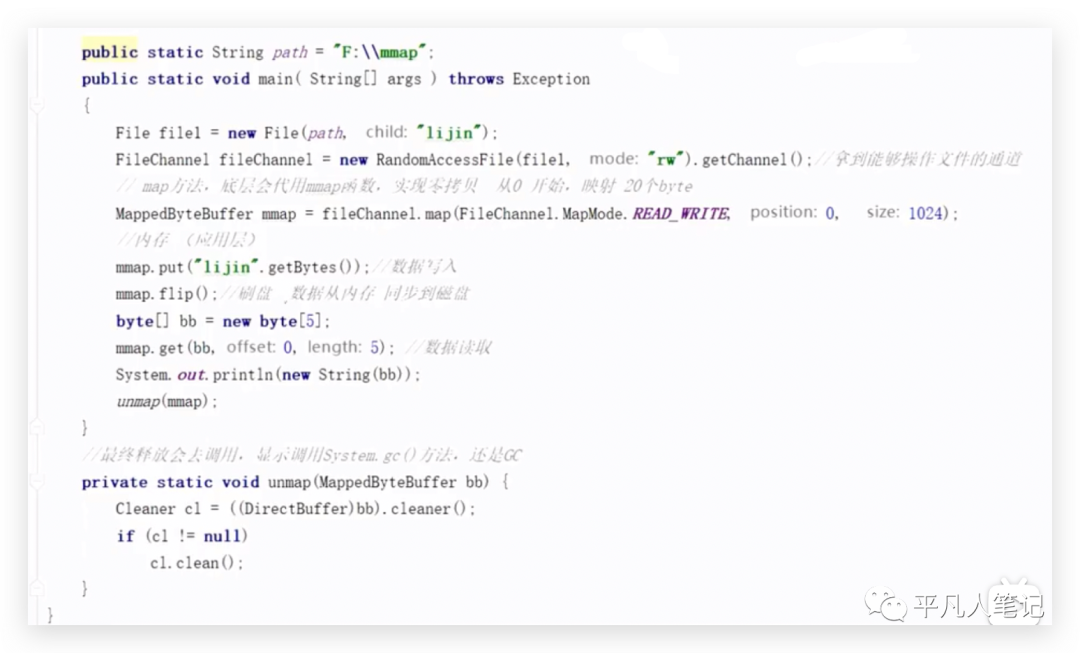
拿到能够操作文件的通道到一个高级类FileChannel,这个高级类实际上是对文件进行操作。
底层会调用操作系统的mmap函数来完成映射,映射的意思是内存即磁盘,磁盘即内存,如果完成映射之后,这个文件和内存的这个buffer(ByteBuffer)就一致了。
mmap是内存文件通过FileChannel调用map方法间接调用的,设置读写模式,文件映射到底可以读还是可以写,内存映射的位置即从哪里开始,0表示从头开始,内存映射大小为1024即这个文件可以映射1kb左右,拿到这个buffer之后,就可以进行写入,这个ByteBuffer和Hashmap是一样的方式,直接put把字符串转换成byte数组进行写入,写入完之后,再去调用flip方法进行刷盘,这个数据就可以同步到磁盘了,当然刷完盘之后,还可以拿出来,通过mmap.get把里面的前5个数据读取出来,读取之后还可以打印,

文件中这么多NULL,刚好长度是1024。
通过mmap创建的,因为它进行内存映射,所以这个文件必须要有空格,通过NULL值进行表示,读的时候,通过偏移量+长度,指定了5个长度,就可以读取到lijin这个字符串数据。
传统的方式
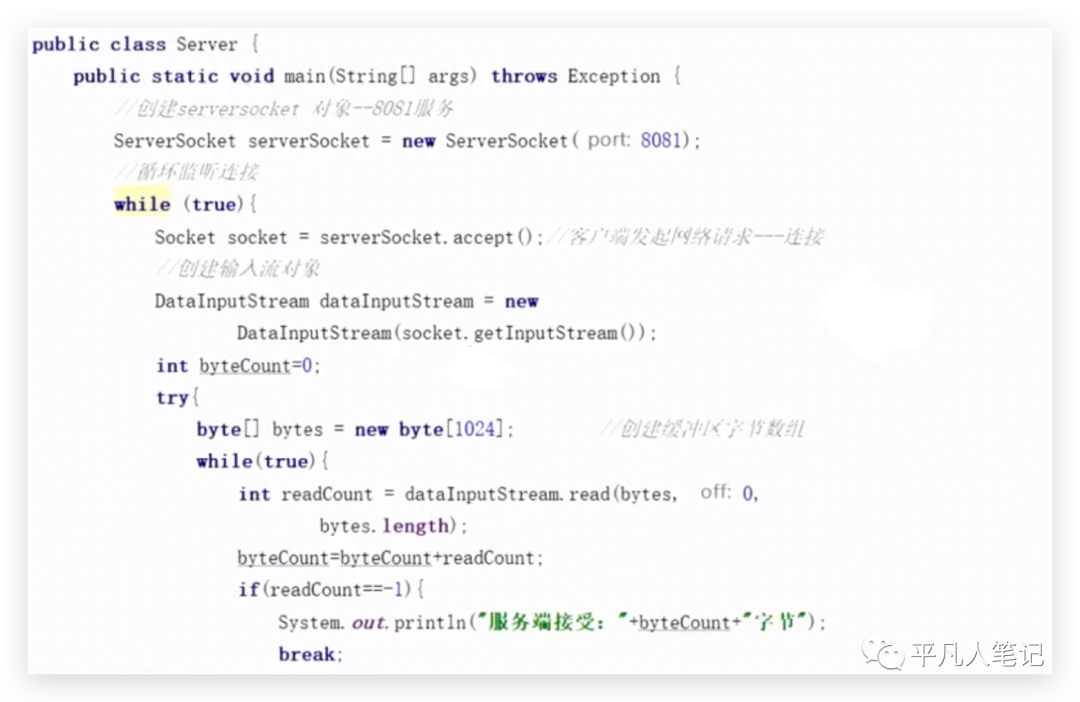
Server端(服务端)启动,模拟一个消费者即专门启动一个Server Socket监听,接受到数据,把数据读出来就可以了。
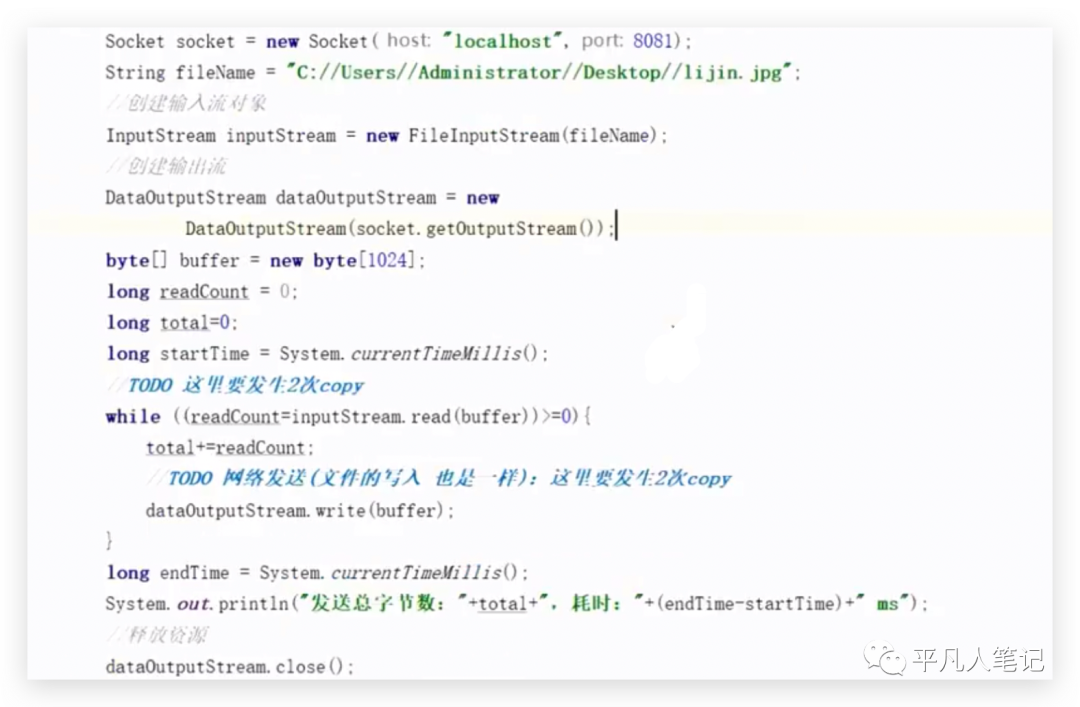
这个是传统的客户端读一个文件发送到网络的过程,这段代码跟
这个的业务场景是一样的。
创建一个socket,因为要发给对应的消费者,先建立一个网络连接。
inpuStream.read()会进行2次拷贝,一个是DMA拷贝,一次是CPU拷贝。
而这种方式只是一次拷贝,因为是内存映射。
map方法在系统启动的时候就被调用了。
传统的方式,每次都要new一个FileInputStream,这里涉及到了2次拷贝(每一次读取出来,读到buffer中,涉及到2次拷贝:一次DMA拷贝、一次CPU拷贝),耗时202毫秒,因为要发送网络,通过连接本机的8081端口,发送给它,还要创建一个对应的输出流拿取结果。
传统的方式本质上和文件读取是一样的,这是通过流的方式读取,while true不断的读并且累加,读完之后,拿到了buffer,再写网络,网络就通过socket创建的getOutputStream(文件的输出流、socket的输出流)转到DataOutputStream。
创建的socket就是一个连接,应用要跟消费者建立一个TCP的连接,这个TCP的连接在底层表示都是socket,不单单只是数据连接,还包含了数据通道,这里new一个socket就相当于跟另外一个消费者8081这样的socket通道建立了链接,通过socket通道里面的dataOutputStream.write方法输出数据,这里又会涉及到一次DMA拷贝,一次CPU拷贝。
首先做一次CPU拷贝,相当于把buffer的数据首先要发到套接字缓冲区(socket里面的缓冲区),这个socket要通过网卡发给消费者最终要把应用内存发送给网卡里面的内存,网卡是一个外设,网卡通过一个USB都可以去接,所以就需要做一个DMA拷贝。
这种方式共有4次拷贝,耗时为422毫秒,这是RabbitMQ的情况,而RocketMQ的mmap发送只有204毫秒,DMA拷贝速度一般是CPU的百倍。
Kafka的sendfile零拷贝技术
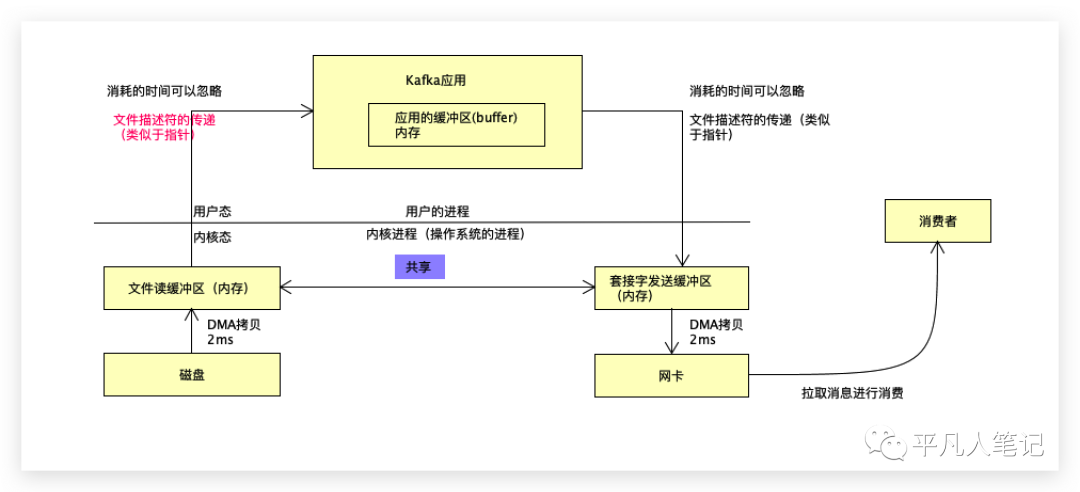
Kafka不会涉及到cpu拷贝,只是进行文件描述符的传递,这点消耗的时间可以忽略。
文件描述符类似一个指针,在linux上面所有东西都是文件描述符。
把数据放到文件数据读取缓冲区,这里就会有一个文件描述符,类似于网盘的地址,比如百度云网盘的分享链接,而真实的数据放百度网盘,这种开销可以忽略,既然数据已经放到了文件缓冲区,只要拿到文件缓冲区的指针,指针在应用程序里面内存的大小就可以忽略不计了。
在现代新的操作系统里面,既然都属于内核操作系统的进程,文件读取缓冲区的内存和套接字的内存可以共享。
文件描述符(offset=1024,size=9721823),比如要读取的文件,偏移量是1024,读取9721823这个大小的数据。
把文件描述符传给应用,这个速度和时间可以忽略不计,调用socket,相当于告诉socket你要去文件读取缓冲区内存找我要发送的数据,因为我已经告诉你偏移量和大小了。
通过sendfile的方式,只剩下2次DMA拷贝了,数据的传输基本上在内核就完成了。
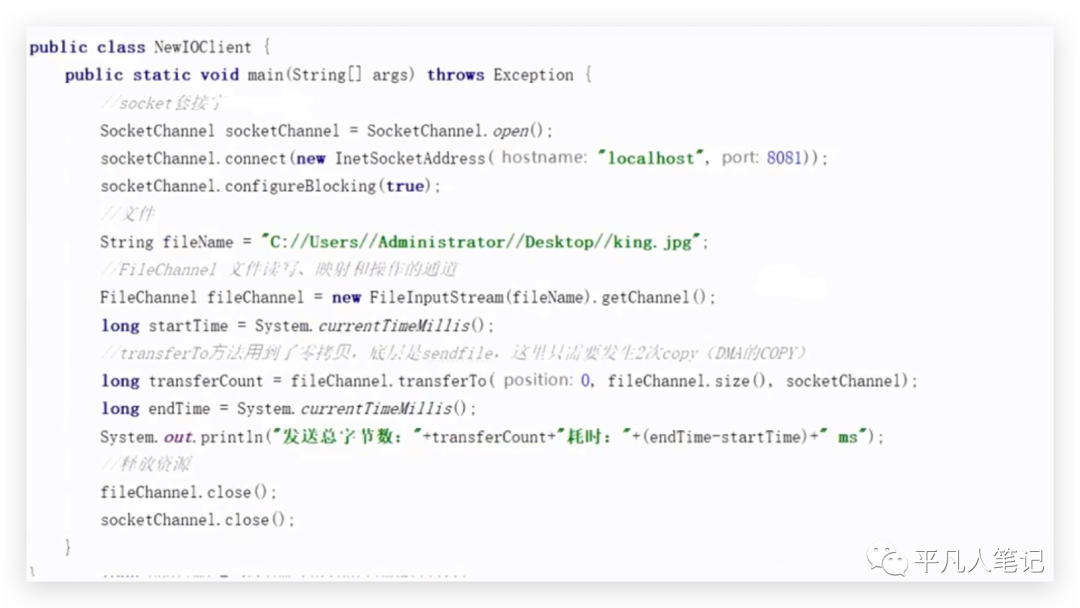
第一步new出一个SocketChannel,使用8081的服务器地址,SocketChannel是套接字发送缓冲区的一个通道,FileChannel是针对磁盘文件的通道,2个通道通过transferTo进行共享,
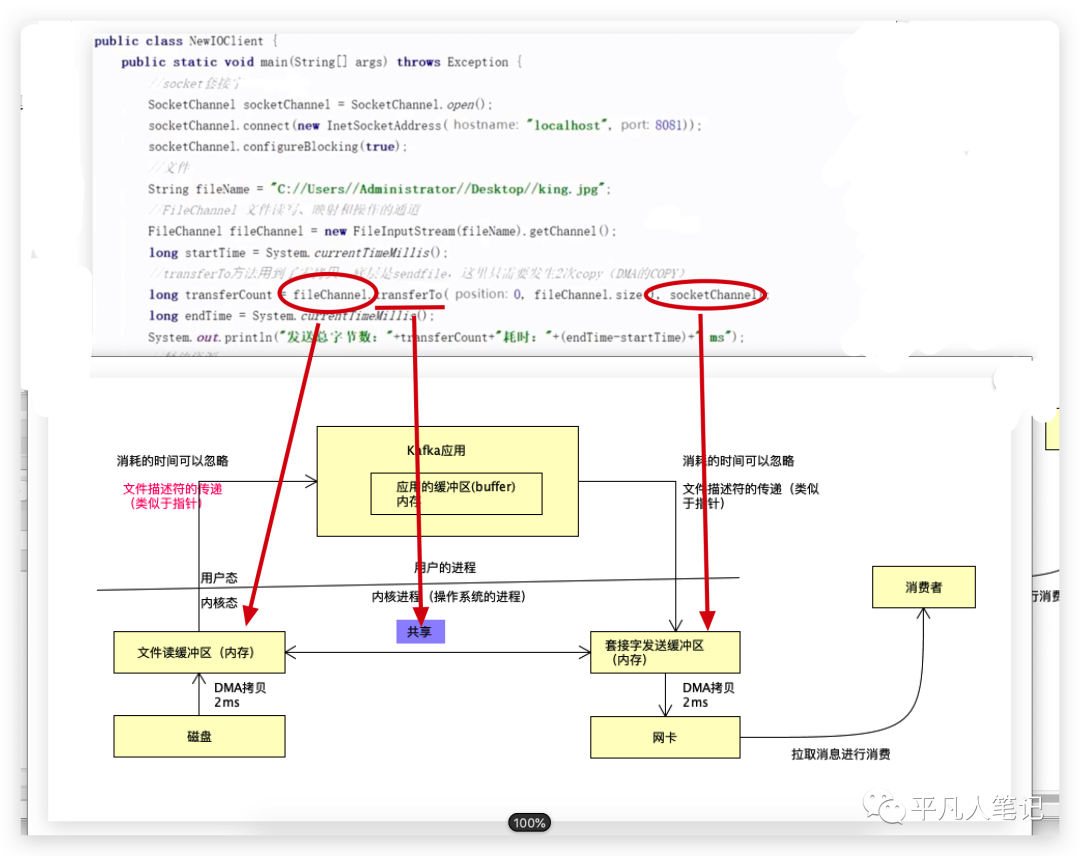
共享的位置是从0开始,长度是文件大小,这里没有使用多文件,只读了一个文件。
fileName可以通过FileChannel传过去,传过去就已经网络传输了,只要调用transferTo方法就会完成网络发送,这种方式的耗时只需要16毫秒。
传统的传输要转换成InputStream、FileInputStream、DataOutputStream,所以开销会大些,同样的一张图片,转换出来的字节流会多一点。
通过NIO转换transferTo直接就这么转了,如果把中间的CPU拷贝的时间忽略,相当于2+2+12,传输文件描述符的话,还是会占据一点点时间。
不同的序列化方式即转换的流不一样,传输的字节数大小也不一样。
为什么Kafka不用mmap
既然sendfile零拷贝技术效率更高,RocketMQ早期版本也是基于Kakfa java版本重写改进的,那RocketMQ为什么不用sendfile技术?
因为它们的设计理念不一样。
作为文件描述符等同于网盘地址。
RocketMQ有很多功能的延伸点是不一样的,比如延迟消息、死信消息需要数据流转到MQ应用。
RocketMQ要支持延迟消息,数据最好要进入应用,不能单纯拿一个文件描述符做延迟消息,这也是为什么Kafka没有延迟消息的原因。
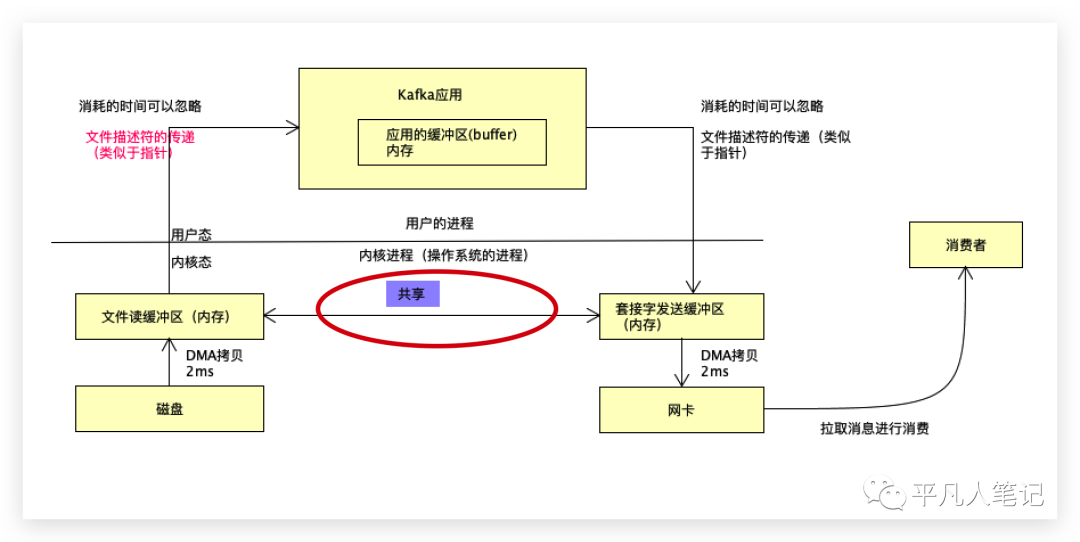
数据是通过这样的方式发送的,数据不会直接经过Kafka。
Kafka的设计比较简单,没有延迟消息、死信消息等。
比如1万条消息中有一个消息发送不成功,这种情况一定要放到mq的应用内存才能处理,
而通过sendfile方式,很多的消息数据都是文件读取缓冲区的文件描述符。
类似网盘资料中的数据很多,是一个代码压缩包,单独把其中的一段代码拿出来是非常麻烦的。
Kafka做死信消息,要写一个定时器,不断的轮询,如果消息失败了,把这个消息写入到Kafka的一个文件或一个队列中,可以这样变相的实现,但自身原生是不支持死信消息的。



