
Go设计模式--桥接模式,让代码既能多维度扩展又不会臃肿原创
大家好,这里是每周都在陪你一起进步的网管~!
桥接模式(Bridge Pattern)又叫作桥梁模式、接口模式或柄体(Handle and Body)模式,指将抽象部分与具体实现部分分离,使它们都可以独立地变化,属于结构型设计模式。
桥接模式适用于以下几种业务场景。
-
在抽象和具体实现之间需要增加更多灵活性的场景。 -
一个负责某块逻辑的类存在两个或多个独立变化的维度,而这些维度都需要独立进行扩展。 -
不希望使用继承,或因为多层继承导致系统类的个数剧增。
下面举个大家都能理解的例子来说明桥接模式模式在系统多维度扩展和降低臃肿度上的作用
桥接模式举例
某业务系统, 现需要开发数据库导出工具, 根据SQL语句导出表数据到文件,数据库类型有多种, 目前需要支持MySQL, Orache 未来可能支持 SQLServer。导出格式可能有多种, 目前需要支持CSV和JSON格式
此场景下, 数据库类型是一种维度, 导出格式是另一种维度, 组合可能性是乘法关系,即数据可以从MySQL读出后,导出成CSV 或者JSON格式,对于Oracle也是同样的情况。
如果我们用常规的继承来实现这个数据库导出模块,模块中首先要有一个类似抽象基础类的基类,然后再用继承分别实现:MySQL-CSV导出类、MySQL- JSON导出类、Oracle-CSV导出类、Oracle-JSON导出类,如果以后模块再加一种支持的数据库SQLServer和导出格式XML,那么系统里实现类就更多了。
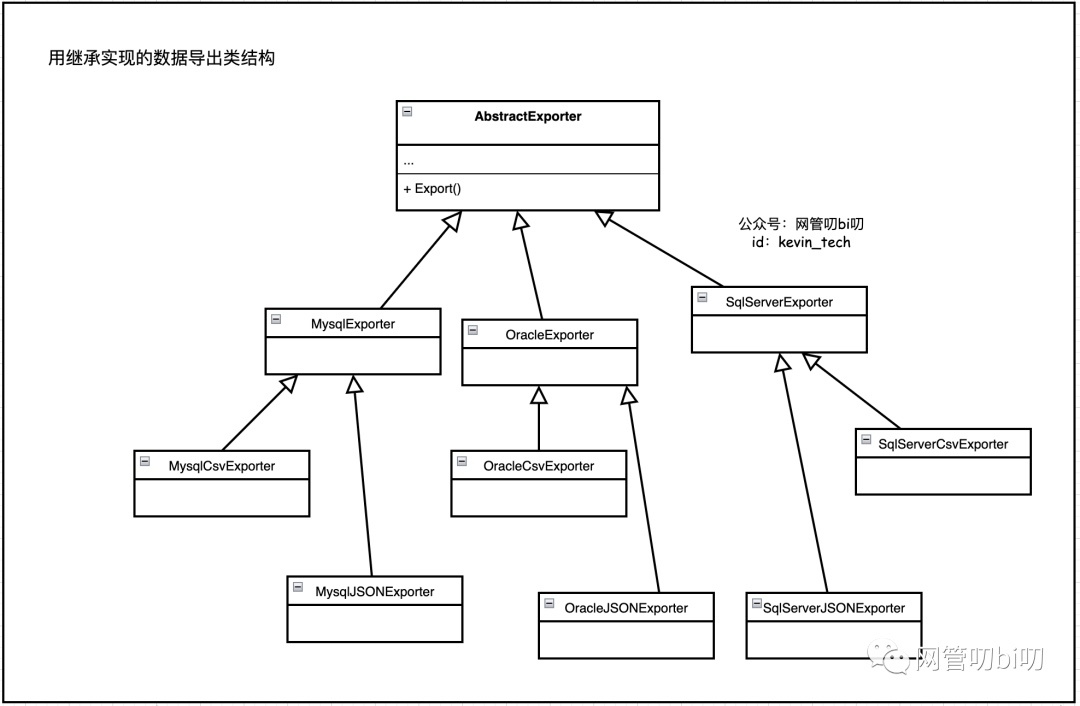
从上图可以看到,对于数据库类型和导出格式两个维度的每种组合都需要创建一个实现类,如果有N个维度,每个维度有M种变化,则最少需要M * N个实现类,类非常多,并且实现类中有非常多的重复功能。
关于最少需要M*N个实现类,这里再解释一下,上面为了现实用继承非常臃肿的视觉效果,特意还把给每种数据库的Exporter抽象了一个父类,实际使用中确实可能会有这种情况。
那么此时我们换一种思路,将"导出工具"分离出"数据抓取"和"数据导出"两个维度, 以便自由扩展、互相组合,从而减少类数目。这便是使用桥接模式解决“需求多维度变化时系统会变臃肿的核心思想。
下面我们再看一下用桥接模式模式的思想把两个维度分离后再组合,系统的类结构: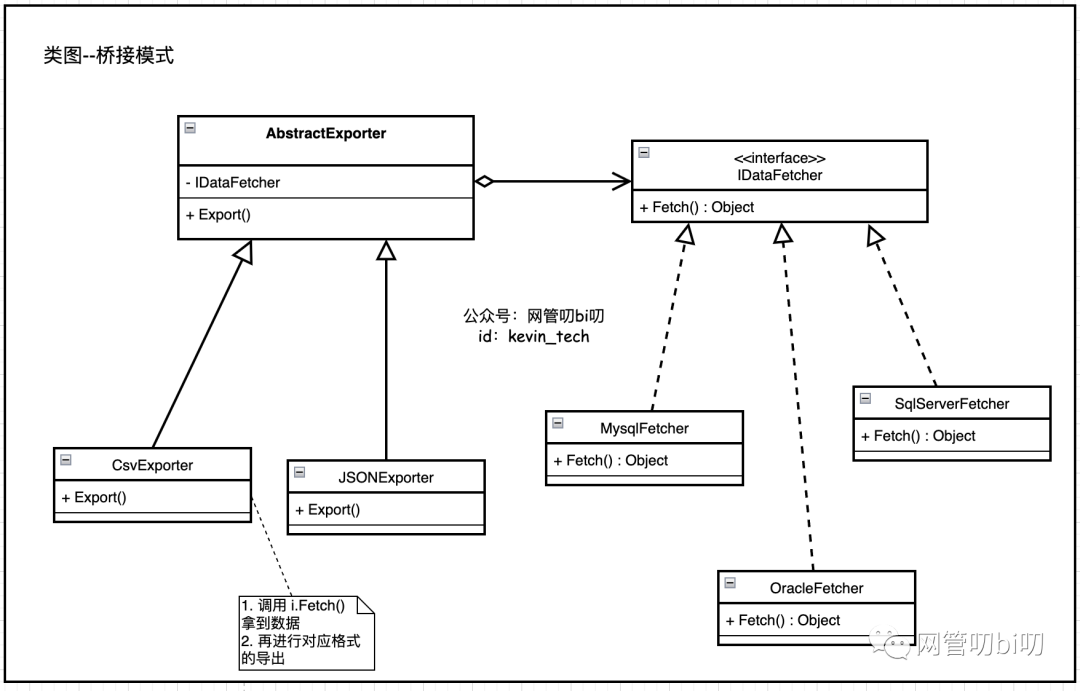
IDataFetcher的实现类即可。
接下来我们把这里分析的类图转化成代码,看看用代码怎么实现桥接模式版本的数据导出工具。
桥接模式代码实现
首先我们定义出数据导出器和查询器的接口
// 数据导出器
type IDataExporter interface {
Fetcher(fetcher IDataFetcher)
Export(sql string, writer io.Writer) error
}
// 数据查询器
type IDataFetcher interface {
Fetch(sql string) []interface{}
}
目前数据器有两个具体实现MysqlDataFetcher 和OracleDataFetcher,它们分别负责从MySQL和Oracle数据库中查询数据。
"本文使用的完整可运行源码
去公众号「网管叨bi叨」发送【设计模式】即可领取"
type MysqlDataFetcher struct {
Config string
}
func (mf *MysqlDataFetcher) Fetch(sql string) []interface{} {
fmt.Println("Fetch data from mysql source: " + mf.Config)
rows := make([]interface{}, 0)
// 插入两个随机数组成的切片,模拟查询要返回的数据集
rows = append(rows, rand.Perm(10), rand.Perm(10))
return rows
}
func NewMysqlDataFetcher(configStr string) IDataFetcher {
return &MysqlDataFetcher{
Config: configStr,
}
}
type OracleDataFetcher struct {
Config string
}
func (of *OracleDataFetcher) Fetch(sql string) []interface{} {
fmt.Println("Fetch data from oracle source: " + of.Config)
rows := make([]interface{}, 0)
// 插入两个随机数组成的切片,模拟查询要返回的数据集
rows = append(rows, rand.Perm(10), rand.Perm(10))
return rows
}
func NewOracleDataFetcher(configStr string) IDataFetcher {
return &OracleDataFetcher{
configStr,
}
}
后续我们要给导出工具扩展支持的数据库,就在新增对应的IDataFetcher实现即可。
然后我们在定义两个数据导出器IDataExporter的实现:CsvExporter和JsonExporter,从类图里我们可以看到IDataExporter的实现会通过一个内部属性持有对IDataFetcher的引用,即通过组合的方式来完成我们的数据导出器在导出格式和数据源类型两个维度上的自由搭配。
"本文使用的完整可运行源码
去公众号「网管叨bi叨」发送【设计模式】即可领取"
type CsvExporter struct {
mFetcher IDataFetcher
}
func NewCsvExporter(fetcher IDataFetcher) IDataExporter {
return &CsvExporter{
fetcher,
}
}
func (ce *CsvExporter) Fetcher(fetcher IDataFetcher) {
ce.mFetcher = fetcher
}
func (ce *CsvExporter) Export(sql string, writer io.Writer) error {
rows := ce.mFetcher.Fetch(sql)
fmt.Printf("CsvExporter.Export, got %v rows\n", len(rows))
for i, v:= range rows {
fmt.Printf(" 行号: %d 值: %s\n", i + 1, v)
}
return nil
}
type JsonExporter struct {
mFetcher IDataFetcher
}
func NewJsonExporter(fetcher IDataFetcher) IDataExporter {
return &JsonExporter{
fetcher,
}
}
func (je *JsonExporter) Fetcher(fetcher IDataFetcher) {
je.mFetcher = fetcher
}
func (je *JsonExporter) Export(sql string, writer io.Writer) error {
rows := je.mFetcher.Fetch(sql)
fmt.Printf("JsonExporter.Export, got %v rows\n", len(rows))
for i, v:= range rows {
fmt.Printf(" 行号: %d 值: %s\n", i + 1, v)
}
return nil
}
两个维度的抽象和实现都定义好后,客户只需要跟IDataExporter就行交互合作就能把整个模块运转起来。
"本文使用的完整可运行源码
去公众号「网管叨bi叨」发送【设计模式】即可领取"
func main() {
mFetcher := NewMysqlDataFetcher("mysql://127.0.0.1:3306")
csvExporter := NewCsvExporter(mFetcher)
var writer bytes.Buffer
// 从MySQL数据源导出 CSV
csvExporter.Export("select * from xxx", &writer)
oFetcher := NewOracleDataFetcher("mysql://127.0.0.1:1001")
csvExporter.Fetcher(oFetcher)
// 从 Oracle 数据源导出 CSV
csvExporter.Export("select * from xxx", &writer)
// 从 MySQL 数据源导出 JSON
jsonExporter := NewJsonExporter(mFetcher)
jsonExporter.Export("select * from xxx", &writer)
}
运行程序后我们会看到类似下面的输出:
Fetch data from mysql source: mysql://127.0.0.1:3306
CsvExporter.Export, got 2 rows
行号: 1 值: [%!s(int=9) %!s(int=4) %!s(int=2) %!s(int=6) %!s(int=8) %!s(int=0) %!s(int=3) %!s(int=1) %!s(int=7) %!s(int=5)]
行号: 2 值: [%!s(int=6) %!s(int=3) %!s(int=8) %!s(int=4) %!s(int=1) %!s(int=7) %!s(int=9) %!s(int=0) %!s(int=5) %!s(int=2)]
Fetch data from oracle source: mysql://127.0.0.1:1001
CsvExporter.Export, got 2 rows
行号: 1 值: [%!s(int=7) %!s(int=6) %!s(int=4) %!s(int=2) %!s(int=3) %!s(int=9) %!s(int=8) %!s(int=1) %!s(int=5) %!s(int=0)]
行号: 2 值: [%!s(int=6) %!s(int=0) %!s(int=5) %!s(int=8) %!s(int=4) %!s(int=2) %!s(int=9) %!s(int=7) %!s(int=3) %!s(int=1)]
Fetch data from mysql source: mysql://127.0.0.1:3306
JsonExporter.Export, got 2 rows
行号: 1 值: [%!s(int=1) %!s(int=8) %!s(int=0) %!s(int=9) %!s(int=7) %!s(int=4) %!s(int=2) %!s(int=3) %!s(int=6) %!s(int=5)]
行号: 2 值: [%!s(int=4) %!s(int=5) %!s(int=7) %!s(int=3) %!s(int=2) %!s(int=9) %!s(int=0) %!s(int=8) %!s(int=6) %!s(int=1)]
本文的完整源码,已经同步收录到我整理的电子教程里啦,可向我的公众号「网管叨bi叨」发送关键字【设计模式】领取。

对于桥接模式而言,当不同的事物被联系到一起时,可以更换它们其中的任意一个而不受影响。在上面的例子中,导出器是一个抽象维度,数据查询器是一个抽象维度。这两个抽象的实现类通过桥接的形式连接在一起,在这种情况下,我们可以替换两个抽象维度中的实现类从而搭配出不同的组合,与此同时整体系统却不受到影响。
总结
最后我们再来总结一下桥接模式的优缺点以及正确使用它的难点。
桥接模式的优点
-
分离抽象部分及其具体实现部分。 -
提高了系统的扩展性,支持系统向两个或者多个维度的扩展。 -
符合开闭原则。 -
利用组合,大大提高了代码复用率。
桥接模式的缺点
-
增加了系统的理解与设计难度。 -
需要正确地识别系统中两个(或者多个)独立变化的维度,这一条也是桥接模式的难点。

